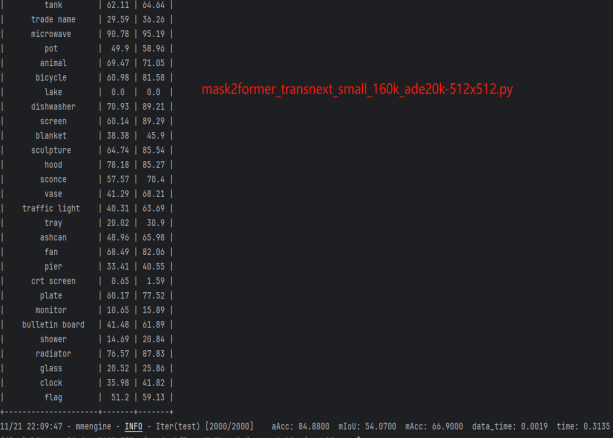
大型语言模型(Large Language Models, LLMs)与智能代理(Agent)的融合架构已成为人工智能领域推动企业智能化的核心技术。这种协同工作模型利用LLM的语言理解、推理和生成能力,为Agent提供强大的知识支持,而Agent通过感知、决策和执行功能,将LLM的智能转化为实际行动。然而,模型不稳定性(如幻觉、过度自信)、总结不专业(如信息冗余、准确性不足)以及复杂任务协调的挑战(如多Agent冲突)限制了其效能。本章基于最新研究,深入探讨LLM与Agent的协同工作机制,重点分析如何通过结构化工作流、一致性机制、序列化架构和混合专家模式(Mixture of Experts, MoE)解决上述问题,助力完成复杂任务。
4.1.1 融合架构的定义与概述
定义
LLM与Agent的协同工作模型是一种融合架构,其中LLM作为核心推理引擎,提供语言理解、知识推理和生成能力,而Agent通过感知环境、制定决策和执行行动,将LLM的输出转化为实际结果。这种架构通过模块化设计和闭环机制,构建出能够处理复杂任务的智能系统。
核心目标
融合架构的目标包括:
- 增强智能性:利用LLM的语义理解和推理能力,提升Agent的决策质量。
- 扩展功能:通过Agent的感知和执行能力,将LLM的知识应用于物理或虚拟环境。
- 动态适应:结合LLM的上下文感知和Agent的状态管理,适应动态、不确定场景。
- 高效协作:通过标准化接口和模块化设计,实现LLM与Agent的无缝交互。
架构特点
- 模块化:将LLM和Agent功能分解为独立模块,便于定制和扩展。
- 闭环系统:通过感知、推理、决策和执行形成闭环,支持持续优化。
- 多Agent支持:适配多Agent协作,处理大规模任务。
- 上下文感知:利用LLM的记忆能力,增强交互连续性和个性化。
4.1.2 LLM与Agent的协同工作机制
协同工作流程
LLM与Agent的协同工作通过以下机制实现,基于Multi-Agent Collaboration Mechanisms: A Survey of LLMs:
- 任务分解与推理
LLM通过Chain of Thought(CoT)提示将复杂任务分解为子任务,生成推理步骤。Agent根据推理结果分配子任务,调用工具或执行行动。例如,规划一次旅行被分解为“查询航班”、“预订酒店”和“安排交通”。 - 上下文管理与记忆
LLM通过上下文窗口或外部记忆模块(如LangMem、Zep)存储任务历史、用户偏好或环境状态。Agent利用这些信息保持交互连续性。例如,客服Agent记住用户之前的查询,提供一致回答。 - 决策与行动
LLM生成推理结果或建议,Agent基于此选择行动并执行。例如,LLM预测市场趋势,Agent决定买入或卖出股票。执行结果反馈给LLM,触发下一轮推理。 - 反馈与优化
Agent通过感知执行结果,评估任务进展,并将反馈传递给LLM。LLM根据反馈调整推理或生成新建议,形成闭环优化。例如,自动驾驶Agent感知路径偏差,LLM重新推理并调整行驶策略。
关键框架
2025年的协同框架包括:
- OpenAI的Swarm:通过例程和交接(handoffs)实现无缝协作,适合客服等场景(参考:OpenAI Cookbook)。
- Microsoft的Magentic-One:使用协调器(Orchestrator)规划、跟踪和错误恢复,委托给专业Agent(参考:Magentic-One Research)。
- IBM的Bee Agent:模块化设计,支持序列化暂停/恢复工作流,使用Granite和Llama 3(参考:[Bee Agent框架](https://i-am-bee.github.io/bee-agent-framework/#/))。
- LangChain:提供Agents、Tools和Memory模块,支持复杂推理和决策(参考:LangChain文档)。
协同模式
根据Multi-Agent Collaboration Mechanisms,协同模式包括:
- 合作模式:Agent共享目标,共同完成任务。例如,客服Agent和知识库Agent协作回答问题。
- 竞争模式:Agent竞争提供最佳输出,协调器选择优胜者。例如,多个翻译Agent竞争生成最佳译文。
- Coopetition(合作与竞争结合):Agent在竞争中协作,平衡效率和创新。例如,软件开发Agent竞争编码方案,同时协作测试。
4.1.3 解决模型不稳定性
不稳定性的表现
模型不稳定性主要包括:
- 幻觉(Hallucination):LLM生成虚假或不准确信息,可能导致Agent基于错误数据行动。
- 过度自信(Overconfidence):LLM对低置信度输出表现出高确定性,误导Agent决策。
- 级联错误(Cascading Errors):在多Agent系统中,单一错误传播,放大影响(参考:Challenges of Multi-LLM Agent Collaboration)。
解决策略
2025年的研究提供了以下解决方案:
- 结构化工作流
通过预定义角色和阶段减少自由生成风险。例如,MetaGPT通过角色分配(如分析师、执行者)规范Agent行为,降低幻觉概率(参考:MetaGPT研究)。
实现:LangGraph将任务建模为有向无环图(DAG),通过节点控制子任务执行,确保逻辑一致(参考:LangGraph扩展)。 - 一致性机制
Consensus-LLM通过多Agent协商验证输出,确保结果一致。例如,金融Agent协商市场预测,剔除异常值。
实现:使用投票或置信度加权,融合多个LLM输出,降低错误率。 - 错误检测与纠正
Agent通过外部工具验证LLM输出。例如,客服Agent调用知识库核实答案,防止幻觉。
实现:结合Tool Integration(如REST API)验证数据,错误结果触发重新推理。 - 协作友好LLM设计
Google的Gemini 2.0专为多Agent协作优化,减少过度自信和幻觉(参考:Gemini AI博客)。
实现:通过强化学习和人类反馈(RLHF)微调,提升输出可靠性。 - 安全协议
制定伦理指导,防止Agent被误导或滥用。例如,限制Agent访问敏感数据,设置行为边界。
实现:通过沙箱技术和权限控制,确保安全操作。
案例:金融交易Agent
一家投资银行开发交易Agent,LLM分析市场数据,Agent执行买卖。问题:LLM偶现幻觉,预测错误趋势。解决方案:
- 使用MetaGPT结构化工作流,规范分析和执行阶段。
- Consensus-LLM协商多模型预测,剔除异常。
- 实时API验证市场数据,纠正错误。
结果:交易准确率提升20%,错误率降低15%。
4.1.4 确保专业总结
挑战与需求
专业总结需准确、简洁且相关,但面临以下问题:
- 信息冗余:LLM生成冗长或无关内容,降低总结效率。
- 准确性不足:总结可能遗漏关键信息或包含错误。
- 上下文不一致:多Agent协作中,总结可能偏离任务目标。
根据LLM Agents: A Complete Guide,专业总结需动态评估和领域优化。
确保策略
- 序列化架构
Agent-as-a-Judge通过多Agent顺序处理任务,确保总结质量。例如,在科学问答中,检索Agent收集信息,总结Agent生成答案,评估Agent验证准确性(参考:Agent-as-a-Judge研究)。
实现:LangChain的Chains模块支持序列化工作流,规范总结流程。 - 领域知识优化
Agent结合领域知识库,提升总结准确性。例如,医疗诊断Agent调用医学数据库,确保总结符合专业标准。
实现:通过知识图谱或向量存储(如FAISS)检索领域数据。 - 动态评估框架
Benchmark Self-Evolving创建挑战性实例,测试总结能力,优化模型性能。
实现:通过自动化测试和人类反馈,迭代改进总结逻辑。 - 合成数据生成
Orca-AgentInstruct通过三阶段代理流(生成、评估、优化)生成高质量数据,Mistral 7B模型总结能力提升54%(参考:Microsoft研究博客)。
实现:结合合成数据微调LLM,提升总结精准度。
案例:客服总结Agent
一家电商平台开发客服Agent,总结用户交互记录。问题:总结冗长,遗漏关键问题。解决方案:
- 使用Agent-as-a-Judge,检索Agent收集对话,总结Agent生成报告,评估Agent剔除冗余。
- 结合CRM知识库,确保总结准确。
- Orca-AgentInstruct生成训练数据,优化LLM。
结果:总结长度缩短30%,准确率提升25%。
4.1.5 混合专家模式(MoE)在复杂任务协调中的作用
MoE的定义与原理
**混合专家模式(MoE)**是一种将多个专家Agent结合的框架,通过门控机制决定每个专家对输出的贡献权重。根据Multi-Agent Collaboration Mechanisms,MoE适合coopetition场景,专家竞争贡献输出,增强任务多样性处理。
协调复杂任务的机制
MoE通过以下方式协调复杂任务:
- 任务分工
每个Agent专注于子任务,减少冲突。例如,软件开发中,编码Agent、测试Agent和文档Agent分工协作。 - 门控机制
LLM作为门控器,根据任务需求选择专家。例如,多语言翻译中,门控器根据语言类型选择翻译Agent。 - 动态适应
门控机制动态调整专家权重,确保最佳输出。例如,复杂任务中,优先选择高置信度Agent。 - 减少重复交互
通过角色分配,减少Agent间的重复沟通,提高效率。
实现技术
- 门控网络
使用Transformer或MLP作为门控器,基于输入特征选择专家。
实现:通过监督学习或强化学习训练门控器,优化选择逻辑。 - 专家训练
每个专家Agent针对特定任务微调,提升专业性。
实现:通过LoRA或Adapter微调,降低计算成本。 - 分布式计算
MoE通过分布式框架(如PyTorch Distributed)支持大规模专家协作。
实现:结合GPU集群,加速推理和训练。 - 框架支持
ChatDev通过MoE实现软件开发协作,门控机制根据阶段选择Agent(参考:ChatDev研究)。
LangChain支持MoE集成,通过Agents模块实现专家协作。
案例:软件开发MoE
一家科技公司使用MoE开发软件,任务包括需求分析、编码和测试。实现:
- 分工:需求Agent分析用户需求,编码Agent生成代码,测试Agent验证功能。
- 门控机制:LLM根据任务阶段选择Agent(如编码阶段优先编码Agent)。
- 反馈:测试结果反馈给编码Agent,优化代码。
结果:开发周期缩短40%,代码质量提升30%。
优势与挑战
- 优势:
- 提升任务多样性处理能力。
- 动态适应复杂任务需求。
- 减少重复交互,提高效率。
- 挑战:
- 门控机制设计复杂,需优化训练。
- 多Agent协作增加计算成本。
- 专家冲突可能降低一致性。
4.1.6 企业应用案例
- 金融服务:智能投资分析
场景:
一家投资银行开发交易Agent,LLM分析市场数据,Agent执行买卖。
协同:LLM通过CoT分解分析任务,Agent调用API执行交易。
不稳定性解决:MetaGPT规范工作流,Consensus-LLM验证预测。
专业总结:Agent-as-a-Judge生成简洁报告。
MoE:分析Agent、交易Agent和风险Agent协作,门控器选择最佳策略。
优势:交易效率提升25%。
挑战:需确保数据安全。
- 零售:个性化客服
场景:
一家电商平台开发客服Agent,处理用户查询。
协同:LLM理解意图,Agent调用CRM系统。
不稳定性解决:一致性机制验证答案。
专业总结:Orca-AgentInstruct优化总结。
MoE:查询Agent和推荐Agent协作,门控器根据问题类型选择。
优势:客户满意度提升20%。
挑战:需优化响应速度。
- 医疗:辅助诊断
场景:
一家医院开发诊断Agent,分析患者数据。
协同:LLM推理症状,Agent查询数据库。
不稳定性解决:外部验证确保准确性。
专业总结:序列化架构生成诊断报告。
MoE:症状Agent和数据库Agent协作,门控器选择输出。
优势:诊断效率提升30%。
挑战:需保护隐私。
4.1.7 2025年发展趋势
-
多模态融合:LLMs支持图像、语音输入,增强Agent感知能力。
-
多Agent协作:MoE扩展到大规模系统,协调复杂任务。
-
高效部署:模型压缩和边缘计算降低成本。
-
标准化框架:AGNTCY推动互操作性(参考:AGNTCY标准)。
-
伦理与治理:差分隐私和可解释AI提升可信度。
LLM与Agent的协同工作模型通过任务分解、上下文管理、决策行动和反馈优化,形成高效闭环系统。结构化工作流、一致性机制和错误纠正解决模型不稳定性,序列化架构和领域优化确保专业总结,MoE通过门控机制协调复杂任务。在金融、零售和医疗等领域的应用,展示了其强大潜力。未来,多模态融合、多Agent协作和标准化框架将进一步推动发展,为企业智能化转型提供支持。