时间步合成扩散模型的鲁棒半监督分割
摘要
医学图像分割是一项具有挑战性的任务,由于许多数据集的大小和注释的限制,使得分割更加困难。消噪扩散概率模型(DDPM)最近在模拟自然图像的分布方面显示出前景,并成功地应用于各种医学成像任务。这项工作的重点是使用扩散模型进行半监督图像分割,特别是处理域泛化。首先,我们证明了较小的扩散步长产生的潜在表征对下游任务比较大步长更鲁棒。其次,我们利用这一见解提出了一种改进的相似方案,该方案利用信息密集的小步骤和大步骤的正则化效应来生成预测。我们的模型在领域转移设置中表现出明显更好的性能,同时在领域内保持竞争性能。总的来说,这项工作突出了ddpm在半监督医学图像分割方面的潜力,并提供了在域移位下优化其性能的见解。
1 介绍
去噪扩散概率模型(DDPM) (Sohl-Dickstein等,2015;Ho等人,2020)最近成为自然图像分布建模的一种有前途的方法,在样本真实感和多样性方面优于其他方法。最近,DDPM也成功地应用于各种医学成像任务,如合成图像生成(Kim and Ye, 2022),图像重建(Xie and Li, 2022;Peng et al ., 2022),异常检测(Wolleb et al ., 2022;Pinaya等人,2022),诊断(Aviles-Rivero等人,2022)和分割(Wolleb等人,2022)。
图像分割在医学成像中至关重要,需要准确有效的方法来支持诊断、治疗计划和疾病监测。然而,医学成像数据集通常规模有限,可能缺乏足够的注释,这使得训练准确的分割模型具有挑战性。此外,由于采集参数、扫描仪类型和患者人口统计数据的差异,医学成像数据具有高度可变性的特点。这种现象,也被称为领域转移,对应用于新数据集的分割模型的泛化提出了重大挑战,导致临床环境中潜在的性能不佳。
最近对扩散模型的研究显示了半监督学习的有希望的结果(Baranchuk等人,2021;Deja等人,2023)基于瓶颈网络的发现,瓶颈网络的任务是学习从图像中去除噪声的反向过程,也学习了一种富有表现力的特征表示,可以有利于其他下游分析任务。已经提出了几种技术来利用中间扩散步骤来改善域内下游性能。然而,需要对这些设计选择对模型泛化的影响进行更多的研究。
我们的工作重点是后一个问题。
具体来说,我们研究了如何最优地利用扩散步骤来提高域移位下半监督图像分割的泛化。
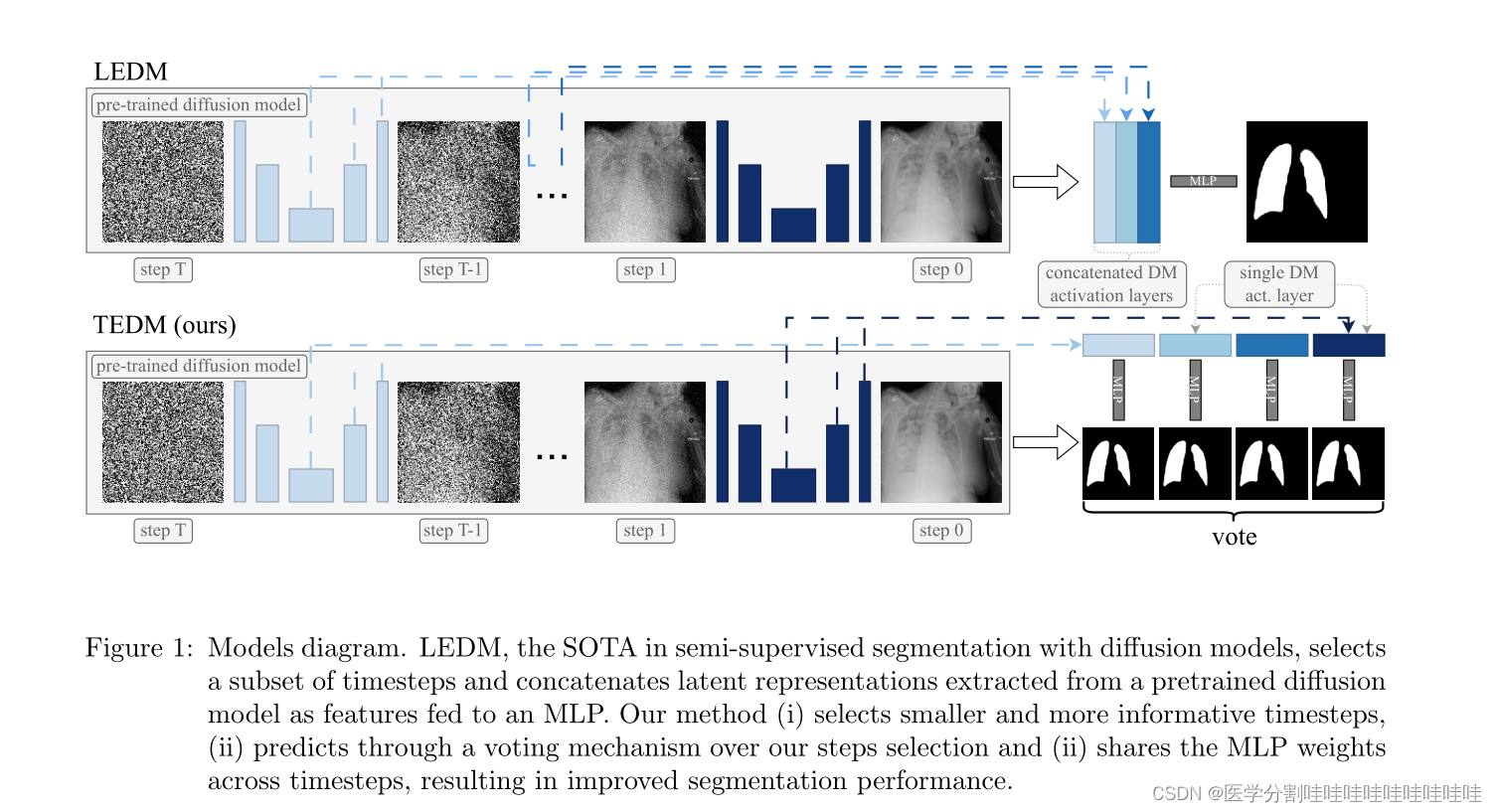
图1:模型图。LEDM是带有扩散模型的半监督分割中的SOTA,它选择一个时间步长子集,并将从预训练的扩散模型中提取的潜在表征连接起来作为特征馈入MLP。我们的方法(i)选择更小和更有信息量的时间步长,(ii)通过投票机制对我们的步骤选择进行预测,(ii)跨时间步长共享MLP权重,从而提高分割性能。
基于对不同成像方式和域转移的数据集的分析,我们的研究结果表明,使用五种不同的数据集,比现有的基线有了显著的改进。我们的主要发现可以总结如下:
①小的扩散步骤对模型泛化至关重要;
②通过步骤串联潜在表示来预测分割图可能会损害泛化;
③相反,通过(i)优化在测试时使用的时间步长,(ii)使用共享预测器从单个时间步长集成预测,以及(iii)在训练期间使用这些单个预测进行正则化,可以显著改善泛化。
2. 背景及相关工作
2.1. 扩散模型
扩散模型在机器学习社区中引起了极大的兴趣,因为它们具有有效地模拟复杂数据分布的卓越能力。扩散模型利用一系列简单的和可学习变换迭代扩散噪声并从目标分布生成样本。
正式地,DDPM的工作方式如下。给定数据分布p(x0)和正向过程:
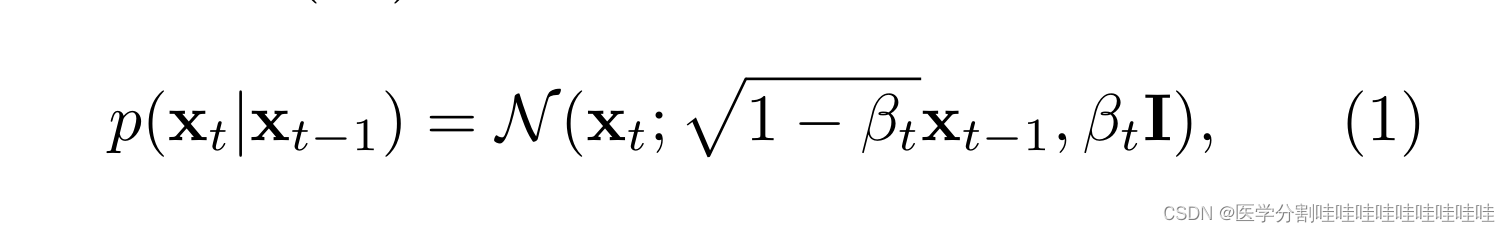
其中βt∈(0,1)为方差计划,t∈[0,t]为马尔可夫链时间步长,DDPM的目标是学习µθ(xt, t)和Σθ(xt, t),它们定义了逆向过程:
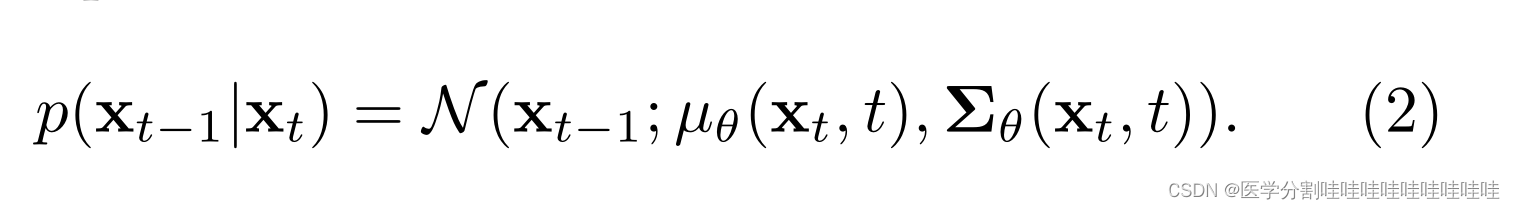
为此,Ho等人(2020)固定方差Σθ(xt, t),将µθ(xt, t)作为噪声ϵθ(xt, t)的函数重新参数化。
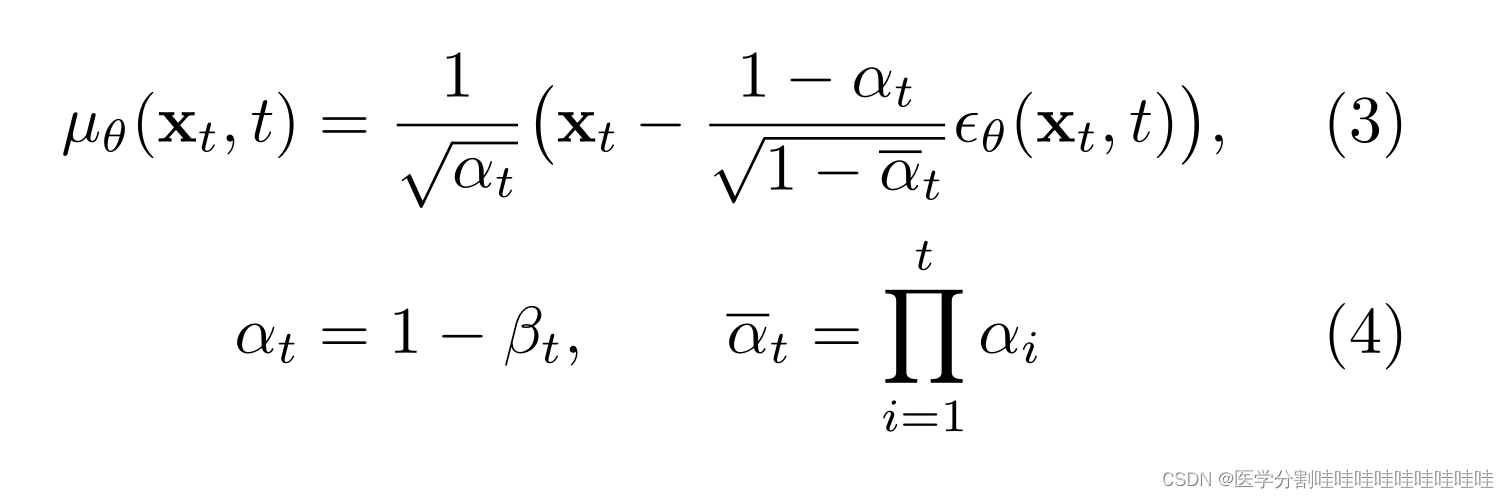
并设计一个基于unet的神经网络架构(Ronneberger et al, 2015)
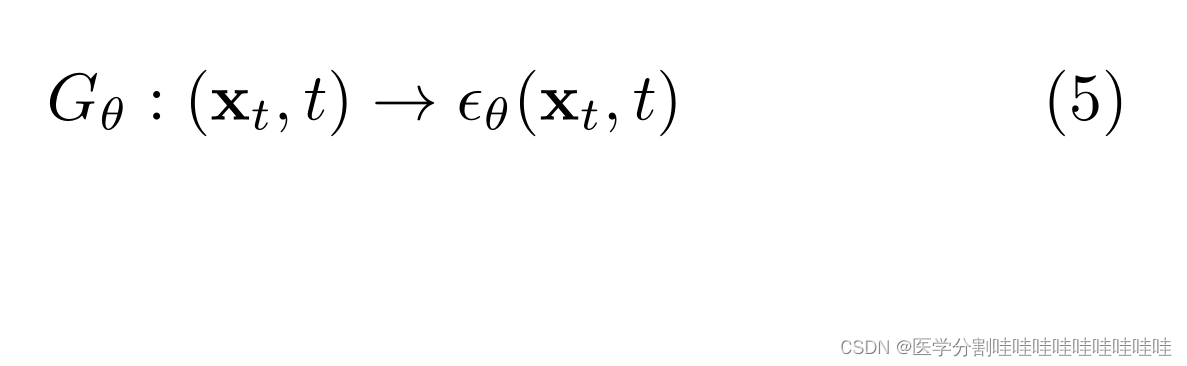
为了学习识别噪音。通过注入噪声和预测噪声之间的交叉熵来训练UNet。
2.2. 标签高效图像分割的扩散模型
Baranchuk等人(2021)将扩散模型应用于半监督分割,方法是在未标记的图像上使用预训练的扩散模型,从UNet的中间层提取潜在表示,并使用它们来训练像素分类器。更具体地说,他们的标签有效扩散模型(LEDM)通过选择一组步长t∈S∧{0,…,提取由预训练的UNet扩散模型生成的潜在表示。T},传递有噪声的输入
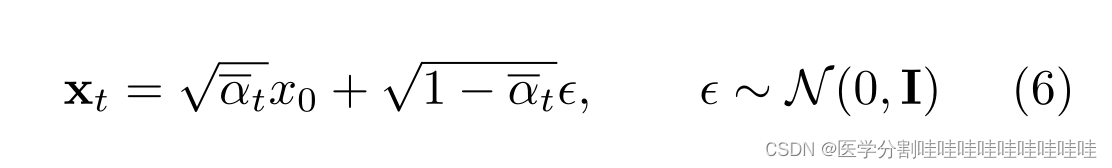
通过UNet。得到的激活图zt∈Rc×h×w然后通过双线性插值上采样到输入大小,并连接到特征图Z∈R(|S|×c)×H×W中。最后,每个逐点预测由轻量级多层感知的集合独立执行
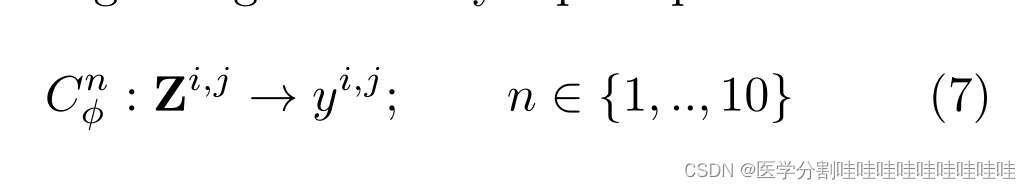
用交叉熵损失训练。作者将扩散步长S ={50,150,250}连接起来,形成这些预测器的输入。
类似地,Deja等人(2023)也使用预训练扩散模型的潜在表示进行分类任务。特别是,他们建议使用所有中间时间步的分类器预测来规范扩散模型的训练。然而,在测试时,他们只使用最后一个扩散步骤t = 1来生成预测。
3. 论扩散步骤对领域推广的重要性
先前的研究结果表明,较大步长中的潜在表征包含粗糙信息,随着扩散步长接近目标数据分布,这些信息变得更加颗粒化(Baranchuk等人,2021;Deja et al, 2023)。在这里,我们感兴趣的是理解当训练数据集大小变化时,每个时间步s∈s中的信息财富如何有助于模型泛化。
我们在特定时间步长t ={1,10,25,50,200,400,600和800}提取的潜在表示上训练基于Ridge逻辑回归的逐像素分类器,以分离每个时间步长的预测能力。我们将这些时间步进预测与LEDM和使用与DDPM骨干相同的UNet骨干的完全监督基线进行比较。
我们评估我们在胸部x线肺分割任务上的工作。胸部x光是临床实践中最常见的放射学检查之一,从解剖区域(如肺)自动提取特征可以帮助临床决策。此外,胸部x射线图像的几个公共数据集的可用性使我们能够在数据集特征发生变化的情况下研究方法的泛化能力。
根据之前在半监督医学图像分割方面的工作(Rosnati等人,2022),我们使用ChestX-ray8 (Wang等人,2017)(n=108k)作为未标记数据集,在T = 1000步上训练DDPM主干,并使用JSRT (Van Ginneken等人,2006)(n=247)标记数据集的子集进行训练(n=197)和验证(n=25)我们的方法。数据集分割、体系结构和代码可以在我们的代码存储库中获得1。
我们保留了剩余的JSRT样本(n=25)以及NIH (Tang等人,2019)(n=95)和Montgomery (Jaeger等人,2014)(n=138)标记的数据集用于最终测试。值得注意的是,NIH数据集是ChestX-ray8数据集的一个注释子集。
这种设置允许我们在以下数据上测试模型:(i)分类器的域内数据(JSRT), (ii)分类器的域外数据,但DDPM的域内数据(ChesX-ray8/NIH)和(iii)两者的域外数据(Montgomery)。
图2显示了在n ={197、49、24、12、6、3和1}个JSRT标记数据点上训练分割模型时的分步实验的Dice系数2,对应于训练数据集的{100、50、25、12、6、3、2和1}%。令人惊讶的是,LEDM并没有明显优于基线在一次设置域移位数据集(NIH, Montgomery)。这表明LEDM可能没有充分利用潜在的表征信息。其次,我们发现
在单个步骤t = 1上训练的预测器在统计上优于LEDM和小训练规模(NIH和Montgomery的1,3,6以及JSRT的一个数据点)的基线。此外,该预测器在所有其他训练数据集大小上都与基线和LEDM具有竞争力。
实验强调,从较小步骤获得的潜在表示比从较大步骤获得的潜在表示更强大,特别是对于领域泛化。特别是,LEDM步骤50、125和250不是分割的最佳选择,因为步长较小的单步方法在分布外数据集上表现更好。在下一节中,我们将研究在正确的选择下,集成不同步骤是否仍然优于单步骤方法的步骤。我们研究了几种集成这些步骤的方法及其对模型泛化的影响。
4. 时间步积扩散模型
在本节中,我们表明,通过在预测和训练时间明智地结合适当的时间步长,可以显著改善低数据区域中基于扩散的分割模型的泛化。
我们假设,在前一节中观察到的LEDM缺乏泛化可以通过更多的模型正则化和减少需要学习的参数数量来缓解。
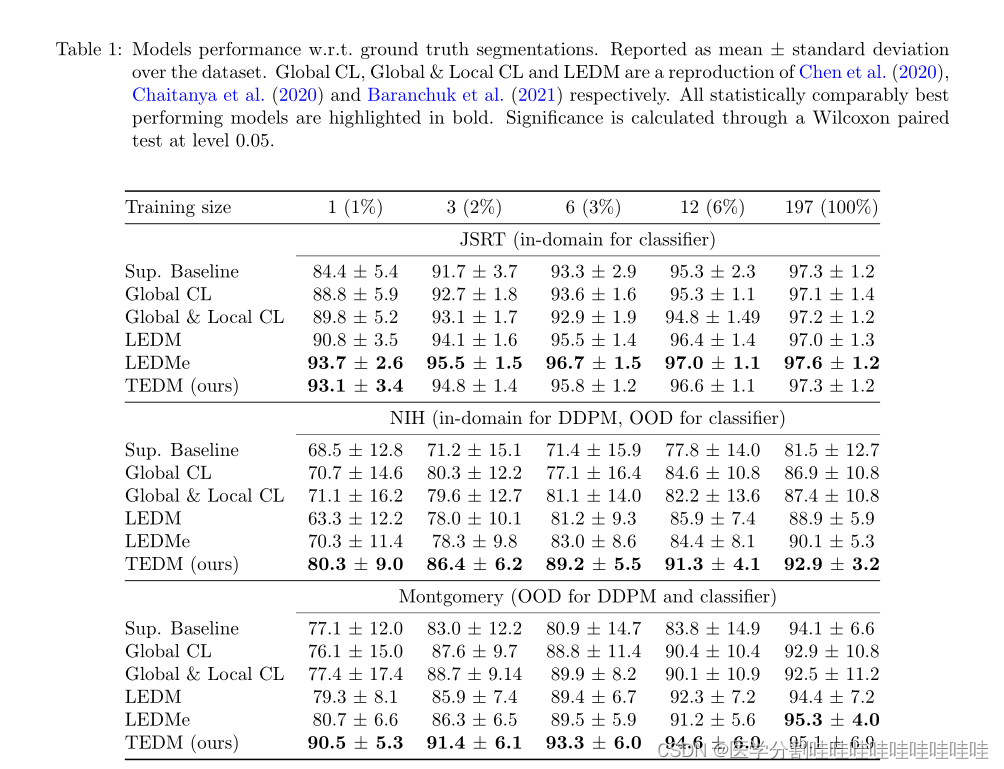
表1:模型性能w.r.t.地面真值分割。以数据集的平均值±标准差报告。Global CL、Global & Local CL和LEDM分别是Chen et al .(2020)、Chaitanya et al .(2020)和Baranchuk et al .(2021)的复制。所有在统计上表现最好的模型都以粗体突出显示。通过Wilcoxon配对检验在0.05水平上计算显著性。
事实上,目前将来自许多时间步长的特征连接到像素级MLP预测器的方法会导致过高的高维输入,从而导致复杂的预测器。为了解决这个问题,我们建议使用经过训练的共享MLP从所考虑的步骤的每个潜在表示生成预测图。
我们定义损失函数如下:
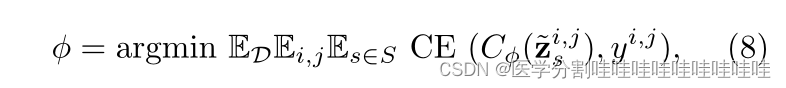
其中i,j是像素索引,yi,j是像素i的真实类,j, ~ zs是步骤s时扩散模型的上采样潜在表示zs, s是所使用的扩散步骤集,Cϕ是像素级MLP预测器,CE代表交叉熵,D是训练集。在测试时,我们使用投票机制集成各种预测图,以获得最终分割图。我们称这种技术为“时间步长集成”,并表明它产生了优越的性能。
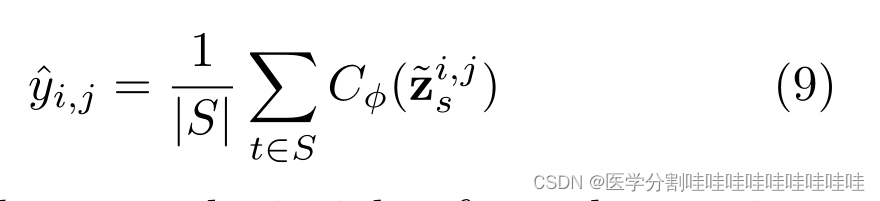
此外,我们利用前一节的见解,并结合扩散步骤S ={1、10、25、50、200、400、600和800}的预测。这种方法使我们受益于小步信息内容和大步正则化效果,不像LEDM,它只使用时间步长{50,125和250。为了更好地理解我们的模型和LEDM之间的区别,请参见图1。关于计算复杂性的讨论可以在附录B部分找到。
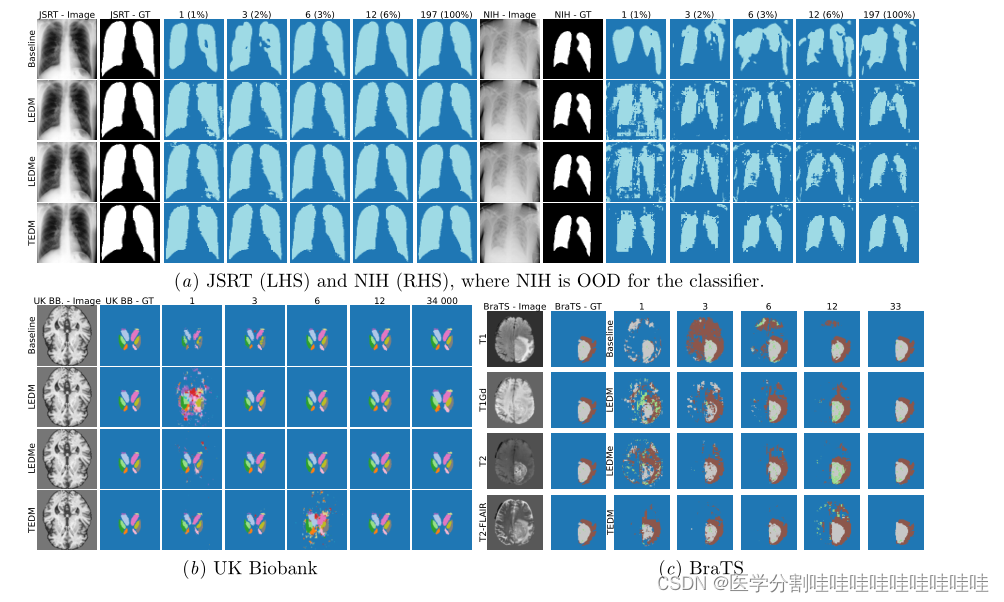
图3:分割示例。Col. 1和Col. 2是图像和地面真值分割。随后的列对应于用n个训练数据点训练的模型(见标题)。第1行对应基线结果,第2、3和4行分别对应LEDM、LEDMe和TEDM(我们的方法)。
5. 实验
我们在JSRT训练数据集的12%、6%、3%、2%和1%的不同百分比上进行了实验,以充分探索我们的半监督方法的潜力。此外,我们在100%的训练集上进行训练,以达到完备性。为了评估我们的时间步集成扩散模型(TEDM)的性能,我们将其与完全监督基线(见第3节)和LEDM进行比较。
LEDM和TEDM具有相同的MLP分类器体系结构。此外,我们将TEDM与另外两种使用对比学习(CL)的半监督方法进行了比较:“全局CL”(Chen等人,2020)和“局部和全局CL”(Chaitanya等人,2020)。
这两种方法都使用与基线和DDPM相同的主干体系结构进行训练。
为了研究我们的TEDM模型中每个组成部分的影响,我们进行了几次消融。
首先,我们将原始LEDM模型与另一个LEDM实例进行比较,这个LEDM实例是用我们的扩散步骤训练的,我们称之为leme。这使我们能够消除扩散步骤选择的影响。
其次,我们通过报告在测试时仅使用步骤1、10或25时的模型性能来测试投票机制。我们使用与第3节相同的评估程序。
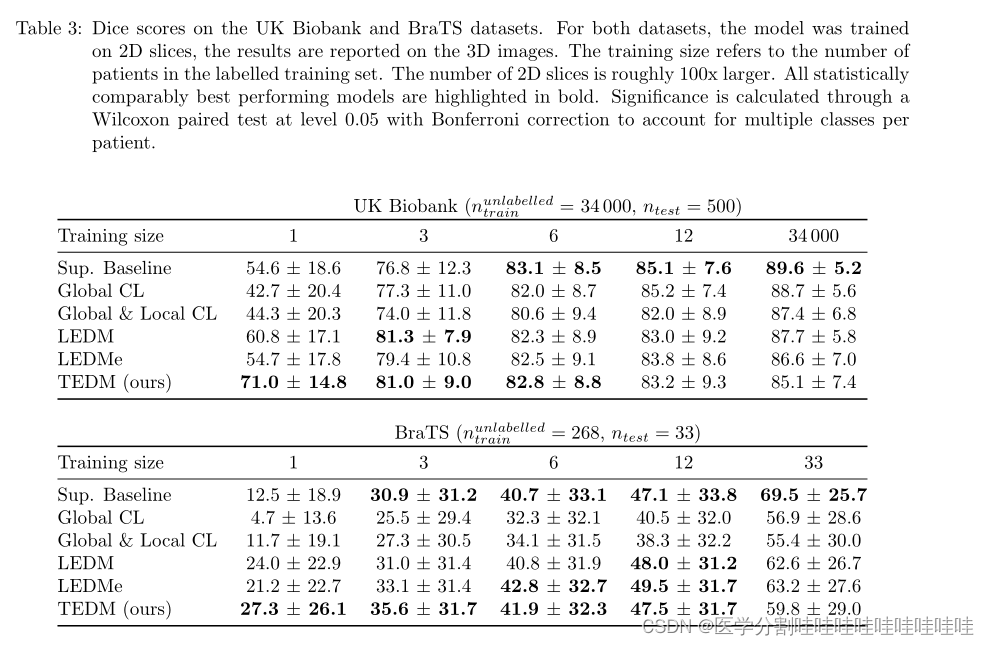
最后,为了测试TEDM方法的泛化性,我们将其应用于另外两个数据集:UK Biobank数据集和BraTS数据集(Menze et al, 2014;Bakas et al, 2017,2018)。在英国生物银行数据集中,我们在大脑MRI T1图像的二维切片中分割大脑结构。由于结构和背景之间的低强度变化,该数据集特别具有挑战性。BraTS数据集取脑肿瘤患者的脑MRI (T1, T1Gd, T2和T2- flair),我们将其分解成二维切片和片段。这个数据集更加困难,因为它需要分割不同形状和位置的项目。关于这两个数据集的实验过程的进一步细节可在附录A中找到。
表2:测试时间随时间步长集合的消融研究。每个“步骤i”实验在测试时只使用时间步骤i的预测。所有在统计上表现最好的模型都以粗体突出显示。通过Wilcoxon配对检验在0.05水平上计算显著性。

6. 结果
胸部x线和脑部MRI表现结果定量见表1和表3,定性见图3。烧蚀结果见表2。进一步的结果可以在附录c中找到。对于所有表,表现最好的模型和所有统计上等效的模型都以粗体突出显示其结果。
使用较小的步长可以提高域内和域外的性能。
在表1中,我们观察到,在所有情况下,选择较小的扩散步长产生了性能最好的模型:除了两个实验(Montgomery n = 12和NIH n = 12)之外,LEDMe在所有实验中都显著优于LEDM。此外,对于训练规模分别大于3和1的UK Biobank和BraTS数据集,LEDMe优于LEDM(见表3)。
连接潜在表示会损害低数据状态下的通用性。
除了n=197之外,在NIH和Montgomery数据集上,TEDM优于LEDMe(和LEDM)。
我们推断,在LEDM中使用的连接方法导致在标记训练集之外的域上泛化不良。此外,对于JSRT, TEDM的统计性能与LEDM相当,这表明它的泛化属性几乎没有域内性能成本。
时间步长的测试时间集成改进了单步预测的泛化。
表2显示,使用投票机制进行预测(在TEDM中使用)比使用最小步长更有效(在OOD情况下,TEDM优于竞争模型),这意味着不同的步骤产生聚焦于图像稍微不同方面的潜在表征。
TEDM在日益具有挑战性的分割任务中表现稳健。
表3显示,在少于12个数据点的所有情况下,TEDM在统计上优于或等于其竞争对手,这表明我们的方法在更具挑战性的域内低标记数据场景中仍然具有竞争力。
完全监督基线在领域内较难分割的任务中具有竞争力
我们的方法TEDM在非常小的数据集大小(表3中的1、2、3和6)上展示了出色的性能。
然而,对于更大的数据集(6名或更多患者),设计良好的基线模型比任何半监督模型都更有效。这一结果表明,尽管具有自监督预训练的半监督方法在为大型数据集提供特定任务性能方面可能存在局限性,但它们在改善小型数据集的结果方面具有很大的潜力。
7 结论
本文研究了不同扩散步骤对半监督分割模型性能和泛化的影响。我们在多个数据集上的综合实验表明,小的扩散步骤对领域泛化至关重要,只需要少量的训练样本就可以成为强大的像素预测器。此外,我们发现随时间步长集成分割映射显着提高了低数据状态下的模型泛化,同时在域内提供具有竞争力的性能。相反,连接潜在表示可能会损害逐像素分类器的泛化。我们提出的时间步合成扩散模型在胸部x射线上的优越性能证明了这些发现
肺分割和更具挑战性的任务,如大脑结构和肿瘤分割。我们的结果表明,跨不同步骤的潜在表示共享语义,并充当模型正则化器,比竞争方法产生更好的泛化。这一分析强调了彻底研究扩散模型中辅助任务的设计决策的重要性,例如时间步长选择和集成。这些决策会对模型的性能产生重大影响。
我们的发现提供了重要的新见解,并可能为利用强大的扩散模型进行医学成像任务的新方法的发展提供信息。在未来的工作中,应该将TEDM和类似方法的性能与新兴的基础模型技术进行比较,其中预训练比半监督方法执行的规模更大。在这里,扩散模型从大量未标记数据中有效捕获数据分布的能力有望克服医学图像分割中持续存在的数据稀缺性问题。
表3:骰子在UK Biobank和BraTS数据集上的得分。对于这两个数据集,模型都是在二维切片上训练的,结果报告在三维图像上。训练大小是指标记训练集中患者的数量。2D切片的数量大约是原来的100倍。所有在统计上表现最好的模型都以粗体突出显示。通过0.05水平的Wilcoxon配对检验和Bonferroni校正来计算显著性,以解释每个患者的多个类别。