5.6 推荐缓存服务
学习目标
- 目标
- 无
- 应用
- 无
5.6.1 待推荐结果的redis缓存
- 目的:对待推荐结果进行二级缓存,多级缓存减少数据库读取压力
- 步骤:
- 1、获取redis结果,进行判断
- 如果redis有,读取需要推荐的文章数量放回,并删除这些文章,并且放入推荐历史推荐结果中
- 如果redis当中不存在,则从wait_recommend中读取
- 如果wait_recommend中也没有,直接返回
- 如果wait_recommend有,从wait_recommend取出所有结果,定一个数量(如100篇)存入redis,剩下放回wait_recommend,不够100,全部放入redis,然后清空wait_recommend
- 从redis中拿出要推荐的文章结果,然后放入历史推荐结果中
- 1、获取redis结果,进行判断
增加一个缓存数据库
# 缓存在8号当中
cache_client = redis.StrictRedis(host=DefaultConfig.REDIS_HOST,
port=DefaultConfig.REDIS_PORT,
db=8,
decode_responses=True)
1、redis 8 号数据库读取
# 1、直接去redis拿取对应的键,如果为空
# 构造读redis的键
key = 'reco:{}:{}:art'.format(temp.user_id, temp.channel_id)
# 读取,删除,返回结果
pl = cache_client.pipeline()
# 拿督redis数据
res = cache_client.zrevrange(key, 0, temp.article_num - 1)
if res:
# 手动删除读取出来的缓存结果
pl.zrem(key, *res)
2、redis没有数据,进行wait_recommend读取,放入redis中
else:
# 如果没有redis缓存数据
# 删除键
cache_client.delete(key)
try:
# 1、# - 首先从wait_recommend中读取,没有直接返回空,进去正常召回流程
wait_cache = eval(hbu.get_table_row('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode()))
except Exception as e:
logger.warning("{} WARN read user_id:{} wait_recommend exception:{} not exist".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, e))
wait_cache = []
if not wait_cache:
return wait_cache
# 2、- 首先从wait_recommend中读取,有数据,读取出来放入自定义100个文章到redis当中,如有剩余放回到wait_recommend。小于自定义100,全部放入redis,wait_recommend直接清空
# - 直接取出被推荐的结果,记录一下到历史记录当中
# 假设是放入到redis当中为100个数据
if len(wait_cache) > 100:
logger.info(
"{} INFO reduce user_id:{} channel:{} wait_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
cache_redis = wait_cache[:100]
# 前100个数据放入redis
pl.zadd(key, dict(zip(cache_redis, range(len(cache_redis)))))
# 100个后面的数据,在放回wait_recommend
hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(wait_cache[100:]).encode())
else:
logger.info(
"{} INFO delete user_id:{} channel:{} wait_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 清空wait_recommend数据
hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str([]).encode())
# 所有不足100个数据,放入redis
pl.zadd(key, dict(zip(wait_cache, range(len(wait_cache)))))
res = cache_client.zrange(key, 0, temp.article_num - 1)
3、推荐出去的结果放入历史结果
# redis初始有无数据
pl.execute()
# 进行类型转换
res = list(map(int, res))
logger.info("{} INFO store user_id:{} channel:{} cache history data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 进行推荐出去,要做放入历史推荐结果当中
hbu.get_table_put('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(res).encode(),
timestamp=temp.time_stamp
)
return res
完整逻辑代码:
from server import cache_client
import logging
from datetime import datetime
logger = logging.getLogger('recommend')
def get_reco_from_cache(temp, hbu):
"""读取数据库缓存
redis: 存储在 8 号
"""
# 1、直接去redis拿取对应的键,如果为空
# 构造读redis的键
key = 'reco:{}:{}:art'.format(temp.user_id, temp.channel_id)
# 读取,删除,返回结果
pl = cache_client.pipeline()
# 拿督redis数据
res = cache_client.zrevrange(key, 0, temp.article_num - 1)
if res:
# 手动删除读取出来的缓存结果
pl.zrem(key, *res)
else:
# 如果没有redis缓存数据
# 删除键
cache_client.delete(key)
try:
# 1、# - 首先从wait_recommend中读取,没有直接返回空,进去正常召回流程
wait_cache = eval(hbu.get_table_row('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode()))
except Exception as e:
logger.warning("{} WARN read user_id:{} wait_recommend exception:{} not exist".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, e))
wait_cache = []
if not wait_cache:
return wait_cache
# 2、- 首先从wait_recommend中读取,有数据,读取出来放入自定义100个文章到redis当中,如有剩余放回到wait_recommend。小于自定义100,全部放入redis,wait_recommend直接清空
# - 直接取出被推荐的结果,记录一下到历史记录当中
# 假设是放入到redis当中为100个数据
if len(wait_cache) > 100:
logger.info(
"{} INFO reduce user_id:{} channel:{} wait_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
cache_redis = wait_cache[:100]
# 前100个数据放入redis
pl.zadd(key, dict(zip(cache_redis, range(len(cache_redis)))))
# 100个后面的数据,在放回wait_recommend
hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(wait_cache[100:]).encode())
else:
logger.info(
"{} INFO delete user_id:{} channel:{} wait_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 清空wait_recommend数据
hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str([]).encode())
# 所有不足100个数据,放入redis
pl.zadd(key, dict(zip(wait_cache, range(len(wait_cache)))))
res = cache_client.zrange(key, 0, temp.article_num - 1)
# redis初始有无数据
pl.execute()
# 进行类型转换
res = list(map(int, res))
logger.info("{} INFO store user_id:{} channel:{} cache history data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 进行推荐出去,要做放入历史推荐结果当中
hbu.get_table_put('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(res).encode(),
timestamp=temp.time_stamp
)
return res
5.6.2 在推荐中心加入缓存逻辑
- from server import redis_cache
# 1、获取缓存
res = redis_cache.get_reco_from_cache(temp, self.hbu)
# 如果没有,然后走一遍算法推荐 召回+排序,同时写入到hbase待推荐结果列表
if not res:
logger.info("{} INFO get user_id:{} channel:{} recall/sort data".
format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
res = self.user_reco_list(temp)5.7 排序模型在线预测
学习目标
- 目标
- 无
- 应用
- 应用spark完成
5.7.1排序模型服务
- 提供多种不同模型排序逻辑
- SPARK LR/Tensorflow
5.7.2 排序模型在线预测
- 召回之后的文章结果进行排序
- 步骤:
- 1、读取用户特征中心特征
- 2、读取文章特征中心特征、合并用户文章特征构造预测样本
- 4、预测并进行排序是筛选
import os
import sys
# 如果当前代码文件运行测试需要加入修改路径,避免出现后导包问题
BASE_DIR = os.path.dirname(os.getcwd())
sys.path.insert(0, os.path.join(BASE_DIR))
PYSPARK_PYTHON = "/miniconda2/envs/reco_sys/bin/python"
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
from pyspark import SparkConf
from pyspark.sql import SparkSession
from server.utils import HBaseUtils
from server import pool
from pyspark.ml.linalg import DenseVector
from pyspark.ml.classification import LogisticRegressionModel
import pandas as pd
conf = SparkConf()
config = (
("spark.app.name", "sort"),
("spark.executor.memory", "2g"), # 设置该app启动时占用的内存用量,默认1g
("spark.master", 'yarn'),
("spark.executor.cores", "2"), # 设置spark executor使用的CPU核心数
)
conf.setAll(config)
spark = SparkSession.builder.config(conf=conf).getOrCreate()
1、读取用户特征中心特征
hbu = HBaseUtils(pool)
# 排序
# 1、读取用户特征中心特征
try:
user_feature = eval(hbu.get_table_row('ctr_feature_user',
'{}'.format(1115629498121846784).encode(),
'channel:{}'.format(18).encode()))
except Exception as e:
user_feature = []
2、读取文章特征中心特征,并与用户特征进行合并,构造要推荐文章的样本
- 合并特征向量(channel_id1个+文章向量100个+用户特征权重10个+文章关键词权重) = 121个特征
if user_feature:
# 2、读取文章特征中心特征
result = []
for article_id in [17749, 17748, 44371, 44368]:
try:
article_feature = eval(hbu.get_table_row('ctr_feature_article',
'{}'.format(article_id).encode(),
'article:{}'.format(article_id).encode()))
except Exception as e:
article_feature = [0.0] * 111
f = []
# 第一个channel_id
f.extend([article_feature[0]])
# 第二个article_vector
f.extend(article_feature[11:])
# 第三个用户权重特征
f.extend(user_feature)
# 第四个文章权重特征
f.extend(article_feature[1:11])
vector = DenseVector(f)
result.append([1115629498121846784, article_id, vector])
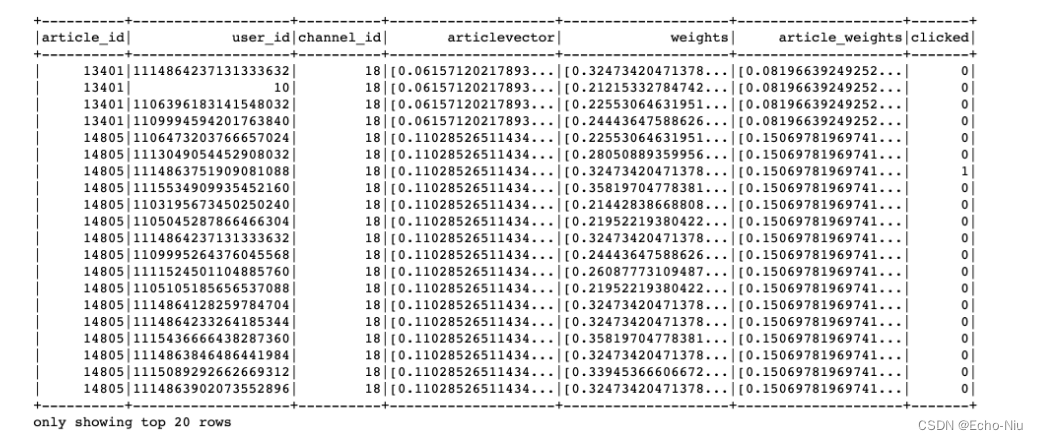
文章特征中心存的顺序
+----------+----------+--------------------+--------------------+--------------------+
|article_id|channel_id| weights| articlevector| features|
+----------+----------+--------------------+--------------------+--------------------+
| 26| 17|[0.19827163395829...|[0.02069368539384...|[17.0,0.198271633...|
| 29| 17|[0.26031398249056...|[-0.1446092289546...|[17.0,0.260313982...|
最终结果:

3、处理样本格式,模型加载预测
# 4、预测并进行排序是筛选
df = pd.DataFrame(result, columns=["user_id", "article_id", "features"])
test = spark.createDataFrame(df)
# 加载逻辑回归模型
model = LogisticRegressionModel.load("hdfs://hadoop-master:9000/headlines/models/LR.obj")
predict = model.transform(test)
预测结果进行筛选
def vector_to_double(row):
return float(row.article_id), float(row.probability[1])
res = predict.select(['article_id', 'probability']).rdd.map(vector_to_double).toDF(['article_id', 'probability']).sort('probability', ascending=False)
获取排序之后前N个文章
article_list = [i.article_id for i in res.collect()]
if len(article_list) > 100:
article_list = article_list[:100]
reco_set = list(map(int, article_list))
5.7.3 添加实时排序的模型预测
- 添加spark配置
grpc启动灰将spark相关信息初始化
from pyspark import SparkConf
from pyspark.sql import SparkSession
# spark配置
conf = SparkConf()
conf.setAll(DefaultConfig.SPARK_GRPC_CONFIG)
SORT_SPARK = SparkSession.builder.config(conf=conf).getOrCreate()
# SPARK grpc配置
SPARK_GRPC_CONFIG = (
("spark.app.name", "grpcSort"), # 设置启动的spark的app名称,没有提供,将随机产生一个名称
("spark.master", "yarn"),
("spark.executor.instances", 4)
)
- 添加模型服务预测函数
from server import SORT_SPARK
from pyspark.ml.linalg import DenseVector
from pyspark.ml.classification import LogisticRegressionModel
import pandas as pd
import numpy as np
from datetime import datetime
import logging
logger = logging.getLogger("recommend")
预测函数
def lr_sort_service(reco_set, temp, hbu):
"""
排序返回推荐文章
:param reco_set:召回合并过滤后的结果
:param temp: 参数
:param hbu: Hbase工具
:return:
"""
# 排序
# 1、读取用户特征中心特征
try:
user_feature = eval(hbu.get_table_row('ctr_feature_user',
'{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode()))
logger.info("{} INFO get user user_id:{} channel:{} profile data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
except Exception as e:
user_feature = []
if user_feature:
# 2、读取文章特征中心特征
result = []
for article_id in reco_set:
try:
article_feature = eval(hbu.get_table_row('ctr_feature_article',
'{}'.format(article_id).encode(),
'article:{}'.format(article_id).encode()))
except Exception as e:
article_feature = [0.0] * 111
f = []
# 第一个channel_id
f.extend([article_feature[0]])
# 第二个article_vector
f.extend(article_feature[11:])
# 第三个用户权重特征
f.extend(user_feature)
# 第四个文章权重特征
f.extend(article_feature[1:11])
vector = DenseVector(f)
result.append([temp.user_id, article_id, vector])
# 4、预测并进行排序是筛选
df = pd.DataFrame(result, columns=["user_id", "article_id", "features"])
test = SORT_SPARK.createDataFrame(df)
# 加载逻辑回归模型
model = LogisticRegressionModel.load("hdfs://hadoop-master:9000/headlines/models/LR.obj")
predict = model.transform(test)
def vector_to_double(row):
return float(row.article_id), float(row.probability[1])
res = predict.select(['article_id', 'probability']).rdd.map(vector_to_double).toDF(
['article_id', 'probability']).sort('probability', ascending=False)
article_list = [i.article_id for i in res.collect()]
logger.info("{} INFO sorting user_id:{} recommend article".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
temp.user_id))
# 排序后,只将排名在前100个文章ID返回给用户推荐
if len(article_list) > 100:
article_list = article_list[:100]
reco_set = list(map(int, article_list))
return reco_set
推荐中心加入排序
# 配置default
RAParam = param(
COMBINE={
'Algo-1': (1, [100, 101, 102, 103, 104], [200]), # 首页推荐,所有召回结果读取+LR排序
'Algo-2': (2, [100, 101, 102, 103, 104], [200]) # 首页推荐,所有召回结果读取 排序
},
# reco_center
from server.sort_service import lr_sort_service
sort_dict = {
'LR': lr_sort_service,
}
# 排序代码逻辑
_sort_num = RAParam.COMBINE[temp.algo][2][0]
reco_set = sort_dict[RAParam.SORT[_sort_num]](reco_set, temp, self.hbu)
5.7.4 supervisor添加grpc实时推荐程序
[program:online]
environment=JAVA_HOME=/root/bigdata/jdk,SPARK_HOME=/root/bigdata/spark,HADOOP_HOME=/root/bigdata/hadoop,PYSPARK_PYTHON=/miniconda2/envs/reco_sys/bin/python ,PYSPARK_DRIVER_PYTHON=/miniconda2/envs/reco_sys/bin/python
command=/miniconda2/envs/reco_sys/bin/python /root/toutiao_project/reco_sys/abtest/routing.py
directory=/root/toutiao_project/reco_sys/abtest
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/recommendsuper.log
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true