目录
一,赛题理解
1,赛题理解
2,数据理解:
3,评价指标(分类和回归)
思考练习
当参赛者拿到竞赛题目的时候,首先应该考虑的事情就是问题建模,同时完成基线模型的管道搭建,从而能够第一时间获得结果上的反馈帮助后续工作的进行,此外,竞赛的存在都依赖于真实的业务场景和复杂的数据参赛者通常对此会有很多想法,但是线上的提交结果验证的次数往往有限因此合理的切分训练集和验证集以及构建可信的线下验证就变得十分重要。这也是保障模型具有泛化性的基础。
竞赛中的问题建模主要可以分为赛题理解,样本选择,线下评估策略三个部分
一,赛题理解
1,赛题理解
赛题理解其实是从直观上梳理问题,分析问题可解的方法赛题背景,赛题的主要痛点
赛题理解的这一部分工作会成为竞赛的重要组成部分和先决条件,通过对赛题的理解,对真实业务的分析我们可以用自身的先验知识进行初步分析,很好的为接下来的部分做出铺垫
2,数据理解:
我们可以将数据理解分为两个部分,分别是数据基础层和数据描述层当然在问题建模阶段,并不需要对数据有特别深的理解,只需要做基本的分析即可在后面的数据探索阶段,再深入理解数据,从数据中发现关键信息
3,评价指标(分类和回归)


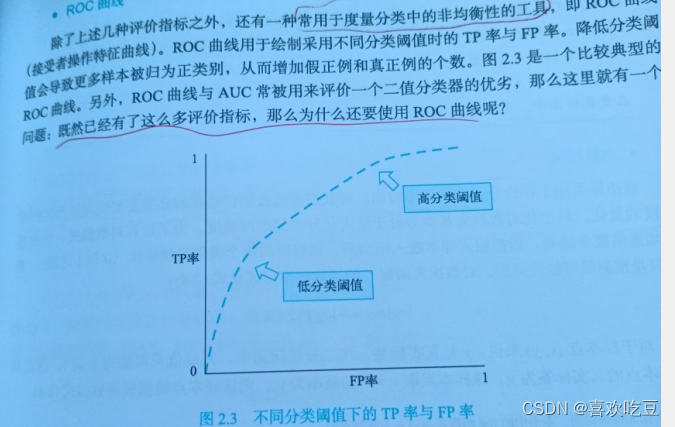
在实际的数据集中,经常会出现正负样本不均衡的现象,即负样本比正样本多很多,或者相反而且测试集中正负样本的分布也可能随着时间roc曲线有一个很好的特质,那就是在这种情况下他依然能够保持不变不过roc曲线在竞赛中倒是不常见,反而auc曲线可以说是我们的老朋友,分类问题中经常出现
在互联网的搜索、推荐和广告的排序业务中,AUC是一个极其常见的评价指标。它定义为ROC曲线下的面积,因为ROC曲线一般都处于y=x 这条直线的上方,所以取值范围在0.5和1之间。之所以使用AUC作为评价指标,是因为ROC曲线在很多时候并不能清晰地说明哪个分类器的效果更好,而AUC作为一个数值, 其值越大就代表分类器的效果越好。值得一提的是AUC的排序特性。相对于准确率、召回率等指标,AUC 指标本身和模型预测的概率绝对值无关,它只关注样本间的排序效果,因此特别适合用作排序相关问题建模的评价指标。AUC 是一个概率值,我们随机挑选一个正样本和一个负样本,由当前的分类算法根据计算出的分数将这个正样本排在负样本前面的概率就是AUC值。所以,AUC值越大,当前的分类算法就越有可能将正样本排在负样本值前面,即能够更好地分类。
对数损失主要是评价模型预测的根率是否足够准确)它更关注和观察数据的吻合程度,而AUC评价的则是模型把正样本排到前面的能力。由于两个指标评价的侧重点不一样,因此参赛著考虑的问题不同,所选择的评价指标就会不同。对于广告CTR预估问题,如果考虑广告排序效果,武可以选择AUC这样也不会受到极端值的影响。此外,对数损失反映了平均偏差,更偏向于将样本数量多的那类划分准确。
平均绝对误差虽然解决了残差加和的正负底下问题能较好的衡量回归模型的好坏,但是绝对值得存在导致函数不光滑,在某些点上不能求导,即平均绝对误差不是,二阶连续可微的,同时二阶导数总为0
即使是在实际的竞赛当中,主办方提供的数据也有可能存在令参赛者们十分头疼的质量问
题。这无疑会对最终预测结果造成很大的影响,因此需要考虑如何选择出合适的样本数据进行
训练那么如何才能够选择出合适的样本呢?在回答这个问题之前,先来看看影响结果的具体
原因又是什么,这里总结出四个主要原因:分别是数据集过大严重影响了模型的性能,噪声和
异常数据导致准确率不够高,样本数据冗余或不相关数据没有给模型带来收益,以及正负样本
分布不均衡导致数据存在倾斜。
思考练习:

(2条消息) 机器学习中的评估指标与损失函数_Yasin_的博客-CSDN博客_余弦相似度 损失函数![]() https://blog.csdn.net/Yasin0/article/details/94435677
https://blog.csdn.net/Yasin0/article/details/94435677
机器学习中的 7 大损失函数实战总结(附Python演练) - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/80370381
https://zhuanlan.zhihu.com/p/80370381
【深度学习】一文读懂机器学习常用损失函数(Loss Function) - 腾讯云开发者社区-腾讯云 (tencent.com)![]() https://cloud.tencent.com/developer/article/1165263
https://cloud.tencent.com/developer/article/1165263
机器学习——损失函数(loss)与评价指标(metric)的区别? - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/373032887
https://zhuanlan.zhihu.com/p/373032887
损失函数VS评估指标 - 快到皖里来 - 博客园 (cnblogs.com)![]() https://www.cnblogs.com/pythonfl/p/13705143.html
https://www.cnblogs.com/pythonfl/p/13705143.html
机器学习样本分类不平衡问题解决思路 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/84322912
https://zhuanlan.zhihu.com/p/84322912
数据集样本类别不均衡时,训练测试集应该如何做? - 知乎 (zhihu.com)![]() https://www.zhihu.com/question/373862904
https://www.zhihu.com/question/373862904
「交叉验证」到底如何选择K值? - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/31924220
https://zhuanlan.zhihu.com/p/31924220
交叉验证和超参数调整:如何优化你的机器学习模型 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/184608795
https://zhuanlan.zhihu.com/p/184608795
(2条消息) k折交叉验证优缺点_【机器学习】训练集,验证集,测试集;验证和交叉验证..._呼呼啦啦就瘸了的博客-CSDN博客![]() https://blog.csdn.net/weixin_35988311/article/details/112540577
https://blog.csdn.net/weixin_35988311/article/details/112540577
你真的了解交叉验证和过拟合吗? - Solong1989 - 博客园 (cnblogs.com)![]() https://www.cnblogs.com/solong1989/p/9415606.html
https://www.cnblogs.com/solong1989/p/9415606.html








![【寒假每日一题】洛谷 P1088 [NOIP2004 普及组] 火星人](https://img-blog.csdnimg.cn/65ba5e4545d04647b9788e5b2d8fc218.png)