大家好,大型语言模型(LLMs)正引领人工智能技术的创新浪潮。自从OpenAI推出ChatGPT,企业、开发者纷纷寻求定制化的AI解决方案,从而催生了对开发和管理这些模型的工具和框架的巨大需求。
LlamaIndex和LangChain作为两大领先框架,二者各自的特点和优势,将决定它们在不同场景下的应用。本文介绍这两个框架的主要差异,帮助大家做出明智的选择。
1 LlamaIndex
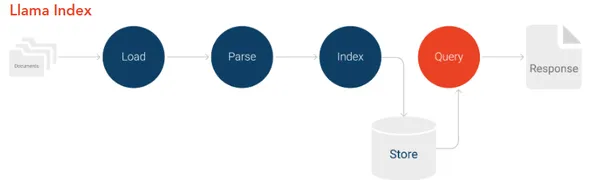
LlamaIndex 流程
LlamaIndex框架简化了对大型语言模型的个性化数据索引和查询,支持多种数据类型,包括结构化、非结构化及半结构化数据。
LlamaIndex通过将专有数据转化为嵌入向量,使数据能够被最新型的LLMs广泛理解,从而省去了重新训练模型的步骤,提高数据处理的效率和智能化水平。
1.1 工作原理
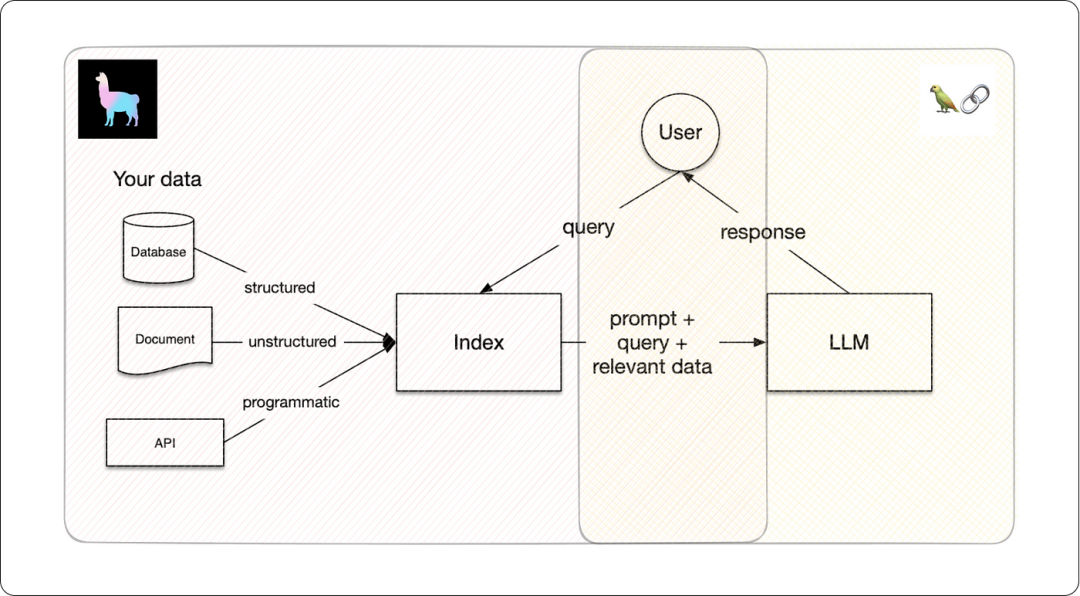
LlamaIndex 架构
LlamaIndex框架推动了大型语言模型(LLMs)的定制化发展。通过将专属数据嵌入内存,使模型在提供上下文相关回答时表现更佳,将LLMs塑造成领域知识专家。无论是作为AI助手还是对话机器人,LlamaIndex都能根据权威资料(如仅限高层访问的业务信息PDF)准确回应查询。
LlamaIndex采用检索增强生成(RAG)技术,定制化LLMs,包括两个核心步骤:
-
索引阶段:将专有数据转化为富含语义信息的向量索引。
-
查询阶段:系统接收到查询后,迅速匹配并返回最相关的信息块,结合原始问题,由LLM生成精准答案。
1.2 LlamaIndex快速入门
安装llama-index:
pip install llama-index
使用 OpenAI 的 LLM 需要 OpenAI API 密钥。获得秘钥后,在 .env 文件中这样设置:
import os
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
1.3 构建问答应用:LlamaIndex实践
为了展示LlamaIndex的能力,下面进行代码演示,开发一个基于自定义文档回答问题的问答应用程序。
安装依赖项:
pip install llama-index openai nltk
使用LlamaIndex的SimpleDirectoryReader函数加载文档,开始构建索引:
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader
)
# 定义SDR函数内的路径,然后构建索引
documents = SimpleDirectoryReader("docs").load_data()
index = VectorStoreIndex.from_documents(documents, show_progress=True)
查询索引并检查响应:
# 查询引擎
query_engine = index.as_query_engine()
response = query_engine.query("If i miss my assignments and projects,
what grade and percentage will i end up with?")
print(response)
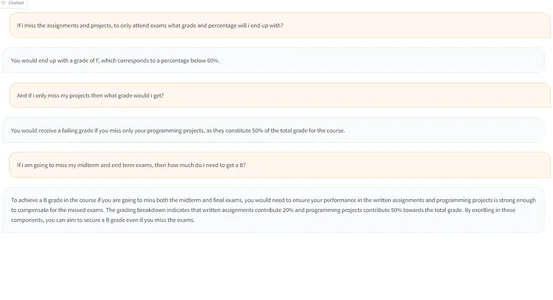
使用 LlamaIndex 建立的 LLM 响应
查询引擎将搜索数据索引,并以相关片段的形式返回响应。还可以通过修改函数将此查询引擎转换为具有记忆的聊天引擎:
chat_engine = index.as_chat_engine()
response = chat_engine.chat("If i miss my assignments and projects,
what grade and percentage will i end up with?")
print(response)
follow_up = chat_engine.chat("And if i only miss my projects,
then what grade would i get?")
print(follow_up)
为了避免每次重建索引,可以将其持久化到磁盘:
index.storage_context.persist()
稍后加载回来:
from llama_index.core import (
StorageContext,
load_index_from_storage,
)
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)2 LangChain
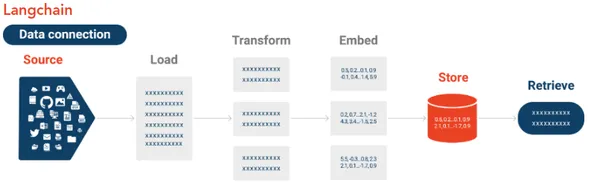
Langchain流程
LangChain是一个框架,专门用于基于自定义数据构建个性化的大型语言模型(LLMs)。它能够整合多种数据源,包括关系型数据库、非关系型数据库、APIs,以及自定义知识库。
LangChain通过链式机制运作,将一系列请求和集成工具的输出依次传递,形成连续的处理流程。利用这一机制,LangChain不仅能够确保从您的专有数据中提取相关上下文,还能生成恰当的响应,无论是用于公司的定制问答机器人、内部分析还是与数据源协同工作的AI助手。其内置的链式结构,便于开发者将多样的工具整合进LLM应用,构建出功能全面的系统。
2.1 工作原理
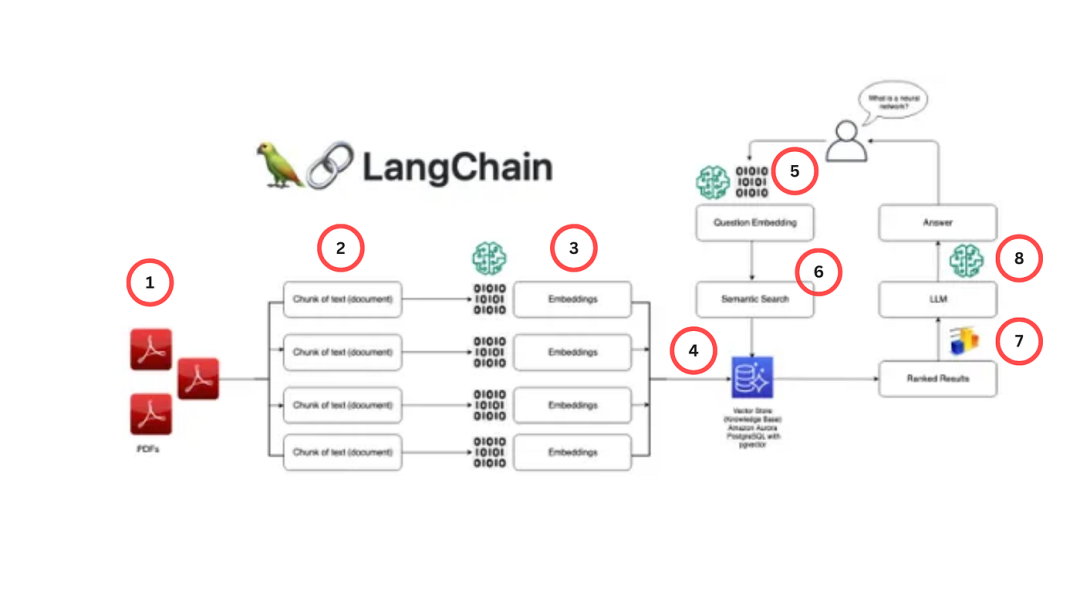
Langchain架构
LangChain框架由以下核心组件构成:
-
提示(Prompts):这是向模型发出的指令,用以引导模型产生预期的输出或响应。
-
模型接口:LangChain提供了一个用户界面,允许用户快速更换并测试不同的语言模型,包括最新的GPT-4、Gemini 1.5 pro、Hugging Face LLM、Claude 3等。
-
索引技术:框架采用嵌入和内存向量存储等技术,以优化数据的索引和检索。
-
组件链式连接:LangChain简化了不同组件之间的连接流程,使得构建复杂的处理链变得轻而易举。
-
AI智能体:提供一系列智能体,协助用户管理和分配任务,以及工具的使用。
2.2 LangChain快速入门
安装LangChain:
pip install langchain
这里使用cohere API密钥。在.env文件中使用 API 密钥设置 cohere 环境变量:
import os
os.environ["cohere_apikey"] = "your_api_key_here"
2.3 构建问答应用:LangChain实践
下面进行代码演示,开发一个基于自定义文档回答问题的问答应用程序。
第一步是安装依赖项:
pip install langchain cohere chromadb ## 我们使用cohere而不是OpenAI的LLM
接着,加载文档数据并创建索引。还将使用 cohere 嵌入生成嵌入:
from langchain.document_loaders import OnlinePDFLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import CohereEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = OnlinePDFLoader(document)
documents = loader.load()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunksize,chunk_overlap=10,
separators=[" ", ",", "\n"])
# 初始化Cohere嵌入
embeddings = CohereEmbeddings(model="large", cohere_api_key=st.secrets["cohere_apikey"])
texts = text_splitter.split_documents(documents)
global db
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()
global qa
查询索引并检查响应:
query = "Compare indian constitution's approach to secularism with
that of other countries?"
result = db.query(query)
print(result)
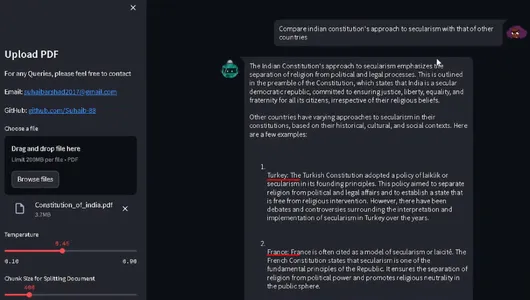
使用 Langchain 建立的 LLM 响应
查询将对数据进行语义搜索,并检索出对查询的适当回应。如果需要可以使用 langchain 的RetrievalQA模块进行链式处理,这里也使用 cohere 的 LLM:
from langchain.llms import Cohere
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=Cohere(
model="command-xlarge-nightly",
temperature=temp_r,
cohere_api_key=st.secrets["cohere_apikey"],
),
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs,
)
3 LlamaIndex与LangChain应用场景
3.1 LlamaIndex
-
构建具有特定知识库的查询和基于搜索的信息检索系统。
-
开发能够针对用户查询仅提供相关信息片段的问答聊天机器人。
-
对大型文档进行摘要、文本补全、语言翻译等。
3.2 LangChain
-
构建端到端的会话聊天机器人和AI智能体。
-
将自定义工作流程集成到大型语言模型(LLMs)中。
-
通过APIs和其他数据源扩展LLMs的数据连接选项。
3.3 LlamaIndex和LangChain的结合使用案例
-
构建专家级AI智能体:LangChain能够整合多种数据源,而LlamaIndex能够根据相似性语义搜索能力进行策划、摘要,并生成更快的响应。
-
高级研发工具:利用LangChain的链式机制同步管理工具和工作流程,同时使用LlamaIndex帮助生成更具上下文意识的LLM,并获取最相关的响应。
4 选择框架:LlamaIndex vs LangChain
在选择LlamaIndex与LangChain这两个框架之前,需要思考几个关键问题:
-
项目需求:如果目标是构建基础的索引、查询搜索和数据检索系统,LlamaIndex将是合适的选择。若项目需要集成复杂的自定义工作流程,则LangChain将更加合适。
-
易用性:LlamaIndex以其简洁的界面著称,易于上手。相比之下,LangChain则要求用户对自然语言处理(NLP)的概念和组件有更深入的了解。
-
定制程度:LangChain的模块化设计让其在定制化和工具集成方面更为灵活。而LlamaIndex则专注于提供高效的搜索和检索功能。
综上所述,LlamaIndex和LangChain都是构建定制化LLM应用的有力工具。LlamaIndex擅长搜索和检索,而LangChain则以其模块化和集成性胜出。如何选择取决于具体的项目需求、易用性偏好和定制化程度。
如果追求多功能集成和AI智能体,LangChain是理想选择。若目标是高效的信息索引和检索,LlamaIndex则更加合适,并且这两个框架可以协同工作。