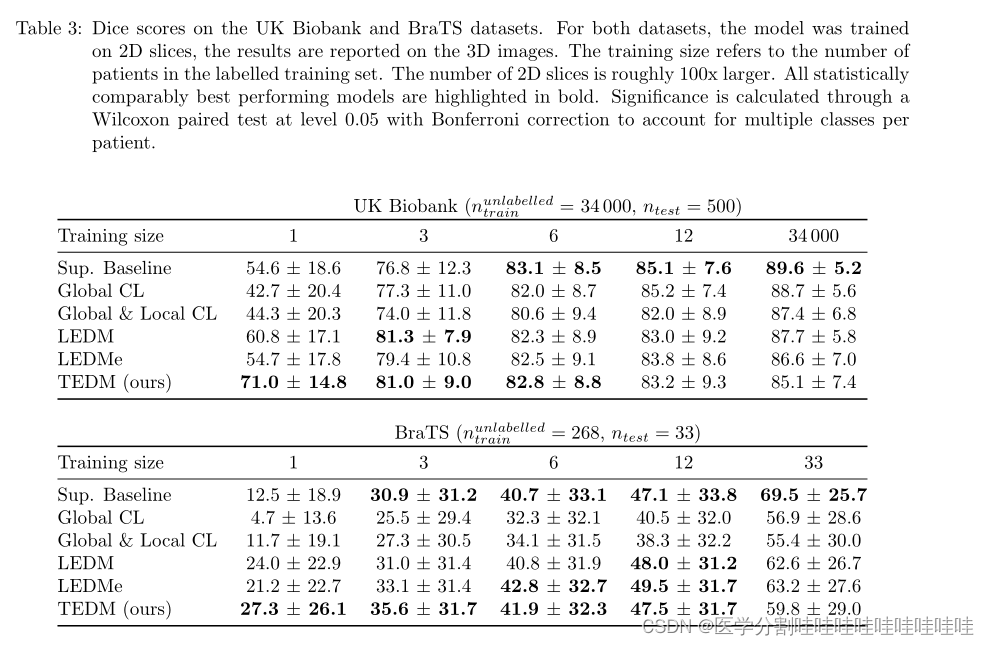
背景
短视频格式、内容与长视频不同,需要引入新的质量评估方法。作者构建了一个新的用于质量评估的数据集,提出了新的质量评估方法。
如下图所示,短视频有不同的格式、有模糊、噪声、编码等各种畸变。

KVQ 数据集
通过快手平台选择多样化的短视频样本,提取多个质量特征,并进行严格的数据清洗和一致性评分,构建了一个可靠的短视频质量评估数据集。先选600个数据,再对600个数据做处理(减小畸变、局部or全局、转码)获取3600个视频。
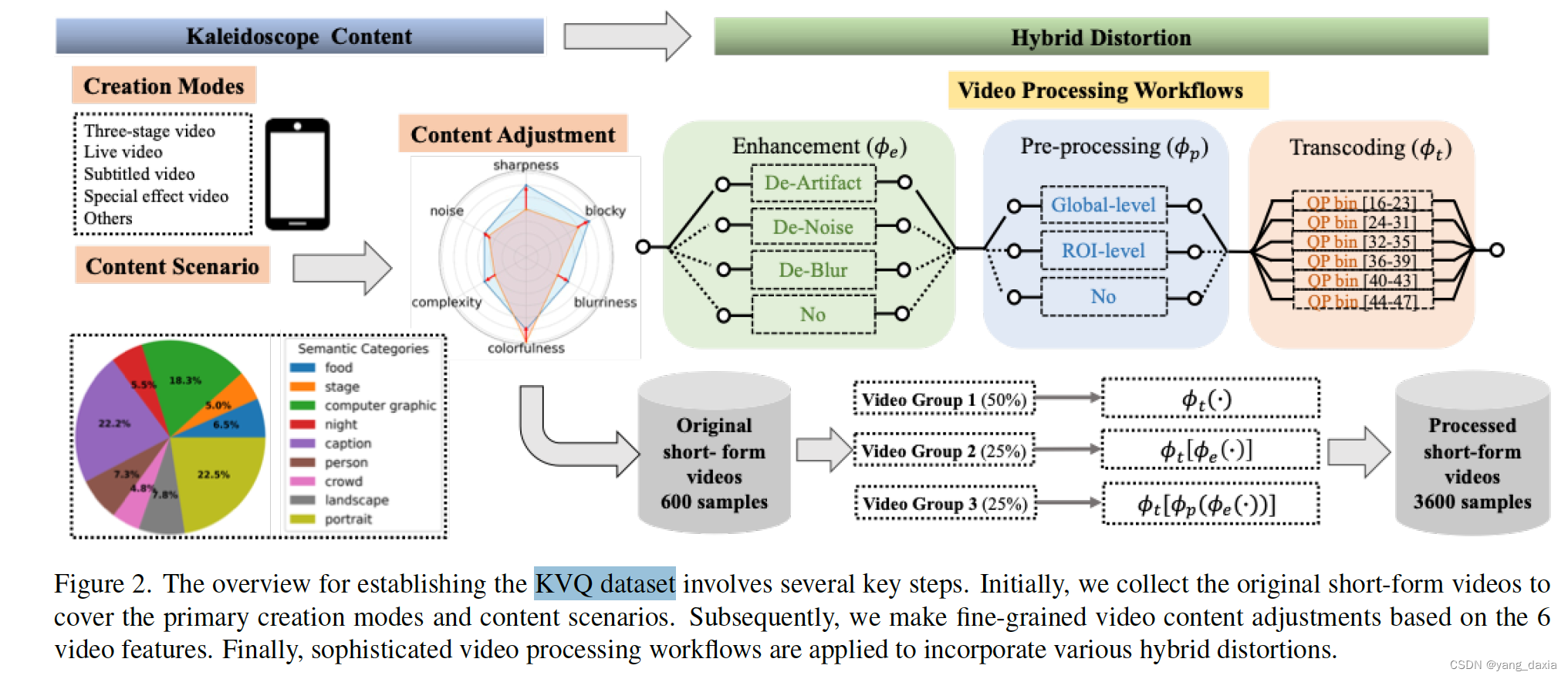
视频选择
- 视频类型:选择了涵盖多种内容类型的视频,包括但不限于娱乐、教育、新闻等,以保证数据集的多样性。
- 视频质量:视频的质量从高到低不等,包含了清晰度高、存在模糊、块效应、噪声等不同质量特征的视频,确保能够全面评估不同质量水平的视频。
特征提取
- 锐度:测量视频的清晰度,评价其细节表现能力。
- 块效应:检测视频压缩后出现的方块伪影。
- 模糊度:评价视频的模糊程度,检测失焦或运动模糊。
- 色彩度:评估视频色彩的饱和度和鲜艳度。
- 复杂度:分析视频内容的复杂性,包括场景变化、物体运动等。
- 噪声:检测视频中的噪声水平,评价其干扰程度。
数据清洗
为了确保评分数据的可靠性,进行了严格的数据清洗过程:
1)观测者评分一致性:计算每个观测者评分与其他人的平均评分之间的相关性(SROCC和PLCC)。如果相关性低于0.7,则重新训练或排除该观测者的数据。
2)评分分布:计算评分的峰度以评估其正态分布情况。对于偏离正态分布的评分进行进一步审查和调整。
3)评分标准
制定了详细的视频质量评分指南,评分范围为1到5:
- 1分:严重失真,难以观看。
- 2分:明显失真,但仍可理解内容。
- 3分:中等质量,有一定的失真但不严重。
- 4分:高质量,只有轻微的失真。
- 5分:非常高的质量,几乎没有失真。
4)评分过程
观测者选择:从专业评审员中选出一组观测者,对每个视频进行评分。
评分环境:确保在统一的环境中进行评分,以减少外部因素的干扰。
评分记录:记录每个视频的评分,并进行统计分析,得出最终的质量评分。
KSVQE质量评估器
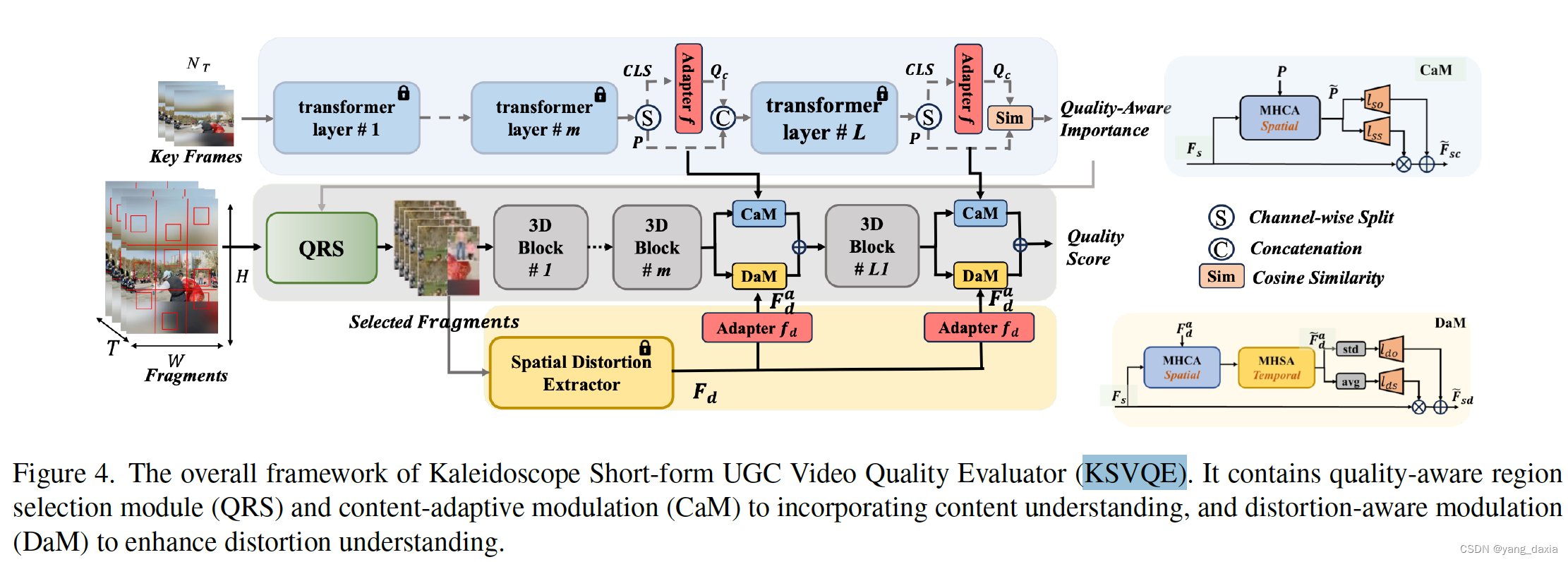
视频质量评估器(KSVQE),利用大型视觉语言模型(如CLIP)的内容理解能力和失真理解模块来识别质量的语义并区分失真。输入使用fragment,backbone为3D-Swin Transformer
方法细节:
内容理解:通过预训练的大型视觉语言模型CLIP,引入可学习的“质量适配器”来识别与质量相关的区域,并采用“内容自适应调制”(CaM)来感知每个区域的内容语义。
失真理解与调制:使用预训练的CONTRIQUE模型作为空间失真提取器,并设计了“失真感知模块”(DaM)通过多头部交叉注意力(MHCA)和多头自注意力(MHSA)来融合失真先验。
内容理解
输入关键帧,使用clip理解语义信息。不过需要在clip最后两层加一个映射,将图像语义空间映射到质量空间。这部分映射会输入到CaM模块中,如图上层所示。最后也会输出一个分数map,该部分会作用于QRS模块
QRS
通过clip的语义理解输出,对图片中的topk个区域进行选择,获取质量有问题的区间。
Cam
通过多头部交叉注意力(MHCA)将CLIP的特征与3D Swin Transformer的特征相结合,以便更好地理解每个片段的内容语义,并根据内容的不同调整质量评估。
失真理解
使用预训练的CONTRIQUE模型作为空间失真提取器,然后加了一个adapter映射到KQV数据集的分布。
Dam
通过多头部交叉注意力(MHCA)和多头自注意力(MHSA)来提取空间和时间的注意力特征
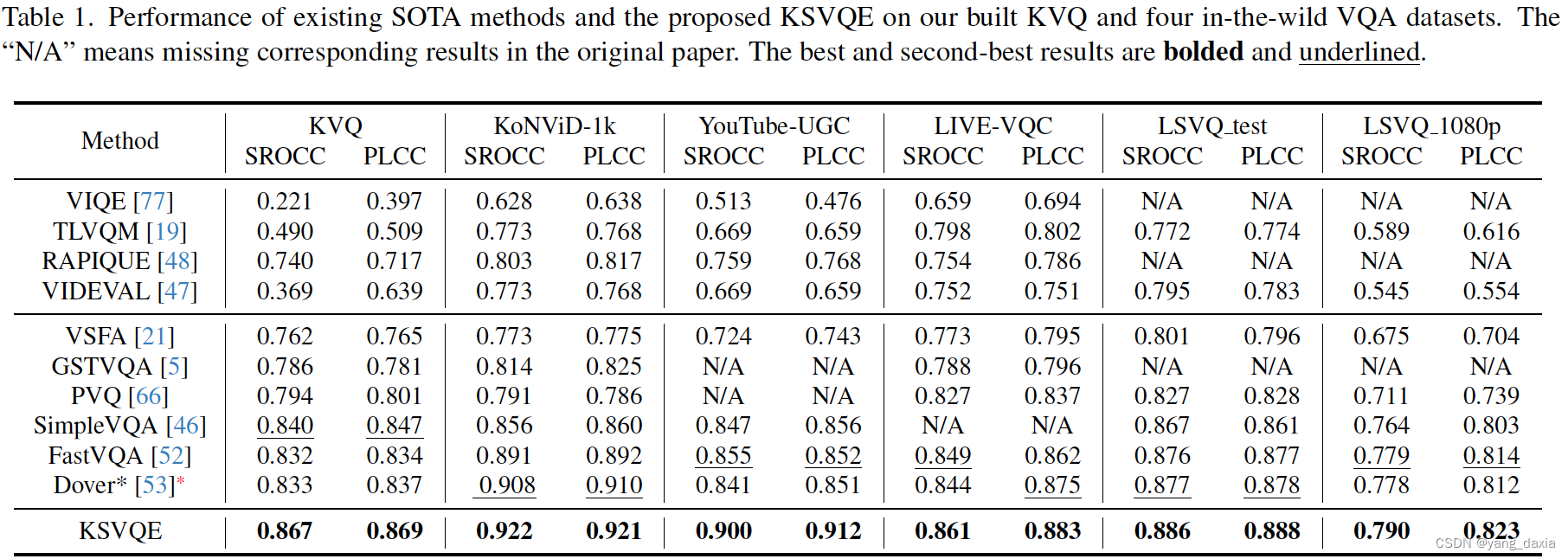
实验结果:
KSVQE在KVQ数据库和流行的VQA数据库上的有效性得到了实验验证。与当前最佳方法Dover相比,KSVQE在PLCC和SROCC上分别提高了0.032和0.034。
贡献:
- 建立了首个大规模的KVQ数据库,提供了可靠的绝对质量标签和部分排名标签。
- 提出了KSVQE评估器,解决了KVQ中的两个主要挑战:由多种创作/生成模式和万花筒内容场景引起的未识别质量决定区域/内容,以及由复杂处理流程和非专业视频拍摄引起的难以区分的失真。
- 通过基于预训练的大型视觉语言模型CLIP提出QRS和CaM,增强了KSVQE的内容理解能力,并通过设计DaM增强了失真理解能力。