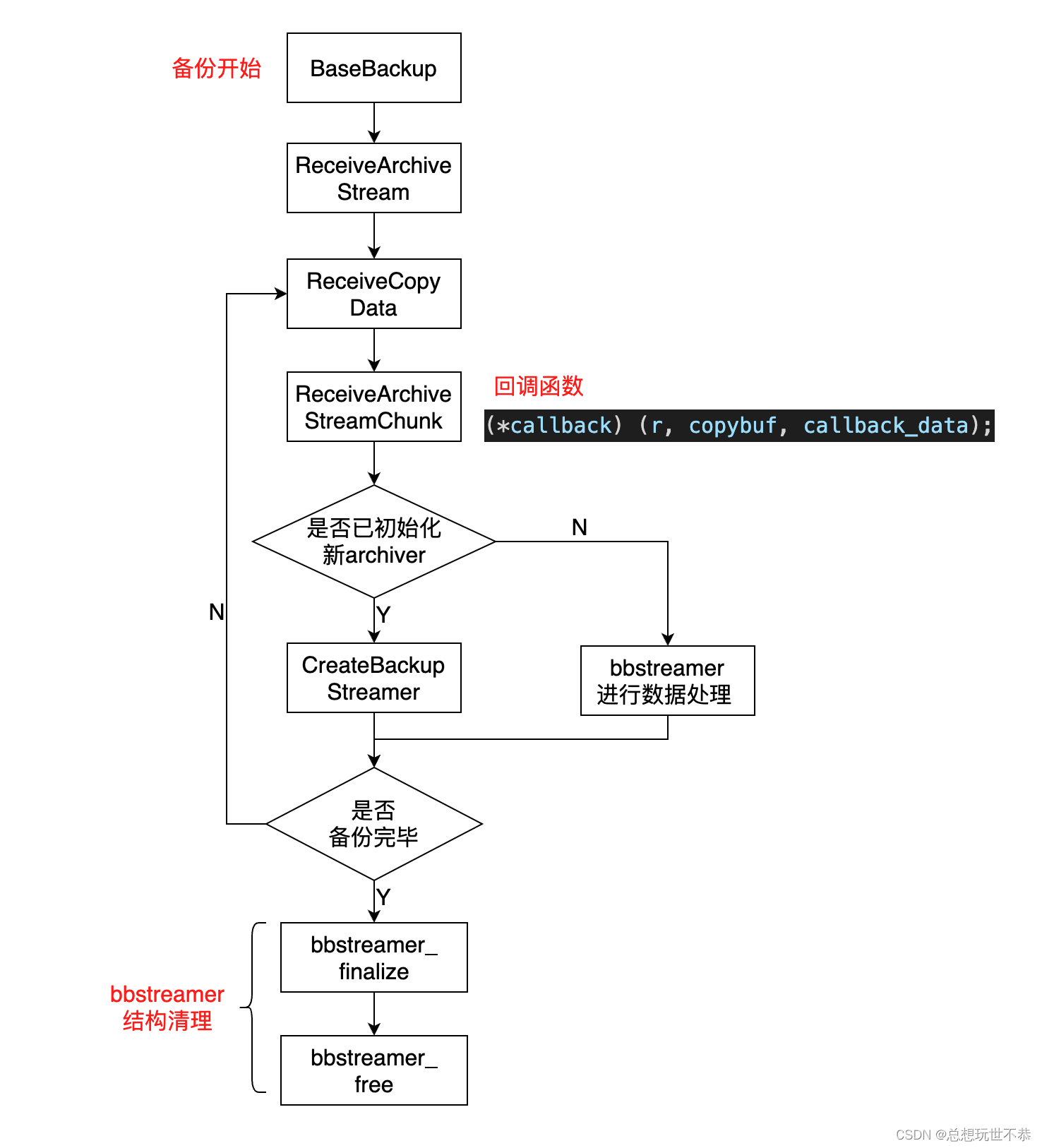
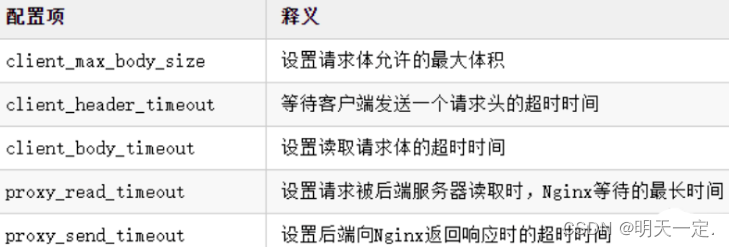
1. 问题的由来
我初次意识到鸭子类型在存在是在学习Sklearn时,在《Hands-On Machine Learing》一书的第二章,作者提供了一个自定义的Tansformer,使用自定义Transformer的好处在于:你既可以实现自己需要的数据处理逻辑,又能保证它可以很好地融入到Sklearn的计算框架中,例如让自己的Transformer与其他Transformer一起加入到Pipeline中。在那个名为CombinedAttributesAdder的Transformer中,它继承了BaseEstimator和TransformerMixin两个基类,并提供了两个方法:fit和transform:
# author: https://laurence.blog.csdn.net/
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
...
def fit(self, X, y=None):
...
def transform(self, X):
...
作为一个静态语言出身刚刚开始学习Python不久的程序员,我的第一直觉是:fit和transform一定是重写或实现了BaseEstimator和TransformerMixin两个父类约定的方法。当我好奇地点开两个类浏览它们的代码时,让我意外且困惑的是:BaseEstimator并没有定义fit方法,TransformerMixin也没有定义transform方法。本文地址:https://laurence.blog.csdn.net/article/details/128798589,转载请注明出处!
Sklearn的官方文档:function :: fit 与 function :: transform 均明确指出:所有的Estimator都应提供fit方法,所有的Transformer都应提供transform方法;检索Sklearn中大量的Estimator和Transformer均实现了这些约定的方法并在适当的时机(例如在Pipeline里)被调用过,然而,它们却都没有定义在相应的基类中。这让人非常困惑,一定是哪里出现了知识漏洞,造成了这一“无法解释”的状况。
2. 鸭子类型
人们总是用那句人尽皆知的短语解释鸭子类型:
如果一只鸟走起来像鸭子,叫起来像鸭子,游起泳来也像鸭子,那它就是鸭子。
或者,下面这张图片更能体现鸭子类型的精髓:

这些比喻确实揭示了鸭子类型的实质,但真切地理解它还是要通过代码。我们不打算使用Duck,Dog一类示例代码了,借用 https://devopedia.org/duck-typing一文列举的短语检索的示例显得更有实际意义:
import random
import string
# author: https://laurence.blog.csdn.net/
class Book:
def __init__(self, num_pages):
self.num_pages = num_pages
def get_page(self, number):
return f"[ Book ] text of page {number}: {''.join(random.sample(string.ascii_letters, 20))}"
def search_phrase(book, phrase):
i = 1
while i <= book.num_pages:
text = book.get_page(i)
print(text)
if phrase in text:
print(f">>> Found phrase \"{phrase}\" in page {i}")
return True
else:
print(f">>> Not found phrase \"{phrase}\" in page {i}")
i+=1
return False
book = Book(2)
search_phrase(book, "duck typing")
程序输出:
[ Book ] text of page 1: vUdNGYhupVTCsIKjQLOS
>>> Not found phrase "duck typing" in page 1
[ Book ] text of page 2: pJPGXWAboHeIuVTvatwd
>>> Not found phrase "duck typing" in page 2
上面的代码中,我们定义了一个Book类和一个短语检索函数search_phrase(),在短语检索函数的实现中,我们要使用到Book类的num_pages属性和get_page()方法,以便完成书本内容的遍历工作。在当前这个阶段,search_phrase()看上去就是为Book类专门设计的一样,它工作良好,也没有歧义。现在,到了揭示Python语言动态性的时候了,我们添加一个新的类Newspaper,并试图让search_phrase()检索它里面的内容:
# author: https://laurence.blog.csdn.net/
class Newspaper:
def __init__(self, num_pages):
self.num_pages = num_pages
def get_page(self,number):
return f"[ Newspaper ] text of page {number}: {''.join(random.sample(string.ascii_letters, 20))}"
newspaper = Newspaper(2)
search_phrase(newspaper, "duck typing")
程序输出:
[ Newspaper ] text of page 1: TFyQnOBctNWmfMjxKRew
>>> Not found phrase "duck typing" in page 1
[ Newspaper ] text of page 2: ndhGolAsZuTPXNRfQceF
>>> Not found phrase "duck typing" in page 2
你会发现,Newspaper搭配search_phrase()也可以工作,没有报任何错误,Newspaper就是“鸭子类型”,它满足search_phrase()对Book这个“概念”的所有要求:有num_pages属性和get_page()方法,所以它就是一本“书”。
3. 关于“动态性”的思考
上述鸭子类型示例得以运行通过且没有报错的原因在于:Python对传入search_phrase()函数的book参数类型没有进行类型检查!但这只是一个表面化的理解,再跟进一步思考就会意识到这个说法并不准确。首先,Python只是在编译期“不做类型检查”,在运行阶段依然会检查数据类型,所以这只能解释在编写这段代码时IDE没有报错,不能解释代码执行时为什么没有报错,进而我们就该意识到,既然程序能成功运行,就说明鸭子类型的示例代码能够通过Python的(运行期)类型检查,即:Python的解释器认为(对于search_phrase()函数来说)book和newspaper就是同一“类型”!
那Python解释器为什么会得出这样的结论呢?唯一经得起推敲的解释就是:不同于静态类型语言,Python同时作为动态类型语言和动态语言,根本无法确定和控制book参数的实际类型,因为:
- Python的“动态类型语言”特性决定了:Python的变量在其生命周期内可以改变自己的类型。例如:先a=‘xyz’,后a=12.3,a从str类型编程float类型,这看似简单,但在静态类型语言中是做不到的,a不是单纯的被赋予了新的值,而是连类型也改变了;
- Python的“动态语言”特性决定了:Python的变量(特指复杂数据结构:类和对象)在其生命周期内可以改变自己的结构,通过动态添加或删除属性和方法,一个类型A可以改成和类型B或者C完全一样,当然,也可以被改的“面目全非”
上述两点明确地告诉我们:在Python中,由于它的“动态”特性,导致变量的类型随时可以变化,在这样的前提下,如果你是Python解释器的设计者,要怎么进行“类型检查”呢?你只能让Python解释器放宽“类型检查”的条件:只要在当前的上下文中(例如一个函数体内),调用方对这个类型所期望的属性和方法它都有,那它就是那个“正确的”类型。
这是在动态类型语言环境下,人们可以给出的最合理的类型检查方案了,因为类型动态化以后势必要比静态类型丢失很多类型相关的信息,使得动态类型语言的类型检查无法做到像静态类型语言那样安全而严格;但也正因为如此,才赋予了动态类型语言极大的灵活性,鸭子类型就是一个典型的例子,你几乎无法在静态类型语言中看到鸭子类型,它们根本无法通过编译的。所以说:这是一把双刃剑,静态类型语言拥有安全有效的类型检查,在代码编写期间就能发现大量的编码错误,同时借助IDE还能有效实现代码提示和自动补全,代价就是要在编写代码时附带大量类型声明,而动态类型语言在上述两方面都很弱,更多的是靠程序员自己,但是它的灵活性确实在很多场景下提升了编程效率。
伴随着这个问题的解答,也化解了我此前的一个疑问:为什么在IDE里Python的代码自动补全和参数列表提示做的那么“差”,本质原因也是因为Python是动态类型语言,IDE无法像Java那样在Python代码中获得足够的类型信息用于支持代码提示和补全操作。
4. 回答问题
最后,回到文章开始提出的问题:为什么CombinedAttributesAdder必须实现fit和transform方法,但又没有定义在BaseEstimator和TransformerMixin中?
fit和transform方法分别代表Estimator和Transformer,而Sklearn中其实并没有Estimator和Transformer这两个(抽象)基类,实际上,它们就是鸭子类型一直强调的“属于文档”的那一部分:即:由于鸭子类型在代码层面上并有任何实体特征(比如像其他语言中的接口或抽象基类),只是靠开发者“人为”遵守约定的方法或属性(例如本例中的fit和transform方法),因此,文档和注释就显得尤为重要了,也就是说:开发者要通过文档和注释告知用户:系统中存在Estimator和Transformer这两个“概念”,它们都是鸭子类型,没有相关的类来指代这两个“概念”,但是,如果你们想要开发它们的具体类,你必须得实现fit和transform方法,否则在程序运行时,其他的代码会调用到这两个方法,如果你没有实现它们,你的程序就会报错。
如果换做是其他语言,鸭子类型大概率会使用接口(Interface)进行定义,在Python这种动态语言里,鸭子类型就是一种“纯纯的口头约定”,但你不实现的话,在调用到具体方法时就会报错,为了告知用户你的程序里有这么个“约定”,你只能在文档和注释中告诉它们。
到这里,我们可以说疑问解答了“一半”,那就是:在Sklearn中,Estimator和Transformer是明确无误的重要“接口”(非编程语言上的Interface,就是一个“概念”,代表一组约束),但是Sklearn选择将它们处理为“鸭子类型”,所以在代码层面上就没任何“对应物”了,并在文档中告知了用户。问题的“另一半”在于,既然有BaseEstimator和TransformerMixin这两个基类,为什么不在这两个类上将fit和transform添加为抽象方法,而约束所有子类去实现它们呢?对于这个问题,以我目前对Sklearn和Python的理解,还不能给出非常确信的解释,但它这个和Python编程风格以及支持抽象基类的时间有关,在《流畅的Python》一书中曾经这样说到:Python语言在诞生15年之后,才在2.6版本中引入了抽象基类,且即使是现在也很少有代码使用抽象基类。这是一个值得思考的问题,显然在Python中是有实现类似抽象基类功能的机制,这个机制其实就是鸭子类型,或者说:是由于鸭子类型,而不怎么需要抽象基类了。本文地址:https://laurence.blog.csdn.net/article/details/128798589,转载请注明出处!
备注提示:
动态类型语言和动态语言是完全不同的两个概念。动态类型语言是指在运行期间才去做数据类型检查的语言,说的是数据类型,动态语言说的是运行时改变结构,说的是代码结构。动态类型语言的数据类型不是在编译阶段决定的,而是把类型绑定延后到了运行阶段。Python既是动态语言双是动态类型语言。
参考资料:
Python 类型系统与类型检查(翻译)
https://cloud.tencent.com/developer/article/1484390
https://devopedia.org/duck-typing