实际上爬虫一共就四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
我们在之前写的爬虫程序中,都只是获取到了页面的全部内容,也就是只进行到了第2步,但是大部分的东西是我们不关心的,因此我们需要将之按我们的需要过滤和匹配出来。这时候我们就需要用到了正则表达式。
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
正则表达式匹配规则
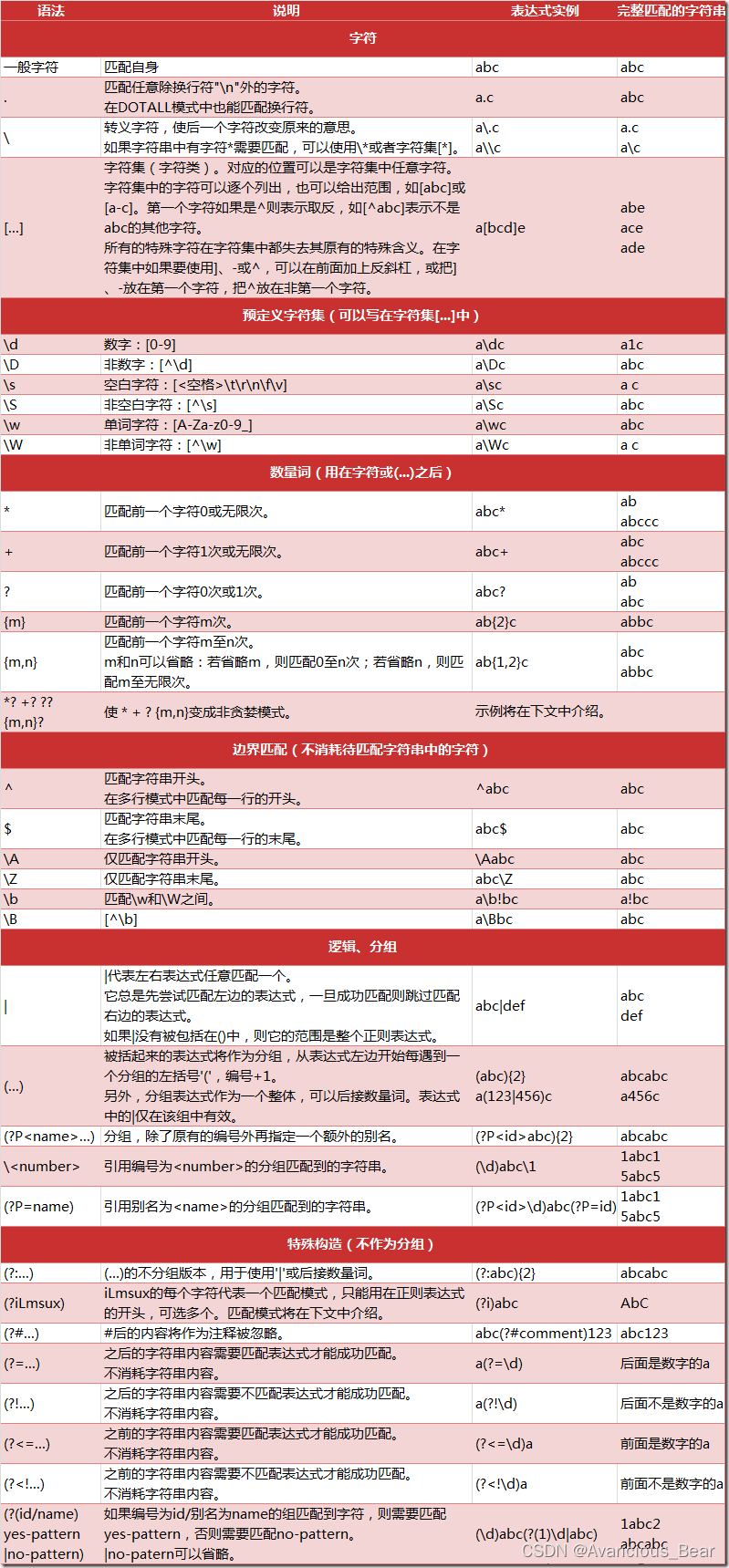
Python 的 re 模块
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,如下:
r'python\\t\\.\\tpython'
re 模块的一般使用步骤如下:
-
使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象 -
通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。 -
最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
1 import re
2
3 # 将正则表达式编译成 Pattern 对象
4 pattern = re.compile(r'\\d+')
在上面,我们已将一个正则表达式编译成 Pattern 对象,接下来,我们就可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
- match 方法:从起始位置开始查找,一次匹配
- search 方法:从任何位置开始查找,一次匹配
- findall 方法:全部匹配,返回列表
- finditer 方法:全部匹配,返回迭代器
- split 方法:分割字符串,返回列表
- sub 方法:替换
match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
1 import re 2
3 pattern = re.compile(r'\\d+') # 用于匹配至少一个数字
4
5 str = 'abc123def456'
6
7 p = pattern.match(str) # 查找头部,没有匹配
8 print(p) # None
9
10 p = pattern.match(str, 2, 9) # 从'c'的位置开始匹配,没有匹配
11 print(p) # None
12
13 p = pattern.match(str, 3, 9) # 从'4'的位置开始匹配,正好匹配, 返回一个 Match 对象
14 print(p) # <re.Match object; span=(3, 6), match='123'>
15
16 p = p.group(0) # 可省略 0
17 print(p) # 123
18
19 p = p.start(0) # 可省略 0
20 print(p) # 3
21
22 p = p.end(0) # 可省略 0
23 print(p) # 6
24
25 p = p.span(0) # 可省略 0
26 print(p) # (3, 6)
在上面,当匹配成功时返回一个 Match 对象,其中:
-
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
-
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
-
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
-
span([group]) 方法返回 (start(group), end(group))。
我们再来看一下具体用法:
1 import re 2
3 pattern = re.compile(r'(\[a-z\]+) (\[a-z\]+)', re.I) # 用于匹配至少一个字母, re.I 表示忽略大小写
4
5 str = 'Hello world hello Python'
6
7 p = pattern.match(str) # 查找头部,匹配成功,返回一个 Match 对象
8 print(p) # <re.Match object; span=(0, 11), match='Hello world'>
9
10 p = p.group(0) # 返回匹配成功的整个子串
11 print(p) # Hello world
12
13 p = p.group(1) # 返回第一个分组匹配成功的子串
14 print(p) # Hello
15 p = p.group(2) # 返回第二个分组匹配成功的子串
16 print(p) # world
17 p = p.group(3) # 不存在第三个分组
18 print(p) # IndexError: no such group
19
20 p = p.span(0) # 返回匹配成功的整个子串的索引
21 print(p) # (0, 11)
22 p = p.span(1) # 返回第一个分组匹配成功的子串的索引
23 print(p) # (0, 5)
24 p = p.span(2) # 返回第二个分组匹配成功的子串的索引
25 print(p) # (6, 11)
26 p = p.span(3) # 不存在第三个分组
27 print(p) # IndexError: no such group
28
29 p = p.start(0) # 返回匹配成功的整个子串的开始下标
30 print(p) # 0
31 p = p.end(0) # 返回匹配成功的整个子串的结束下标
32 print(p) # 11
33 p = p.start(1) # 返回第一个分组匹配成功的子串的开始下标
34 print(p) # 0
35 p = p.end(1) # 返回第一个分组匹配成功的子串的结束下标
36 print(p) # 5
37 p = p.start(2) # 返回第二个分组匹配成功的子串的开始下标
38 print(p) # 6
39 p = p.end(2) # 返回第二个分组匹配成功的子串的结束下标
40 print(p) # 11
41 p = p.start(3) # 返回第三个分组匹配成功的子串的开始下标
42 print(p) # IndexError: no such group
43 p = p.end(3) # 返回第三个分组匹配成功的子串的结束下标
44 print(p) # IndexError: no such group
45
46 p = p.groups() # 等价于 (m.group(1), m.group(2), ...)
47 print(p) # ('Hello', 'world')
search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
1 import re 2
3 pattern = re.compile(r'\\d+') # 用于匹配至少一个数字
4
5 str = 'abc123def456'
6
7 p = pattern.search(str) # 查找头部,匹配成功,返回一个 Match 对象
8 print(p) # <re.Match object; span=(3, 6), match='123'>
9
10 p = pattern.search(str, 1, 3) # 指定区间, 匹配失败,返回一个 None
11 print(p) # None
12
13 p = pattern.search(str, 8, 10) # 指定区间, 匹配成功,返回一个 Match 对象
14 print(p) # <re.Match object; span=(9, 10), match='4'>
findall 方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
1 import re 2
3 pattern = re.compile(r'\\d+') # 用于匹配至少一个数字
4
5 str = 'abc123def456'
6
7 p = pattern.findall(str) # 返回一个列表对象
8 print(p) # \['123', '456'\]
9
10 p = pattern.findall(str, 1, 3) # 返回一个列表对象
11 print(p) # \[\]
finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
1 import re 2
3 pattern = re.compile(r'\\d+') # 用于匹配至少一个数字
4
5 str = 'abc123def456'
6
7 p = pattern.finditer(str) # 返回一个 Match 对象
8 print(p) # <callable\_iterator object at 0x1054eb400>
9
10 p = pattern.finditer(str, 1, 3) # 返回一个 Match 对象
11 print(p) # <callable\_iterator object at 0x10552e358>
在实际中我们很少应用 finditer 方法,因为我们还需要对获取的 Match 对象进行进一步处理,如循环,group() 等来获取直观数据。
split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
1 import re
2
3 pattern = re.compile(r'\[\\s\\,\\;\]+') # 匹配至少一个空格和 ;
4
5 str = 'a,b;; c d'
6
7 p = pattern.split(str)
8 print(p) # \['a', 'b', 'c', 'd'\]
sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
-
如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
-
如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
-
count 用于指定最多替换次数,不指定时全部替换。
1 import re 2
3 pattern = re.compile(r'(\\w+) (\\w+)', re.I) # \\w = \[A-Za-z0-9\]
4
5 str = 'Hello 123, hello 456'
6
7 p = pattern.sub(r'hello World', str) # 使用 'hello World' 替换 'Hello 123' 和 'hello 456'
8 print(p) # hello World, hello World
9
10 p = pattern.sub(r'hello World', str, 1) # 使用 'hello World' 替换 'Hello 123', 1 表示最多替换一次
11 print(p) # hello World, hello 456
本文仅做项目练习,切勿商用
由于文章篇幅有限,文档资料内容较多,需要这些文档的朋友,可以加小助手微信免费获取,【保证100%免费】,中国人不骗中国人。

全套Python学习资料分享:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
今天的分享就到这里,再见