在2023年11月,谷歌研究院发布了一项令人瞩目的研究成果——Generative Image Dynamics(生成图像动力学)。这项技术的核心是将静态的图片转化为动态的、无缝循环的视频,而且更令人兴奋的是,这些生成的视频还具有交互性。
一作Zhengqi Li,作为谷歌研究院的杰出科学家,专注于3D/4D计算机视觉、基于图像的渲染以及计算摄影的研究。他尤其擅长处理“in the wild”图像和视频,即那些在非受控环境下捕获的复杂数据。在康奈尔大学攻读计算机科学博士学位期间,师从著名学者Noah Snavely。Zhengqi Li的杰出贡献得到了业界的广泛认可,曾荣获CVPR 2019最佳论文荣誉提名奖,并于2020年获得谷歌博士奖学金和奥多比研究奖学金。在随后的职业生涯中,他再接再厉,于2021年获得百度全球人工智能100强中国新星奖,在CVPR 2023上荣获最佳论文荣誉奖,更在CVPR 2024的评选中获得最佳论文奖。这些荣誉充分展现了Zhengqi Li在计算机视觉领域的卓越才华和持续贡献。
该研究提出了一种对场景运动建模图像—空间先验的方法。该先验是从真实视频序列中提取的运动轨迹集合中学习而来,描绘了物体的自然振荡动力学,例如树木、衣服等物体在风中摇曳。该研究将傅立叶域中密集、长期运动建模为频谱体积(spectral volume),研究团队发现这非常适合用扩散模型预测。
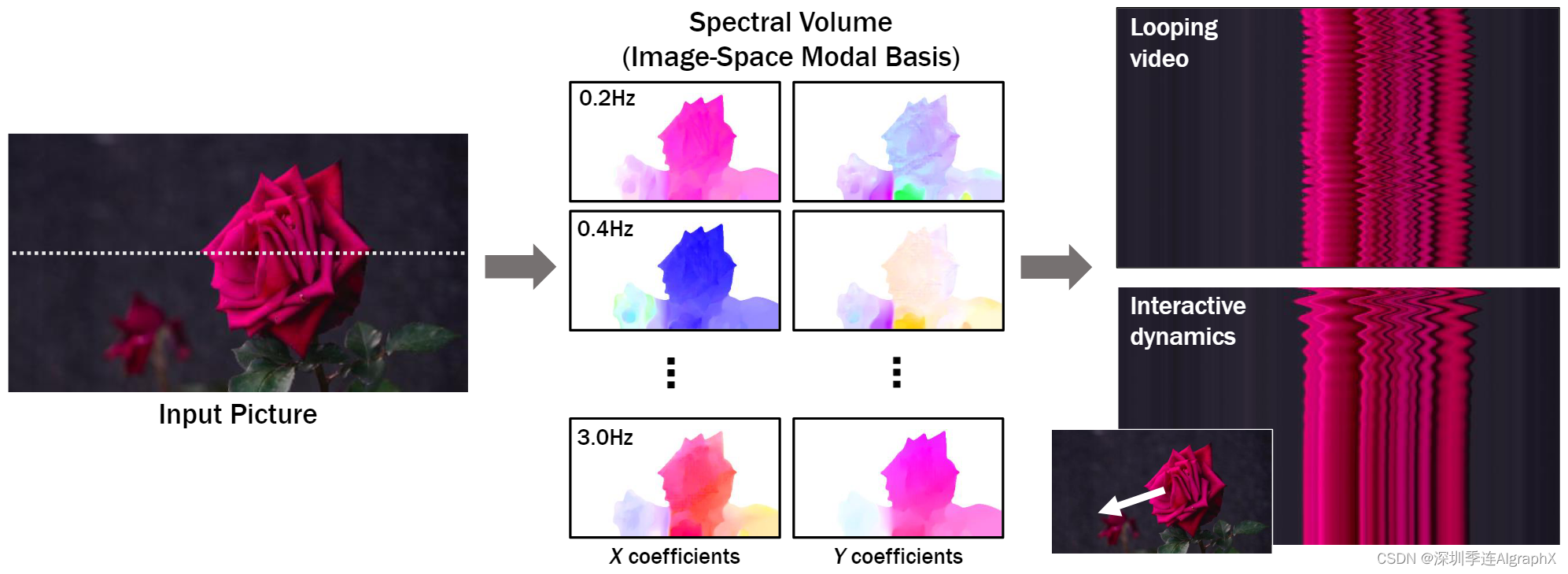
Figure 1. We model a generative image-space prior on scene motion
该研究可以通过调整运动纹理的幅度来缩小(顶部)或放大(底部)动画运动。

与基于图像的渲染模块一起,预测的运动特征可用于许多下游应用,例如将静止图像变成无缝循环视频,或者允许用户与真实图像中的对象进行交互,产生逼真的动态模拟。


本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删,转发请注明出处。
Abstract
我们提出了一种基于场景运动图像空间先验的建模方法。先验知识是从真实运动轨迹序列中学习,这些运动轨迹描绘了树木、花朵、蜡烛和在风中摇摆的衣服等物体的自然振荡动力学。我们将傅里叶域中密集、长期的运动建模为频谱体积spectral volumes,我们发现这非常适合用扩散模型进行预测。给定单个图像,训练模型使用频率协调扩散frequency-coordinated diffusion采样过程来预测频谱体积,可以将其转换为跨整个视频的运动纹理。与基于图像渲染模块一起,预测运动表示可用于许多下游应用,例如将静止图像转换为无缝循环视频,或允许用户与真实图像对象进行交互,产生逼真的动态变化(通过将频谱体积解释为图像空间模态基)。
项目网址:Generative Image Dynamics
1. Introduction
自然世界总是在运动中,即使是看似静态的场景,即使风、水流、呼吸或其他自然韵律,也包含不易觉察的振荡。模拟这种运动对于视觉内容合成至关重要——人类对运动的敏感性会导致没有运动的图像看起来不可思议或不真实。
虽然人类很容易解释或想象场景中的运动,但训练模型来学习或产生逼真的场景运动绝非易事。我们在现实世界中观察到的运动是底层物理动力学的结果,即施加在物体上的力根据其独特的物理特性(质量、弹性等)做出反应,这些物理特性很难在一定范围内测量和捕捉。幸运的是,对于某些应用程序来说,测量它们不是必需的:例如,可以通过简单地分析一些观察到的 2D 运动来模拟场景中的合理动态。
这种运动也可以作为跨场景学习的监督信号——因为尽管观察到的运动是多模态的,并且基于复杂的物理效应,但它仍然通常是可预测的:蜡烛会以某种方式闪烁,树木会摇摆,树叶会沙沙作响。对于人类来说,这种可预见性在我们的感知系统中根深蒂固:通过查看静止图像,我们可以想象合理的运动——或者,由于可能有许多可能的这样的运动,自然运动的分布取决于该图像。考虑到人类有模拟这些分布的能力,一个自然的研究问题是通过计算来模拟。
生成模型特别是条件扩散模型的最新进展使我们能够对丰富的分布进行建模,包括以文本为条件的真实图像分布。该功能支持几个新应用,例如以文本为条件生成各种逼真的图像内容。随着这些图像模型的成功,最近的工作将这些模型扩展到其他领域,如视频和3D几何。
在本文中,我们为图像空间场景运动建模生成先验,即单个图像中所有像素的运动。该模型从大量真实视频序列中自动提取运动轨迹来进行训练。特别是,从每个训练视频中,我们以频谱体积的形式计算运动,这是密集长像素轨迹的频域表示。
- Image-space modal bases for plausible manipulation of objects in video,2015
- Visual vibration analysis,2016
频谱体积非常适合表示振荡动力学的场景,例如,树木和花朵在风中移动。我们发现这种表示作为扩散模型输出来建模场景运动也非常有效。我们训练了一个生成模型,该模型以单个图像为条件,从学习分布中采样频谱体积。然后,预测的频谱体积可以直接转换为运动纹理——一组逐像素的长运动轨迹——可以用来使图像动画化。频谱体积也可以解释为图像空间模态基——用于模拟交互动力学。
我们使用扩散模型从输入图像中预测频谱体积,该模型每次生成一个频率的系数,但通过共享注意力模块跨频段协调这些预测。预测的运动可以用来合成未来帧(通过基于图像的渲染模型)——将静止图像转化为逼真的动画,如图1所示。
与原始RGB像素的先验相比,运动先验捕捉更基本,更低维的结构,有效地解释了像素值的长期变化。因此,生成中间运动有助于更连贯的长期生成和对动画更细粒度控制。我们演示了几个下游应用,例如创建无缝循环视频、编辑生成运动,以及通过图像空间模态基建立交互式动态图像,即针对用户施加的力来模拟物体动态响应。
2. Related Work
Generative synthesis.
生成模型的最新进展使基于文本提示的图像合成成为可能。这些文本到图像的模型可以通过沿着时间维度扩展生成的图像张量来增强合成视频序列。虽然这些方法可以产生视频序列,捕捉真实镜头的时空统计信息,然经常会出现伪影,如不连贯的运动、纹理中不切实际的时间变化,以及违反物理约束。
Animating images.
其他技术不是完全从文本生成视频,而是将静止图片作为输入,并使其动画化。最近许多深度学习方法采用3D-Unet架构直接生成视频。这些模型实际上是相同的视频生成模型(但以图像信息而不是文本为条件),并且表现出与上述相似的伪影。克服这些限制的一种方法是不直接生成视频内容本身,而是通过基于图像的渲染对输入源图像进行动画处理。即根据来自外部源的运动如驾驶视频、运动或三维几何先验或用户标注移动图像周围内容。根据运动场对图像进行动画会产生更大的时间一致性和真实感,但这些先前的方法要么需要额外的引导信号或用户输入,要么利用有限的运动表示。
Motion models and motion priors.
在计算图形学中,自然振荡的3D运动(例如,水的波纹或风中摇曳的树木),可以用在傅立叶域中形成的噪声来建模,然后转换为时域运动场。其中一些方法依赖于被模拟系统潜在动力学的模态分析。
Chuang等人在给定用户标注的情况下,将这些频谱技术用于从单张2D图片中绘制植物、水和云的动画。我们的工作特别受到[Visual vibration analysis,2016]的启发,他将场景的模态分析与该场景视频中观察到的运动联系起来,并使用该分析来模拟视频中的交互动态。我们采用频率-空间频谱体积运动表示法frequency-space spectral volume motion representation,并从大量训练视频中提取该表示法。结果表明,频谱体积适用于具有扩散模型的单幅图像运动预测。其他方法在预测任务中使用了各种运动表示,其中使用图像或视频来告知确定性的未来运动估计,或更丰富的可能运动分布。然而这些方法大部分是预测光流运动估计(即,每个像素的瞬时运动),而不是完整的运动轨迹。此外,之前的许多工作都集中在活动识别等任务上,而不是综合任务上。最近的研究表明,在人类和动物等封闭领域环境中,使用生成模型建模和预测运动具有优势。
Videos as textures.
某些移动场景可以被认为是一种纹理——称为运动纹理——它将视频建模为随机过程的时空样本。运动纹理可以表示平滑、自然的运动,如波浪、火焰或移动的树木,并已广泛用于视频分类、分割或编码。另一种相关的纹理称为视频纹理,它将运动场景表示为一组输入视频帧以及任意帧对之间的过渡概率。许多方法通过分析场景运动和像素统计来估计运动或视频纹理,目的是生成无缝循环或无限变化的输出视频。与此工作相比,我们的方法可以提前学习先验,然后将其应用于单个图像。
3. Overview
给定一张图片I0,我们的目标是生成一个具有振荡运动的视频{^I1, ^I2,… ^It},如在微风中摇曳的树木、花朵或蜡烛火焰。我们的系统由两个模块组成:运动预测模块和基于图像的渲染模块。我们的流程首先使用潜在扩散模型LDM,输入I0,预测频谱体积S = (Sf0 , Sf1 , ..., SfK−1)。然后通过离散傅里叶反变换,将预测的频谱体积转换为运动纹理F = (F1, F2,… FT)。这个运动决定了每个输入像素在未来每个时间步长的位置。
给定预测的运动纹理,然后我们使用基于神经图像的渲染技术对输入的RGB图像进行动画处理(第5节)。我们在第6节中探索了这种方法的应用,包括生成无缝循环动画和模拟交互动态。
4. Predicting motion
4.1. Motion representation
形式上,运动纹理是一系列时变的2D位移映射 F = {Ft|t = 1, ..., T }。其中,从输入图像I0开始的每个像素坐标p处的2D位移向量Ft(p)定义了该像素在未来时刻 t 的位置。为了在时间 t 生成未来帧,可以使用相应的位移映射Dt从I0中分割像素,从而得到前向扭曲图像
![]()
我们的目标是通过运动纹理制作视频,那么一种选择是直接从输入图像中预测时域运动纹理。然而,运动纹理的大小需要根据视频的长度进行缩放:
生成T个输出帧意味着预测T个位移场。为了避免预测长视频如此大的输出表示,许多先验动画方法要么自回归生成视频帧,要么通过额外的时间嵌入独立预测每个未来输出帧。然而,这两种策略都不能保证生成视频的长时间一致性。
幸运的是,许多自然运动可以被描述为以不同频率、幅度和相位表示的少数谐波振荡器叠加。因为这些潜在运动是准周期的,所以在频域对它们进行建模是很自然的。因此,我们采用了[Visual vibration analysis,2016]对视频运动一种有效的频率空间表示,称为频谱体积,如图 1 所示。频谱体积是从视频中提取的逐像素轨迹的时间傅里叶变换,组织成称为模态图像的图像。
以前工作进一步表明,在某些假设下,在特定频率下评估的频谱体积形成了一个图像空间模态基,它是底层场景的振动模式投影(或者更一般地说,捕捉运动中的空间相关性)。我们使用术语频谱体积来指代特定运动纹理的频率空间编码(去除高频)。稍后,当频谱体积用于模拟时,我们也将其称为“图像空间模态基”。
鉴于这种运动表示,我们将运动预测问题表述为多模态图像到图像的转换任务:从输入图像到输出运动频谱体积。我们采用潜在扩散模型LDM来生成由4K通道2D运动频谱图组成的频谱体积,其中K << T是建模的频率数,并且在每个频率上我们需要四个标量来表示x和y维度的复傅立叶系数。
注意,像素在未来时间步长运动轨迹 F(p) = {Ft(p)|t = 1, 2, ...T }
及其频谱体积 S(p) = {Sfk (p)|k = 0, 1,...,T2 -1} 通过快速傅里叶变换 (FFT) 关联:
![]()
如何选择K个输出频率?
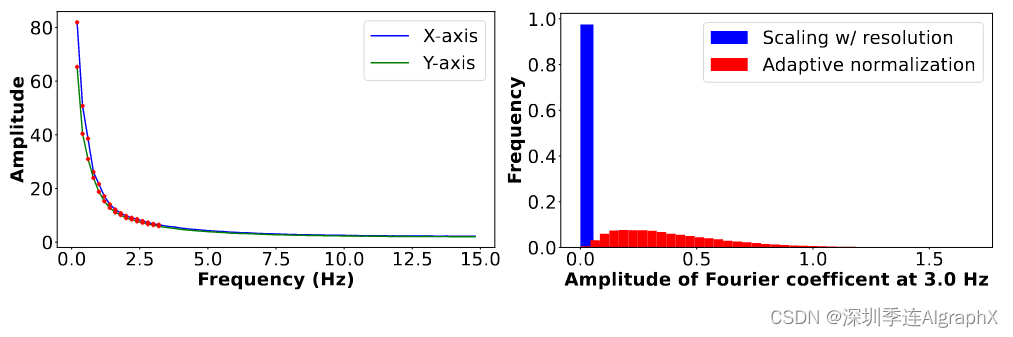
先前的实时动画研究工作发现,大多数自然振荡运动主要由低频成分组成。为了验证这一观察结果,我们计算了从1000个随机采样的5秒真实视频片段中提取的运动的平均功率频谱。如图 2 左图所示,运动的功率频谱随着频率的增加呈指数递减。这表明大多数自然振荡运动确实可以用低频项很好地表示。在实践中,我们发现第一个K = 16傅立叶系数足以在一系列真实视频和场景中逼真地再现原始的自然运动。
4.2. Predicting motion with a diffusion model
我们选择潜在扩散模型LDM作为运动预测模块的主干,因为LDM比像素空间扩散模型计算效率更高,同时保持合成质量。

Frequency adaptive normalization.
我们观察到的一个问题是,运动纹理在频率上具有特定的分布特征。如图 2 左图所示,频谱体积的振幅范围为0到100,并且随着频率的增加近似呈指数衰减。由于扩散模型需要输出值在0到1之间才能进行稳定的训练和去噪,因此我们必须对从真实视频中提取的S系数进行归一化,然后再使用它们进行训练。如果我们像之前的工作一样,根据图像尺寸将这些系数的大小缩放到[0,1],则几乎所有高频系数最终都接近于零,如图 2 的右图所示。在这些数据上训练的模型可能会产生不准确的运动,因为在推理过程中,即使很小的预测误差也会在非规范化后导致较大的相对误差。
为了解决这个问题,我们采用了一种简单但有效的频率自适应归一化方法:首先,我们根据从训练集计算的统计数据独立地归一化每个频率的傅里叶系数。也就是说,对于每个单独的频率 fj,我们计算所有输入样本的傅里叶系数幅度的97个百分位数,并将该值用作每频率缩放因子sfj。然后,我们对每个缩放后的傅里叶系数进行幂变换,使其远离极值。在实践中,我们观察到平方根比其他非线性变换(如对数或倒数)表现得更好。总之,频谱体积S(p)在频率 fj (用于训练我们的LDM)的最终系数值计算为

如图 2 右图所示,经过频率自适应归一化处理后,频谱体积系数分布更加均匀。
Frequency-coordinated denoising.
预测具有K个频带的频谱体积S的直接方法是从单个扩散U-Net输出4K通道的张量。然而,正如之前的工作,我们观察到训练一个模型来产生大量的通道可能会产生过度平滑的、不准确的输出。另一种选择是通过向LDM中注入额外的频率嵌入来独立预测每个单独频率,但这种设计选择将导致频域中不相关的预测,从而导致不切实际的运动。
因此,受最近视频扩散工作的启发,我们提出了一种频率协调去噪策略,如图 3 所示。
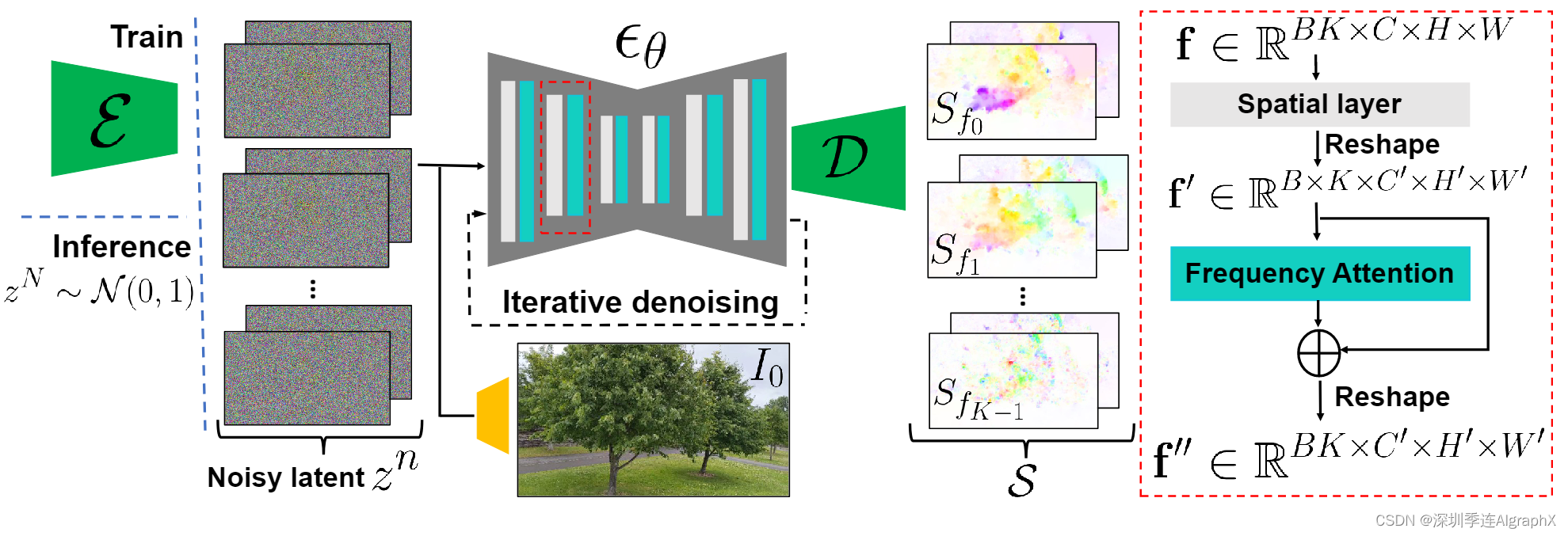
Figure 3. Motion prediction module.
特别的,给定输入图像I0,我们首先训练LDM εθ来预测频谱体积Sfj的单个4通道频率,其中我们将额外的频率嵌入与时间步长嵌入一起注入LDM。然后,我们冻结LDM的参数,在K频段上引入与εθ的2D空间层交织的注意层,并进行微调。
具体来说,对于批大小B, εθ的2D空间层将通道大小C对应的B·K噪声潜在特征视为形状为R(B·K)×C×H×W的独立样本。然后,注意层将这些解释为跨频率轴的连续特征,我们将先前2D空间层中的潜在特征重塑为RB×K×C×H×W,将它们提供给注意层。换句话说,频率注意层被微调以协调所有的频率切片,从而产生相干的频谱体积。在我们的实验中,我们看到当我们从单个2D U-Net切换到频率协调去噪模块时,平均VAE重建误差从0.024提高到0.018,这表明LDM预测精度的上限得到了提高;在第7.3节中,我们还展示了这种设计选择提高了视频生成质量。
5. Image-based rendering
现在,描述如何对给定输入图像I0预测频谱体积S,并在时间t上渲染未来的帧。首先使用应用于每个像素 F(p) =FFT−1(S(p)) 的逆时序 FFT 推导出时域的运动纹理。为了生成未来的帧^It,我们采用基于深度图像的渲染技术,并使用预测的运动场Ft进行溅射,对编码后的I0进行正向扭曲,如图 4 所示。由于前向扭曲会导致孔洞,并且多个源像素可以映射到相同的输出2D位置,因此我们采用先前在帧插值中提出的 feature pyramid softmax splatting 策略。
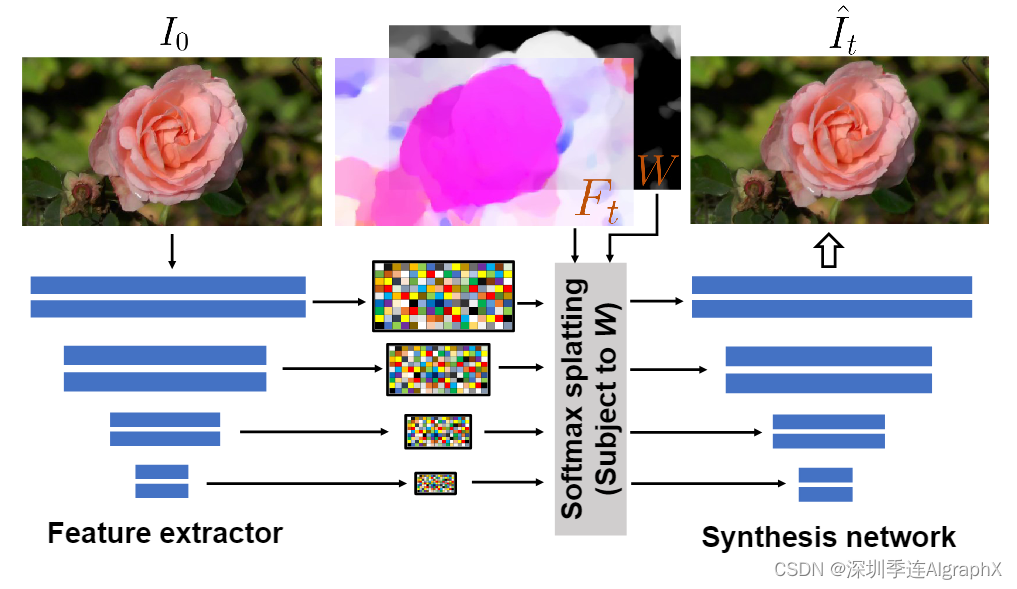
Figure 4. Rendering module.
具体而言,我们通过特征提取器网络对I0进行编码,生成多尺度特征图。对于尺度为 j 的每个单独的特征图,我们根据分辨率调整预测的2D运动场Ft的大小。与先前工作一样,我们使用预测的流Flow大小作为深度的代理,以确定映射到其目标位置的每个源像素贡献权重。特别是,我们计算了每像素的权重W (p) = 1/T Pt || Ft(p) ||2 作为预测运动纹理的平均大小。换句话说,我们假设大的运动对应于移动的前景物体,小的或零的运动对应于背景。我们使用运动衍生的权重,而不是可学习的权重,因为我们观察到在单视图情况下,可学习的权重不能有效地解决消光歧义。
对于运动场Ft和权重W,我们应用 softmax splatting 在每个尺度上变换特征映射,以产生变形的特征。然后将新特征注入到图像合成解码器的相应块中,以产生最终渲染的图像。我们使用从真实视频中随机采样的起始帧和目标帧(I0, It)共同训练特征提取器和合成网络,使用I0到It的估计流场来变换I0的编码特征,并使用VGG感知损失监督预测。
6. Applications
Image-to-video.
我们的系统通过首先从输入图像预测运动频谱体积,并通过应用基于图像的渲染模块对从频谱体积转换的运动纹理生成动画,从而实现单个静止图像的动画。由于我们明确地模拟场景运动,这允许我们通过线性插值运动纹理来制作慢动作视频,或者通过调整预测的频谱体积系数的幅度来放大(或缩小)动作。
Seamless looping.
许多应用程序需要无缝循环的视频,在视频的开始和结束之间没有间断。不幸的是,很难找到大量的无缝循环视频用于培训。相反,我们设计了一种方法来使用我们的运动扩散模型,在常规的非循环视频剪辑上训练,以产生无缝循环视频。受近期图像编辑指导工作的启发,我们的方法是一种运动自引导技术,使用显式循环约束指导运动去噪采样处理。特别是,在推理过程中的每个迭代去噪步骤中,我们在标准无分类器引导的基础上加入了一个额外的运动引导信号,其中我们强制每个像素在开始帧和结束帧的位置和速度尽可能相似:

其中,Fn/t为预测的2D位移场时刻,去噪步数n, w为无分类器引导权值,u为运动自引导权值。在补充视频中,我们应用了基于基线外观的循环算法,从我们的非循环输出中生成循环视频,并表明我们的运动自引导技术产生的无缝循环视频失真更少,伪影更少。
Interactive dynamics from a single image.
以前工作在某些共振频率下评估的频谱体积可以近似图像空间模态基,即底层场景振动模式的投影(或者,更一般地说,捕获振荡动力学中的空间和时间相关性),并可用于模拟对象对用户定义力的响应。我们采用这种模态分析方法,使我们能够将物体物理响应的图像空间2D运动位移场写成运动谱系数Sfj的加权和,该运动谱系数由每个模拟时间步长t处的复模态坐标qfj(t)的状态调制:
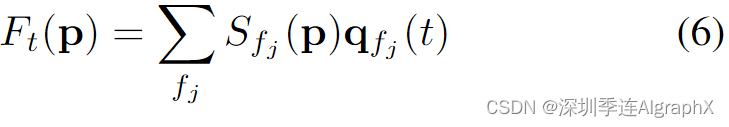
复模态坐标qfj(t)通过一种应用于模态空间中质量-弹簧-阻尼解耦系统运动方程的显式欧拉方法来模拟。我们建议读者参阅补充材料和原始作品以获得完整的推导。请注意,我们的方法从单个图片生成交互式场景,而之前的方法需要视频作为输入。
7. Experiments
Implementation details.
我们使用LDM[74]作为骨干来预测光谱体积,为此我们使用连续潜在空间为4维的VAE。我们用L1重建损失、多尺度梯度一致性损失和KL散度损失来训练VAE,其权重分别为1、0.2、10−6。我们训练原始LDM工作中使用的相同的2D U-Net,使用简单的MSE损失进行迭代去噪,并采用[41]中的注意层进行频率协调去噪。对于定量评估,我们从头开始训练大小为 256 × 160 图像的 VAE 和 LDM 以进行公平比较,使用 16 个 Nvidia A100 GPU 训练,收敛大约需要 6 天。为了主要的定量和定性结果,我们使用DDIM运行运动扩散模型250步。最后还展示了生成分辨率为 512 × 288 的视频,通过在我们的数据集上微调预训练图像修复 LDM 模型来创建。
我们在IBR模块中对特征提取器采用ResNet-34。我们的图像合成网络基于条件图像修复的架构。我们的渲染模块在推理过程中在Nvidia V100 GPU上以25FPS实时运行。我们采用通用指导来生成无缝循环视频,权重 w = 1.75, u = 200,并使用 500 步具有 2 次自重复迭代的 DDIM 步骤。
Data.
我们收集并处理了一组3015个自然场景的视频。自己拍摄的振荡运动视频,保留10%的视频用于测试,其余用于训练。为了提取地面真值运动轨迹,我们在每个选定的起始图像和视频的每个未来帧之间应用从粗到细的流方法flow method。作为训练数据,作为训练数据,我们将每第10视频帧作为输入图像,并使用接下来的149帧上计算运动轨迹来导出相应的地面真值频谱体积。总的来说,我们的数据由超过150K个图像-运动对组成。
7.1. Quantitative results
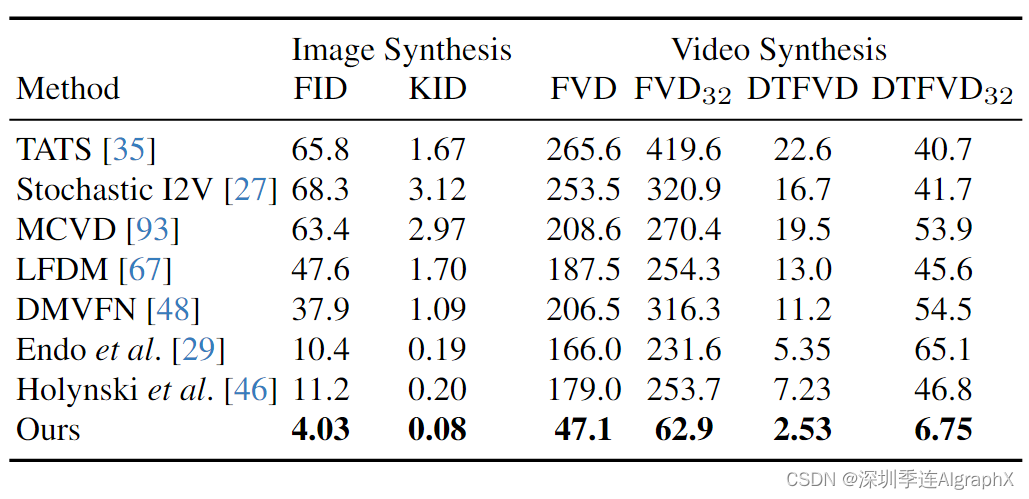
7.2. Qualitative results

7.3. Ablation study
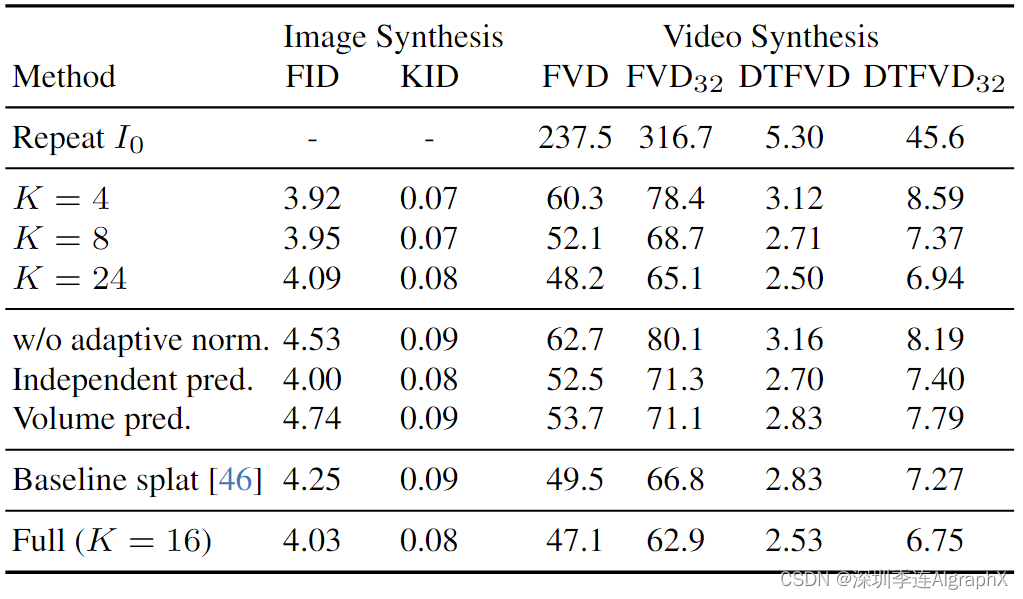
8. Discussion and conclusion
Limitations.
由于我们的方法只预测频谱体积的较低频率,它可能无法模拟非振荡运动或高频振动——这可以通过使用学习运动基来解决。此外,生成视频质量依赖于底层运动轨迹质量,在具有很小运动或具有大位移物体的场景中,性能可能会降低。即使正确,需要产生大量新的未见内容的运动也可能导致退化。
Conclusion.
我们提出了一种从单幅静止图像建模自然振荡动力学的新方法。我们的图像空间运动先验用频谱体积表示,频谱体积是每像素运动轨迹的频率表示,我们发现这对于扩散模型的预测是有效的,并且我们从真实世界的视频集合中学习。使用频率协调的潜在扩散模型预测频谱体积,并通过基于图像的渲染模块对未来视频帧进行动画处理。实验表明,我们的方法可以从一张图片中产生逼真的动画,明显优于先前的基线,并且它还可以支持一些下游应用程序,例如创建无缝循环或交互式的动态图。