Zookeeper 教程
- Zookeeper 概述
- 分布式应用
- Zookeeper 架构图
- ZooKeeper当中的主从与主备:
- Zookeeper的特性
- 分布式应用的优点
- 分布式应用的挑战
- 什么是Apache ZooKeeper?
- ZooKeeper的好处
- Zookeeper 基础
- ZooKeeper的架构
- 层次命名空间
- Znode的类型
- Sessions(会话)
- Watches(监视)
- Zookeeper 工作流
- ZooKeeper集群中的节点
- Zookeeper leader选举
- Zookeeper 安装
- Zookeeper CLI
- 创建Znodes
- 获取数据
- Watch(监视)
- 设置数据
- 创建子项/子节点
- 列出子项
- 检查状态
- 移除Znode
- Zookeeper API
- ZooKeeper API的基础知识
- Java绑定
- 连接到ZooKeeper集合
- 创建Znode
- Exists - 检查Znode的存在
- getData方法
- setData方法
- getChildren方法
- 删除Znode
- Zookeeper 应用程序
- 雅虎
- Apache Hadoop
- Apache HBase
- Apache Solr
Zookeeper 概述
ZooKeeper 是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper 通过其简单的架构和 API 解决了这个问题。ZooKeeper 允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
ZooKeeper 框架最初是在“Yahoo!"上构建的,用于以简单而稳健的方式访问他们的应用程序。 后来,Apache ZooKeeper 成为 Hadoop,HBase 和其他分布式框架使用的有组织服务的标准。 例如,Apache HBase 使用 ZooKeeper 跟踪分布式数据的状态。
在进一步深入之前,我们了解关于分布式应用的一两件事情是很重要的。因此,让我们开始分布式应用的概述的快速讨论。
分布式应用
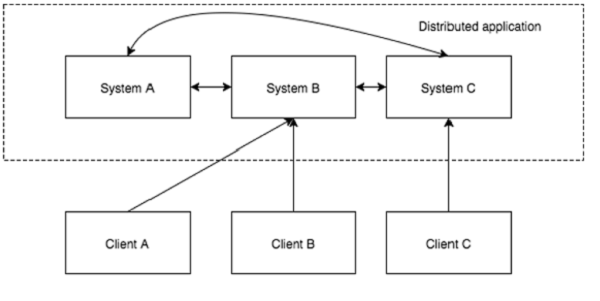
分布式应用可以在给定时间(同时)在网络中的多个系统上运行,通过协调它们以快速有效的方式完成特定任务。通常来说,对于复杂而耗时的任务,非分布式应用(运行在单个系统中)需要几个小时才能完成,而分布式应用通过使用所有系统涉及的计算能力可以在几分钟内完成。
通过将分布式应用配置为在更多系统上运行,可以进一步减少完成任务的时间。分布式应用正在运行的一组系统称为集群,而在集群中运行的每台机器被称为节点。
分布式应用有两部分, Server(服务器) 和 Client(客户端) 应用程序。服务器应用程序实际上是分布式的,并具有通用接口,以便客户端可以连接到集群中的任何服务器并获得相同的结果。 客户端应用程序是与分布式应用进行交互的工具。
ZooKeeper 是一个分布式协调服务的开源框架。主要用来解决分布式集群中应用系统的一致性的问题,例如怎样避免同时操作同一数据造成脏读的问题。ZooKeeper 本质上是一个分布式的小文件存储系统。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树种 的节点进行有效管理。从而来维护和监控你存储的数据的状态变化。将通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。诸如:统一命名服务(dubbo)、分布式配置管理(solr的配置集中管理)、分布式消息队列(sub/pub)、分布式锁、分布式协调等功能。
Zookeeper 架构图
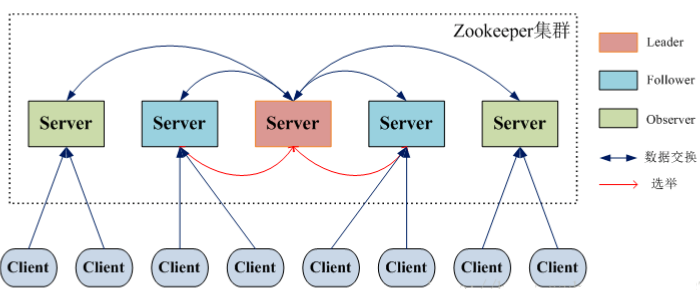
- Leader: ZooKeeper 集群工作的核心 事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各个服务的调度者。 对于 create,setData,delete 等有写操作的请求,则需要统一转发给 leader 处理,leader 需要决定编号、执行操作,这个过程称为一个事务。
- Follower: 处理客户端非事务(读操作)请求 转发事务请求给 Leader 参与集群 leader 选举投票2n-1台可以做集群投票 此外,针对访问量比较大的 zookeeper 集群,还可以新增观察者角色
- Observer: 观察者角色,观察ZooKeeper集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给Leader服务器处理 不会参与任何形式的投票只提供服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力 扯淡:说白了就是增加并发的请求
ZooKeeper当中的主从与主备:
- 主从:主节点少,从节点多,主节点分配任务,从节点具体执行任务
- 主备:主节点与备份节点,主要用于解决我们主机节点挂掉以后,如何选出来一个新的主节点的问题,保证我们的主节点不会宕机
- 很多时候,主从与主备没有太明显的分界线,很多时候都是一起出现
Zookeeper的特性
- 全局数据的一致:每个 server 保存一份相同的数据副本,client 无论链接到哪个 server,展示的数据都是一致的
- 可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 server 上消息 a 在消息 b 前被发布,偏序是指如果一个消息 b 在消息 a 后被同一个发送者发布,a 必须将排在 b 前面
- 数据更新原子性:一次数据更新要么成功,要么失败,不存在中间状态
- 实时性:ZooKeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息
分布式应用的优点
-
可靠性 - 单个或几个系统的故障不会使整个系统出现故障。
-
可扩展性 - 可以在需要时增加性能,通过添加更多机器,在应用程序配置中进行微小的更改,而不会有停机时间。
-
透明性 - 隐藏系统的复杂性,并将其显示为单个实体/应用程序。
分布式应用的挑战
-
竞争条件 - 两个或多个机器尝试执行特定任务,实际上只需在任意给定时间由单个机器完成。例如,共享资源只能在任意给定时间由单个机器修改。
-
死锁 - 两个或多个操作等待彼此无限期完成。
-
不一致 - 数据的部分失败。
什么是Apache ZooKeeper?
Apache ZooKeeper是由集群(节点组)使用的一种服务,用于在自身之间协调,并通过稳健的同步技术维护共享数据。ZooKeeper本身是一个分布式应用程序,为写入分布式应用程序提供服务。
ZooKeeper提供的常见服务如下 :
-
命名服务 - 按名称标识集群中的节点。它类似于DNS,但仅对于节点。
-
配置管理 - 加入节点的最近的和最新的系统配置信息。
-
集群管理 - 实时地在集群和节点状态中加入/离开节点。
-
选举算法 - 选举一个节点作为协调目的的leader。
-
锁定和同步服务 - 在修改数据的同时锁定数据。此机制可帮助你在连接其他分布式应用程序(如Apache HBase)时进行自动故障恢复。
-
高度可靠的数据注册表 - 即使在一个或几个节点关闭时也可以获得数据。
分布式应用程序提供了很多好处,但它们也抛出了一些复杂和难以解决的挑战。ZooKeeper框架提供了一个完整的机制来克服所有的挑战。竞争条件和死锁使用故障安全同步方法进行处理。另一个主要缺点是数据的不一致性,ZooKeeper使用原子性解析。
ZooKeeper的好处
以下是使用ZooKeeper的好处:
-
简单的分布式协调过程
-
同步 - 服务器进程之间的相互排斥和协作。此过程有助于Apache HBase进行配置管理。
-
有序的消息
-
序列化 - 根据特定规则对数据进行编码。确保应用程序运行一致。这种方法可以在MapReduce中用来协调队列以执行运行的线程。
-
可靠性
-
原子性 - 数据转移完全成功或完全失败,但没有事务是部分的。
Zookeeper 基础
在深入了解ZooKeeper的运作之前,让我们来看看ZooKeeper的基本概念。我们将在本章中讨论以下主题:
1、Architecture(架构)
2、Hierarchical namespace(层次命名空间)
3、Session(会话)
4、Watches(监视)
ZooKeeper的架构
看看下面的图表。它描述了ZooKeeper的“客户端-服务器架构”。
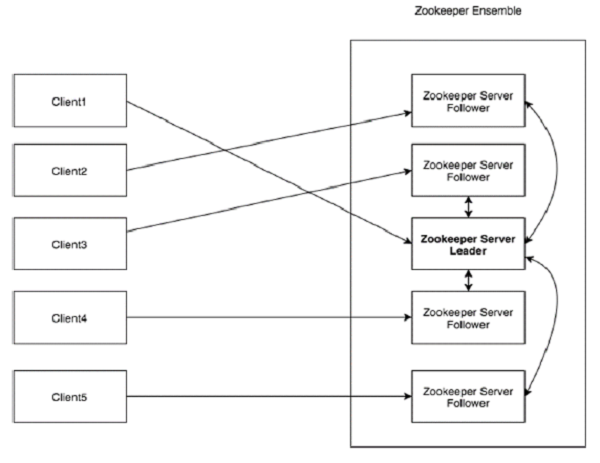
作为ZooKeeper架构的一部分的每个组件在下表中进行了说明。
| 部分 | 描述 |
|---|---|
| Client(客户端) | 客户端,我们的分布式应用集群中的一个节点,从服务器访问信息。对于特定的时间间隔,每个客户端向服务器发送消息以使服务器知道客户端是活跃的。类似地,当客户端连接时,服务器发送确认码。如果连接的服务器没有响应,客户端会自动将消息重定向到另一个服务器。 |
| Server(服务器) | 服务器,我们的ZooKeeper总体中的一个节点,为客户端提供所有的服务。向客户端发送确认码以告知服务器是活跃的。 |
| Ensemble | ZooKeeper服务器组。形成ensemble所需的最小节点数为3。 |
| Leader | 服务器节点,如果任何连接的节点失败,则执行自动恢复。Leader在服务启动时被选举。 |
| Follower | 跟随leader指令的服务器节点。 |
层次命名空间
下图描述了用于内存表示的ZooKeeper文件系统的树结构。ZooKeeper节点称为 znode 。每个znode由一个名称标识,并用路径(/)序列分隔。
-
在图中,首先有一个由“/”分隔的znode。在根目录下,你有两个逻辑命名空间 config 和 workers 。
-
config 命名空间用于集中式配置管理,workers 命名空间用于命名。
-
在 config 命名空间下,每个znode最多可存储1MB的数据。这与UNIX文件系统相类似,除了父znode也可以存储数据。这种结构的主要目的是存储同步数据并描述znode的元数据。此结构称为 ZooKeeper数据模型。

Znode兼具文件和目录两种特点。既像文件一样维护着数据长度、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。每个Znode由三个部分组成:
-
stat:此为状态信息,描述该Znode版本、权限等信息。
-
data:与该Znode关联的数据
-
children:该Znode下的节点
-
版本号 - 每个znode都有版本号,这意味着每当与znode相关联的数据发生变化时,其对应的版本号也会增加。当多个zookeeper客户端尝试在同一znode上执行操作时,版本号的使用就很重要。
-
操作控制列表(ACL) - ACL基本上是访问znode的认证机制。它管理所有znode读取和写入操作。
-
时间戳 - 时间戳表示创建和修改znode所经过的时间。它通常以毫秒为单位。ZooKeeper从“事务ID"(zxid)标识znode的每个更改。Zxid 是唯一的,并且为每个事务保留时间,以便你可以轻松地确定从一个请求到另一个请求所经过的时间。
-
数据长度 - 存储在znode中的数据总量是数据长度。你最多可以存储1MB的数据。
Znode的类型
Znode被分为持久(persistent)节点,顺序(sequential)节点和临时(ephemeral)节点。
-
持久节点 - 即使在创建该特定znode的客户端断开连接后,持久节点仍然存在。默认情况下,除非另有说明,否则所有znode都是持久的。
-
临时节点 - 客户端活跃时,临时节点就是有效的。当客户端与ZooKeeper集合断开连接时,临时节点会自动删除。因此,只有临时节点不允许有子节点。如果临时节点被删除,则下一个合适的节点将填充其位置。临时节点在leader选举中起着重要作用。
-
顺序节点 - 顺序节点可以是持久的或临时的。当一个新的znode被创建为一个顺序节点时,ZooKeeper通过将10位的序列号附加到原始名称来设置znode的路径。例如,如果将具有路径 /myapp 的znode创建为顺序节点,则ZooKeeper会将路径更改为 /myapp0000000001 ,并将下一个序列号设置为0000000002。如果两个顺序节点是同时创建的,那么ZooKeeper不会对每个znode使用相同的数字。顺序节点在锁定和同步中起重要作用。
Sessions(会话)
会话对于ZooKeeper的操作非常重要。会话中的请求按FIFO顺序执行。一旦客户端连接到服务器,将建立会话并向客户端分配会话ID 。
客户端以特定的时间间隔发送心跳以保持会话有效。如果ZooKeeper集合在超过服务器开启时指定的期间(会话超时)都没有从客户端接收到心跳,则它会判定客户端死机。
会话超时通常以毫秒为单位。当会话由于任何原因结束时,在该会话期间创建的临时节点也会被删除。
Watches(监视)
监视是一种简单的机制,使客户端收到关于ZooKeeper集合中的更改的通知。客户端可以在读取特定znode时设置Watches。Watches会向注册的客户端发送任何znode(客户端注册表)更改的通知。
Znode更改是与znode相关的数据的修改或znode的子项中的更改。只触发一次watches。如果客户端想要再次通知,则必须通过另一个读取操作来完成。当连接会话过期时,客户端将与服务器断开连接,相关的watches也将被删除。
Zookeeper 工作流
一旦ZooKeeper集合启动,它将等待客户端连接。客户端将连接到ZooKeeper集合中的一个节点。它可以是领导或跟随者节点。一旦客户端被连接,节点将向特定客户端分配会话ID并向该客户端发送确认。如果客户端没有收到确认,它将尝试连接ZooKeeper集合中的另一个节点。 一旦连接到节点,客户端将以有规律的间隔向节点发送心跳,以确保连接不会丢失。
-
如果客户端想要读取特定的znode,它将会向具有znode路径的节点发送读取请求,并且节点通过从其自己的数据库获取来返回所请求的znode。为此,在ZooKeeper集合中读取速度快。
-
如果客户端想要将数据存储在ZooKeeper集合中,则会将znode路径和数据发送到服务器。连接的服务器将该请求转发给领导者,然后领导者将向所有的跟随着重新发出写入请求。如果只有大部分节点成功响应,而写入请求成功,则成功返回代码将被发送到客户端。 否则,写入请求失败。绝大多数节点被称为 Quorum 。
ZooKeeper集群中的节点
ZooKeeper集合中可以有不同数量的节点。那么,让我们分析一下在ZooKeeper工作流中更改节点的效果:
-
如果我们有单个节点,那么当该节点失败时,ZooKeeper集群就会失效。这就是为什么不建议在生产环境中使用它,因为它会导致"单点故障"。
-
如果我们有两个节点和一个节点故障,我们就没有多数,因为两个节点中有一个不是多数节点。
-
如果我们有三个节点而一个节点故障,那么我们有大多数,因此,这是最低要求。ZooKeeper集群在实际生产环境中必须至少有三个节点。
-
如果我们有四个节点而两个节点故障,它将再次故障。类似于有三个节点,额外节点不用于任何目的,因此,最好添加奇数的节点,例如3,5,7。
我们知道写入过程比ZooKeeper集合中的读取过程昂贵,因为所有节点都需要在数据库中写入相同的数据。因此,对于平衡的环境拥有较少数量(例如3,5,7)的节点比拥有大量的节点要好。
下图描述了ZooKeeper工作流,后面的表说明了它的不同组件。
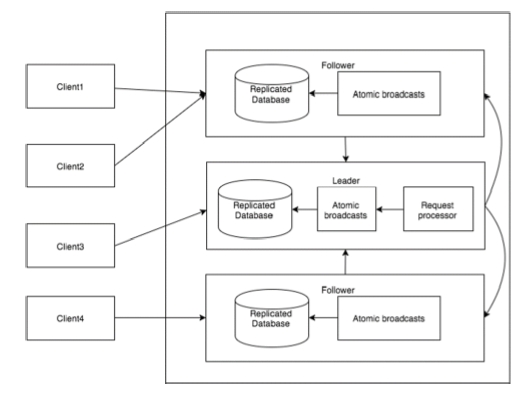
| 组件 | 描述 |
|---|---|
| 写入(write) | 写入过程由leader节点处理。leader将写入请求转发到所有znode,并等待znode的回复。如果一半的znode回复,则写入过程完成。 |
| 读取(read) | 读取由特定连接的znode在内部执行,因此不需要与集群进行交互。 |
| 复制数据库(replicated database) | 它用于在zookeeper中存储数据。每个znode都有自己的数据库,每个znode在一致性的帮助下每次都有相同的数据。 |
| 领导者(Leader) | Leader是负责处理写入请求的Znode。 |
| 跟随者(Follower) | follower从客户端接收写入请求,并将它们转发到leader znode。 |
| 请求处理器(request processor) | 只存在于leader节点。它管理来自follower节点的写入请求。 |
| 原子广播(atomic broadcasts) | 负责广播从leader节点到follower节点的变化。 |
Zookeeper leader选举
Leader 选举是保证分布式数据一致性的关键所在。Leader 选举分为 Zookeeper 集群初始化启动时选举和 Zookeeper 集群运行期间 Leader 重新选举两种情况。在讲解 Leader 选举前先了解一下 Zookeeper 节点 4 种可能状态和事务ID概念。
1、Zookeeper 节点状态
- LOOKING:寻找 Leader 状态,处于该状态需要进入选举流程
- LEADING:领导者状态,处于该状态的节点说明是角色已经是 Leader
- FOLLOWING:跟随者状态,表示 Leader 已经选举出来,当前节点角色是 follower
- OBSERVER:观察者状态,表明当前节点角色是 observer
2、事务ID
ZooKeeper 状态的每次变化都接收一个 ZXID(ZooKeeper 事务 id)形式的标记。ZXID 是一个 64 位的数字,由 Leader 统一分配,全局唯一,不断递增。ZXID 展示了所有的ZooKeeper 的变更顺序。每次变更会有一个唯一的 zxid,如果 zxid1 小于 zxid2 说明 zxid1 在 zxid2 之前发生。
3、Zookeeper 集群初始化启动时 Leader 选举
若进行 Leader 选举,则至少需要两台机器,这里选取 3 台机器组成的服务器集群为例。初始化启动期间 Leader 选举流程如下图所示。
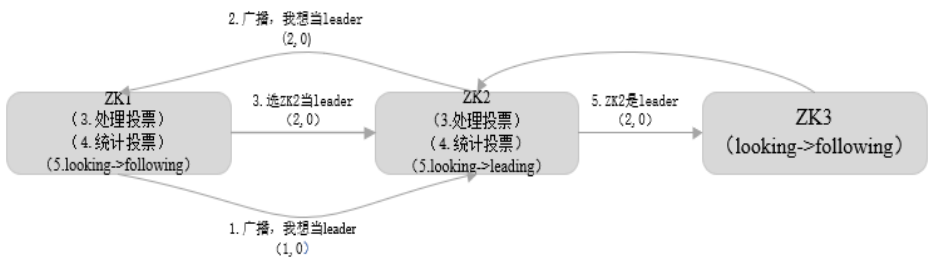
在集群初始化阶段,当有一台服务器 ZK1 启动时,其单独无法进行和完成 Leader 选举,当第二台服务器 ZK2 启动时,此时两台机器可以相互通信,每台机器都试图找到 Leader,于是进入 Leader 选举过程。选举过程开始,过程如下:
(1) 每个Server发出一个投票。由于是初始情况,ZK1 和 ZK2 都会将自己作为 Leader 服务器来进行投票,每次投票会包含所推举的服务器的 myid 和 ZXID,使用(myid, ZXID)来表示,此时 ZK1 的投票为(1, 0),ZK2 的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自 LOOKING 状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行比较,规则如下
-
优先检查 ZXID。ZXID 比较大的服务器优先作为 Leader。
-
如果 ZXID 相同,那么就比较 myid。myid 较大的服务器作为Leader服务器。
对于 ZK1 而言,它的投票是(1, 0),接收 ZK2 的投票为(2, 0),首先会比较两者的 ZXID,均为 0,再比较 myid,此时 ZK2 的 myid 最大,于是 ZK2 胜。ZK1 更新自己的投票为(2, 0),并将投票重新发送给 ZK2。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于 ZK1、ZK2 而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出 ZK2 作为Leader。
(5) 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为 FOLLOWING,如果是 Leader,就变更为 LEADING。当新的 Zookeeper 节点 ZK3 启动时,发现已经有 Leader 了,不再选举,直接将直接的状态从 LOOKING 改为 FOLLOWING。
4、Zookeeper 集群运行期间 Leader 重新选
在 Zookeeper 运行期间,如果 Leader 节点挂了,那么整个 Zookeeper 集群将暂停对外服务,进入新一轮Leader选举。假设正在运行的有 ZK1、ZK2、ZK3 三台服务器,当前 Leader 是 ZK2,若某一时刻 Leader 挂了,此时便开始 Leader 选举。选举过程如下图所示。
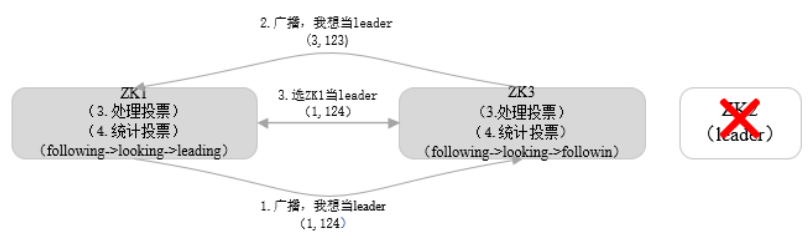
(1) 变更状态。Leader 挂后,余下的非 Observer 服务器都会讲自己的服务器状态变更为 LOOKING,然后开始进入 Leader 选举过程。
(2) 每个Server会发出一个投票。在运行期间,每个服务器上的 ZXID 可能不同,此时假定 ZK1 的 ZXID 为 124,ZK3 的 ZXID 为 123;在第一轮投票中,ZK1 和 ZK3 都会投自己,产生投票(1, 124),(3, 123),然后各自将投票发送给集群中所有机器。
(3) 接收来自各个服务器的投票。与启动时过程相同。
(4) 处理投票。与启动时过程相同,由于 ZK1 事务 ID 大,ZK1 将会成为 Leader。
(5) 统计投票。与启动时过程相同。
(6) 改变服务器的状态。与启动时过程相同。
leader选举是一个复杂的过程,但 ZooKeeper 服务使它非常简单。让我们在下一章中继续学习 ZooKeepe r 安装,以用于开发目的。
Zookeeper 安装
在安装ZooKeeper之前,请确保你的系统是在以下任一操作系统上运行:
-
任意Linux OS - 支持开发和部署。适合演示应用程序。
-
Windows OS - 仅支持开发。
-
Mac OS - 仅支持开发。
ZooKeeper服务器是用Java创建的,它在JVM上运行。你需要使用JDK 6或更高版本。
现在,按照以下步骤在你的机器上安装ZooKeeper框架。
步骤1:验证Java安装
相信你已经在系统上安装了Java环境。现在只需使用以下命令验证它。
$ java -version
如果你在机器上安装了Java,那么可以看到已安装的Java的版本。否则,请按照以下简单步骤安装最新版本的Java。
步骤1.1:下载JDK
通过访问链接下载最新版本的JDK,并下载最新版本的Java。
最新版本(在编写本教程时)是JDK 8u 60,文件是“jdk-8u60-linuxx64.tar.gz"。请在你的机器上下载该文件。
步骤1.2:提取文件
通常,文件会下载到download文件夹中。验证并使用以下命令提取tar设置。
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gz
步骤1.3:移动到opt目录
要使Java对所有用户可用,请将提取的Java内容移动到“/usr/local/java"文件夹。
$ su
password: (type password of root user)
$ mkdir /opt/jdk
$ mv jdk-1.8.0_60 /opt/jdk/
步骤1.4:设置路径
要设置路径和JAVA_HOME变量,请将以下命令添加到〜/.bashrc文件中。
export JAVA_HOME = /usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin
现在,将所有更改应用到当前运行的系统中。
$ source ~/.bashrc
步骤1.5:Java替代
使用以下命令更改Java替代项。
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100
步骤1.6
使用步骤1中说明的验证命令(java -version)验证Java安装。
步骤2:ZooKeeper框架安装
步骤2.1:下载ZooKeeper
要在你的计算机上安装ZooKeeper框架,请访问以下链接并下载最新版本的ZooKeeper。http://zookeeper.apache.org/releases.html
到目前为止,最新版本的ZooKeeper是3.4.6(ZooKeeper-3.4.6.tar.gz)。
步骤2.2:提取tar文件
使用以下命令提取tar文件
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir data
步骤2.3:创建配置文件
使用命令 vi conf/zoo.cfg 和所有以下参数设置为起点,打开名为 conf/zoo.cfg 的配置文件。
$ vi conf/zoo.cfg
tickTime = 2000
dataDir = /path/to/zookeeper/data
clientPort = 2181
initLimit = 5
syncLimit = 2
一旦成功保存配置文件,再次返回终端。你现在可以启动zookeeper服务器。
步骤2.4:启动ZooKeeper服务器
执行以下命令
$ bin/zkServer.sh start
执行此命令后,你将收到以下响应
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg
$ Starting zookeeper ... STARTED
步骤2.5:启动CLI
键入以下命令
$ bin/zkCli.sh
键入上述命令后,将连接到ZooKeeper服务器,你应该得到以下响应。
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]
停止ZooKeeper服务器
连接服务器并执行所有操作后,可以使用以下命令停止zookeeper服务器。
$ bin/zkServer.sh stop
Zookeeper CLI
ooKeeper命令行界面(CLI)用于与ZooKeeper集合进行交互以进行开发。它有助于调试和解决不同的选项。
要执行ZooKeeper CLI操作,首先打开ZooKeeper服务器(“bin/zkServer.sh start”),然后打开ZooKeeper客户端(“bin/zkCli.sh”)。一旦客户端启动,你可以执行以下操作:
1、创建znode
2、获取数据
3、监视znode的变化
4、设置数据
5、创建znode的子节点
6、列出znode的子节点
7、检查状态
8、移除/删除znode
现在让我们用一个例子逐个了解上面的命令。
创建Znodes
用给定的路径创建一个znode。flag参数指定创建的znode是临时的,持久的还是顺序的。默认情况下,所有znode都是持久的。
当会话过期或客户端断开连接时,临时节点(flag:-e)将被自动删除。
顺序节点保证znode路径将是唯一的。
ZooKeeper集合将向znode路径填充10位序列号。例如,znode路径 /myapp 将转换为/myapp0000000001,下一个序列号将为/myapp0000000002。如果没有指定flag,则znode被认为是持久的。
语法
create /path /data
示例
create /FirstZnode “Myfirstzookeeper-app"
输出
[zk: localhost:2181(CONNECTED) 0] create /FirstZnode “Myfirstzookeeper-app"
Created /FirstZnode
要创建顺序节点,请添加flag:-s,如下所示。
语法
create -s /path /data
示例
create -s /FirstZnode second-data
输出
[zk: localhost:2181(CONNECTED) 2] create -s /FirstZnode “second-data"
Created /FirstZnode0000000023
要创建临时节点,请添加flag:-e ,如下所示。
语法
create -e /path /data
示例
create -e /SecondZnode “Ephemeral-data"
输出
[zk: localhost:2181(CONNECTED) 2] create -e /SecondZnode “Ephemeral-data"
Created /SecondZnode
记住当客户端断开连接时,临时节点将被删除。你可以通过退出ZooKeeper CLI,然后重新打开CLI来尝试。
获取数据
它返回znode的关联数据和指定znode的元数据。你将获得信息,例如上次修改数据的时间,修改的位置以及数据的相关信息。此CLI还用于分配监视器以显示数据相关的通知。
语法
get /path
示例
get /FirstZnode
输出
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode
“Myfirstzookeeper-app"
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 16:15:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0
要访问顺序节点,必须输入znode的完整路径。
示例
get /FirstZnode0000000023
输出
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode0000000023
“Second-data"
cZxid = 0x80
ctime = Tue Sep 29 16:25:47 IST 2015
mZxid = 0x80
mtime = Tue Sep 29 16:25:47 IST 2015
pZxid = 0x80
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 13
numChildren = 0
Watch(监视)
当指定的znode或znode的子数据更改时,监视器会显示通知。你只能在 get 命令中设置watch。
语法
get /path [watch] 1
示例
get /FirstZnode 1
输出
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode 1
“Myfirstzookeeper-app"
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 16:15:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0
输出类似于普通的 get 命令,但它会等待后台等待znode更改。<从这里开始>
设置数据
设置指定znode的数据。完成此设置操作后,你可以使用 get CLI命令检查数据。
语法
set /path /data
示例
set /SecondZnode Data-updated
输出
[zk: localhost:2181(CONNECTED) 1] get /SecondZnode “Data-updated"
cZxid = 0x82
ctime = Tue Sep 29 16:29:50 IST 2015
mZxid = 0x83
mtime = Tue Sep 29 16:29:50 IST 2015
pZxid = 0x82
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x15018b47db00000
dataLength = 14
numChildren = 0
如果你在 get 命令中分配了watch选项(如上一个命令),则输出将类似如下所示。
输出
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode “Mysecondzookeeper-app"
WATCHER: :
WatchedEvent state:SyncConnected type:NodeDataChanged path:/FirstZnode
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x84
mtime = Tue Sep 29 17:14:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 23
numChildren = 0
创建子项/子节点
创建子节点类似于创建新的znode。唯一的区别是,子znode的路径也将具有父路径。
语法
create /parent/path/subnode/path /data
示例
create /FirstZnode/Child1 firstchildren
输出
[zk: localhost:2181(CONNECTED) 16] create /FirstZnode/Child1 “firstchildren"
created /FirstZnode/Child1
[zk: localhost:2181(CONNECTED) 17] create /FirstZnode/Child2 “secondchildren"
created /FirstZnode/Child2
列出子项
此命令用于列出和显示znode的子项。
语法
ls /path
示例
ls /MyFirstZnode
输出
[zk: localhost:2181(CONNECTED) 2] ls /MyFirstZnode
[mysecondsubnode, myfirstsubnode]
检查状态
状态描述指定的znode的元数据。它包含时间戳,版本号,ACL,数据长度和子znode等细项。
语法
stat /path
示例
stat /FirstZnode
输出
[zk: localhost:2181(CONNECTED) 1] stat /FirstZnode
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 17:14:24 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 23
numChildren = 0
移除Znode
移除指定的znode并递归其所有子节点。只有在这样的znode可用的情况下才会发生。
语法
rmr /path
示例
rmr /FirstZnode
输出
[zk: localhost:2181(CONNECTED) 10] rmr /FirstZnode
[zk: localhost:2181(CONNECTED) 11] get /FirstZnode
Node does not exist: /FirstZnode
删除(delete/path)命令类似于 remove 命令,除了它只适用于没有子节点的znode。
Zookeeper API
ZooKeeper有一个绑定Java和C的官方API。Zookeeper社区为大多数语言(.NET,python等)提供非官方API。使用ZooKeeper API,应用程序可以连接,交互,操作数据,协调,最后断开与ZooKeeper集合的连接。
ZooKeeper API具有丰富的功能,以简单和安全的方式获得ZooKeeper集合的所有功能。ZooKeeper API提供同步和异步方法。
ZooKeeper集合和ZooKeeper API在各个方面都完全相辅相成,对开发人员有很大的帮助。让我们在本章讨论Java绑定。
ZooKeeper API的基础知识
与ZooKeeper集合进行交互的应用程序称为 ZooKeeper客户端或简称客户端。
Znode是ZooKeeper集合的核心组件,ZooKeeper API提供了一小组方法使用ZooKeeper集合来操纵znode的所有细节。
客户端应该遵循以步骤,与ZooKeeper集合进行清晰和干净的交互。
-
连接到ZooKeeper集合。ZooKeeper集合为客户端分配会话ID。
-
定期向服务器发送心跳。否则,ZooKeeper集合将过期会话ID,客户端需要重新连接。
-
只要会话ID处于活动状态,就可以获取/设置znode。
-
所有任务完成后,断开与ZooKeeper集合的连接。如果客户端长时间不活动,则ZooKeeper集合将自动断开客户端。
Java绑定
让我们来了解本章中最重要的一组ZooKeeper API。ZooKeeper API的核心部分是ZooKeeper类。它提供了在其构造函数中连接ZooKeeper集合的选项,并具有以下方法:
-
connect - 连接到ZooKeeper集合
-
create- 创建znode
-
exists- 检查znode是否存在及其信息
-
getData - 从特定的znode获取数据
-
setData - 在特定的znode中设置数据
-
getChildren - 获取特定znode中的所有子节点
-
delete - 删除特定的znode及其所有子项
-
close - 关闭连接
连接到ZooKeeper集合
ZooKeeper类通过其构造函数提供connect功能。构造函数的签名如下 :
ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher)
-
connectionString - ZooKeeper集合主机。
-
sessionTimeout - 会话超时(以毫秒为单位)。
-
watcher - 实现“监视器”界面的对象。ZooKeeper集合通过监视器对象返回连接状态。
让我们创建一个新的帮助类 ZooKeeperConnection ,并添加一个方法 connect 。 connect 方法创建一个ZooKeeper对象,连接到ZooKeeper集合,然后返回对象。
这里 CountDownLatch 用于停止(等待)主进程,直到客户端与ZooKeeper集合连接。
ZooKeeper集合通过监视器回调来回复连接状态。一旦客户端与ZooKeeper集合连接,监视器回调就会被调用,并且监视器回调函数调用CountDownLatch的countDown方法来释放锁,在主进程中await。
以下是与ZooKeeper集合连接的完整代码。
编码:ZooKeeperConnection.java
// import java classes
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
// import zookeeper classes
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.AsyncCallback.StatCallback;
import org.apache.zookeeper.KeeperException.Code;
import org.apache.zookeeper.data.Stat;
public class ZooKeeperConnection {
// declare zookeeper instance to access ZooKeeper ensemble
private ZooKeeper zoo;
final CountDownLatch connectedSignal = new CountDownLatch(1);
// Method to connect zookeeper ensemble.
public ZooKeeper connect(String host) throws IOException,InterruptedException {
zoo = new ZooKeeper(host,5000,new Watcher() {
public void process(WatchedEvent we) {
if (we.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
});
connectedSignal.await();
return zoo;
}
// Method to disconnect from zookeeper server
public void close() throws InterruptedException {
zoo.close();
}
}
保存上面的代码,它将在下一节中用于连接ZooKeeper集合。
创建Znode
ZooKeeper类提供了在ZooKeeper集合中创建一个新的znode的create方法。 create 方法的签名如下:
create(String path, byte[] data, List<ACL> acl, CreateMode createMode)
-
path - Znode路径。例如,/myapp1,/myapp2,/myapp1/mydata1,myapp2/mydata1/myanothersubdata
-
data - 要存储在指定znode路径中的数据
-
acl - 要创建的节点的访问控制列表。ZooKeeper API提供了一个静态接口 ZooDefs.Ids 来获取一些基本的acl列表。例如,ZooDefs.Ids.OPEN_ACL_UNSAFE返回打开znode的acl列表。
-
createMode - 节点的类型,即临时,顺序或两者。这是一个枚举。
让我们创建一个新的Java应用程序来检查ZooKeeper API的 create 功能。创建文件 ZKCreate.java 。在main方法中,创建一个类型为 ZooKeeperConnection 的对象,并调用 connect 方法连接到ZooKeeper集合。
connect方法将返回ZooKeeper对象 zk 。现在,请使用自定义path和data调用 zk 对象的 create 方法。
创建znode的完整程序代码如下:
编码:ZKCreate.java
import java.io.IOException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
public class ZKCreate {
// create static instance for zookeeper class.
private static ZooKeeper zk;
// create static instance for ZooKeeperConnection class.
private static ZooKeeperConnection conn;
// Method to create znode in zookeeper ensemble
public static void create(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
public static void main(String[] args) {
// znode path
String path = "/MyFirstZnode"; // Assign path to znode
// data in byte array
byte[] data = "My first zookeeper app".getBytes(); // Declare data
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
create(path, data); // Create the data to the specified path
conn.close();
} catch (Exception e) {
System.out.println(e.getMessage()); //Catch error message
}
}
}
一旦编译和执行应用程序,将在ZooKeeper集合中创建具有指定数据的znode。你可以使用ZooKeeper CLI zkCli.sh 进行检查。
cd /path/to/zookeeper
bin/zkCli.sh
>>> get /MyFirstZnode
Exists - 检查Znode的存在
ZooKeeper类提供了 exists 方法来检查znode的存在。如果指定的znode存在,则返回一个znode的元数据。exists方法的签名如下:
exists(String path, boolean watcher)
-
path- Znode路径
-
watcher - 布尔值,用于指定是否监视指定的znode
让我们创建一个新的Java应用程序来检查ZooKeeper API的“exists”功能。创建文件“ZKExists.java”。在main方法中,使用“ZooKeeperConnection”对象创建ZooKeeper对象“zk”。然后,使用自定义“path”调用“zk”对象的“exists”方法。完整的列表如下:
编码:ZKExists.java
import java.io.IOException;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKExists {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path, true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign znode to the specified path
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path of the znode
if(stat != null) {
System.out.println("Node exists and the node version is " +
stat.getVersion());
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage()); // Catches error messages
}
}
}
一旦编译和执行应用程序,你将获得以下输出。
Node exists and the node version is 1.
getData方法
ZooKeeper类提供 getData 方法来获取附加在指定znode中的数据及其状态。 getData 方法的签名如下:
getData(String path, Watcher watcher, Stat stat)
path - Znode路径。
watcher - 监视器类型的回调函数。当指定的znode的数据改变时,ZooKeeper集合将通过监视器回调进行通知。这是一次性通知。
stat - 返回znode的元数据。
让我们创建一个新的Java应用程序来了解ZooKeeper API的 getData 功能。创建文件 ZKGetData.java 。在main方法中,使用 ZooKeeperConnection 对象创建一个ZooKeeper对象 zk 。然后,使用自定义路径调用zk对象的 getData 方法。
下面是从指定节点获取数据的完整程序代码:
编码:ZKGetData.java
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException, KeeperException {
String path = "/MyFirstZnode";
final CountDownLatch connectedSignal = new CountDownLatch(1);
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path);
if(stat != null) {
byte[] b = zk.getData(path, new Watcher() {
public void process(WatchedEvent we) {
if (we.getType() == Event.EventType.None) {
switch(we.getState()) {
case Expired:
connectedSignal.countDown();
break;
}
} else {
String path = "/MyFirstZnode";
try {
byte[] bn = zk.getData(path,
false, null);
String data = new String(bn,
"UTF-8");
System.out.println(data);
connectedSignal.countDown();
} catch(Exception ex) {
System.out.println(ex.getMessage());
}
}
}
}, null);
String data = new String(b, "UTF-8");
System.out.println(data);
connectedSignal.await();
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
一旦编译和执行应用程序,你将获得以下输出
My first zookeeper app
应用程序将等待ZooKeeper集合的进一步通知。使用ZooKeeper CLI zkCli.sh 更改指定znode的数据。
cd /path/to/zookeeper
bin/zkCli.sh
>>> set /MyFirstZnode Hello
现在,应用程序将打印以下输出并退出。
Hello
setData方法
ZooKeeper类提供 setData 方法来修改指定znode中附加的数据。 setData 方法的签名如下:
setData(String path, byte[] data, int version)
-
path- Znode路径
-
data - 要存储在指定znode路径中的数据。
-
version- znode的当前版本。每当数据更改时,ZooKeeper会更新znode的版本号。
现在让我们创建一个新的Java应用程序来了解ZooKeeper API的 setData 功能。创建文件 ZKSetData.java 。在main方法中,使用 ZooKeeperConnection 对象创建一个ZooKeeper对象 zk 。然后,使用指定的路径,新数据和节点版本调用 zk 对象的 setData 方法。
以下是修改附加在指定znode中的数据的完整程序代码。
编码:ZKSetData.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import java.io.IOException;
public class ZKSetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to update the data in a znode. Similar to getData but without watcher.
public static void update(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.setData(path, data, zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path= "/MyFirstZnode";
byte[] data = "Success".getBytes(); //Assign data which is to be updated.
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
update(path, data); // Update znode data to the specified path
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
编译并执行应用程序后,指定的znode的数据将被改变,并且可以使用ZooKeeper CLI zkCli.sh 进行检查。
cd /path/to/zookeeper
bin/zkCli.sh
>>> get /MyFirstZnode
getChildren方法
ZooKeeper类提供 getChildren 方法来获取特定znode的所有子节点。 getChildren 方法的签名如下:
getChildren(String path, Watcher watcher)
path - Znode路径。
watcher - 监视器类型的回调函数。当指定的znode被删除或znode下的子节点被创建/删除时,ZooKeeper集合将进行通知。这是一次性通知。
编码:ZKGetChildren.java
import java.io.IOException;
import java.util.*;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetChildren {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path
if(stat!= null) {
//“getChildren" method- get all the children of znode.It has two
args, path and watch
List <String> children = zk.getChildren(path, false);
for(int i = 0; i < children.size(); i++)
System.out.println(children.get(i)); //Print children's
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}
在运行程序之前,让我们使用ZooKeeper CLI zkCli.sh 为 /MyFirstZnode 创建两个子节点。
cd /path/to/zookeeper
bin/zkCli.sh
>>> create /MyFirstZnode/myfirstsubnode Hi
>>> create /MyFirstZnode/mysecondsubmode Hi
现在,编译和运行程序将输出上面创建的znode。
myfirstsubnode
mysecondsubnode
删除Znode
ZooKeeper类提供了 delete 方法来删除指定的znode。 delete 方法的签名如下:
delete(String path, int version)
-
path - Znode路径。
-
version - znode的当前版本。
让我们创建一个新的Java应用程序来了解ZooKeeper API的 delete 功能。创建文件 ZKDelete.java 。在main方法中,使用 ZooKeeperConnection 对象创建一个ZooKeeper对象 zk 。然后,使用指定的路径和版本号调用 zk 对象的 delete 方法。
删除znode的完整程序代码如下:
编码:ZKDelete.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
public class ZKDelete {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static void delete(String path) throws KeeperException,InterruptedException {
zk.delete(path,zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; //Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
delete(path); //delete the node with the specified path
} catch(Exception e) {
System.out.println(e.getMessage()); // catches error messages
}
}
}
Zookeeper 应用程序
Zookeeper为分布式环境提供灵活的协调基础架构。ZooKeeper框架支持许多当今最好的工业应用程序。我们将在本章中讨论ZooKeeper的一些最显着的应用。
雅虎
ZooKeeper框架最初是在“Yahoo!”中构建的。设计良好的分布式应用程序需要满足诸如数据透明度,更好的性能,稳健性,集中配置和协调等要求。所以,他们设计了ZooKeeper框架来满足这些要求。
Apache Hadoop
Apache Hadoop是大数据行业发展的推动力。Hadoop依靠ZooKeeper进行配置管理和协调。让我们来了解一下ZooKeeper在Hadoop中的作用。
假设 Hadoop集群 桥接100个或更多的商品服务器。那么,就需要协调和命名服务。因此涉及大量节点的计算,每个节点需要彼此同步,知道在哪里访问服务器,以及知道如何配置它们。在这个时间点,Hadoop集群需要跨节点服务器。ZooKeeper提供跨节点同步的功能,并确保跨越Hadoop项目的任务被序列化和同步化。
多个ZooKeeper服务器支持大型Hadoop集群。每个客户端机器与ZooKeeper服务器之一通信以检索和更新其同步信息。一些实时示例如下:
-
人类基因组计划 - 人类基因组计划包含兆兆字节数据。Hadoop MapReduce框架可用于分析数据集并为人类发展找到有趣的事实。
-
医疗保健 - 医院可以存储,检索和分析大量患者医疗记录,通常为兆兆字节。
Apache HBase
Apache HBase是一个开源的,分布式的NoSQL数据库,用于大型数据集的实时读/写访问,并在HDFS上运行。HBase遵循主从架构,HBase主控制所有从机。从机称为区域服务器。
HBase分布式应用程序安装取决于运行的ZooKeeper集群。Apache HBase使用ZooKeeper通过集中式配置管理和分布式互斥机制来帮助主机和区域服务器跟踪分布式数据的状态。以下是一些HBase的用例:
-
电信 - 电信行业存储数十亿条移动通话记录(约30TB/月),实时访问这些通话记录成为一项巨大的任务。HBase可以用来实时,轻松,高效地处理所有记录。
-
社交网络 - 与电信行业类似,Twitter,LinkedIn和Facebook等网站通过用户创建的帖子接收大量数据。HBase可以用来查找最近的趋势和其他有趣的事实。
Apache Solr
Apache Solr是一个用Java编写的快速,开源的搜索平台。它是一个快速,容错的分布式搜索引擎。建立在 Lucene 之上,是一个高性能,全功能的文本搜索引擎。
Solr广泛使用ZooKeeper的每个功能,如配置管理,leader选举,节点管理,数据锁定和同步化。
Solr有两个不同的部分,索引和搜索。索引是以适当格式存储数据以便后续可以搜索的过程。Solr使用ZooKeeper对多个节点中的数据进行索引和搜索。ZooKeeper提供以下功能:
-
根据需要添加/删除节点
-
在节点之间复制数据,随后最小化数据丢失
-
在多个节点之间共享数据,随后从多个节点搜索以获得更快的搜索结果
Apache Solr的一些用例包括电子商务,求职搜索等。