Transformer库简介
是一个开源库,其提供所有的预测训练模型,都是基于transformer模型结构的。
Transformer库
我们可以使用 Transformers 库提供的 API 轻松下载和训练最先进的预训练模型。使用预训练模型可以降低计算成本,以及节省从头开始训练模型的时间。这些模型可用于不同模态的任务,
- 文本:文本分类、信息抽取、问答系统、文本摘要、机器翻译和文本生成。
- 图像:图像分类、目标检测和图像分割。
- 音频:语音识别和音频分类。
- 多模态:表格问答系统、OCR、扫描文档信息抽取、视频分类和视觉问答。
Transformer库支持最流行的深度学习库, p y T o r c h t e n s o r f l o w J A X pyTorch tensorflow JAX pyTorchtensorflowJAX
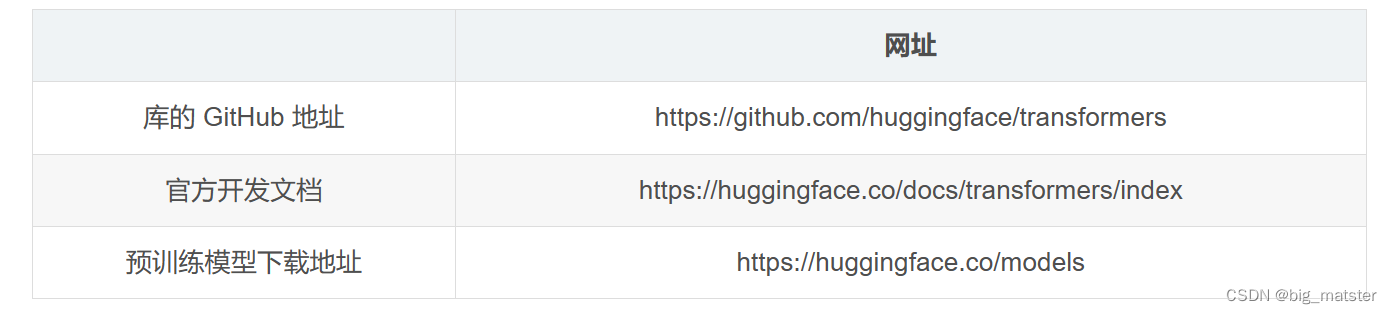
相关资源对应网站如下:
Transformer库支持的模型和架构
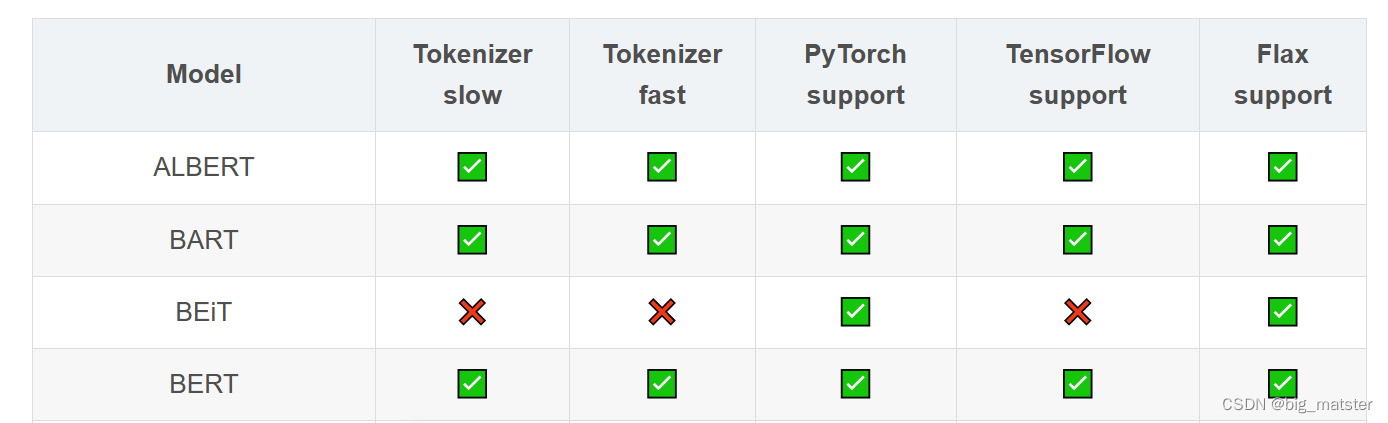
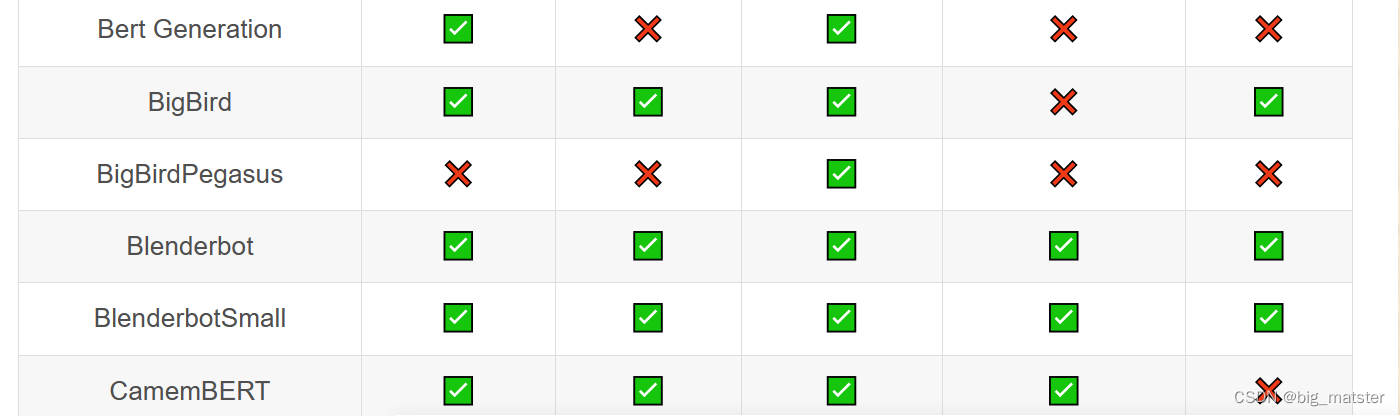
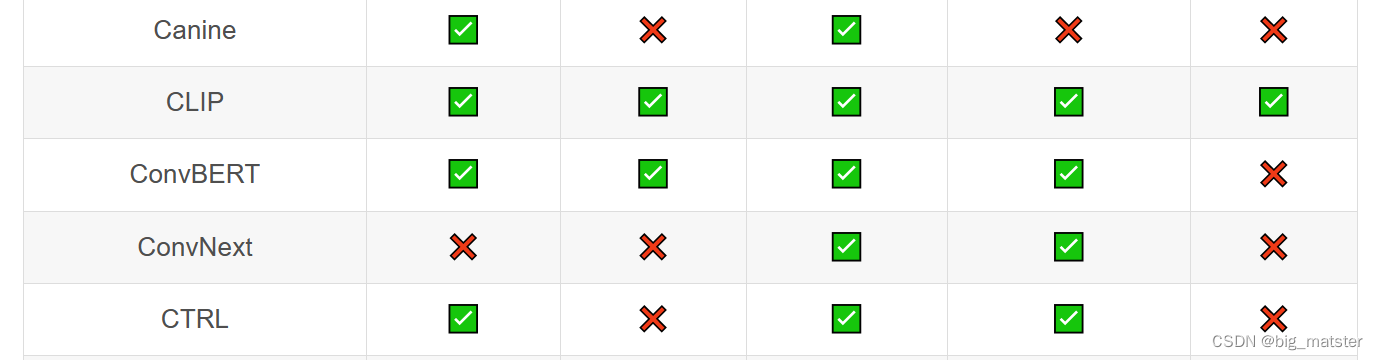
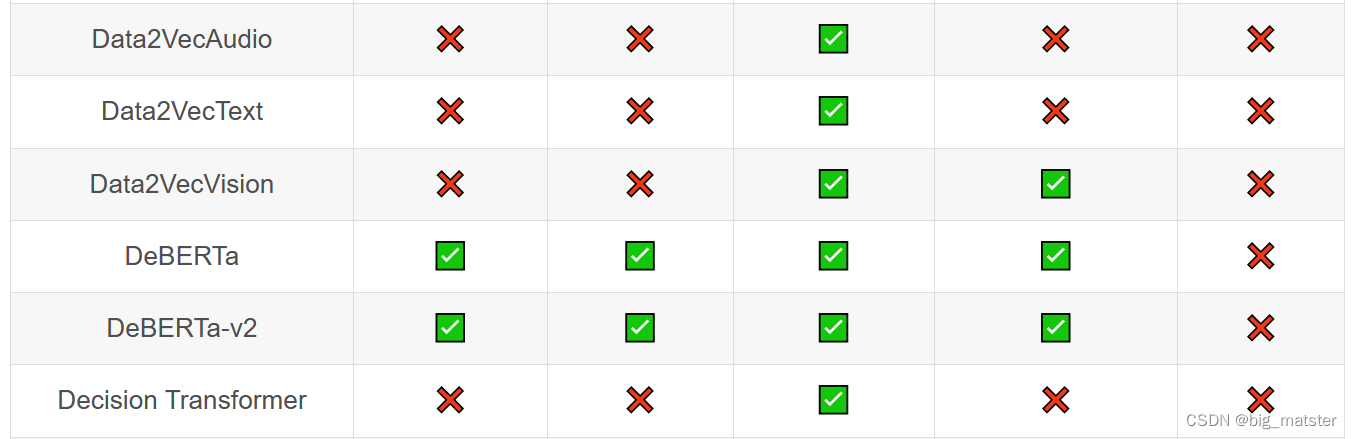
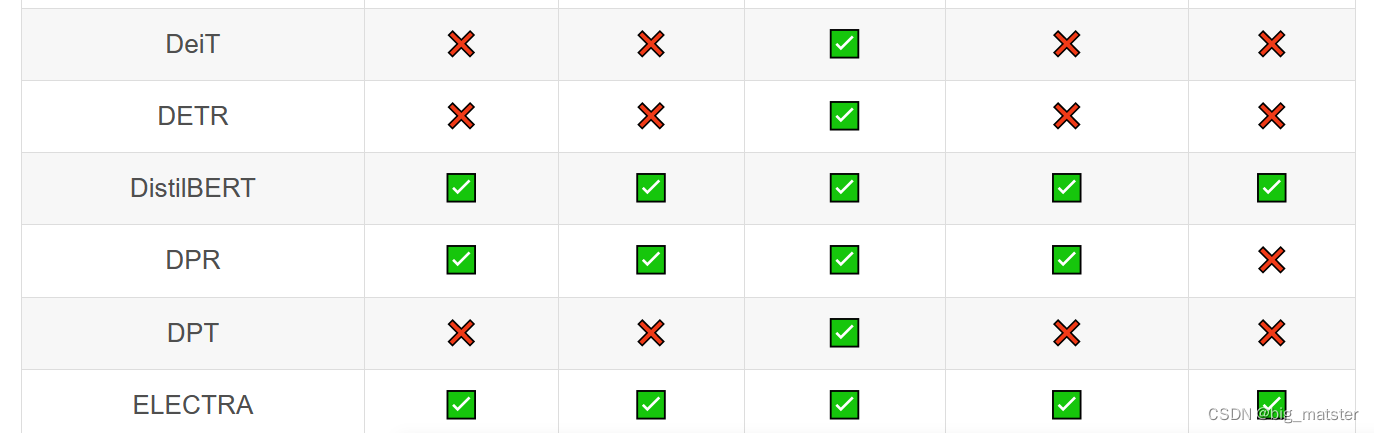
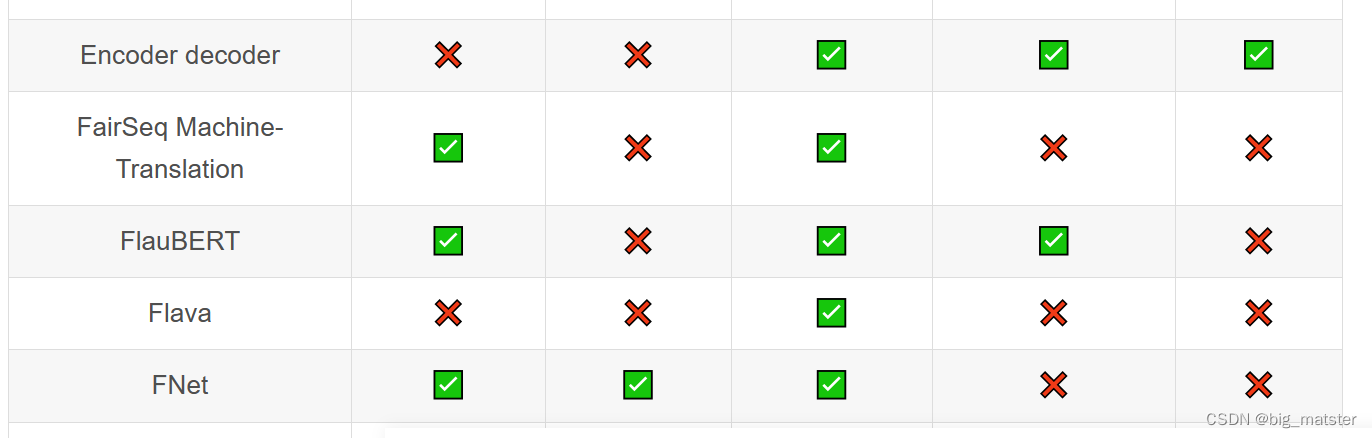
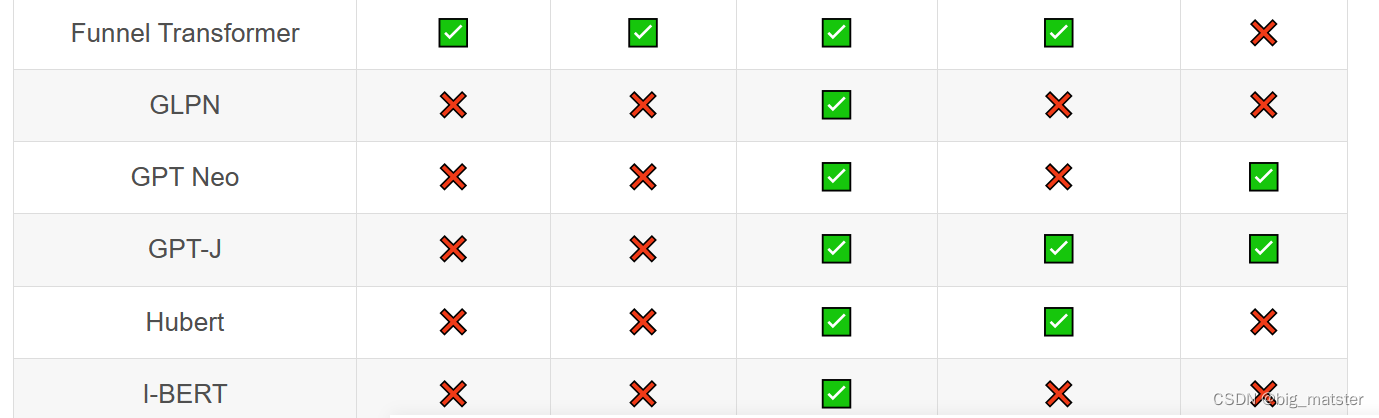
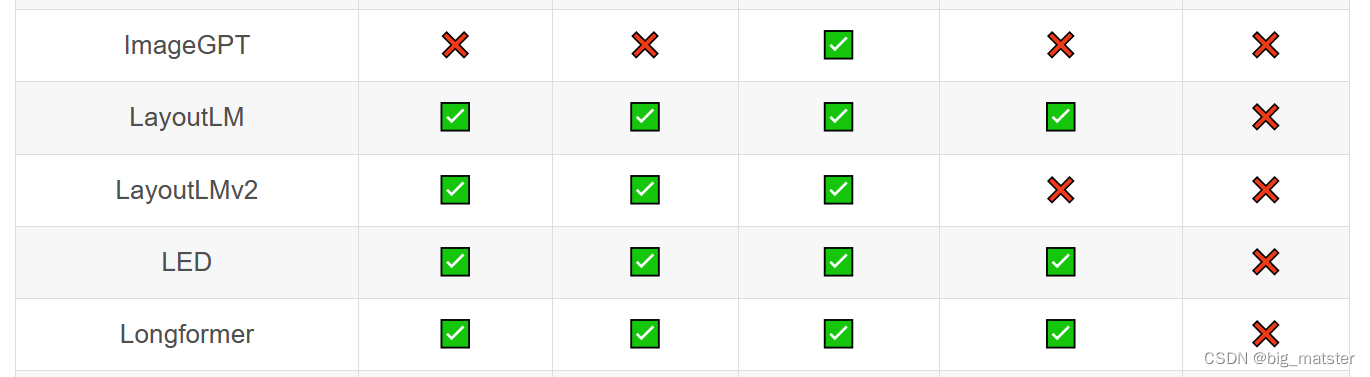
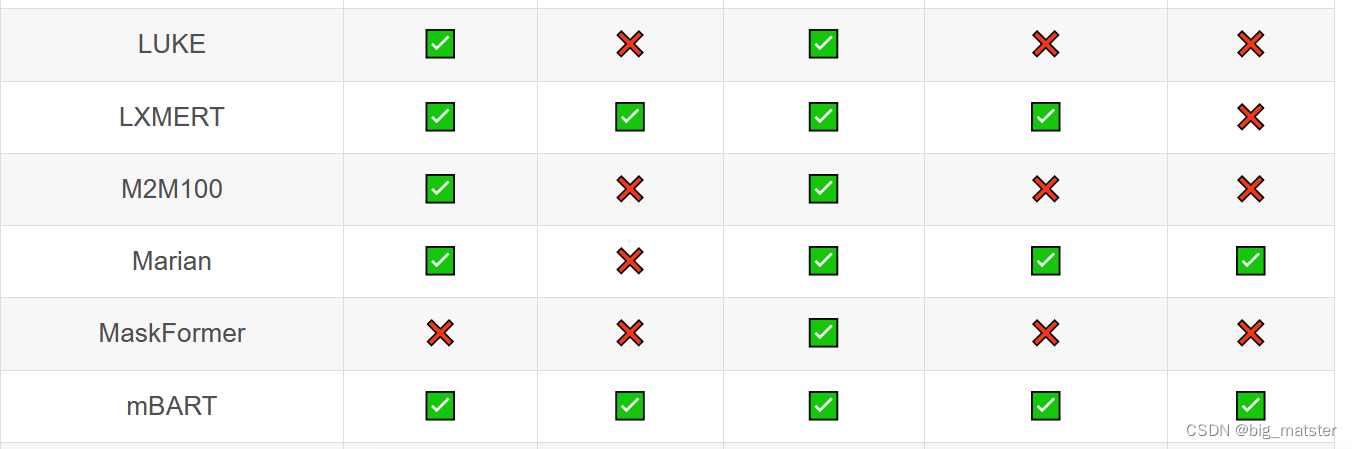
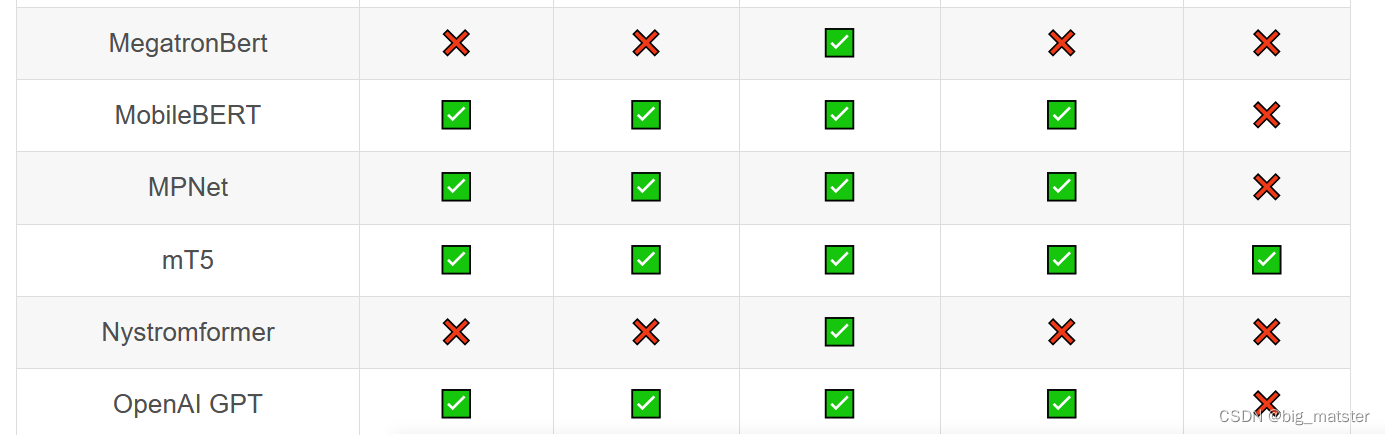
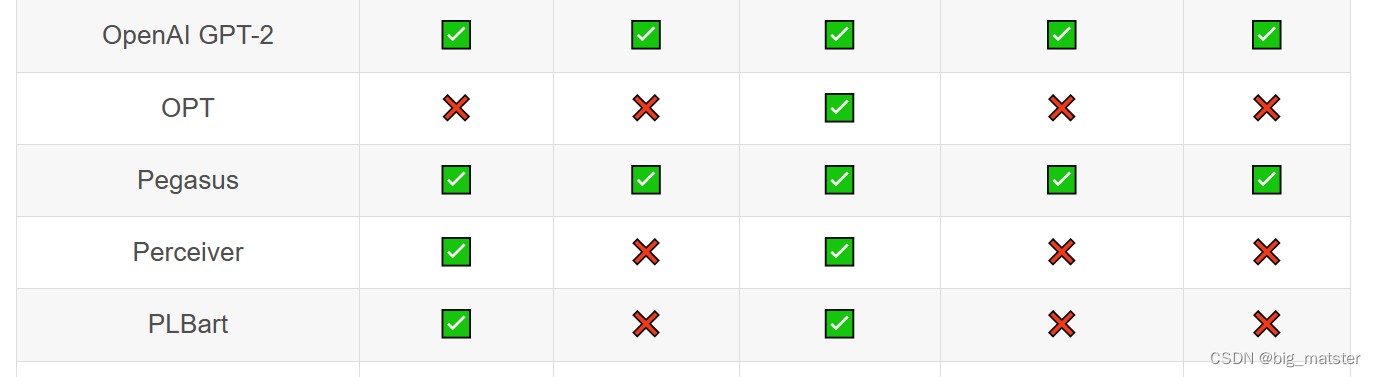
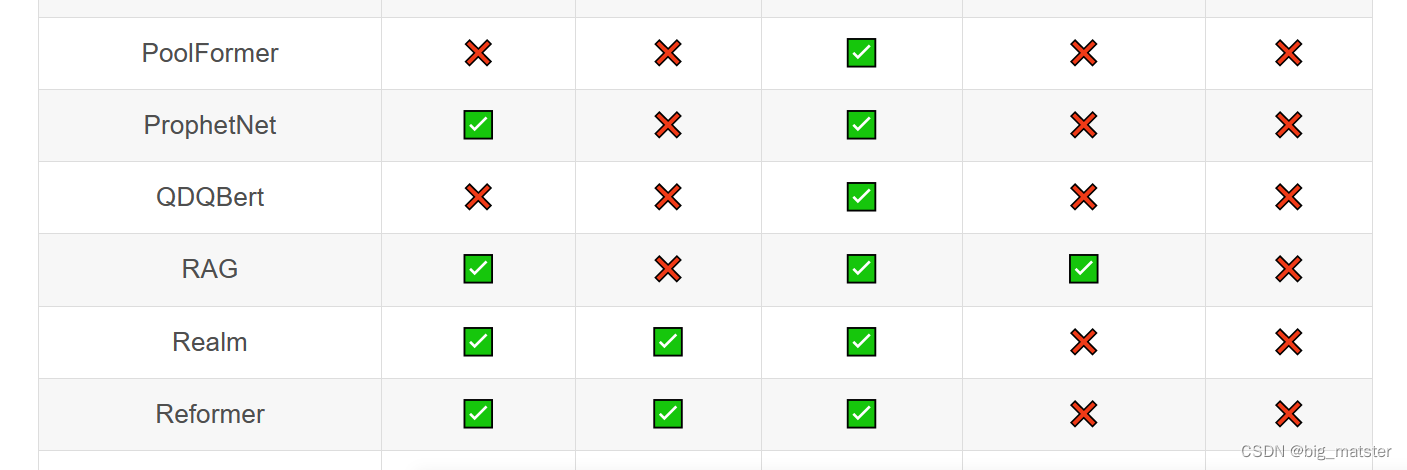
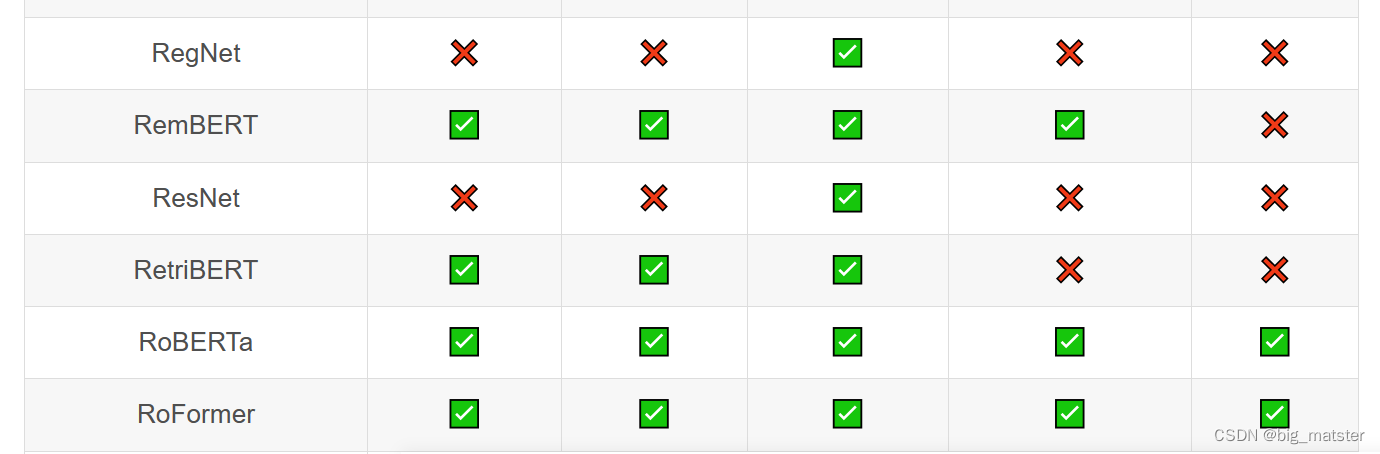
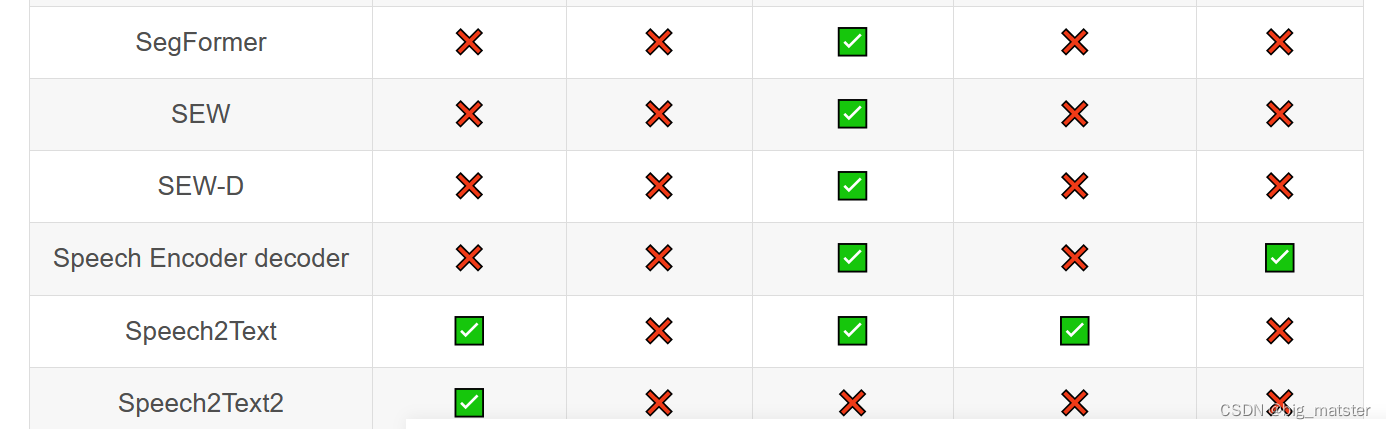
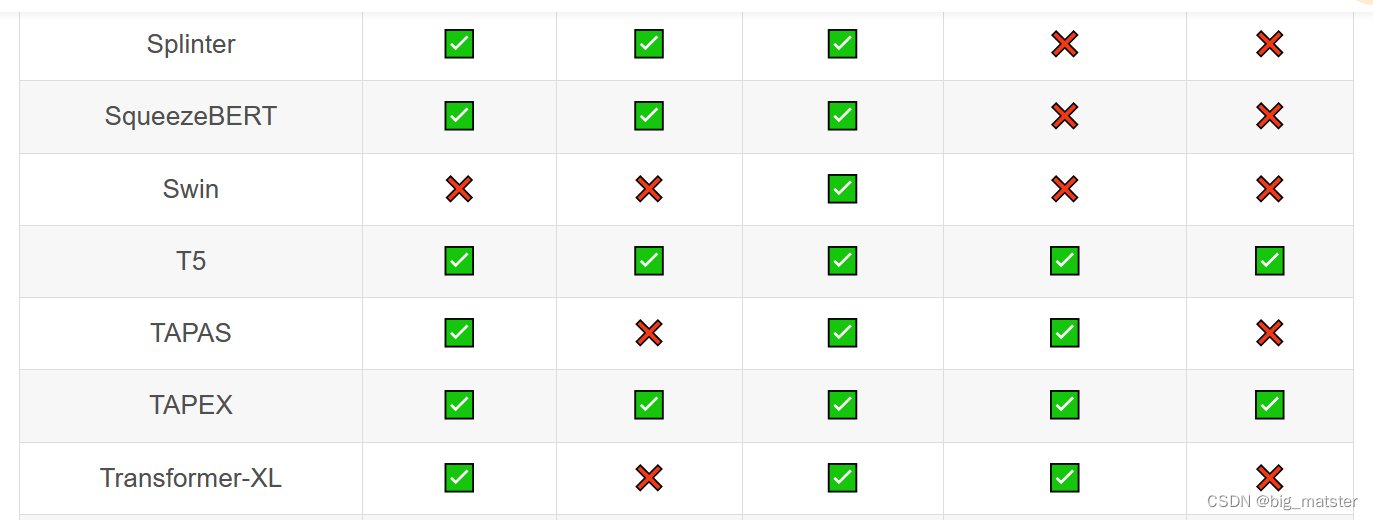
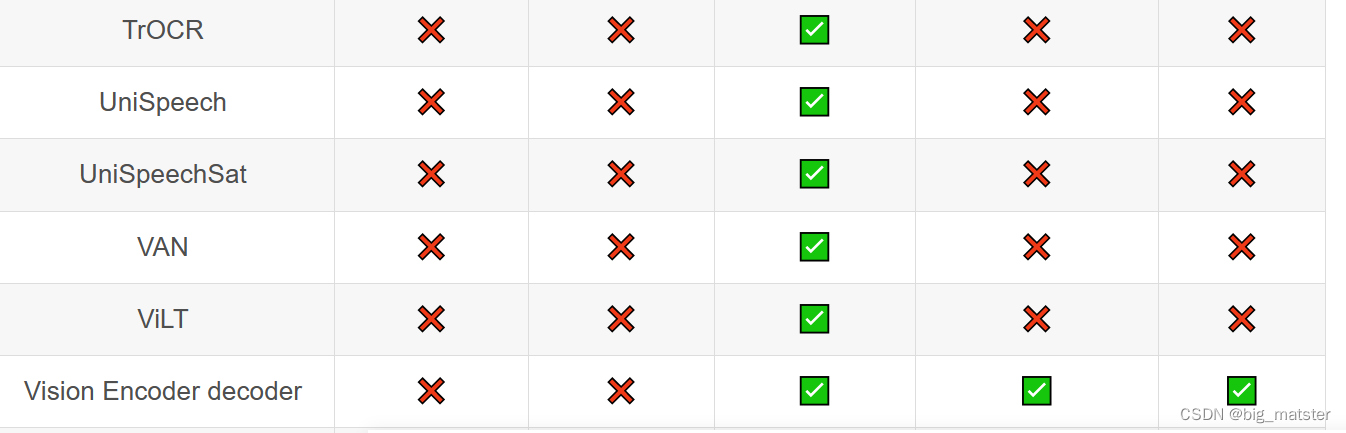
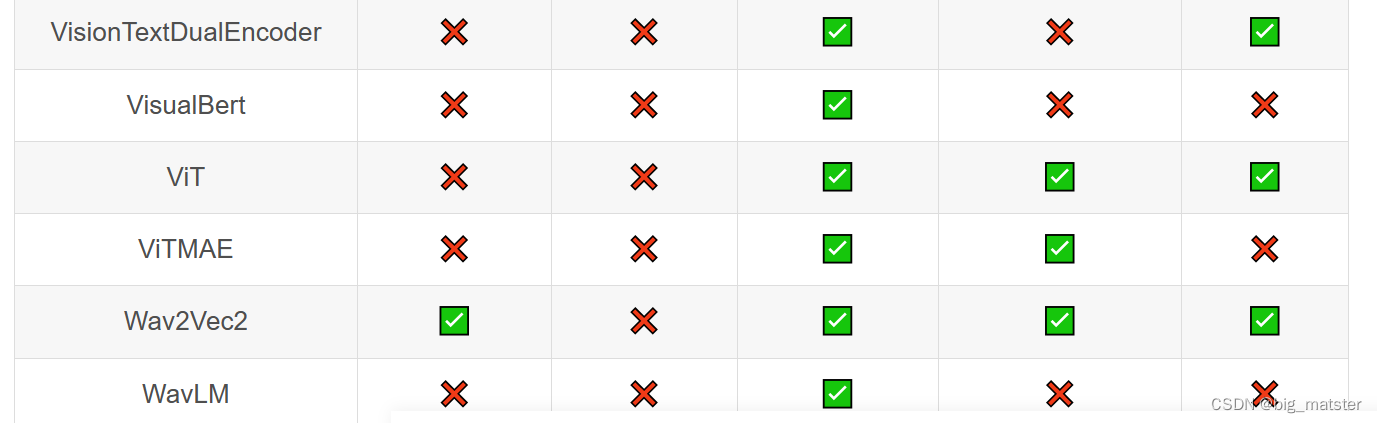
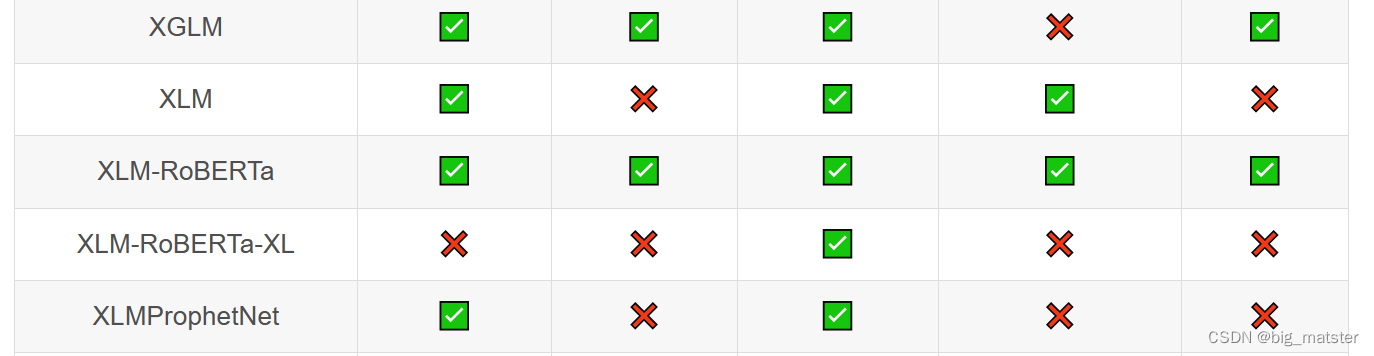

注意:Tokenizer slow:使用 Python 实现 tokenization 过程。Tokenizer fast:基于 Rust 库 Tokenizers 进行实现。
Pipeline
pipeline() 作用就是使用预训练模型进行推断,它支持从这里下载所有模型
pipeline() 支持的任务类型
支持许多常见任务
- 文本
- 情感分析
- 文本生成
- 命名实体识别
- 问答系统
- 掩码恢复
- 文本摘要
- 机器翻译
- 特征提取
- 图像
- 图像分类
- 图像分割
- 目标检测
- 音频
- 音频分类
- 自动语音识别(ASR)
注意:可以在 Transformers 库的源码(查看 Transformers/pipelines/init.py 中的 SUPPORTED_TASKS 定义)中查看其支持的任务,不同版本支持的类型会存在差异。
pipeline使用
简单的使用
当我们需要进行一个情感分类任务时,我们可以直接使用如下代码:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("We are very happy to show you the 🤗 Transformers library.")
print(result)
将输出以下结果
的
的
额
将输出以下结果:
[{'label': 'POSITIVE', 'score': 0.9997795224189758}]
上面的代码中 p i p e l i n e ( " s e n t i m e n t − a n a l y s i s " ) pipeline("sentiment-analysis") pipeline("sentiment−analysis")将下载并缓存一个默认的情感分析预测训练模型和加载对应的 t o k e n i z e r tokenizer tokenizer,针对不同类型的任务,对应的参数名称可以查看pipelilne参数taskj的说明,不同类型的任务所下载的默认预训练模型可以在Transformer中的源码(查看 Transformers/pipelines/init.py 中的 SUPPORTED_TASKS 定义)中查看
当我们需要一次性推理多个句子时候,可以使用list形式作为参数传入:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
results = classifier(["We are very happy to show you the 🤗 Transformers library.",
"We hope you don't hate it."])
print(results)
将输出以下结果:
[{'label': 'POSITIVE', 'score': 0.9997795224189758},
{'label': 'NEGATIVE', 'score': 0.5308570265769958}]
选择模型
上面部分,在进行推理时**,使用的是对应任务的默认模型。但是有时候我们希望使用指定的模型**,可以通过指定 pipeline() 的参数 model 来实现。
第一种方法
from transformers import pipeline
classifier = pipeline("sentiment-analysis",
model="IDEA-CCNL/Erlangshen-Roberta-110M-Sentiment")
result = classifier("今天心情很好")
print(result)
将输出以下结果:
[{'label': 'Positive', 'score': 0.9374911785125732}]
第二种方法:(和上面的方法,加载的是相同的模型。不过这种方法可以使用本地模型进行推理。)
预测训练模型
预训练tokenizer
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
from transformers import pipeline
model_path = r"../pretrained_model/IDEA-CCNL(Erlangshen-Roberta-110M-Sentiment)"
model = AutoModelForSequenceClassification.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
result = classifier("今天心情很好")
print(result)
将输出以下结果:
[{‘label’: ‘Positive’, ‘score’: 0.9374911785125732}]
``
总结:上面部分介绍了使用 pipeline() 对文本分类任务的推断的方法。针对文本其他类型任务、图像和音频的任务,使用方法基本一致,详细可参照 这里。
加载模型
我们将介绍加载模型的一些方法:
随机初始化模型权值
使用预训练权值初始化模型权值
预处理
模型本身无法理解原始文本,图像或者音频的,所以需要先将数据转换成模型可以接受的形式,然后再传入模型中。
NLP Auto Tokenizer
处理文本数据的主要工具是
t
o
k
e
n
i
z
e
r
tokenizer
tokenizer,首先
t
o
k
e
n
i
z
e
r
tokenizer
tokenizer会根据一组规则将文本拆分成token,然后将这些token转换成数值(根据词表,即 vocab),这些数值会被构建成张量并作为模型的输入,模型所需要的其他输入也是有
t
o
k
e
n
i
z
e
r
tokenizer
tokenizer添加的。
当我们使用预训练模型时候,一定要使用对应的预训练
t
o
k
e
n
i
z
e
r
tokenizer
tokenizer,只有这样,才能确保文本以预训练语料库相同的方式进行切割,并使用相同对应的索引
t
o
k
e
n
token
token索引,即
V
o
c
a
b
Vocab
Vocab
Tokenizer
使用 AutoTokenizer.from_pretrained() 加载一个预训练 tokenizer,并将文本传入 tokenizer:
from transformers import AutoTokenizer
model_path = r"../pretrained_model/IDEA-CCNL(Erlangshen-Roberta-110M-Sentiment)"
tokenizer = AutoTokenizer.from_pretrained(model_path)
encoded_input = tokenizer("今天心情很好")
prin**加粗样式**t(encoded_input)
**加粗样式**
并输出以下结果:
{'input_ids': [101, 791, 1921, 1921, 3698, 4696, 1962, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
可以看到上面输出包含三个部分:
- input_ids:对应于句子中每个 token 的索引。
- token_type_ids:当存在多个序列时,标识 token 属于那个序列。
- attention_mask:表明对应的 token 是否需要被注意(1 表示需要被注意,0 表示不需要被注意。涉及到注意力机制)
我们还可以i使用 t o k e n i z e r tokenizer tokenizer将 input_ids 解码为原始输入:
decoded_input = tokenizer.decode(encoded_input["input_ids"])
print(decoded_input)
将输出以下结果:
[CLS] 今 天 天 气 真 好 [SEP]
我们可以看到上面的输出,相比原始文本多了 [CLS] 和 [SEP],它们是在 BERT 等模型中添加一些特殊 token。
如果需要同时处理多个句子,可以将多个文本以list形式输入到
t
o
k
e
n
i
z
e
r
tokenizer
tokenizer中。
填充 Pad
当我们处理一批句子时,它的长度并不总是相同的,但是模型的输入需要具有统一的形状
s
h
a
p
e
shape
shape,填充是实现此需求的一种策略,即为 token 较少的句子添加特殊的填充 token。
给 tokenizer() 传入参数 padding=True:
batch_sentences = ["今天天气真好",
"今天天气真好,适合出游"]
encoded_inputs = tokenizer(batch_sentences, padding=True)
print(encoded_inputs)
将输出以下结果:
{'input_ids':
[[101, 791, 1921, 1921, 3698, 4696, 1962, 102, 0, 0, 0, 0, 0],
[101, 791, 1921, 1921, 3698, 4696, 1962, 8024, 6844, 1394, 1139, 3952, 102]], 'token_type_ids':
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask':
[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
可以看到 tokenizer 使用 0 对第一个句子进行了一些填充。
截断(Truncation)
当句子太短时候,可以采用填充策略,但是有时候,句子可能太长,模型无法处理,在这种情况下,可以将句子进行截断。
给 tokenizer() 传入参数 truncation=True 即可实现
如果想了解 tokenizer() 中更多关于参数 padding 和 truncation 的信息,可以参照 这里
构建张量(Build tensors)
最终,如果我们想要 tokenizer 返回传入模型中的实际张量。需要设置参数 return_tensors。如果是传入 PyTorch 模型,将其设置为 pt;如果是传入 TensorFlow 模型,将其设置为 tf。
batch_sentences = ["今天天气真好",
"今天天气真好,适合出游"]
encoded_inputs = tokenizer(batch_sentences,
padding=True, truncation=True,
return_tensors="pt")
print(encoded_inputs)
将输出以下结果:
{'input_ids':
tensor([[ 101, 791, 1921, 1921, 3698, 4696, 1962, 102, 0, 0, 0, 0,
0],
[ 101, 791, 1921, 1921, 3698, 4696, 1962, 8024, 6844, 1394, 1139, 3952,
102]]),
'token_type_ids':
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask':
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
其他
针对音频数据,预处理包括重采样、特征提取、填充和截断。这对图像数据,预处理主要包括:特征提取和数据增强。针对多模态数据,不同类型的数据使用前面介绍的对应预处理方法详细请参照,虽然每种数据预处理方法不完全一样,但是最的目的都是一致的,将原始数据转换为模型可以接受的形式。
微调预训练模型
下面将以一个文本多分类的例子,简单介绍如何使用我们自己的数据训练一个分类模型
准备数据
在微调预训练模型之前,我们需要先准备数据,我们可以使用 D a t a s e t Dataset Dataset库,的load_dataset加载数据集。
from datasets import load_dataset
# 第 1 步:准备数据
# 从文件中获取原始数据
datasets = load_dataset(f'./my_dataset.py')
# 输出训练集中的第一条数据
print(datasets["train"][0])
在这里需要注意一下,因为我们是使用自己的数据进行模型训练,所以上面 load_dataset 传入的参数是一个 py 文件的路径。这个 py 文件按照 Datasets 库的规则读取文件并返回训练数据,如果想了解更多信息,可以参照
如果我们只是想简单的学习Transformer库的使用**,可以使用 Datasets 这个库预置的一些数据集,这个时候 load_dataset 传入的参数是一些字符串**(比如,load_dataset(“imdb”)),然后会自动下载对应数据集。
预处理
在将数据喂给模型之前,需要将数据进行预处理(Tokenize、填充、截断等)。
from transformers import AutoTokenizer
# 第 2 步:预处理数据
# 2.1 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(configure["model_path"])
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 2.2 得到经过 tokenization 后的数据
tokenized_datasets = datasets.map(tokenize_function, batched=True)
print(tokenized_datasets["train"][0])
首先,加载tokenizer, 使用 d a t a s e t s . m a p ( ) datasets.map() datasets.map()生成经过预处理后的数据,因为数据经过 t o k e n i z e r ( ) tokenizer() tokenizer(),处理后不再是dataset格式,所以需要使用 datasets.map() 进行处理
加载模型
在前面的部分,已经介绍过模型加载的方法,可以使用 AutoModelXXX.from_pretrained 加载模型:
from transformers import AutoModelForSequenceClassification
# 第 3 步:加载模型
classification_model = AutoModelForSequenceClassification.from_pretrained(
configure["model_path"], num_labels=get_num_labels())
与前面部分不同的地方在于:上面的代码中有一个 num_labels 参数,需要给这个参数传入我们的数据集中的类别数量。
设定度量指标
在模型的训练过程中,我们希望能够输出模型的性能指标:比如准确率、精确率、召回率、F1 值等)以便了解模型的训练情况.们可以通过 Datasets 库提供的 load_metric() 来实现。下面的代码中实现了准确率计算:
import numpy as np
from datasets import load_metric
# 第 4 步:设定度量指标
metric = load_metric("./accuracy.py")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
设置训练超参数
在进行模型训练时候,还需要设置一些超参数,Transformers 库提供了 TrainingArguments 类
from transformers import TrainingArguments
# 第 5 步:设置训练超参数
training_args = TrainingArguments(output_dir=configure["output_dir"],
evaluation_strategy="epoch")
在上面的代码中,我们设置了两个参数**:output_dir 指定保存模型的输出路径;evaluation_strategy 决定什么时候对模型进行评估,**设置的参数 epoch 表明每训练完一个 epoch 后进行一次评估,评估内容即上一步设定的度量指标。
训练和保存模型
经过前面一系列的步骤后,我们终于可以开始进行模型训练了。Transformers 库提供了 Trainer 类,可以很简单方便地进行模型训练。首先,创建一个 Trainer,然后调用 train() 函数,就开始进行模型训练了。当模型训练完毕后,调用 save_model() 保存模型。
# 第 6 步:开始训练模型
trainer = Trainer(model=classification_model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
compute_metrics=compute_metrics)
trainer.train()
# 保存模型
trainer.save_model()
总结
慢慢的会用transformer库编写自己的代码,将其全部都搞定都行啦的样子与打算。
经验
- 有质疑的研读论文
- 讲论文进行分类。