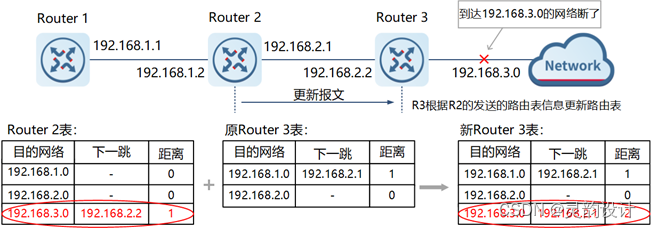
大模型(LLMs)在处理海量文本数据时展现出了前所未有的能力。然而这些模型在面对超出其训练时所见序列长度的长文本时存在两个主要问题:一是模型对于超出预训练长度的文本难以有效泛化,二是注意力机制的二次方时间复杂度导致计算成本急剧上升。这些问题严重限制了LLMs在长文本处理领域的应用潜力。

复旦大学计算机科学学院的研究团队在论文《LONGHEADS: Multi-Head Attention is Secretly a Long Context Processor》中提出了一种无需额外训练的框架,通过挖掘多头注意力的潜力,有效提升了LLMs处理长文本的能力。与传统方法相比,LONGHEADS无需额外的训练,便能在保持线性时间复杂度的同时,有效扩展模型的上下文处理窗口,为长文本的深入理解和生成任务提供了新的解决方案。
方法
本方法的核心思想是将输入文本分割成多个逻辑块,每个块由固定数量的连续token组成。这种分块策略不仅简化了注意力机制的复杂性,而且使得模型能够更加灵活地处理长文本。在生成特定token时,LONGHEADS会根据当前token的查询向量和块的表示,选择与之最相关的k个块。这一过程不依赖于额外的训练数据,完全基于模型已经学到的知识。
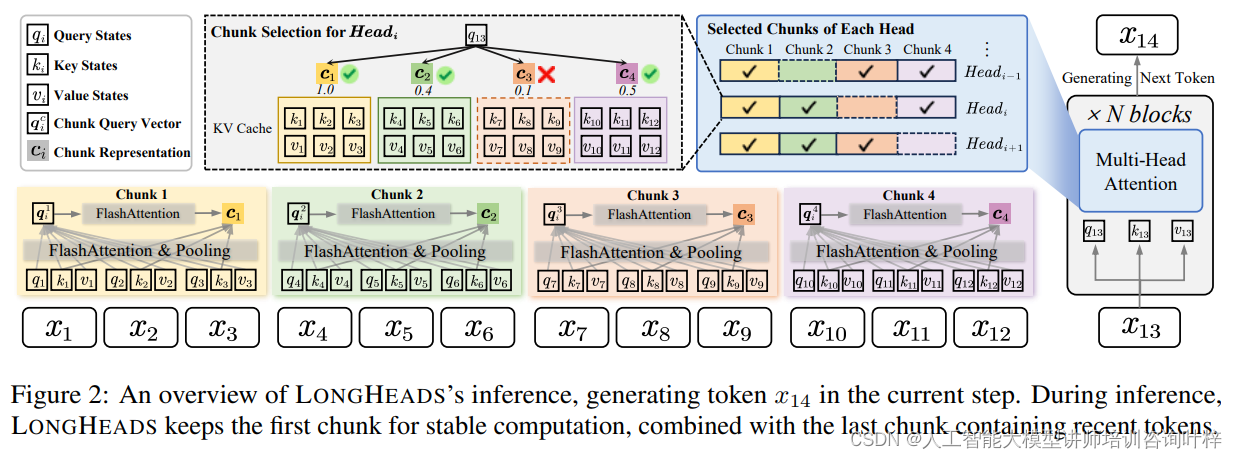
图2提供了对LONGHEADS推理过程的高层次概览,尤其是在生成特定步骤中的token x14时。在LONGHEADS的推理过程中,模型会特别关注两个关键的文本块:第一个块和最后一个块。
-
第一个块的重要性:第一个块(Chunk 1)对于保持计算的稳定性至关重要。它通常包含了文本的开始部分,这些信息对于模型理解整个上下文和维持生成过程中的连贯性非常关键。
-
最后一个块的作用:最后一个块(记为C−1)包含了最近的token,为模型提供了必要的局部上下文信息。这对于生成任务尤其重要,因为它帮助模型了解最近发生的事情,并据此做出合理的预测。
在生成token x14的当前步骤中,LONGHEADS会保留第一个块,并与最后一个包含最近token的块结合起来。这样,模型在生成新token时,既考虑了文本的整体结构,也考虑了近期的上下文信息。LONGHEADS模型的一些关键特性和操作方式包括:
-
选择性注意力机制:模型仅对与当前生成任务最相关的文本块进行注意力计算,而不是对整个文本进行全面的注意力分配。
-
计算效率的优化:通过限制参与计算的文本块数量,模型能够降低处理长文本时所需的内存和计算资源。
-
多头注意力的协作:模型中的多个注意力头可能各自选择不同的文本块进行处理,这样的设计允许模型从不同的角度和层面理解文本信息。
-
推理过程的动态性:模型在生成每个新token时,会根据当前的上下文动态选择相关的文本块,以适应不断变化的推理需求。
块表示是LONGHEADS中的一个关键概念,它指示了块内token是否应该被模型所关注。与传统方法不同,LONGHEADS通过一种训练无关的方式来获取块表示,这主要得益于注意力机制的内在能力。
每个块的块表示是通过对其内部所有token的关键状态进行聚合来获得的。为了更好地反映块内各个token的重要性,LONGHEADS采用了一种基于flash-attention的方法,通过评估每个token对整个块表示的贡献度,然后进行加权聚合。这种方法不仅考虑了块内token的语义重要性,而且还能够捕捉到它们在语义上的相关性。
在编码或生成下一个token的过程中,LONGHEADS采用了一种查询感知的块选择策略。这一策略基于当前token的查询状态和块表示之间的点积相似度来选择目标块。通过这种方式,模型能够识别出与当前任务最相关的上下文信息,并将其纳入到注意力计算中。
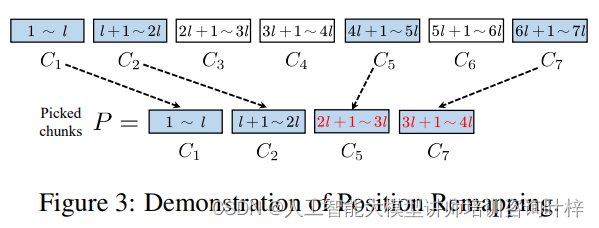
选择过程首先确保包含文本的开始部分和最近的部分,以维持生成的流畅性和局部性。然后,模型会根据点积相似度分数,选择剩余的k-2个最相关的块。这种选择机制不仅提高了模型对长文本信息的捕捉能力,而且还保持了计算效率。
在推理阶段,LONGHEADS对长输入的编码和长输出的生成进行了特别的优化。首先,模型会并行计算所有块的表示,然后根据块表示和查询向量选择最相关的k个块。这一过程通过两次flash-attention操作高效完成,大大减少了参与注意力计算的token数量。
在生成阶段,LONGHEADS首先执行块选择,然后加载所选k个块的键值表示,以进行长度受限的因果注意力计算。这种设计允许模型在保持预训练长度内的有效计算的同时,还能够处理超出该长度的长文本序列。
通过这些创新的方法,LONGHEADS不仅提高了LLMs处理长文本的能力,而且还保持了计算效率,为长文本的深入分析和应用提供了新的可能性。
实验
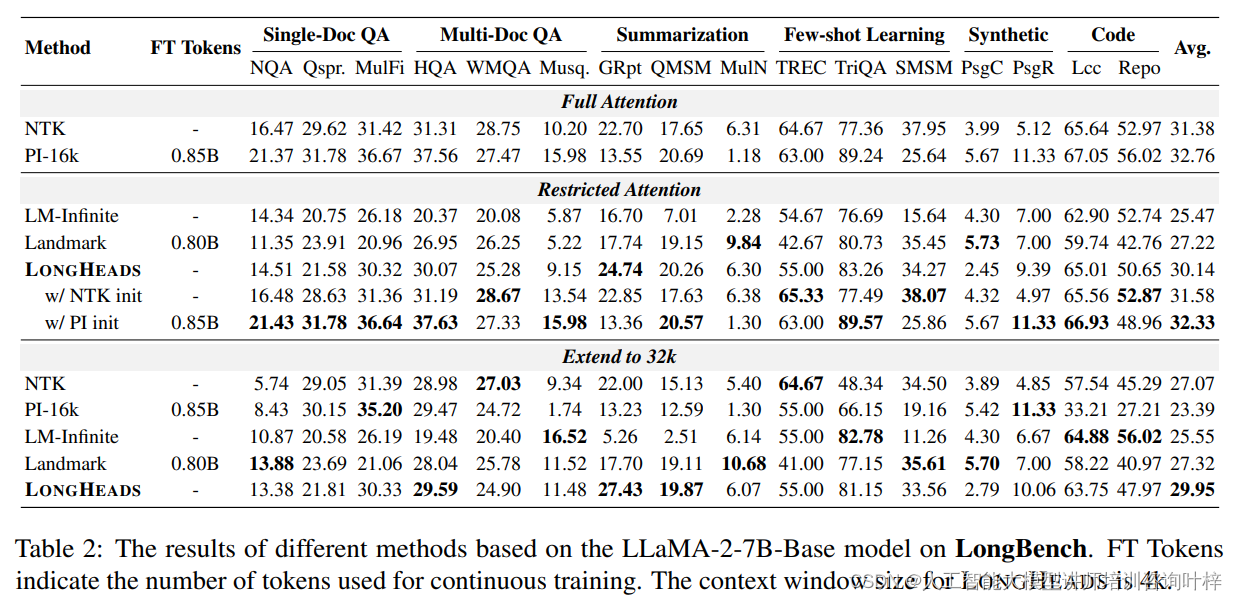
为了验证LONGHEADS框架的有效性,研究团队将LONGHEADS应用于流行的LLaMA-2-7B模型的基础和聊天版本,这两种模型因其广泛的应用和受欢迎程度而被选中。实验的基线设置包括了全注意力方法和受限注意力方法,以进行全面的比较。
全注意力方法包括了动态NTK插值和位置插值技术,而受限注意力方法则涵盖了LM-Infinite和Landmark-Attention。这些方法的实现细节在附录A中有详细描述。实验的目的是为了评估LONGHEADS在处理长文本时的性能,特别是在语言建模、合成检索任务和长文本基准测试中的表现。
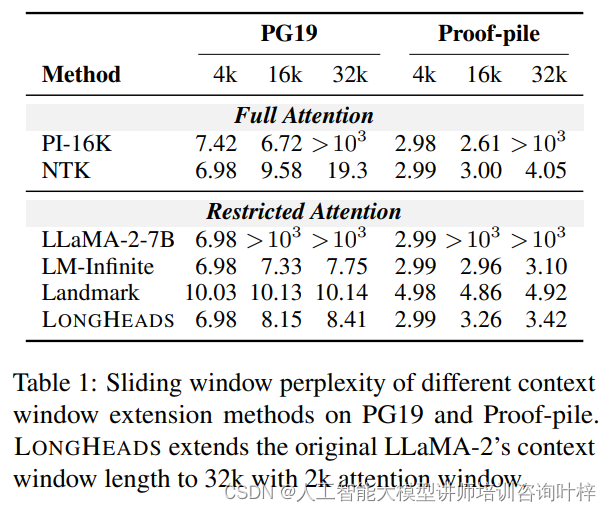
实验聚焦于长文本语言建模的能力。研究团队使用了两个数据集:PG19和Proof-pile。PG19是一个由书籍组成的语料库,而Proof-pile则是一个清洁过的Arxiv数学证明数据集。通过在这些数据集上进行实验,研究团队展示了不同方法在不同上下文长度下的困惑度(PPL)。
困惑度是衡量语言模型预测下一个token能力的指标,其值越低表示模型的预测能力越强。实验结果显示,当上下文长度在预训练范围内时,LLaMA-2-7B基础模型和位置插值方法的PPL保持在较低水平。然而,当上下文长度超出这个范围时,PPL显著增加。相比之下,LONGHEADS、Landmark Attention和LM-Infinite即使在32k的序列长度上也能成功保持低PPL得分。
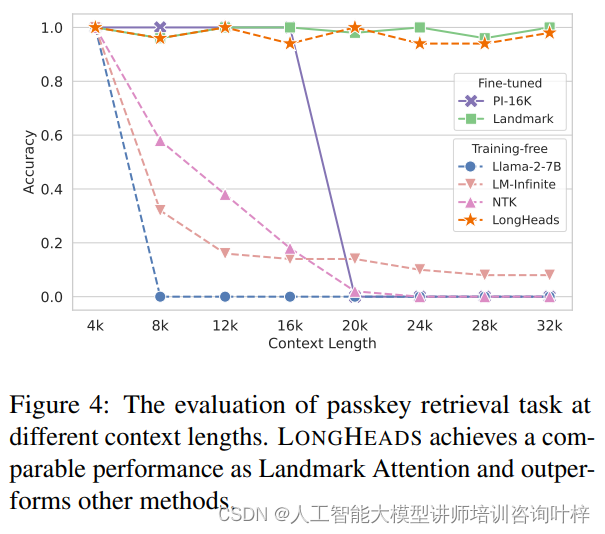
基于检索的任务评估这项任务挑战语言模型在长文本序列中准确定位和检索一个简单的密码——一个五位数的随机数。这项任务测试了语言模型是否能够有效地关注输入序列的所有位置的信息。
实验中,密码被放置在不同上下文长度(从4k到32k,间隔为4k)的文本中,每种上下文长度进行了50次测试,密码在上下文中的位置是随机的。结果显示,所有模型在预训练长度内都能输出密码,但基础模型在扩展长度上完全失败。而LONGHEADS和Landmark Attention无论序列长度如何,都能以接近100%的准确率一致地检索密码。
最后,为了更全面地反映模型处理长序列的能力,研究团队使用了LongBench进行下游NLP任务的评估。LongBench是一个多任务基准,包括单文档问答、多文档问答、摘要、少样本学习和代码补全等任务。这些任务覆盖了NLP领域的多个重要方面,能够全面评估模型对长文本的理解和处理能力。
在LongBench上的实验结果表明,LONGHEADS在受限注意力设置中的性能优于其他方法,并且在与全注意力方法的比较中也显示出竞争力。特别是在将上下文窗口扩展到32k时,LONGHEADS能够保持其性能,超越了所有基线方法,证明了其在长文本处理上的通用性和有效性。
分析
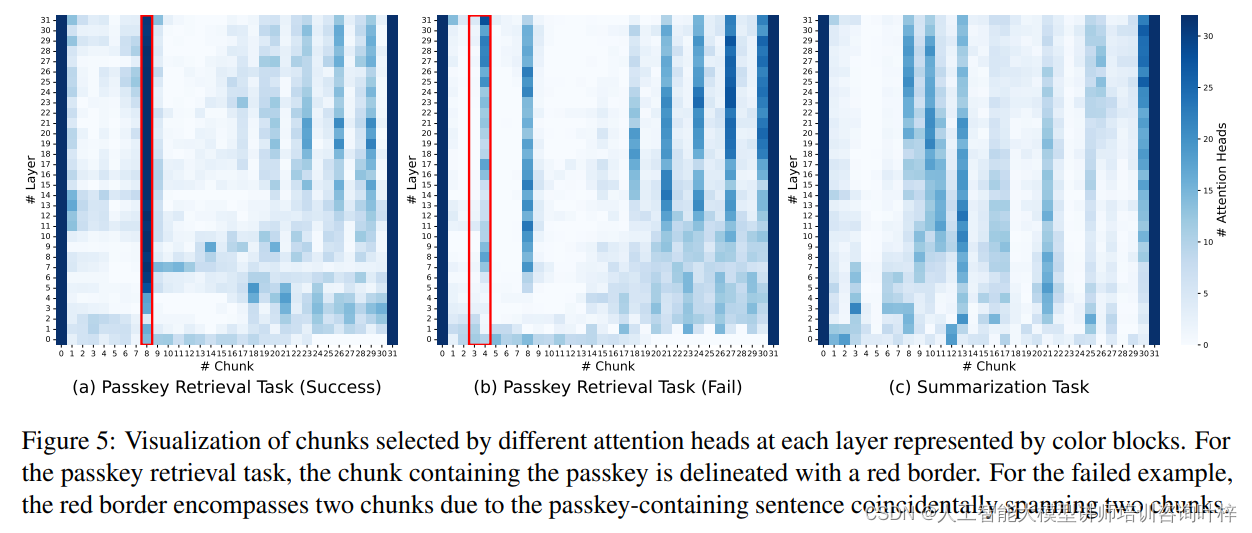
研究团队探讨了LONGHEADS框架中不同注意力头是如何处理长文本的,以及它们是否能够成功识别并集中于文本中的关键信息。通过一系列的可视化展示和统计分析,研究团队评估了模型在执行检索密码和摘要任务时的表现。
检索密码任务: 在这一任务中,所有注意力头都集中于包含答案的同一文本块,并准确预测出了密码。即使在某些情况下密码没有被成功预测,包含答案的文本块仍然被多个注意力头选中。这表明LONGHEADS的注意力头能够聚焦于文本中的重要部分,即便在长文本环境中也能够准确捕捉到关键信息。
摘要任务: 与检索任务不同,在摘要任务中,注意力头更加均匀地分散其关注点,以覆盖整个文本的信息。这种分布的均匀性有助于模型生成全面且连贯的摘要。
可视化结果: 通过可视化分析,研究团队展示了不同注意力头在不同层级上选择的文本块。颜色块表示了每个注意力头在每个层级上选择的文本块,清晰地揭示了模型在处理长文本时的注意力分布。
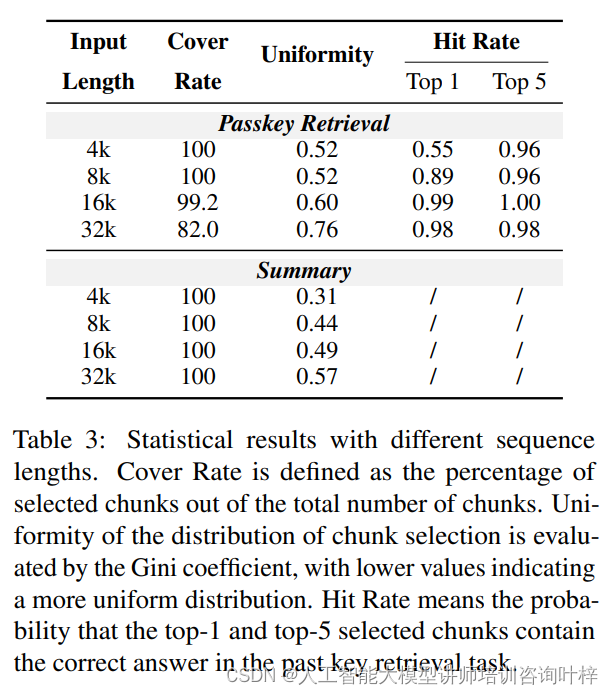
统计结果: 统计数据进一步证实了LONGHEADS的注意力头在不同序列长度上的表现。例如,在检索密码任务中,即使在32k的长序列上,模型的命中率也接近100%,这显示了模型在长文本处理上的高效性和有效性。
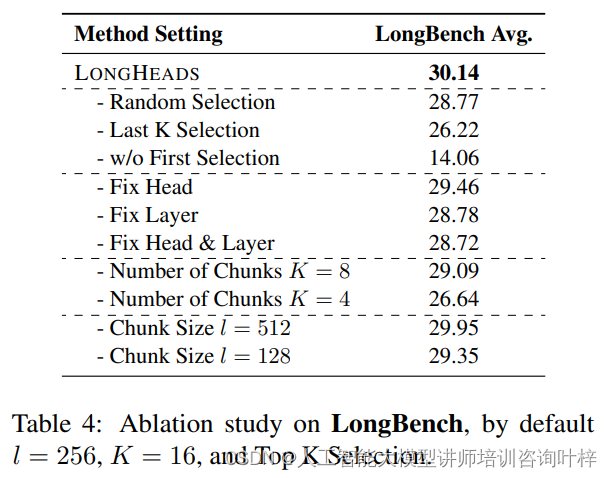
为了更深入地理解LONGHEADS框架的性能,研究团队还进行了消融实验,以评估块选择策略、注意力头的灵活性、块数K和块大小l对模型表现的具体影响。
块选择策略: 实验结果显示,选择得分最高的块明显优于选择得分最低的块,甚至随机选择也比最后K个选择的结果要好。此外,当不保留文本的第一个块时,模型性能显著下降,这强调了块选择策略在维持模型输出分布稳定性中的重要性。
注意力头的灵活性: 当限制注意力头的灵活性时,模型性能受到了不同程度的影响。这表明在LONGHEADS框架中,不同注意力头在每一层的协作对于整体性能至关重要。
块数和块大小: 消融实验还探讨了块数和块大小对模型性能的影响。结果表明,增加文本中的块数可以提供更多信息,但效益呈现递减趋势。这表明适量的块数已经足够保证性能,并且通过块选择策略可以有效地获取整个序列的信息。同时,不同的块大小对结果的影响不大,说明LONGHEADS可以适应不同的块大小设置。
实验结果表明,LONGHEADS不仅在语言建模、密码检索等任务上取得了优异的性能,而且在下游NLP任务中也展现出了强大的能力。特别是在不需要额外训练成本的情况下,LONGHEADS能够直接扩展现有模型的上下文处理能力,这一点对于资源受限的实际应用场景尤为重要。
然而,LONGHEADS也存在一些局限性。例如,文本分块可能会破坏内容的连续性,影响模型对某些任务的性能;另外,模型能够处理的文本长度受到一定限制。未来的工作可以探索更加灵活的分块策略,以及进一步提高模型对长文本的理解和处理能力。
论文链接:https://arxiv.org/abs/2402.10685
代码链接:https://github.com/LuLuLuyi/LongHeads