目录
一、顺序表和链表的区别【表格】
二、顺序表优缺点
三、链表优缺点
四、缓存命中率(缓存利用率)
❥ 主存和本地二级存储
❥ 寄存器和三级缓存
❥ 顺序表缓存命中率
❥ 链表缓存命中率
一、顺序表和链表的区别【表格】
| 不同点 | 顺序表 | 链表(带头双向循环链表) |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问(用下标随机访问) | 支持 复杂度为O(1) | 不支持 复杂度为O(N) |
| 任意位置插入或者删除元素 | 可能需要搬移元素,效率低 复杂度为O(N) | 只需要修改指针的指向 |
| 插入 | 动态顺序表,空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 频繁插入和删除任意位置 |
| 缓存利用率 | 高 | 低 |
二、顺序表优缺点
优势
- 能够通过下标进行随机访问
- 物理上一定连续
- 缓存利用率高
缺点
- 扩容有消耗。扩容分为原地扩容和异地扩容,当为异地扩容时,消耗容量更多,因为还要进行数据的拷贝到新的空间,然后再释放掉原来的空间。
- 扩容还有可能存在空间浪费。例如:开辟了100个空间,却只用了80个,浪费了20个空间。
- 在插入删除时需要移动大量的元素
三、链表优缺点
优势
- 可以任意位置插入和删除元素
- 没有扩容的消耗,可以按需申请和释放
- 不浪费空间
缺点
- 不能用下标随机访问。所以链表排序意义不大,不如用数组进行排序(因为不能随机访问)
- 缓存利用率低
所以说,顺序表和链表是互补的线性结构
四、缓存命中率(缓存利用率)
❥ 主存和本地二级存储
下图1是计算机存储器的层次结构。计算机的内部存储体系分为很多层,其中有两个使我们所熟知的,分别是
- 主存:也就是电脑的内存
- 本地磁盘:也就是硬盘
内存和硬盘的区别:
- 内存:带电存储,速度很快,一个电脑内存一般是8/16G。
- 硬盘:不带电存储,速度较慢。
虽然他们的区别是速度快慢问题,但本质区别是他们是否带电存储。
那何为带电不带电存储呢?
举个例子 ! ! !
假设我们正在word上写笔记,这时候如果我们把电脑里的电池扣掉,那么正在word上写的笔记就会消失,再打开电脑就需要我们重新再写,为什么呢?
这是因为我们写的笔记不是存在硬盘中,而是存在内存。
为什么不存在硬盘呢?
是因为硬盘的速度比较慢。
那什么情况下它才会存在硬盘中呢?
我们点击左上角的保存(或者直接ctrl+s),鼠标转两个圈圈(转圈说明速度较慢),这样就会保存到文件中,也就保存到了硬盘当中。
若是存好之后我们又想修改一下我们的笔记,那修改之后的内容是不会存到文件中的,需要我们再次进行保存。
所以金字塔越往下存储容量越大,访问速度越来越慢,成本价格也越来越低。

❥ 寄存器和三级缓存
除此之外,我们发现每个电脑都还有一个寄存器和三级缓存。
补充:CPU和寄存器定义
- CPU(中央处理器)是一块超大规模的集成电路,它是计算机的运算核心和控制核心。它由控制单元、运算单元和存储单元组成,负责解释计算机指令和处理软件中的数据。
- 寄存器是位于CPU内部的一种物理存储器,用于高速存储指令和数据,设计目的是在CPU内部快速访问这些存储区域。
我们已经有了内存,且内存速度也还行,为什么还要有三级缓存呢?
分析如下:
代码:
int a = 0;
++a;转到反汇编(汇编就是对应的指令),如下图所示:

我们定义了变量a,这个变量i是存储在内存中,现在对a执行下一步指令(即++a)。
那么谁来对i执行++a指令呢?
是CPU。CPU可以执行各种各样的指令(加减乘除,异或等)。
上图我们可知:++a转到反汇编,分为三步执行:
- 首先它不是直接对内存a的位置进行++,它是把a从内存中读取出来,存储到eax这个寄存器
- 然后执行inc eax指令,对寄存器中的值进行自增
- 最后再把寄存器中自增完的值返回到ptr[a]这个位置。
为什么要这样做呢?
是因为它们不同频,cpu运行的速度太快,如果它直接去访问内存,把内存数据访问到,然后对内存的数据直接进行++,速度太慢;所以更愿意把这个数据从内存加载到寄存器,(因为访问寄存器很快,越往上速度越快),然后在寄存器中cpu执行这个指令(cpu中有加法器,执行完之后再把这个结果返回到内存里面),而不是去访问内存。
cpu通常是不会直接去访问内存,如果去访问内存的数据,内存的数据比较小,通常就会加载到寄存器。
这里的小指的是4/8个字节。
如果比较大就会加载到缓存(三级缓存),一级一级加载。
假设我们要执行一段指令,要访问顺序表和链表里的一段数据,例如:1 2 3 4
在这里这些数据分别是怎么访问的呢?
我们知道,不管是顺序表还是链表,这些数据都是在内存中(堆上)的。
假设我们要执行顺序表或链表 +1 -1 等类似操作,cpu是不会直接去访问这个内存的,而是加载到缓存去访问。
加载到缓存的原因:
因为这些数据1 2 3 4 太大,所以它们不会加载到寄存器中,而是加载到缓存当中。
假设我们要访问1 2 3 4 这一段数据,cpu就会查看首元素的地址在不在缓存
- 如果在缓存,就叫缓存命中,可以直接去访问
- 如果不在缓存,就叫不命中,数据会先从内存加载到缓存,再访问。

那到底是怎么加载到缓存呢?
在实际加载过程中,cpu每次不会只加载一个字或一个字节,而是一块块地加载(原因:局部性原理),它会认为当前位置的数据被访问了,那与之相邻地址的数据有很大概率也会被访问。
打个比方:
每个班里应该都发生过这种情况,我们正在上课。
这时候班主任突然进来说:5号你们这一列出来去把新书搬到班里。
到了楼下,班主任发现运了一车书,心想:这3个学生去搬不得累坏了。于是又到班里点了一列学生:4号这一列也出来一下。
我们发现:当班主任把5号这列叫走的时候,再去叫的时候最大可能就是叫4号这列,也就是和他们相邻的那一列。如果班主任叫人的时候,东叫一个,西叫一个,那班里不得乱糟糟的,任课老师怎么讲课啊!
那到底是加载多少字节到缓存呢?
一般是几十个字节,甚至是多少k,缓存会按照它的定义去拉取多少,它跟cpu的型号有关,叫作CPU的字长。
其实读这些数据就是探测这些二进制位是0还是1,把这个01通过电信号位读到了以后然后拿过来,它是有很多很多的线连接着,cpu访问一次,有多少根线,就是访问了多少个比特位。
❥ 顺序表缓存命中率
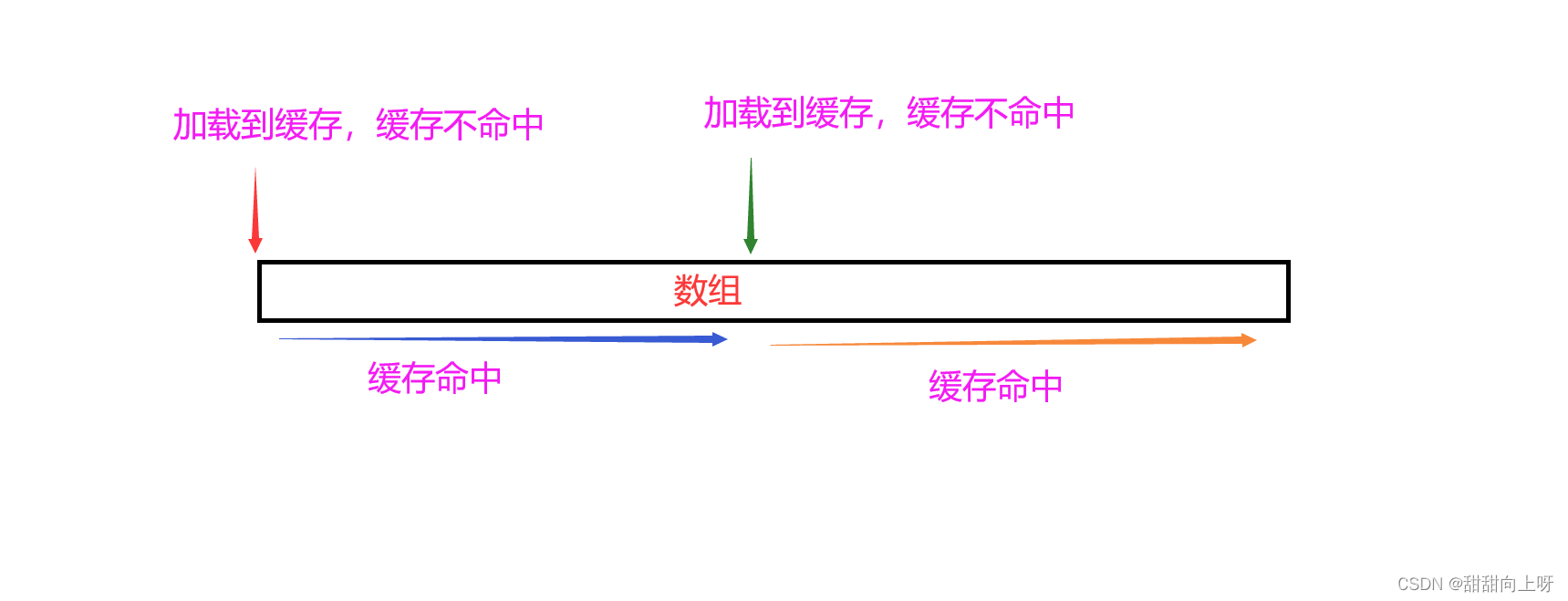
假设最开始去访问这些数据,这些数据是都没有被访问过的,也就在缓存中,那第一个数据就是不命中。
如果是数组的话,由于第一个数据不命中,会把首地址开始的一长段数据都加载到缓存中去,如果再访问第2个位置的数据,则在缓存,也就是缓存命中。
如果数据特别长,第一个不命中,然后后面连续一长段都命中,再不命中,然后再加载到缓存,后面一长段命中......以此类推。
这就叫做:缓存利用率高(缓存命中率高)。
❥ 链表缓存命中率
那链表为什么缓存利用率低呢?
我们知道,数组在内存中是连续存放的,而链表节点与节点之间的内存不一定连续,因为每次malloc的地址都是随机的。
第一次访问的时候,我们把第一个数据后面一连串连续的地址加载到缓存,虽然有可能会访问到后面的节点,但通常情况下是访问不到的,最坏的情况是后面的一个节点都没访问到,这就会造成:缓存利用率低(缓存命中率低)。
除了不命中之外,还会导致缓存污染。
缓存污染意思是:缓存空间大小是一定的,加载进来却没有用的数据把其它数据挤走,这就造成了缓存污染。