文章目录
- 前言
- 认识Metadata
- 认识Metastore
- metastore三种配置方式
- 一、安装前准备
- 二、下载hive-3.1.2安装包
- 三、下载完成后,通过xftp6上传到Linux服务器上
- 四、解压Hive安装包
- 五、配置Hive
- 六、内嵌模型安装—Hive元数据配置到Derby
- 七、本地模式安装—Hive元数据配置到MySQL
- 八、远程模型安装—使用元数据服务的方式访问Hive
- 九、Hive客户端使用
- hive客户端
- HiveServer、HiveServer2服务
- Hive客户端与服务的关系
- Hive客户机使用—Hive Client
- Hive客户机— Hive Beeline Client
前言
本文主要介绍在Linux环境下安装Hive的过程。
- 使用Linux 工具/版本 :
- xshell6、xftp6
- Centos7:CentOS Linux release 7.6.1810 (Core)
- 安装Hive版本:
- hive-3.1.2
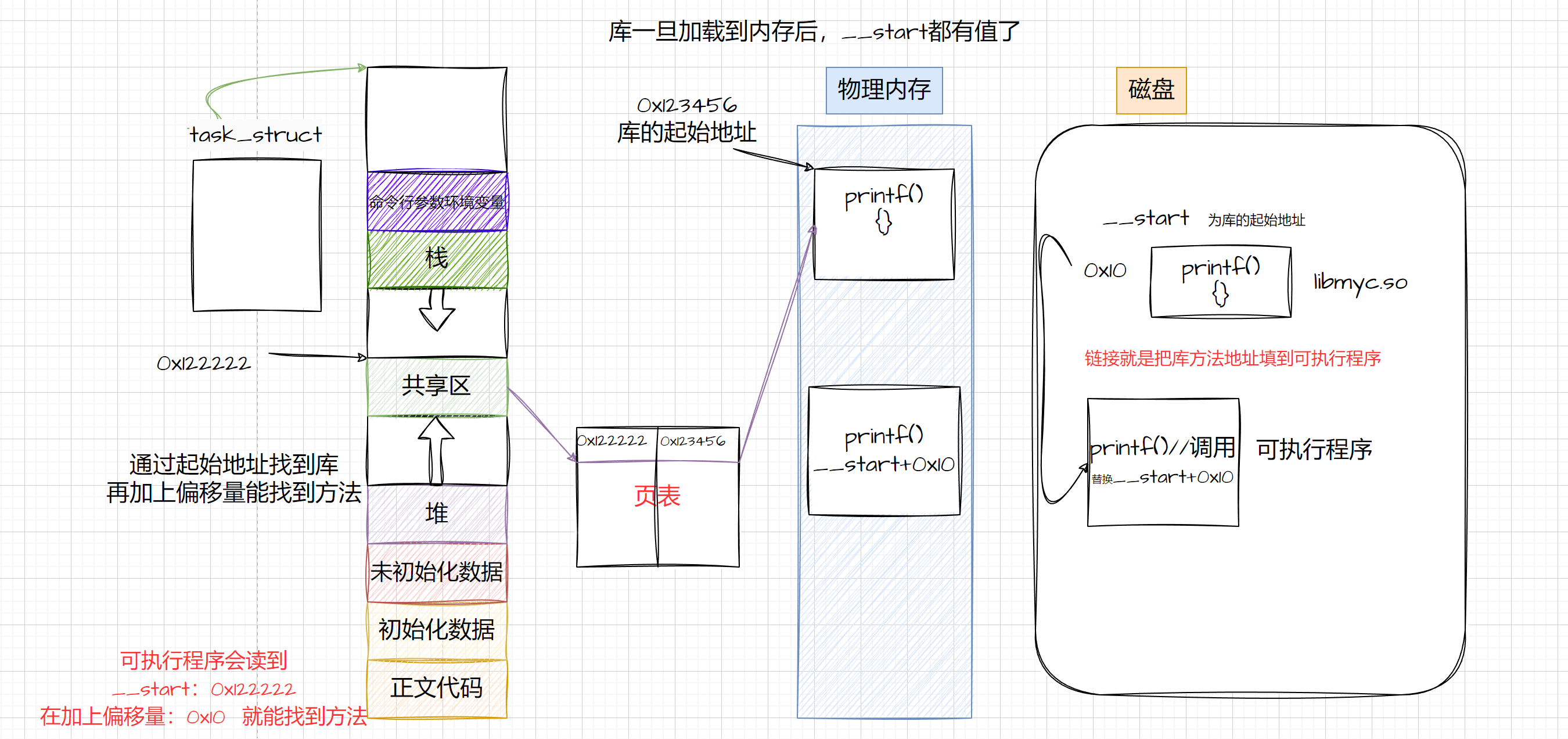
认识Metadata
Metadata即元数据。元数据包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。元数据存储在关系型数据库中,如hive内置的Derby、或者第三方如MySQL等。
认识Metastore
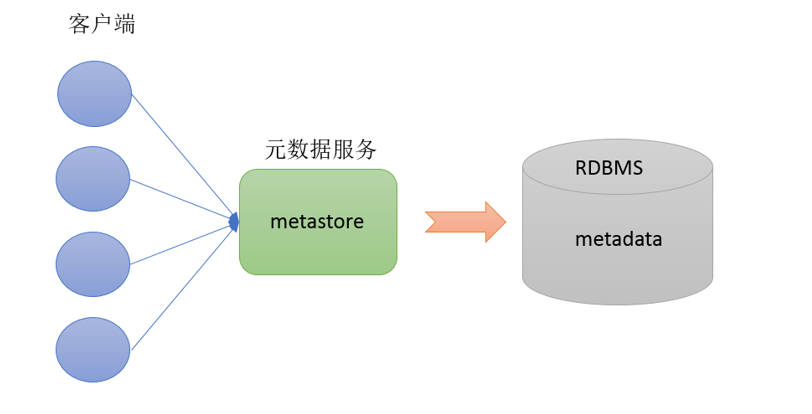
Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore服务即可。某种程序上也保证上了hive元数据的安全。
metastore三种配置方式
- 内嵌模式
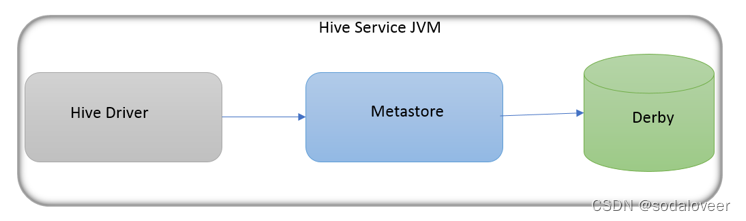
内嵌模式(Embedded Metastore)是metastore默认部署模式。此种模式下,元数据存储在内置的Derby数据库,并且Derby数据库和metastore服务都嵌入在主HiveServer进程中,当启动HiveServer进程时,Derby和metastore都会启动。不需要额外起Metastore服务。
但是一次只能支持一个活动用户,适用于测试体验,不适用于生产环境。
- 本地模式
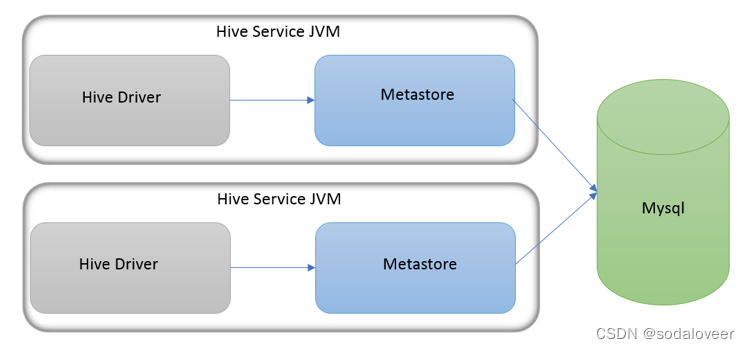
本地模式(Local Metastore)下,Hive Metastore服务与主HiveServer进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。metastore服务将通过JDBC与metastore数据库进行通信。本地模式采用外部数据库来存储元数据,推荐使用MySQL。
hive根据hive.metastore.uris 参数值来判断,如果为空,则为本地模式。
缺点是:每启动一次hive服务,都内置启动了一个metastore。
- 远程模式
远程模式(Remote Metastore)下,Metastore服务在其自己的单独JVM上运行,而不在HiveServer的JVM中运行。如果其他进程希望与Metastore服务器通信,则可以使用Thrift Network API进行通信。
在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
远程模式下,需要配置hive.metastore.uris 参数来指定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务。
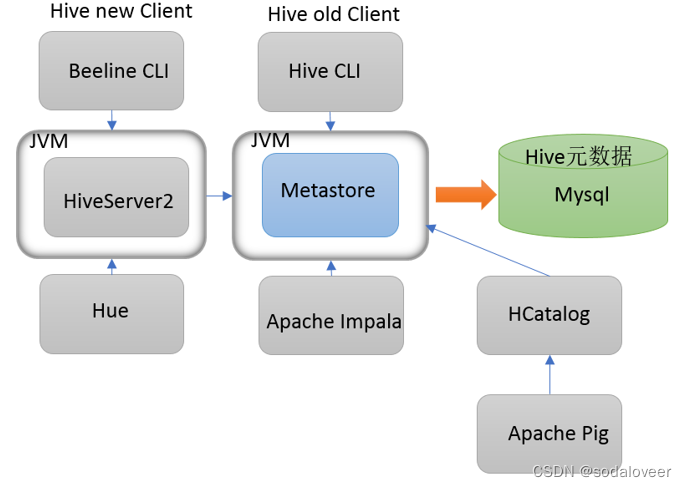
- 三种模式对比
| 内嵌模式 | 本地模式 | 远程模式 | |
|---|---|---|---|
| Metastore单独配置、启动 | 否 | 否 | 是 |
| Metastore存储介质 | Derby | Mysql | Mysql |
一、安装前准备
由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配置Hive Metastore,必须要先保证服务器的基础环境正常,Hadoop集群健康可用。
-
服务器基础环境
-
集群时间同步
-
防火墙关闭,执行"systemctl status firewalld.service“命令查看防火墙的状态;如果没有关闭,则执行"systemctl stop firewalld.service"命令关闭防火墙。

-
主机Host映射
-
免密登录
-
JDK安装
-
-
Hadoop集群
-
启动Hive之前必须先启动Hadoop集群,需等待HDFS安全模式关闭之后再启动运行Hive。执行"myhadoop start"命令启动集群,执行"jpsall"命令查看集群启动状态。


-
二、下载hive-3.1.2安装包
hive安装包下载地址:https://archive.apache.org/dist/hive/
三、下载完成后,通过xftp6上传到Linux服务器上
将hive-3.1.2安装包上传到 /opt/software 路径下面。
1、打开xshell6,连接要安装hive的Linux服务器,执行 “cd /opt/software” 命令。

2、打开xftp6,选择下载好的hive安装包,点击上传到 /opt/software下面。

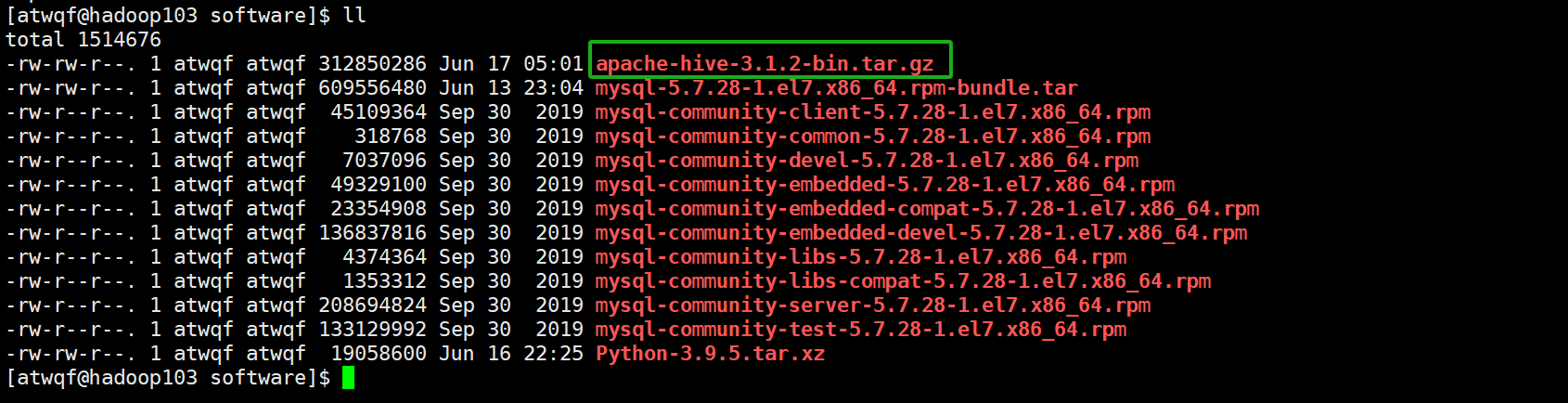
3、关闭xftp6,在刚刚连接Linux服务器的 /opt/software 路径下执行 “ll” 命令,可以查看到hive安装包已经上传成功。
四、解压Hive安装包
1、解压 apache-hive-3.1.2-bin.tar.gz 到/opt/module/目录下面,执行"tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/"命令。

2、修改apache-hive-3.1.2-bin.tar.gz 的名称为 hive,执行"mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive"命令。

五、配置Hive
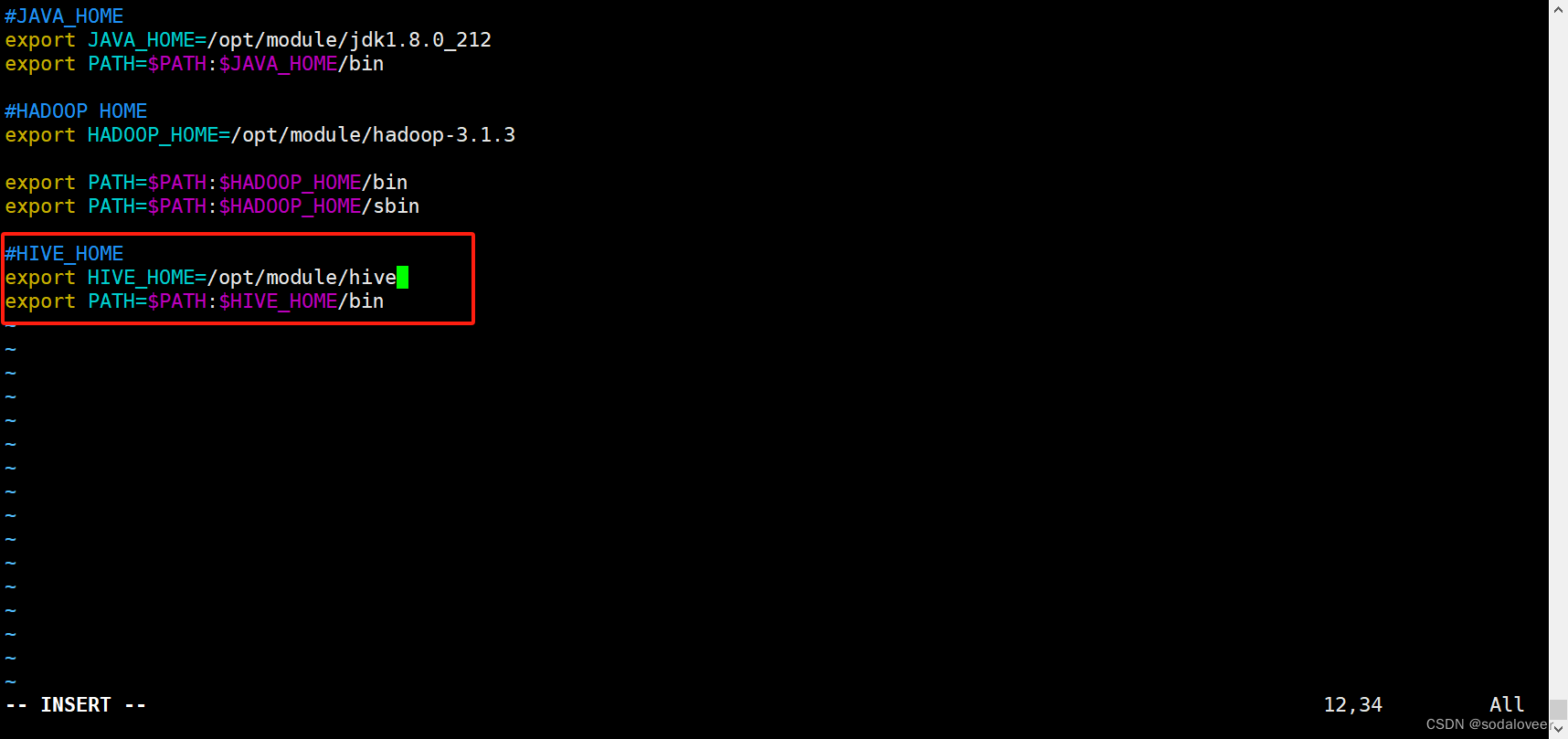
1、添加环境变量,执行"vim /etc/profile.d/my_env.sh"命令。
- 添加以下内容:
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
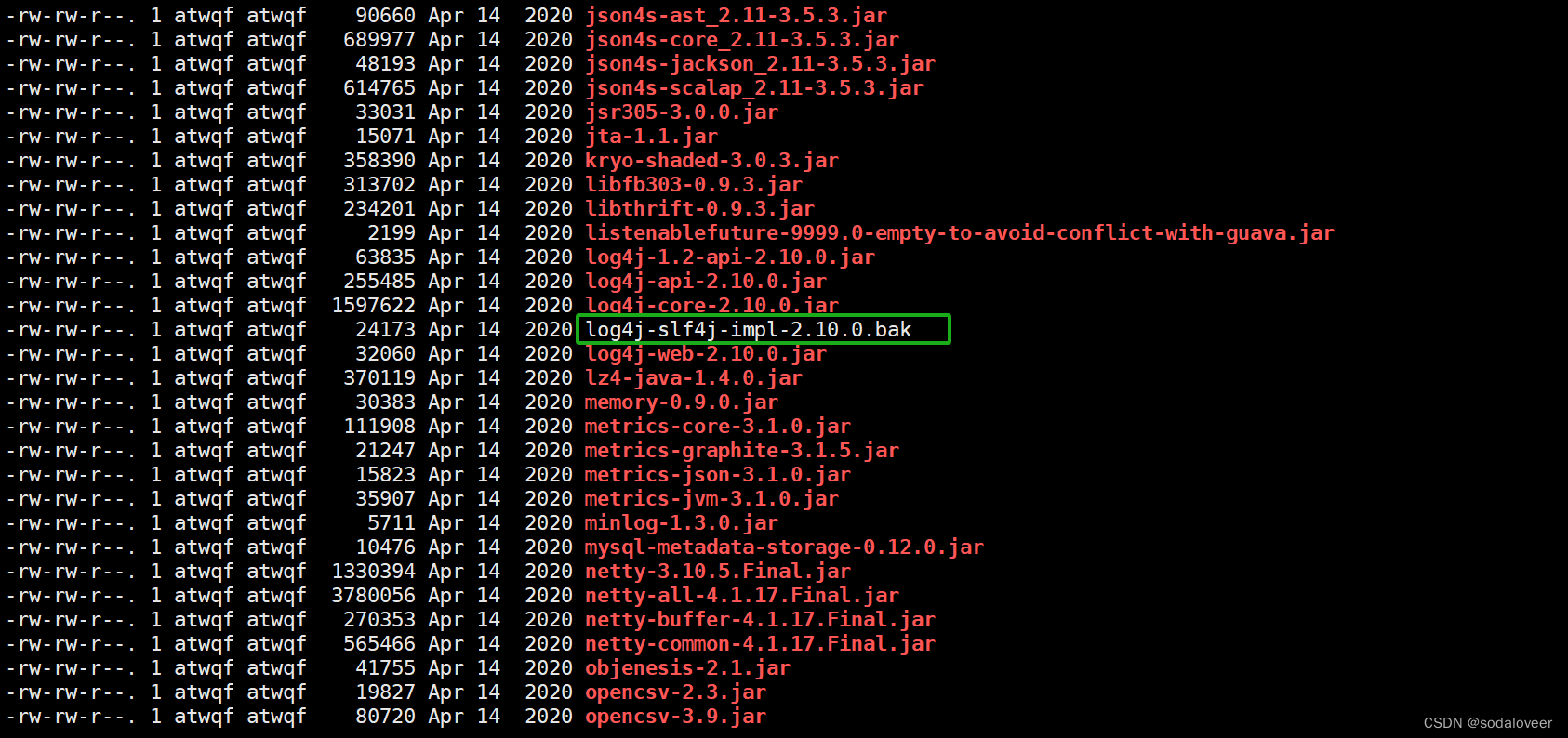
2、解决日志冲突,执行"mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak”命令。

六、内嵌模型安装—Hive元数据配置到Derby
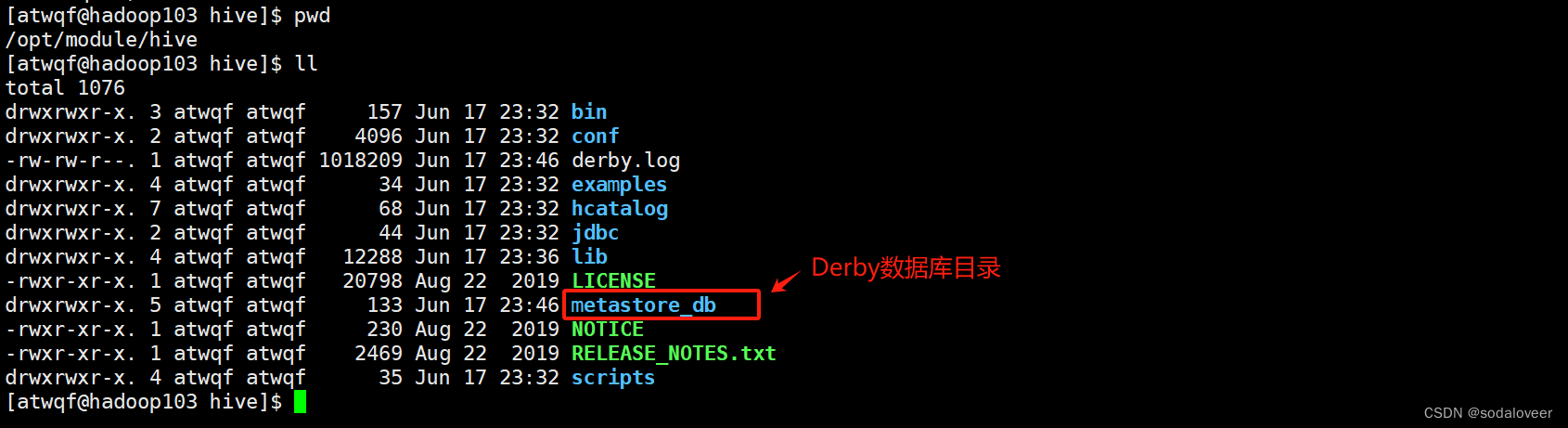
Derby是内置的数据库,无需下载。
1、初始化元数据库。执行"bin/schematool -dbType derby -initSchema"命令 。


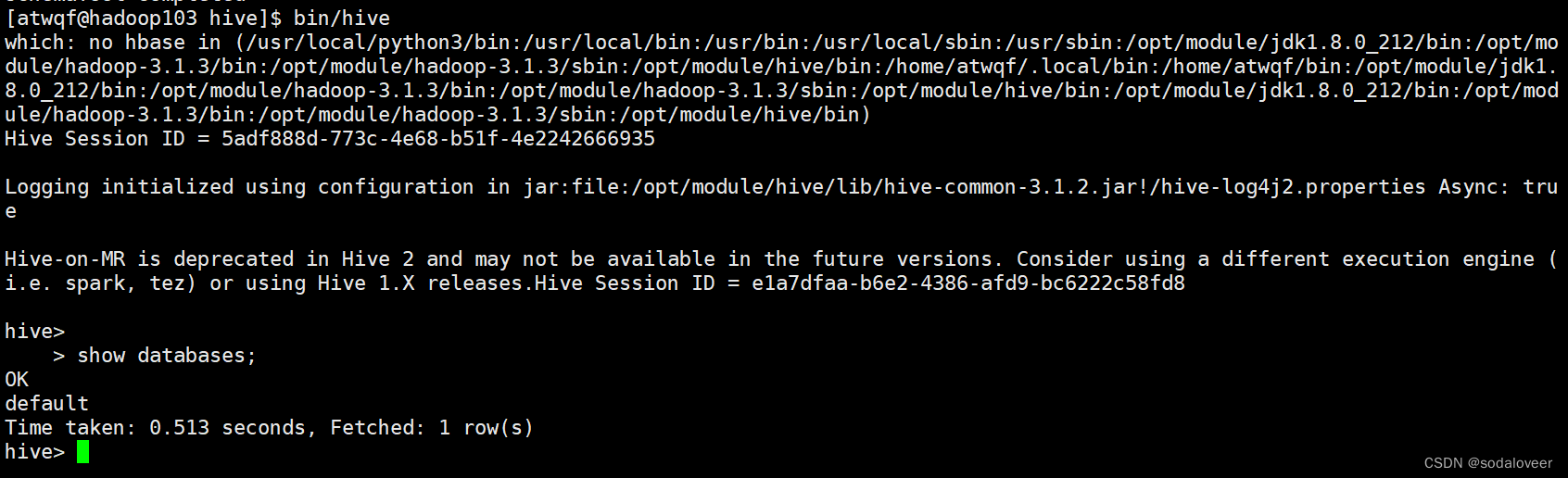
2、启动使用hive,执行"bin/hive"命令。
3、开启另一个窗口,执行"cat /tmp/atwqf/hive.log"命令查看日志文件。
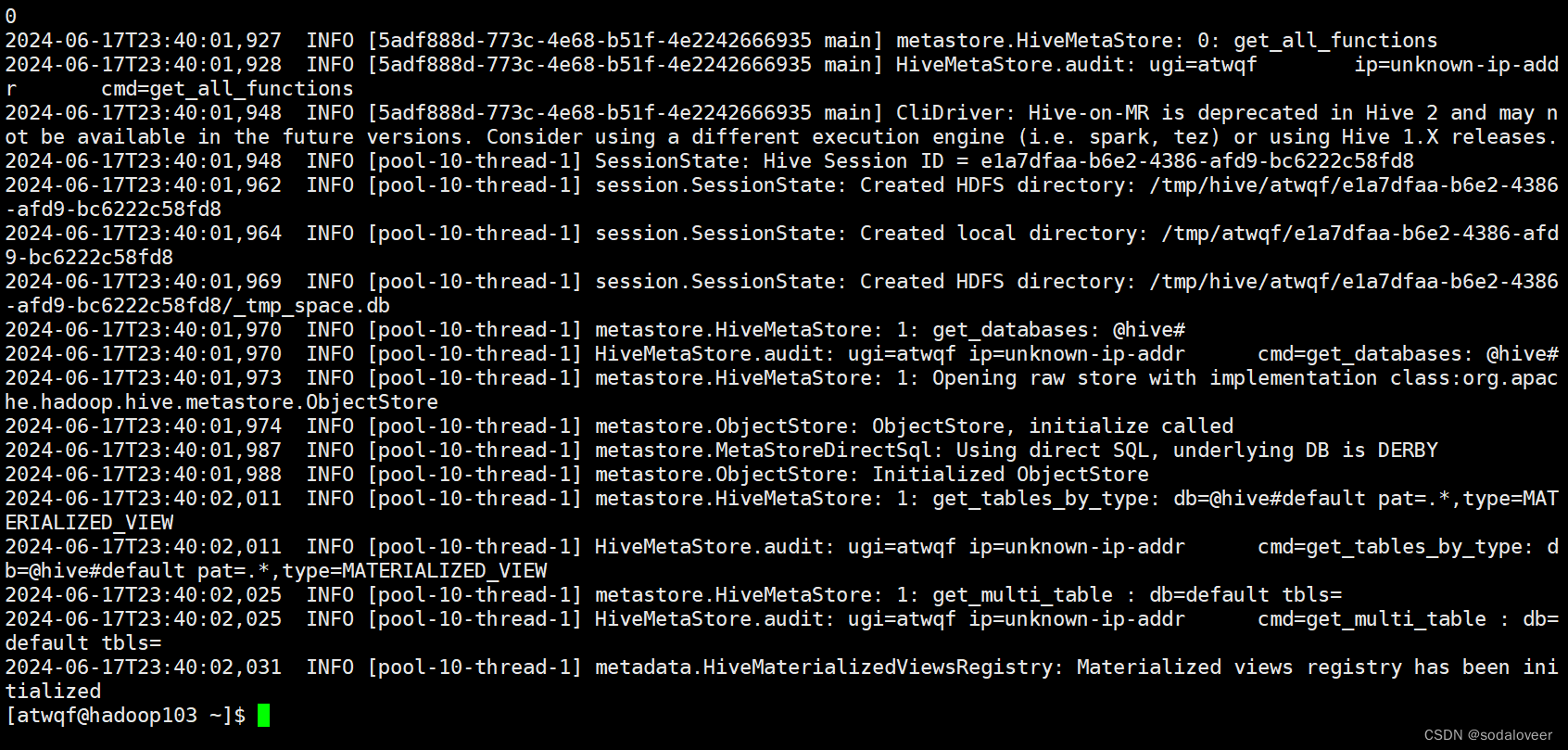
注意:
Hive默认使用的元数据库为derby,开启Hive之后就会占用元数据库,且不与其他客户端共享数据。
例如:另外开一个窗口使用hive,会报错FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
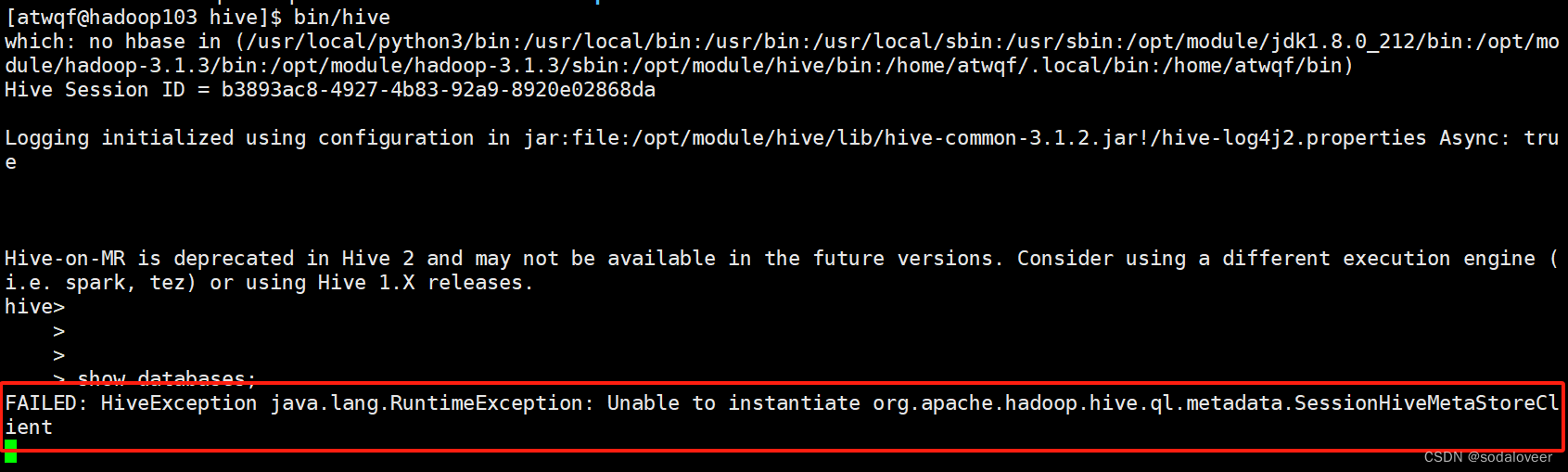
七、本地模式安装—Hive元数据配置到MySQL
本地模式安装前先进行MySQL安装,参考链接:https://blog.csdn.net/sodaloveer/article/details/139674393,确定MySQL数据库安装成功后,才将Hive元数据配置到MySQL。
1、上传MySQL的JDBC驱动(通过xftp6上传),将MySQL的JDBC驱动拷贝到Hive的lib目录下,执行"cp /opt/software/mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib"命令。
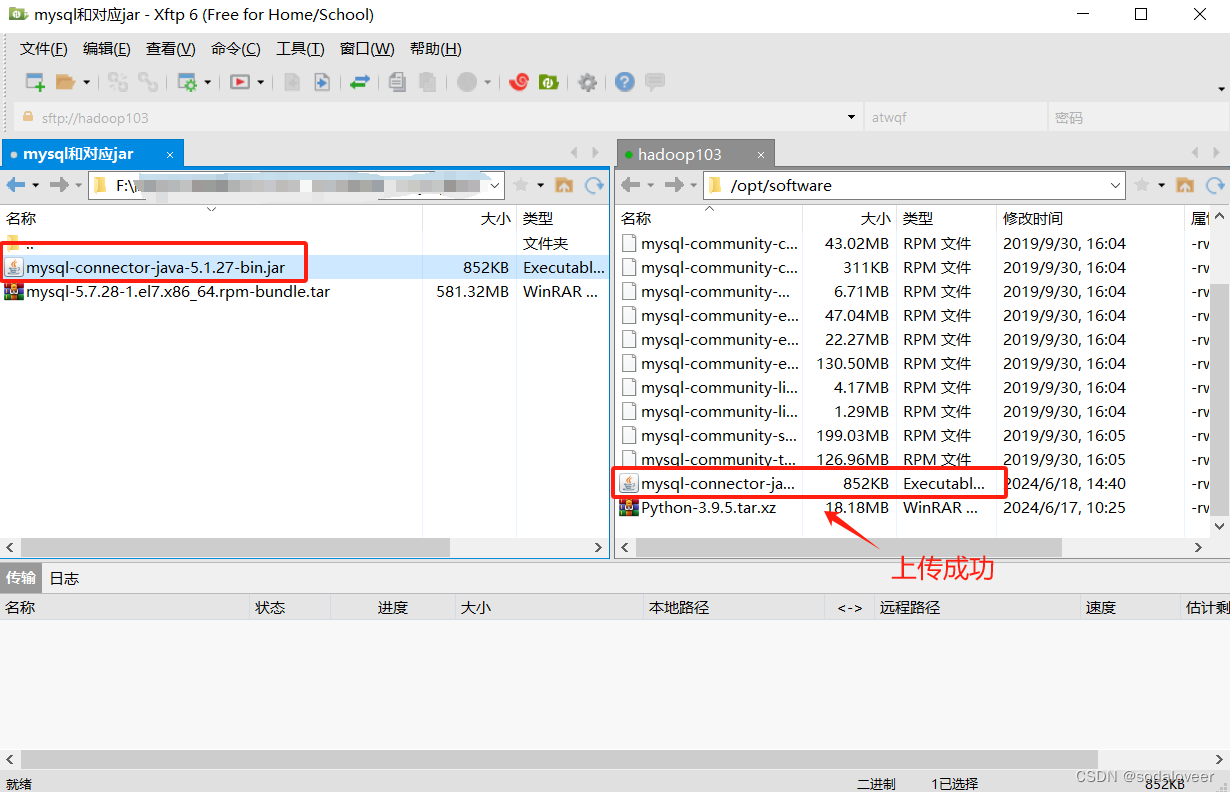

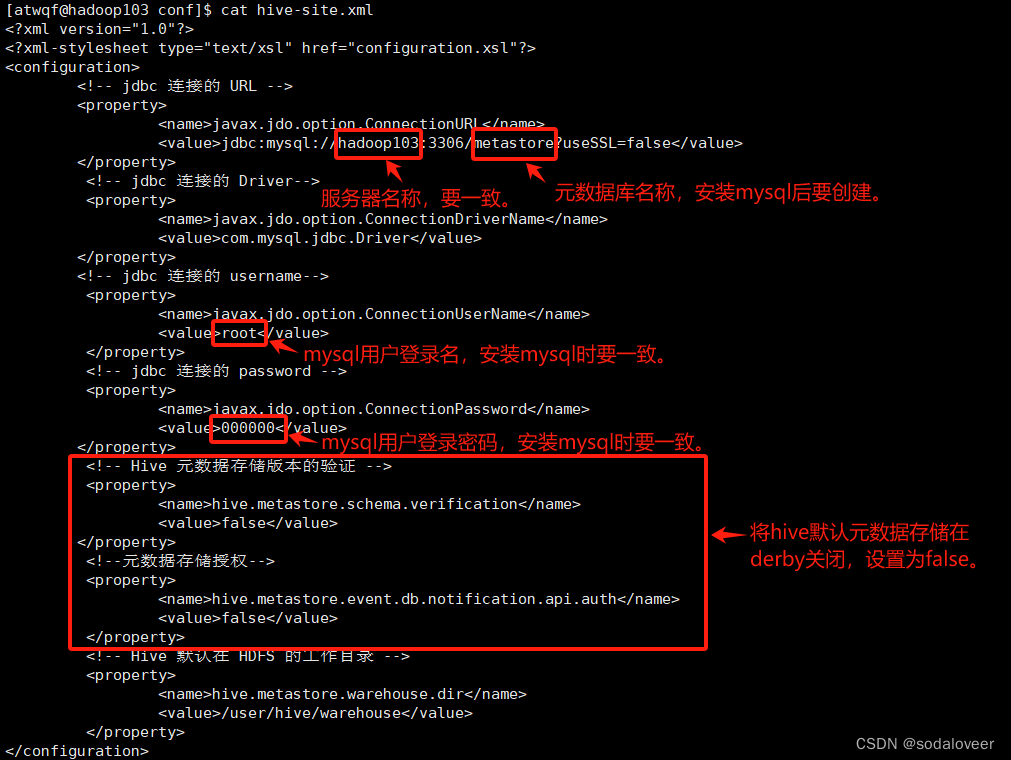
2、配置Metastore到MySQL,在/opt/module/hive/conf目录下新建hive-site.xml文件。执行"vim /opt/module/hive/conf/hive-site.xml",添加内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop103:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
复制粘贴上面的内容需要注意:<?xml version="1.0"?>这里需要注意,这一行必须在第一行,并且需要顶格,前面没有任何空格或其他字符。多余空格需去掉,特殊字符需转义),否则会报错:
Illegal processing instruction target ("xml"); xml (case insensitive) is reserved by the specs.
3、登陆MySQL,执行"mysql -uroot -p000000"

4、新建Hive元数据库,元数据库的名称要和配置文件hive-site.xml一致。
> create database metastore;
> show databases;
> quit;

5、初始化元数据库,执行"schematool -initSchema -dbType mysql -verbose"命令。
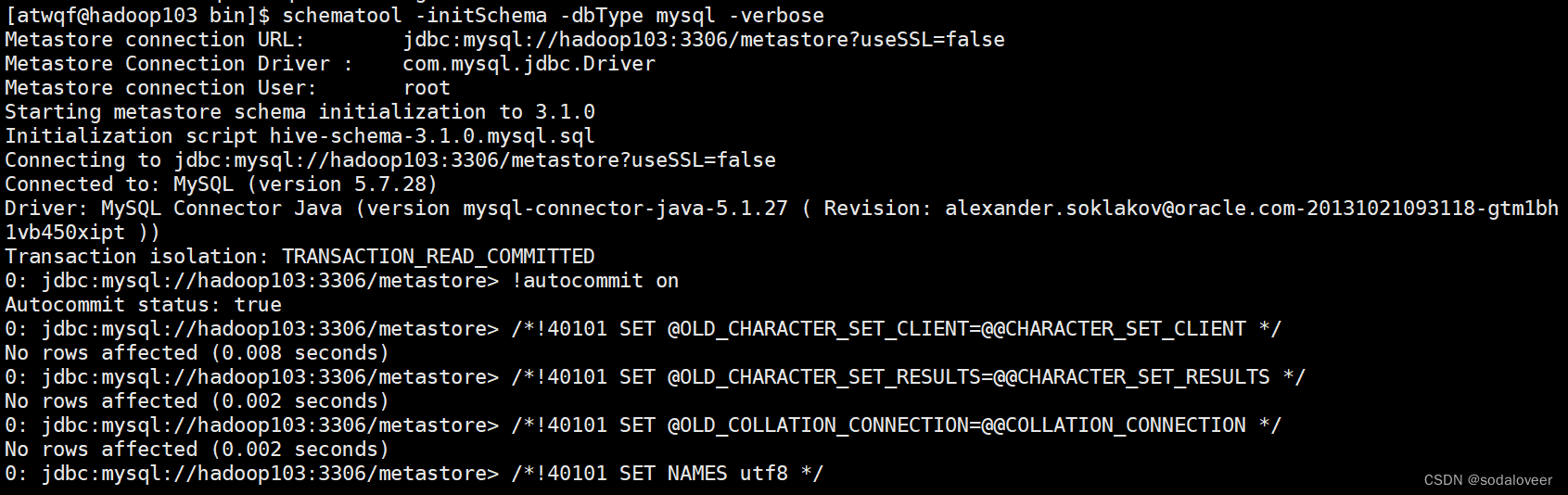
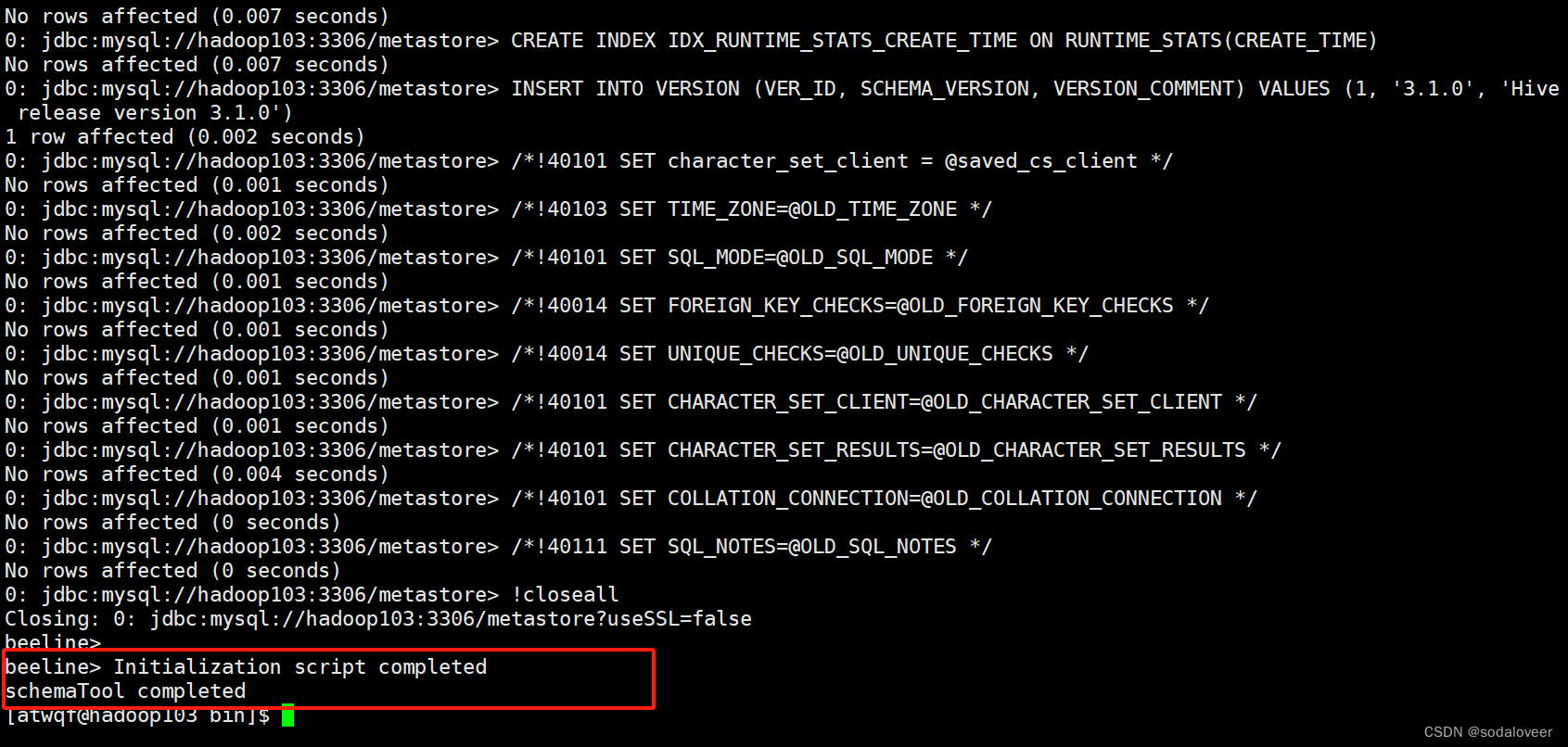
初始化完成。
6、再次启动Hive,执行"bin/hive"命令。
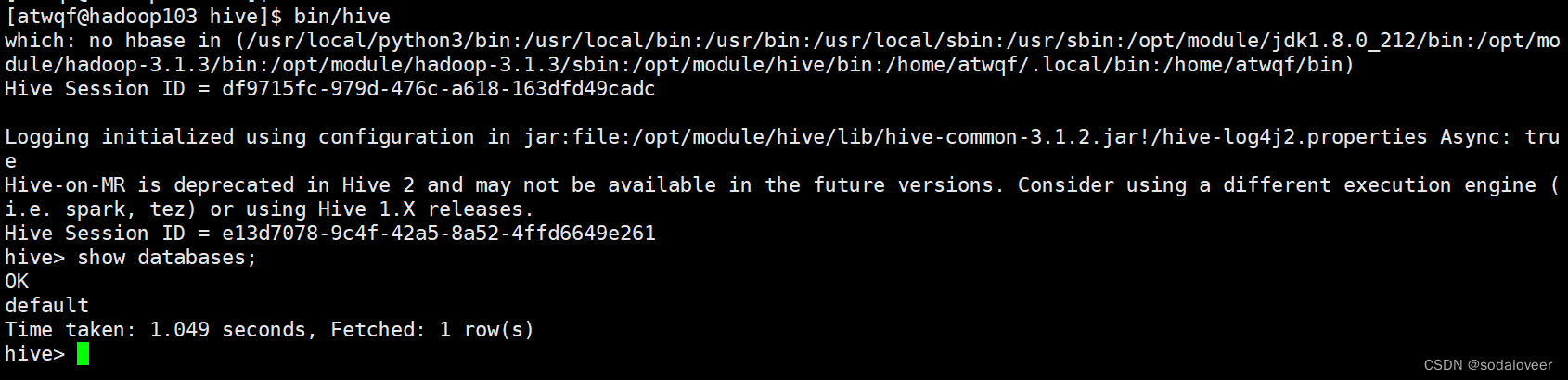
另一个窗口开启hive,执行"bin/hive"命令。

八、远程模型安装—使用元数据服务的方式访问Hive
1、执行"vim /opt/module/hive/conf/hive-site.xml",添加内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop103:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop103:9083</value>
</property>
</configuration>
与本地模式相比,hive-site.xml文件主要是在增加了下面的内容:
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop103:9083</value>
</property>
要给hive起一个服务,主要是提供端口使第三方框架可以连接使用。
2、启动metastore,三种方式:
- 前台启动,执行"hive --service metastore"命令。

另起一个窗口:

后台启动,进程挂起,执行"nohup /opt/module/hive/bin/hive --service metastore &"命令,后台启动的输出日志信息,在/root目录下,nohup.out。
也可以使用脚本管理服务的启动和关闭。
1.执行"vim $HIVE_HOME/bin/hiveservices.sh"命令新建脚本,脚本内容如下;
2.执行"chmod +x $HIVE_HOME/bin/hiveservices.sh"命令,添加执行权限;
3.执行"hiveservices.sh start"启动 Hive 后台服务.
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数 1 为进程名,参数 2 为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print
$2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1
&"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe 服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2 服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore 服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2 服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore 服务运行
正常" || echo "Metastore 服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2 服务运
行正常" || echo "HiveServer2 服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
-
注意:
- 前台启动后窗口不能再操作,需打开一个新的 shell 窗口做别的操作。
在远程模式下,必须首先启动Hive metastore服务才可以使用hive。因为metastore服务和hive server是两个单独的进程了。否则会报错:

九、Hive客户端使用
hive客户端
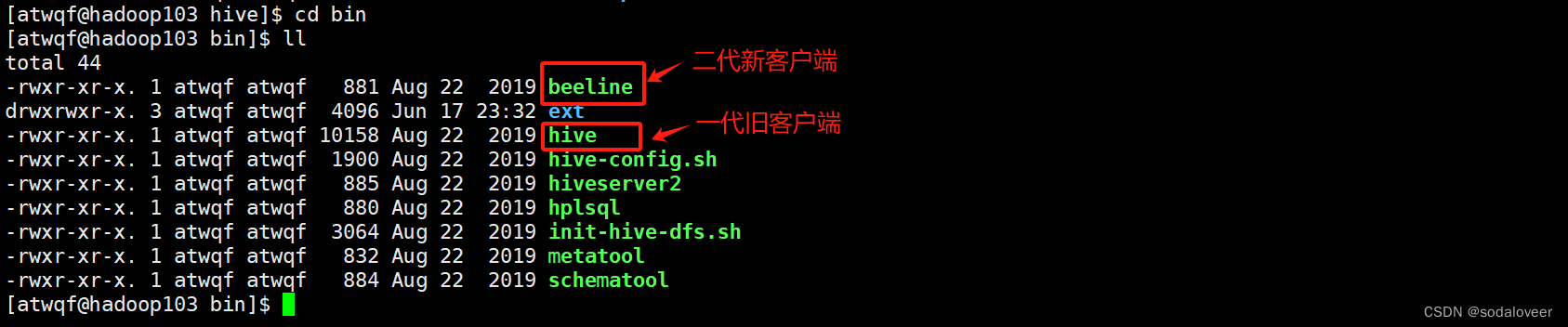
第一代客户端(deprecated不推荐使用):$HIVE_HOME/bin/hive。
第二代客户端(recommended 推荐使用):$HIVE_HOME/bin/beeline,是一个JDBC客户端。
HiveServer、HiveServer2服务
HiveServer、HiveServer2都是Hive自带的两种服务,允许客户端在不启动CLI的情况下对Hive中的数据进行操作,且两个都允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果。
区别:
HiveServer不能处理多于一个客户端的并发请求。
HiveServer2支持多客户端的并发和身份认证,旨在为开放API客户端如JDBC、ODBC提供更好的支持。所以更加推荐使用第二代客户端($HIVE_HOME/bin/beeline)。
Hive客户端与服务的关系

Hiveserver2通过metastore服务读写元数据,所以在远程模式下启动Hiveserver2之前必须先启动metastore服务。
Beeline客户端只能通过Hiveserver2服务访问Hive,而Hive Cline是通过Metastore服务访问的。
Hive客户机使用—Hive Client
bin/hive客户端是hive第一代客户端,可以访问metastore服务,从而达到操作hive目的。
内嵌和本地模式下直接执行"$HIVE_HOME/bin/hive"命令,metastore服务会内嵌一起启动。
如果需要在其他机器上(远程模式)通过bin/hive访问hive metastore服务,只需要在该机器的hive-site.xml配置中添加metastore服务地址即可。(参考上面:远程模型安装—使用元数据服务的方式访问Hive)
Hive客户机— Hive Beeline Client
Beeline客户端是hive第二代客户端(推荐使用),不是直接访问metastore服务的,需要单独启动hiveserver2服务。
Beeline是JDBC客户端面,通过JDBC协议与HIveserver2服务进行通信,协议的地址是:jdbc:hive2://hadoop103:10000。
1、使用JDBC方式访问Hive,执行"vim /opt/module/hive/conf/hive-site.xml",添加内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop103:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop103:9083</value>
</property>
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop103</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
</configuration>
与远程模式相比,hive-site.xml文件主要是在增加了下面的内容:
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop103</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
2、先启动metastore服务,执行"$HIVE_HOME/bin/hive --service metastore"命令。
然后启动hiveserver2,执行"$HIVE_HOME/bin/hive --service hiveserver2"命令。


3、启动beeline客户端,执行"$HIVE_HOME/bin/beeline -u jdbc:hive2://hadoop103:10000 -natwqf"命令。

安装过程中可能出现的报错:
“schematool -initSchema -dbType mysql -verbose” 报错!!!
安装Hive后执行“$HIVE_HOME/bin/hive”命令时,报错Connection refused
![[RPI4] 树莓派4b安装istoreos及使用 -- 1. 系统安装](https://img-blog.csdnimg.cn/direct/55d8c7eaba514c77a772d3754112865b.png)