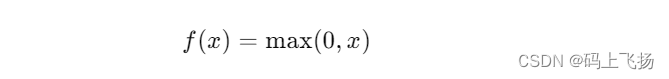可扩展性
概述
有些应用仅仅适用于一台或少数几台服务器,那么哪些可扩展性建议是和这些应用相关的呢?大多数人从不会维护超大规模的系统,并且通常也无法效仿在主流大公司所使用的策略。选择一个合适的策略能够大大地节约时间和金钱。
MySQL经常被批评很难进行扩展,有些情况下这种看法是正确的,但如果选择正确的架构并很好地实现,就能够非常好地扩展MySQL.但是扩展性并不是一个很好理解的主题。
什么是可扩展性
人们常常把诸如"可扩展性"、"高可用性"以及"性能"等术语在一些非正式的场合用作同一侧,但事实上它们是完全不同的。在前面我们将性能定义为响应时间。我们也可以很精确地定义可扩展性。简要地说,可扩展性表明了当需要增加资源以执行更多工作时系统能够获得划算地等同提升(equal bang for the buck)的能力。缺乏扩展能力的系统在达到收益递减的转折点后,将无法进一步增长。
容量是一个和可扩展性相关的概念。系统容量表示在一定时间内能够完成的工作量(从物理学来看,单位时间内做的功称为功率(power),而在计算机领域,"power"是一个被反复使用的术语,含义模糊,因此应避免使用它,但是关于容量的精确定义是系统的最大功率输出。)但容量必须是可以有效利用的。系统的最大吞吐量并不等同于容量。大多数基准测试能够衡量一个系统的最大吞吐量,但真实的系统一般不会使用到极限。如果达到最大吞吐量,则性能会下降,并且响应时间会变得不可接受地大且非常不稳定。我们将系统地真实容量定义为在保证可接受地性能地情况下能够达到地吞吐量。这就是为什么基准测试地结果通常不应该简化为一个单独地数字。
容量和可扩展性并不依赖于性能。以高速公路上的汽车来类比的话:
- 1.性能是汽车的时速
- 2.容量是车道数乘以最大安全时速
- 3.可扩展性就是在不减慢交通的情况下,能增加更多车和车道的程度
在这个类比中,可扩展性依赖于多个条件:换道设计得是否合理、路上有多少车抛锚或者发生事故,汽车行驶速度是否不同或者是否频繁变换车道——但一般来说和汽车得引擎是否强大无关。这并不是说性能不重要,性能确实重要,只是需要指出,即使系统性能不是很高也可以具备可扩展性。
从较高层次看,可扩展性就是能够通过增加资源来提升容量的能力。即使MySQL架构是可扩展的,但应用本身也可能无法扩展,如果很难增加容量,不管原因是什么,应用都是不可扩展的。之前我们从吞吐量方面来定义容量,但同样也需要从较高的层次来看代容量问题。从有利的角度来看,容量可以简单地认为是处理负载的能力,从不同的角度来考虑负载很有帮助。
- 1.数据量
应用所能累积的数据量是可扩展性最普遍的挑战,特别时对于现在的许多互联网应用而言,这些应用从不删除任何数据。例如社交网站,通常从不会删除老的消息或评论 - 2.用户量
即使每个用户只有少量的数据,但在累计到一定数量的用户后,数据量也会开始不成比例地增长且速度快过用户增长。更多的用户意味着要处理更多的事务,并且事务数可能和用户数不成比例。最后,大量用户(以及更多的数据)也意味着更多复杂的查询,特别是查询跟用户关系相关时(用户间的关联数可以用N x (N -1)来计算,这里的N表示用户数) - 3.用户活跃度
不是所有的用户活跃度都相同,并且用户活跃度也不总是不变的。如果用户突然变得活跃,例如由于增加了一个吸引人的新特性,那么负载可能会明显提升。用户活跃度不仅仅指页面浏览数,即使同样的页面浏览数,如果网站的某个需要执行大量工作的部分变得流行,也可能导致更多的工作。另外,某些yoghurt也会比其他用户更活跃:它们可能比一般人拥有更多的朋友、消息、照片 - 4.相关数据集的大小
如果用户间存在关系,应用可能需要在整个相关联用户群体上执行查询和计算,这比处理一个一个的用户和用户数据要复杂得多。社交网站经常会遇到由那些人气很旺的用户组或朋友很多的用户所带来的挑战
正式的可扩展性定义
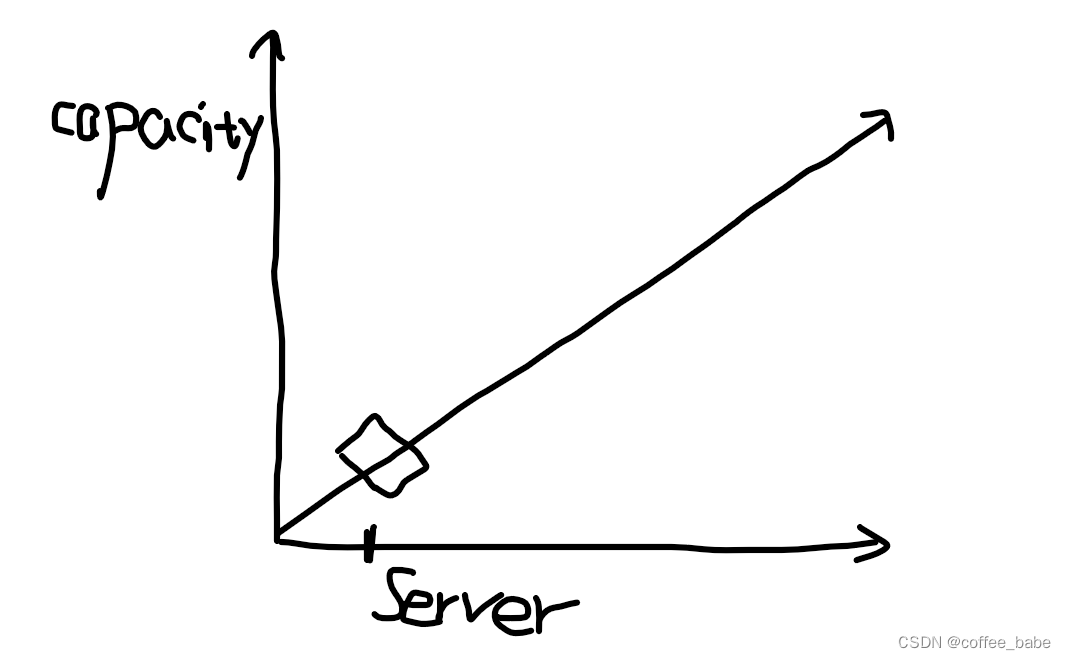
(一个只有一台服务器的系统)
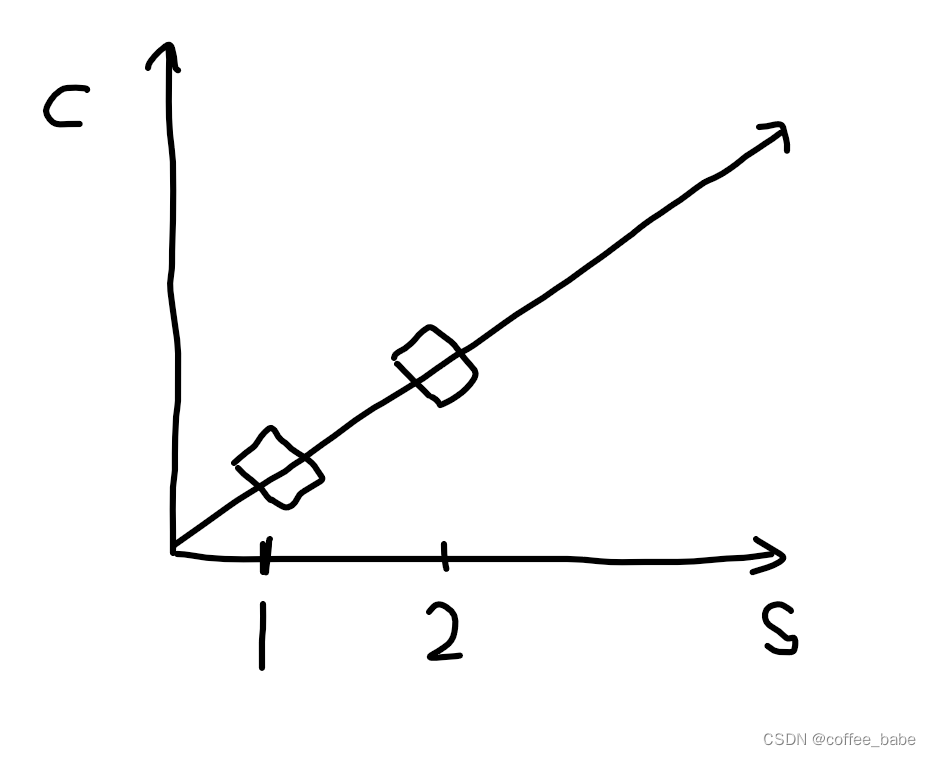
(一个线性扩展的系统能由两台服务器获得两倍容量)
(一个非线性扩展的系统)
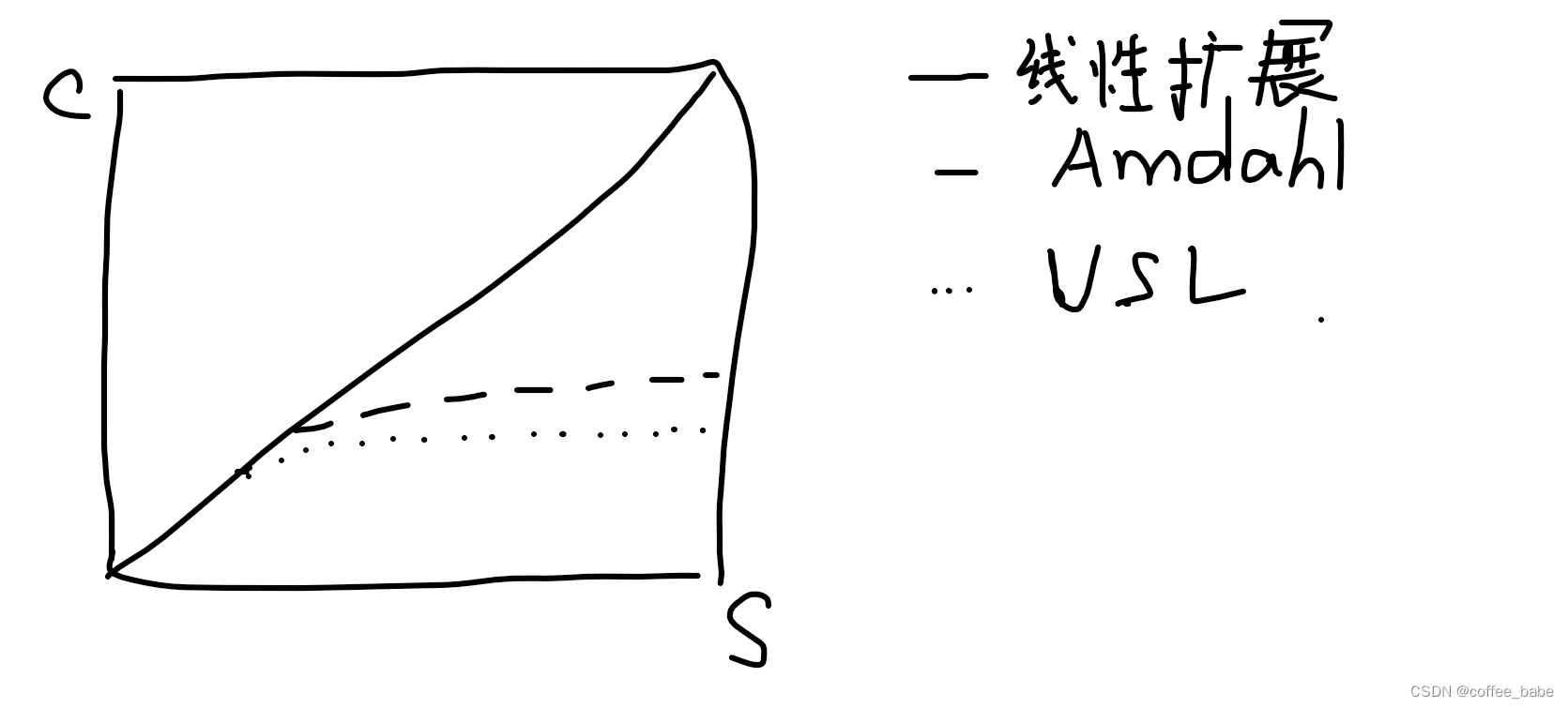
(线性扩展、Amadhl扩展以及USL扩展定律)
有必要探讨以下可扩展性在数学上的定义了,这有助于在更高层次的概念上清晰地理解可扩展性。如果没有这样的基础,就可能无法理解或精确地表达可扩展性。不过不用担心,这里不会涉及高等数学,即使不是数学天才,也能够很直观地理解它。关键是前面使用的短语:“划算的等同提升(equal bang for the buck)”.另一种说法是,可扩展性是当增加资源以处理负载和增加容量时系统能够获得的投资产出率(ROI).假设有一个只有一台服务器的系统,并且能够测量它的最大容量,如图所示。下面用s表示服务器,c表示容量,假设我们现在增加一台服务器,系统的能力加倍,如图所示。这就是线性扩展。我们增加了一倍的服务器,结果增加了一倍的容量。大部分系统并不是线性扩展的,而是如图所示的扩展方式。大部分系统都只能以比线性扩展略低的扩展系数进行扩展,越高的扩展系数会导致越大的线性偏差。事实上,多数系统最终会达到一个最大吞吐量临界点,超过这个点后增加头伏反而会带来负回报——继续增加更多工作负载,实际上会降低系统的吞吐量(事实上,"投资产出率"也可以从金融投资的角度来考虑,将一个组件的容量升级到两倍所需要符出的常常不止是最初开销的两倍。虽然在现实世界里我们常常这么考虑,但在讨论中会将其忽略掉,因为它会使一个已经复杂的主题变得更加复杂)。这怎么可能呢?这些年产生了许多可扩展性模型,它们有着不同程度的良好表现和实用性。我们这里所讲的可扩展性模型是基于某些能够影响系统扩展的内在机制。这就是Neil J.Gunther博士提出的通用可扩展性定律(Universal Scalability Law, USL).Gunther博士将这些详尽地写到了他的书中,包括Guerrilla Capacity Planning(Springer).这里不会深入到背后的数学理论中。
简而言之,USL说的是线性扩展的偏差可通过两个因素来建立模型:无法并发执行的一部分工作,以及需要交互的另外一部分工作。为第一个因素建模就有了著名的Amdahl定律,它会导致吞吐量趋于平缓。如果部分任务无法并行,那么不管你如何分而治之,该任务至少需要串行部分的时间。
增加第二个因素——内部节点间或者进程间的通信——到Amdahl定律就得出了USL.这种通信的代价取决于通信信道的数量,而信道的数量将按照系统内工作者数量的二次方增长。因此最终开销比带来的收益增长得更快,这是产生扩展性倒退得原因。如图所示,阐明了目前讨论到的三个概念:线性扩展、Amdahl扩展以及USL扩展。大多数真实系统看起来更像USL取线。
USL可以应用于硬件和软件领域。对于硬件,横轴表示硬件的数量,例如服务器数量或CPU数量。每个硬件的工作量、数据大小以及查询的复杂度必须保持为常量(现实中很难精确定义硬件的可扩展性,因为当你改变你的系统中的服务器数量时很难保证哪些变量不变)。对于软件,横轴表示并发度,例如用户数或者线程数。每个并发的工作量必须保持为常量。有一点很重要,USL并不能完美地描述真实系统,它只是一个简化哦行。但这是一个很好的框架,可用于理解为什么系统增长无法带来等同的收益。它也揭示了一个构建高可扩展性系统的重要原则:在系统内尽量避免串行化和交互。
可以衡量一个系统并使用回归来确定串行和交互的量。你可以将它作为容量规划和性能预测评估的最优上限值。也可以检查系统是怎么偏离USL模型的,将其作为最差下限值以之处系统的哪一部分没有表现出它应有的性能。这两种情况下,USL给出了一个讨论可扩展性的参考。如果没有USL,那即使盯着系统看也无法直到期望的结果是什么。
另外一个理解可扩展性的框架是约束理论,它解释了如何通过减少依赖时间和统计变化(statistical variation)来改进系统的吞吐量和性能。这在Eliyahu M.Goldratt所撰写的The Goal(North River)一书中有描述,其中有一个关于管理制造业设备的眼神的比喻。尽管这看起来和数据库服务器没有什么关联,但其中包含的法则和排队理论以及其他运筹学方面是一样的
扩展模型不是最终定论
虽然有许多理论,但在现实中能做到何种程度呢?正如牛顿定律被证明只有远低于光速时才合理,哪些"扩展性定律"也只是在某些场景下才能很好地工作的简化模型。有一种说法认为所有的模型都是错误的,但有一些模型还是有用的,特别是USL能够帮助理解一些导致扩展性差的因素。
当工作负载和其所运行的系统存在微妙的关系时,USL理论可能失效。例如,一个USL无法很好建模的常见情况是:当集群的总内存由于数据集大小而发生改变时,也会导致系统的行为发生变化。USL不允许比线性更好的可扩展性,但现实中可能会发生这样的事情:增加系统的资源后,原来一部分IO密集型的工作变成了纯内存工作,因此获得了超过线性的性能扩展。
还有一些情况,USL无法很好地描述系统行为。当系统或数据集大小改变时算法的复杂度可能改变,类似这样的情况可能就无法建立模型(USL由O(1)复杂度和O(N^2)复杂度两部分构成,那么对于诸如O(logN)或者O(NlogN)这样复杂度的部分呢?)根据一些思考和实际经验,我们可以将USL扩展以覆盖这些比较普遍的场景中的一部分。但这会将一个简单并且有用的模型变得复杂并难以使用。事实上,它在很多情况下都是很好地,足以为你所能想象到的系统行为建立模型,这也是为什么我们发现它是在正确性和有效性之间的一个很好的妥协。
简单地说:有保留地使用模型,并且在使用中验证你的发现