智慧语音助手
- 1 语音识别系统(ASR)
- 2 语义理解
- 1 传统的实现方法
- 1. 音频信号处理和语音识别(Automatic Speech Recognition, ASR)
- 2. 自然语言理解(Natural Language Understanding, NLU)
- 3. 对话管理(Dialog Management)
- 4. 后端服务集成和执行
- 5. 系统集成与优化
- 6. 用户界面设计与反馈机制
- 7. 部署和监控
- 2 基于大模型
- 1. 数据收集与准备
- 2. 语音识别(Automatic Speech Recognition, ASR)
- 3. 自然语言理解(Natural Language Understanding, NLU)
- 4. 对话管理(Dialog Management)
- 5. 后端服务集成和执行
- 6. 用户界面设计与反馈机制
- 7. 部署和监控

1 语音识别系统(ASR)
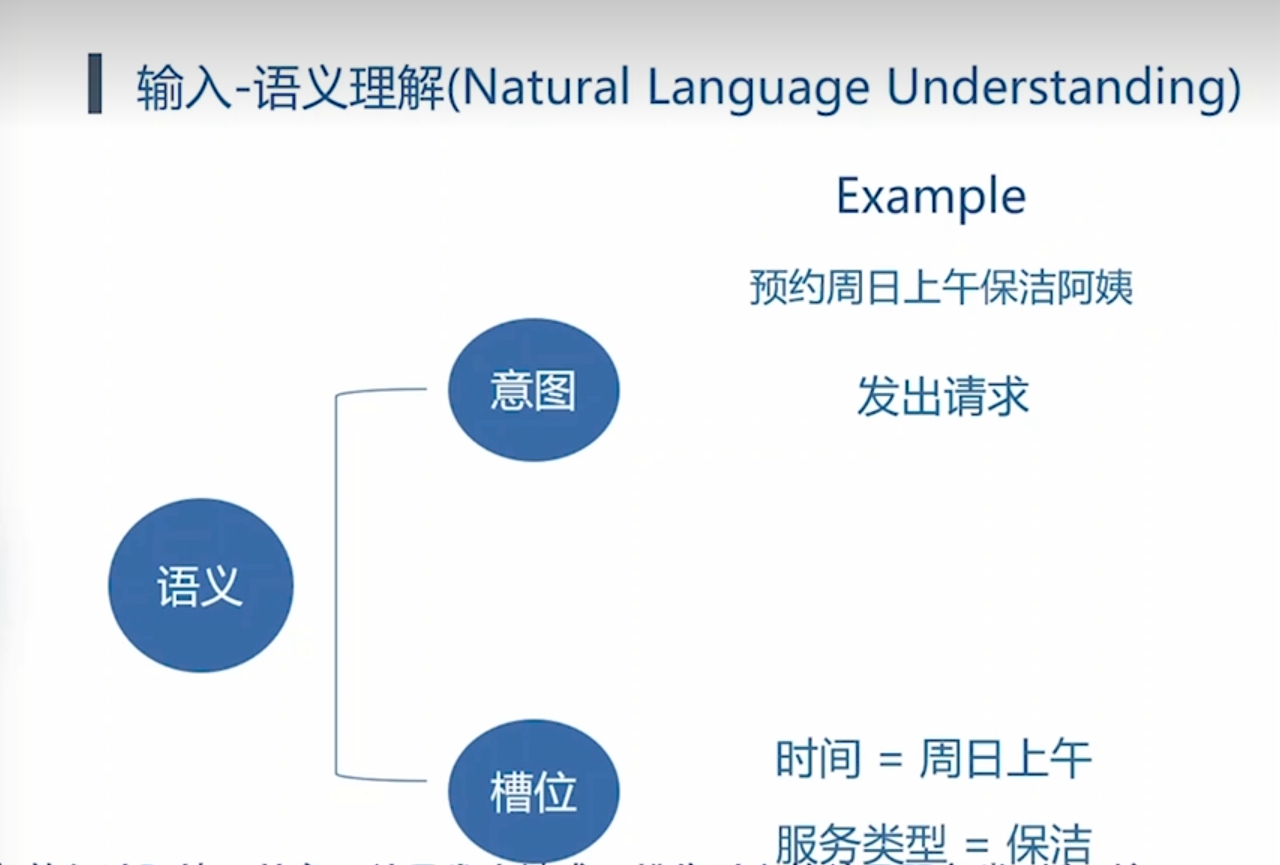
2 语义理解
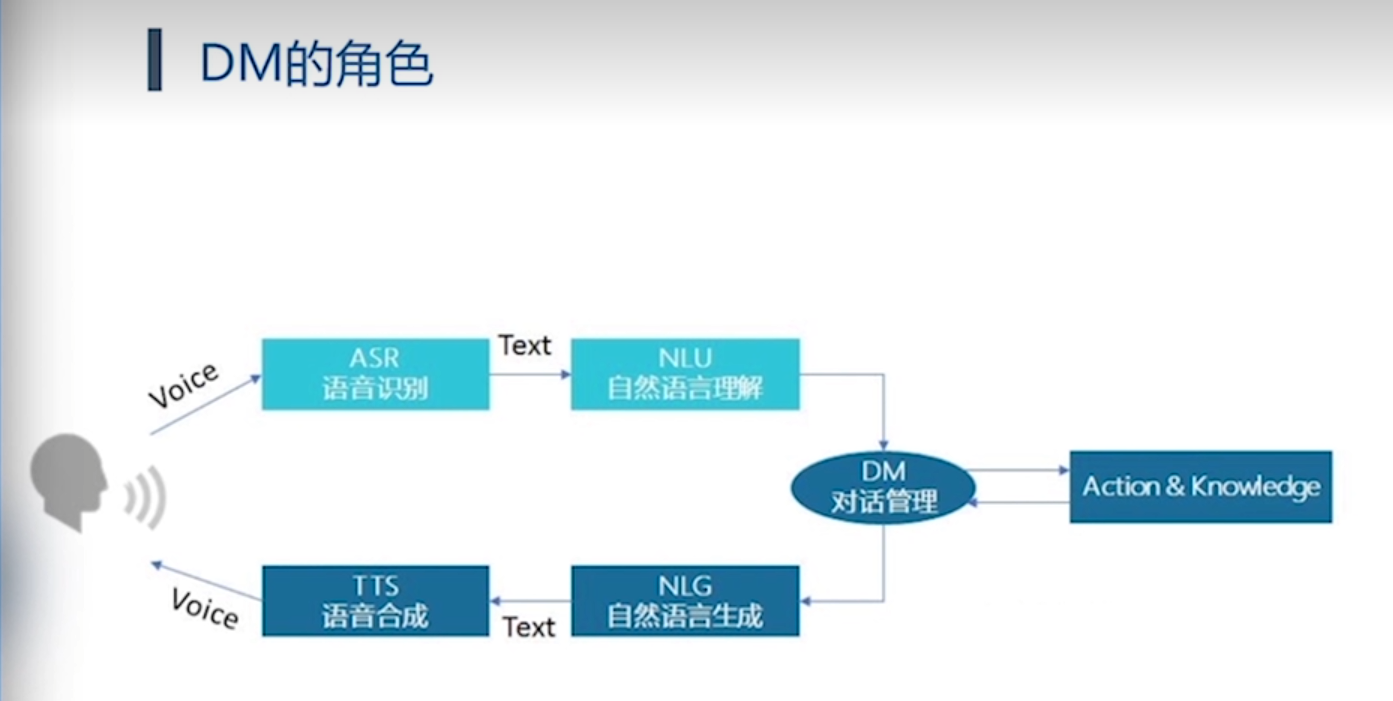
DM对话管理:

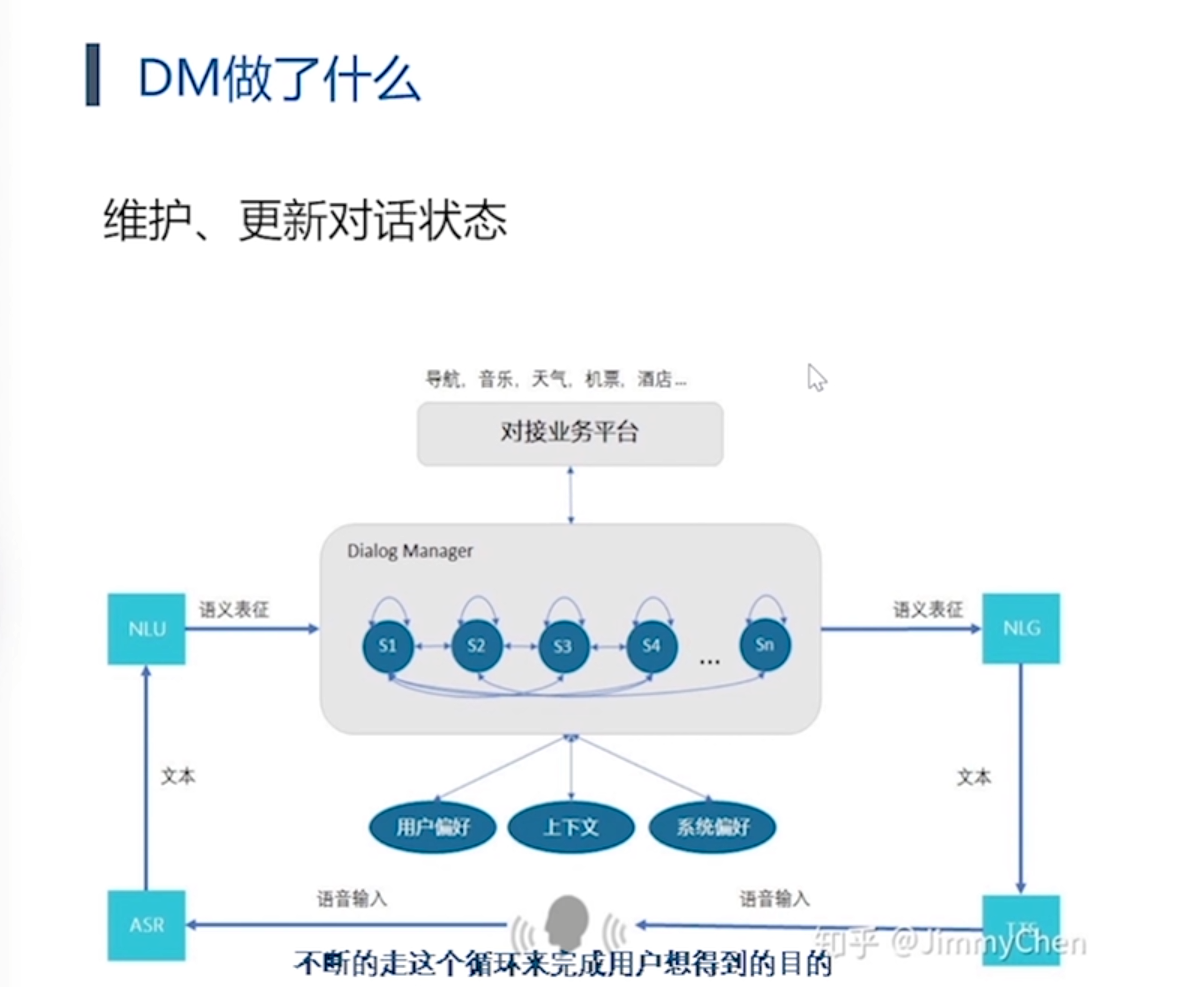
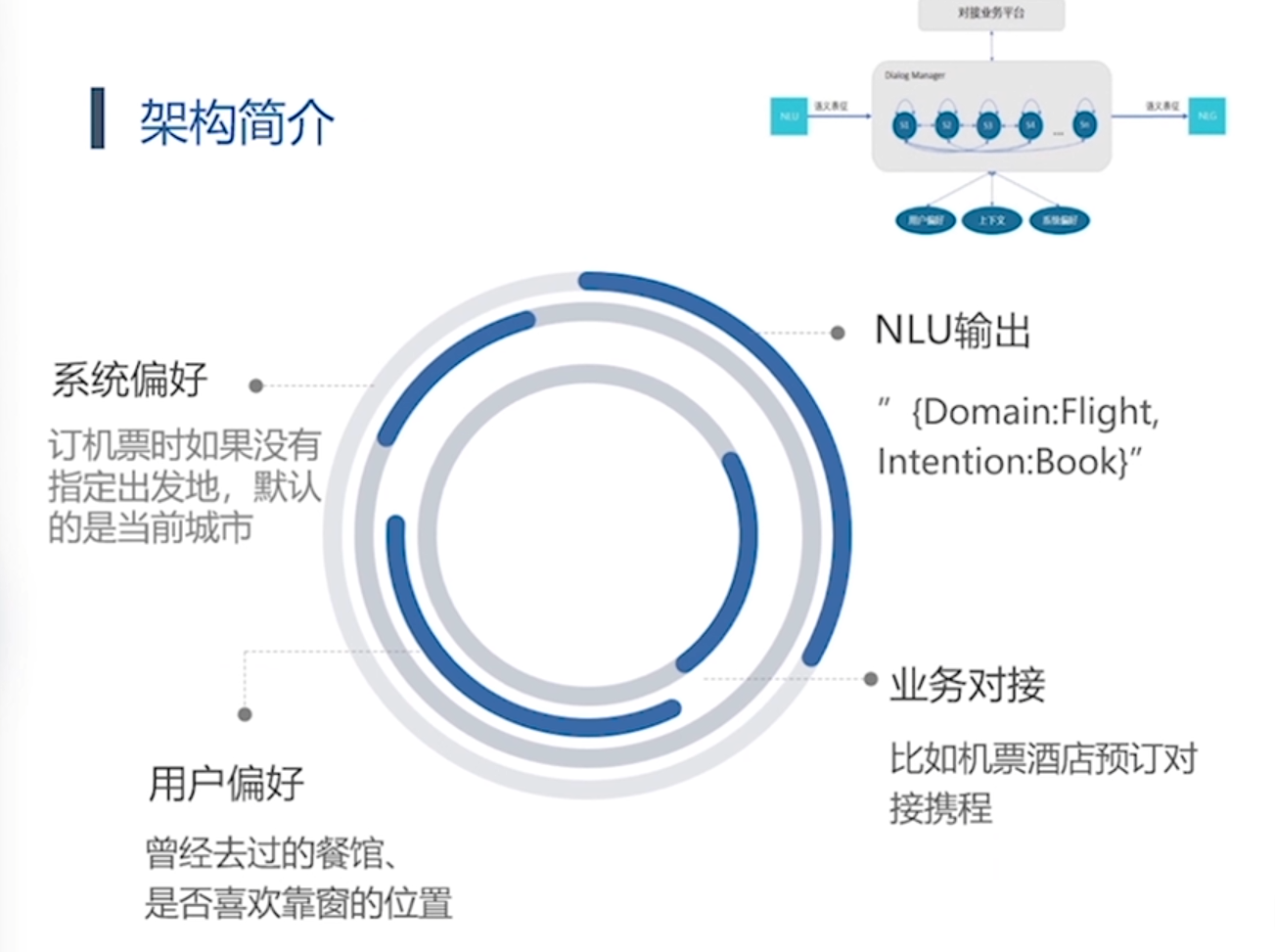
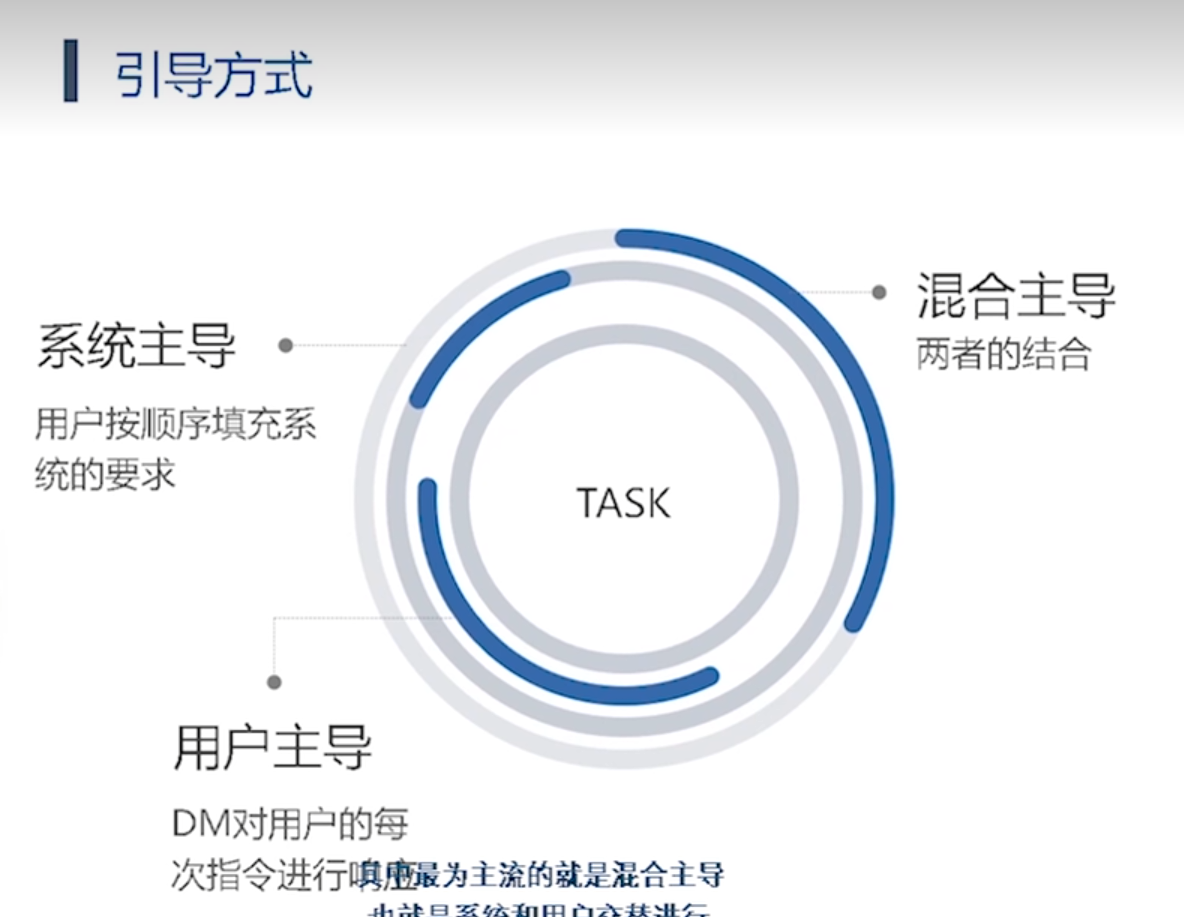
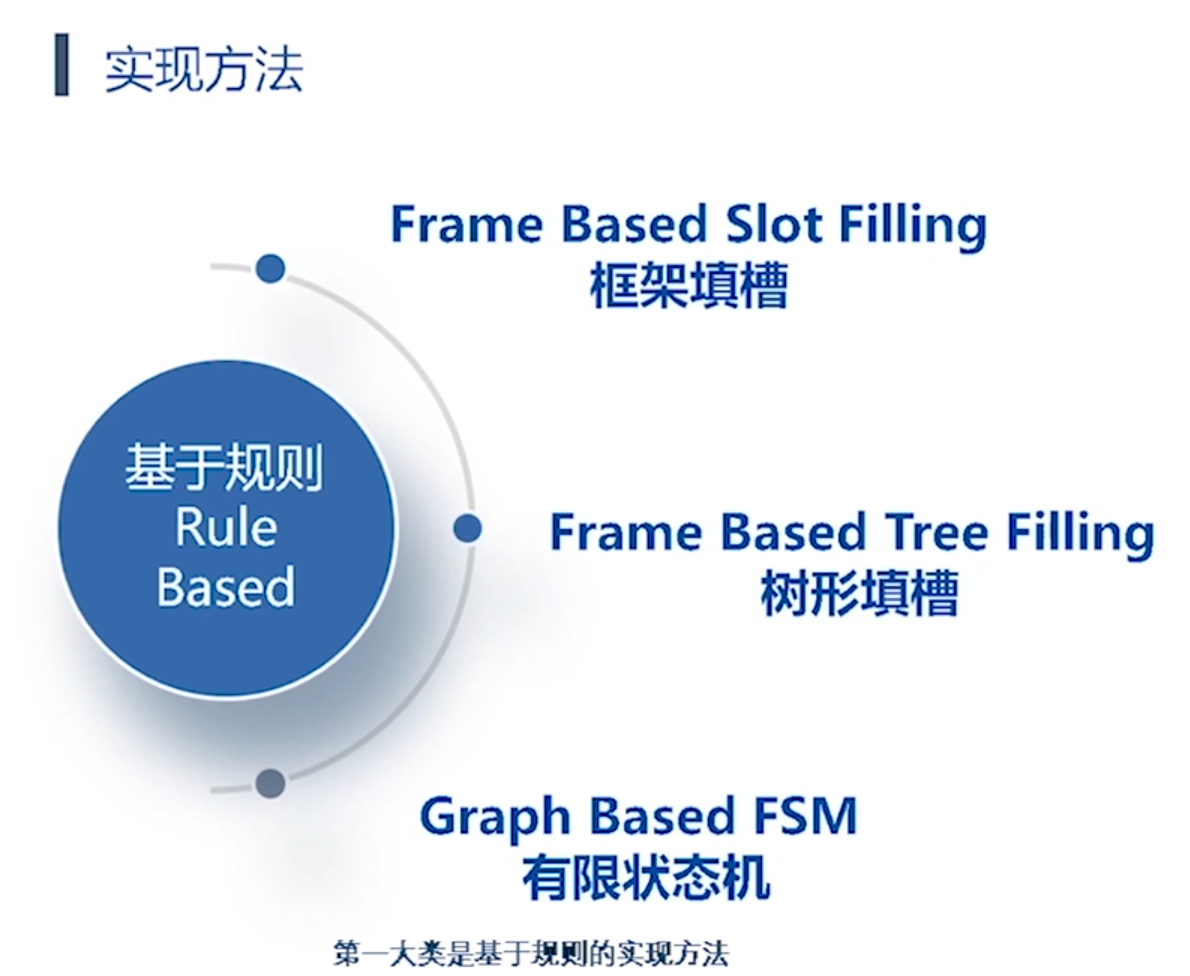


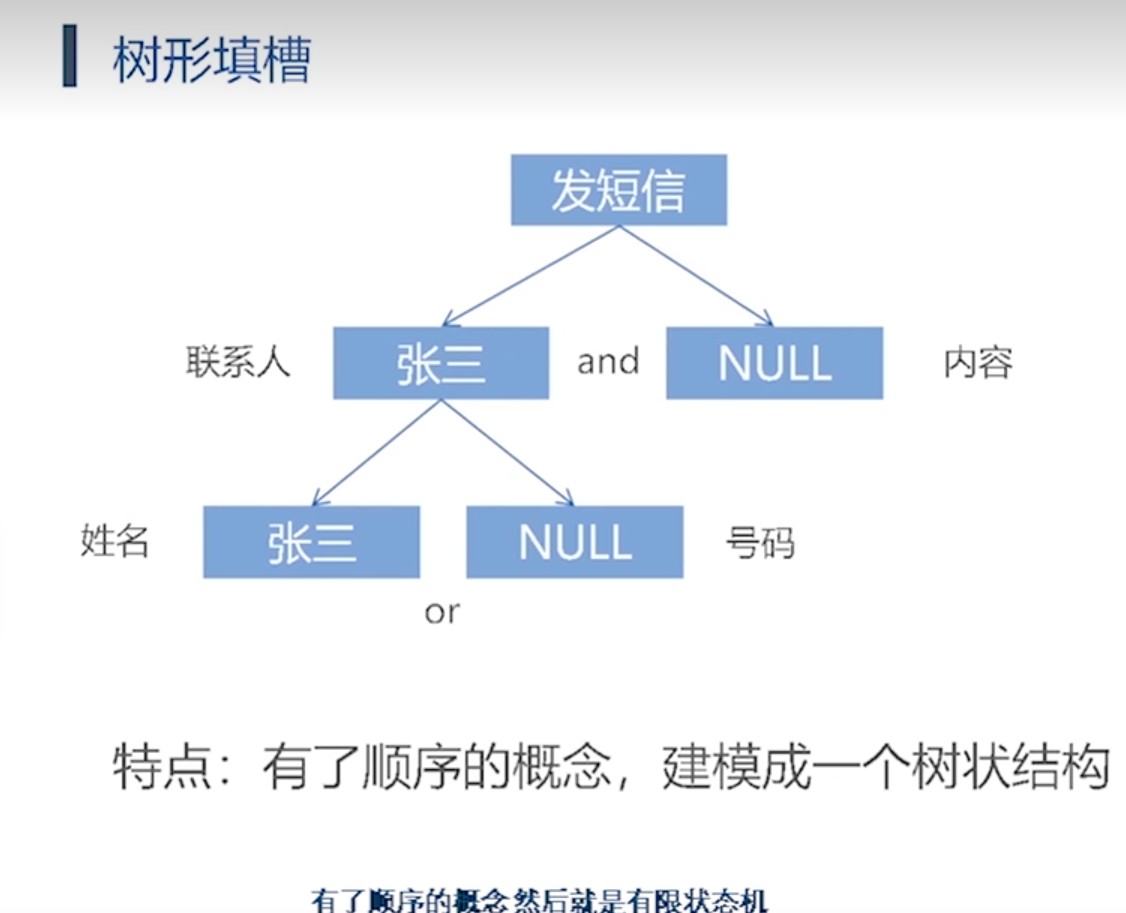
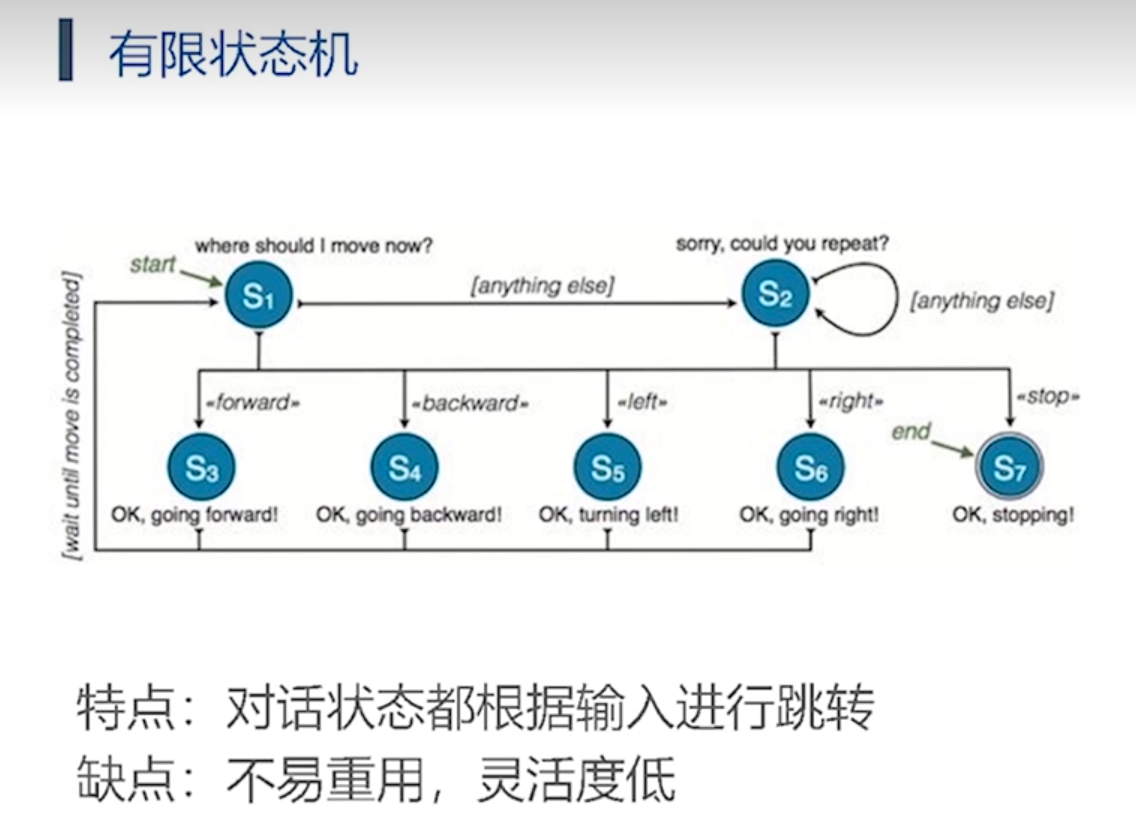
第二类方法:


在自然语言处理和语义理解中,槽位填充(Slot Filling)是指识别和填充一个句子或对话中特定信息的过程。通常情况下,这些特定信息被称为槽位(Slots),它们是对话中需要填写的关键信息或变量,比如时间、地点、人物、事件等等。
槽位填充通常用于对话系统(如语音助手或聊天机器人)中,以帮助系统理解用户意图并有效地响应。在对话系统中,用户通常会提出各种请求或问题,例如预订机票、查询天气、订购食物等。这些请求中会涉及到不同的槽位,例如:
- 预订机票时可能涉及的槽位包括出发地、目的地、日期、座位类型等;
- 查询天气时可能涉及的槽位包括地点、日期、时间段等。
槽位填充的过程涉及到以下几个步骤:
-
意图识别(Intent Recognition):确定用户在进行何种类型的请求或问题。
-
槽位识别(Slot Recognition):识别句子中与特定信息有关的部分,例如地点、时间等。
-
槽位填充(Slot Filling):填充识别出的槽位,将其具体的值提取出来,并与系统的后端服务进行集成,以完成用户的请求。
-
对话管理(Dialog Management):根据填充的槽位和识别的意图,决定系统如何响应用户,可能涉及到后续的询问、确认或直接操作后端服务。
槽位填充技术通常依赖于自然语言处理(NLP)技术,包括命名实体识别(NER)、关系抽取、语法分析等。近年来,随着深度学习技术的发展,特别是序列标注任务(如基于条件随机场的序列标注)和预训练语言模型(如BERT、GPT等),槽位填充在对话系统中的精度和效率有了显著提升。
是的,目前的语音助理系统通常使用槽位填充技术来理解用户的语音输入并执行相应的控制或服务。语音助理的工作流程通常如下:
-
语音识别(ASR):将用户的语音输入转换为文本形式。
-
意图识别(Intent Recognition):识别用户的意图,即用户想要完成的任务或请求。
-
槽位识别和填充(Slot Recognition and Filling):从识别出的文本中提取出关键信息,填充预定义的槽位。这些槽位通常与用户请求相关,例如时间、地点、动作等。
-
对话管理(Dialog Management):根据填充的槽位和识别的意图,决定如何处理用户请求。这可能涉及到进一步的信息获取、确认用户意图、执行相关操作等。
-
后端服务调用和执行:将填充的槽位值传递给后端服务,执行实际的任务或操作。例如,预订机票、设置提醒、查询天气等。
通过槽位填充技术,语音助理能够更精确地理解用户的语音指令,从而提供更高效和个性化的服务。随着语音识别和自然语言理解技术的进步,这些系统在处理各种语音指令时的准确性和用户体验也在不断提升。
1 传统的实现方法
传统的语音助理系统在没有大模型技术支持的情况下,通常采用以下技术和实现路径:
-
语音识别(Automatic Speech Recognition, ASR):
- 音频信号处理: 首先对用户的语音输入进行预处理,如降噪、语音分割等。
- 特征提取: 将预处理后的语音信号转换为特征向量,通常使用MFCC(Mel-frequency cepstral coefficients)或其它声学特征来表示语音信息。
- 声学模型: 使用经典的声学模型(如隐马尔可夫模型,Hidden Markov Models, HMM)或基于高斯混合模型(Gaussian Mixture Models, GMM)的语音识别系统,将语音特征序列映射到文字转录。
-
自然语言理解(Natural Language Understanding, NLU):
- 语法分析和模式匹配: 使用基于规则或有限状态机的方法来分析和理解用户输入的文本,识别用户意图和关键信息。
- 模板匹配: 预先定义好的模板或固定的语法规则来匹配和提取用户意图和槽位信息。
-
对话管理(Dialog Management):
- 基于预定义的对话策略(如有限状态机或基于规则的对话管理器),根据当前对话状态和用户输入来确定系统的响应。
- 简单的逻辑处理来管理对话流程,如确定何时向用户请求进一步信息或执行特定操作。
-
后端服务集成:
- 将从NLU阶段获取的槽位信息传递给后端服务进行具体任务的执行,如查询数据库、调用API服务等。
- 对服务响应进行简单的处理和整合,生成最终的回复或结果,然后返回给用户。
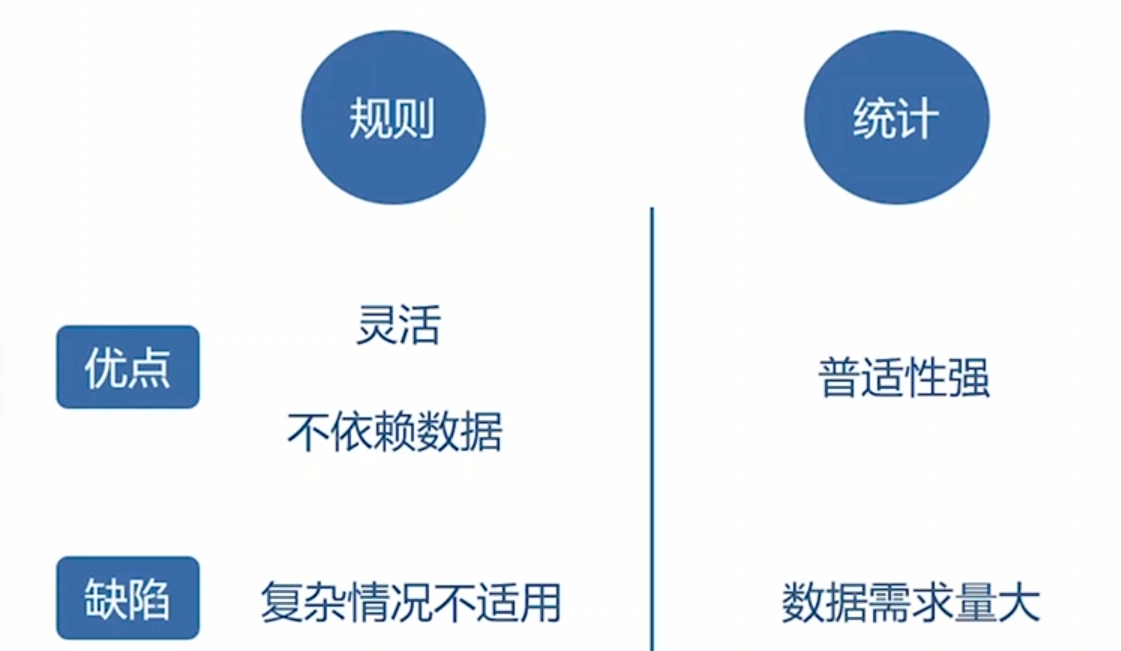
传统的语音助理系统在技术上更加依赖于规则和经典机器学习方法,这些方法通常需要人工设计和调整。与基于大模型的现代方法相比,传统系统可能在语义理解和自然语言生成的准确性和灵活性上存在一定的局限性。然而,传统方法在资源消耗和实时性上可能具有一定的优势,因为它们通常不需要大规模的计算资源和训练过程。
**作为产品经理,要设计一个传统的语音助理系统的技术路线图,可以包括以下关键步骤和技术组成:
1. 音频信号处理和语音识别(Automatic Speech Recognition, ASR)
-
音频信号预处理:
- 实现噪声消除、语音信号增强等预处理技术,确保清晰的语音输入。
-
特征提取:
- 使用MFCC(Mel-frequency cepstral coefficients)或其它声学特征提取方法,将语音信号转换为特征向量。
-
声学模型:
- 部署基于隐马尔可夫模型(Hidden Markov Models, HMM)或高斯混合模型(Gaussian Mixture Models, GMM)的声学模型,将语音特征映射到文字转录。
2. 自然语言理解(Natural Language Understanding, NLU)
-
语法分析和模式匹配:
- 设计和实现基于规则或有限状态机的语法分析器,用于识别用户意图和关键信息。
-
关键词提取和槽位填充:
- 开发算法来提取用户输入中的关键词和槽位信息,如时间、地点、操作动作等。
3. 对话管理(Dialog Management)
-
对话状态追踪:
- 设计状态追踪机制,以管理和维护当前对话状态,包括用户已提供的信息和系统待请求的信息。
-
对话策略设计:
- 定义基于规则的对话策略,确定系统如何根据用户输入和当前状态生成响应。
4. 后端服务集成和执行
-
服务调用接口设计:
- 设计和实现与后端服务(如数据库、API服务等)的接口,用于执行特定任务,如查询、预订、信息检索等。
-
结果整合和响应生成:
- 将来自后端服务的响应整合并生成最终的语音或文本回复,以向用户呈现结果。
5. 系统集成与优化
-
系统集成和测试:
- 将各个模块集成到一个整体系统中,并进行全面的功能和性能测试。
-
性能优化:
- 优化系统各部分的效率和响应时间,以提升用户体验和系统的实时性。
6. 用户界面设计与反馈机制
-
语音交互界面设计:
- 设计用户友好的语音交互界面,包括语音提示、确认和错误处理机制。
-
反馈机制:
- 实现用户反馈收集和处理机制,用于持续改进系统的功能和性能。
7. 部署和监控
-
系统部署:
- 将系统部署到生产环境,并确保稳定性和可扩展性。
-
监控和维护:
- 设计监控系统来监测系统运行状况和性能指标,及时处理问题并进行必要的维护和更新。
这个技术路线图涵盖了传统语音助理系统开发的主要步骤和关键技术,可以帮助产品经理规划和管理整个开发过程,确保系统能够按照预期功能和性能要求进行实现和部署。*
2 基于大模型
作为产品经理,设计基于大模型的语音助理系统的技术路线图需要考虑以下关键步骤和技术组成,以确保系统能够高效地实现语音理解和对话管理:
1. 数据收集与准备
-
语音数据收集:
- 获取足够量的语音数据,覆盖各种语音风格、口音和环境条件。
- 数据清洗和标注:清理和标注语音数据,准备用于训练语音识别模型的数据集。
-
文本数据收集:
- 收集用于预训练语言模型的大规模文本数据,用于训练和微调自然语言理解模型。
2. 语音识别(Automatic Speech Recognition, ASR)
-
端到端语音识别模型设计:
- 选择合适的深度学习架构,如CNN、LSTM、Transformer等,设计端到端的语音识别模型。
- 训练模型以将原始语音信号直接转换为文本序列。
-
模型优化与调整:
- 调整模型架构和超参数,优化语音识别的准确率和速度。
- 集成语音前处理技术,如噪声消除、语音增强等,提升模型在复杂环境下的鲁棒性。
3. 自然语言理解(Natural Language Understanding, NLU)
-
预训练语言模型应用:
- 使用预训练的语言模型(如BERT、GPT系列)进行意图识别和槽位填充。
- Fine-tuning:在特定的语料库上微调预训练模型,适应特定领域和任务要求。
-
槽位抽取与关键信息识别:
- 开发算法和模型来提取和填充用户输入中的关键信息槽位,如日期、时间、地点等。
4. 对话管理(Dialog Management)
-
生成式对话模型设计:
- 基于Transformer架构的生成式对话模型(如GPT系列),用于自然流畅的对话生成。
- 设计对话策略和逻辑,管理多轮对话流程和上下文理解。
-
强化学习优化:
- 使用强化学习方法优化对话管理策略,使系统能够学习并改进对话过程中的决策和回复。
5. 后端服务集成和执行
-
API调用和服务集成:
- 将从NLU阶段提取的槽位信息传递给后端服务,执行各种任务,如查询数据库、调用外部API完成操作等。
-
分布式系统设计:
- 设计和实施分布式系统架构,支持高并发和扩展性,通过微服务和消息队列管理服务调用和响应。
6. 用户界面设计与反馈机制
- 多模态交互设计:
- 设计支持语音输入和文本输入的用户界面,提供直观和友好的交互体验。
- 实现用户反馈机制,收集和分析用户输入和系统响应数据,用于优化系统的性能和用户体验。
7. 部署和监控
- 系统部署和优化:
- 使用容器化技术(如Docker)和自动化部署工具(如Kubernetes)实现系统的快速部署、扩展和管理。
- 设计和实施监控系统,实时监测系统运行状况、性能指标和用户反馈,及时处理问题并进行系统优化和更新。
这个技术路线图涵盖了基于大模型的语音助理系统开发的主要步骤和关键技术,帮助产品经理规划和管理整个开发过程,确保系统能够按照预期功能和性能要求进行实现和部署。







![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] LYA的数字游戏(100分) - 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/c2de77980c1445bcbc68022a43f62061.png)