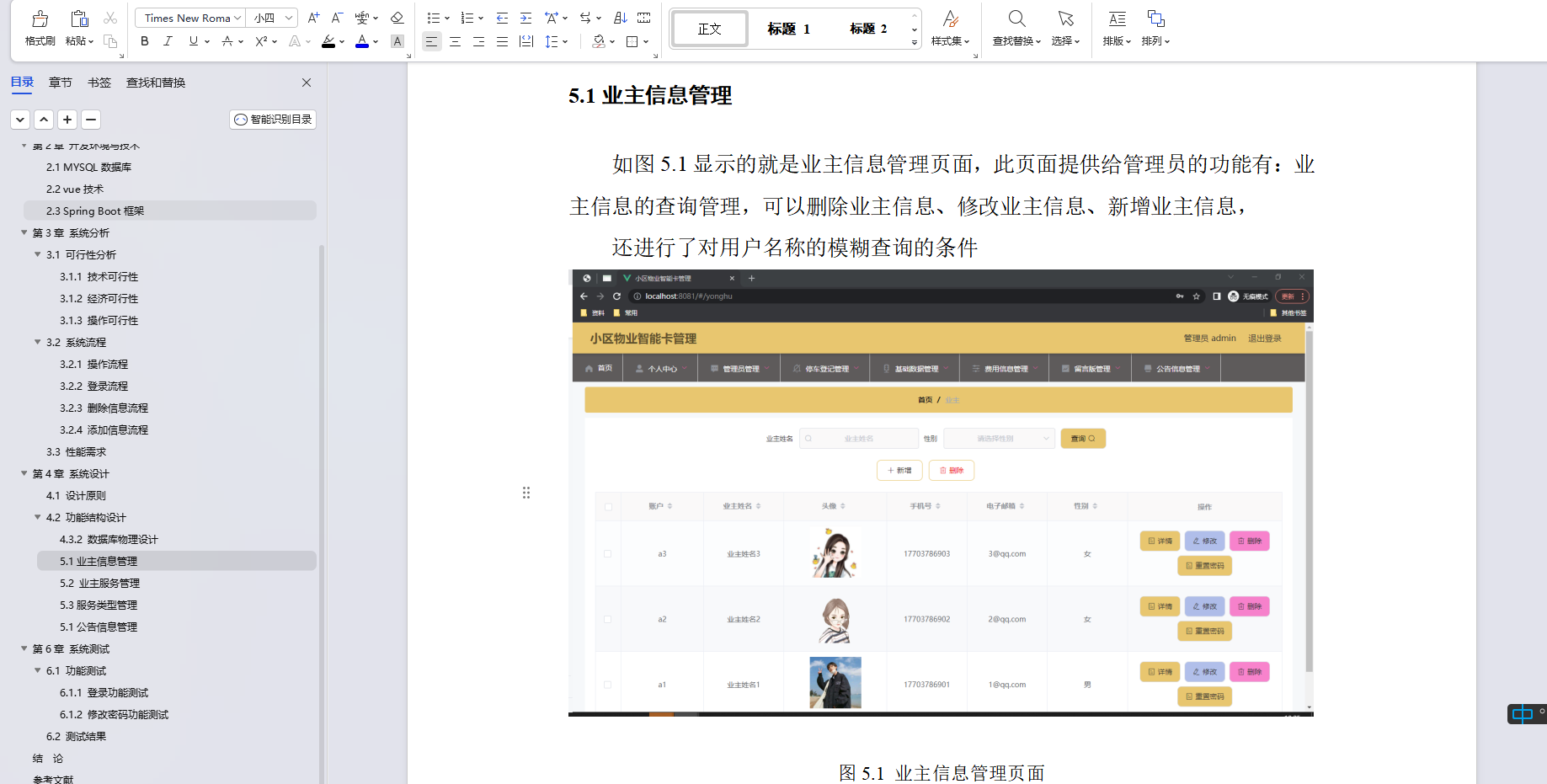
本博客结合2023年发表的综述文章,对近期一些联邦推荐文章进行总结,综述原文:
SUN Z, XU Y, LIU Y, et al. A Survey on Federated Recommendation Systems[J]. 2023.https://doi.org/10.48550/arXiv.2301.00767
引言
最近,已有许多工作将联邦学习应用到推荐系统中来保护用户的隐私。在联邦学习的设置中,服务器不再收集用户的个人数据,而是收集中间参数来训练模型,这极大的保护了用户的隐私。此外,联邦推荐系统可以与其他数据平台合作,以提高推荐性能,同时满足监管和隐私约束。然而,联邦推荐系统面临着隐私、安全、异构性和通信成本等诸多新挑战。虽然已经有工作在这些领域进行了大量研究,但还没有一篇综述文章。在本篇综述中,(1)总结了联邦推荐系统中使用的一些常见隐私机制,并讨论了每种机制的优点和局限性;(2)回顾了几种针对安全的新型攻击和防御策略;(3)总结了解决异构性和通信成本问题的方法;(4)为联邦推荐系统引入了一些实际应用和公共基准数据集;(5)未来提出了一些有前景的研究方向。
一、联邦推荐的一些挑战
挑战 1:用户的隐私问题
隐私保护通常是FedRS的主要目标。在FedRS中,每个参与者通过共享中间参数而不是真实的用户项目交互数据来联合训练全局推荐模型,这对隐私保护推荐系统迈出了重要的一步。然而,好奇的服务器仍然可以从上传的中间参数推断用户评分和用户交互行为。此外,FedRS 在整合辅助信息(例如社会特征)以提高推荐性能时也面临隐私泄露的风险。
挑战 2: FedRS的安全攻击
在联邦推荐场景中,参与者可能是恶意的,他们可以毒害他们的本地训练样本或上传的中间参数来攻击FedRS的安全性。它们可以增加特定产品的利润暴露,或破坏竞争公司的整体推荐性能。为了确保推荐的公平性和性能,FedRS必须具备检测和防御参与者毒害攻击的能力。
挑战 3:FedRS 的异质性
FedRS 还面临多个客户端协作训练期间系统异质性、统计异质性和隐私异质性的问题。当在本地训练推荐模型时,由于存储、计算和通信能力的差异,能力有限的客户端可能会成为掉队者,进而影响训练效率。此外,不同客户端的数据(例如,用户属性、评级和交互行为)通常不独立且同分布(Non-IID),为所有用户训练一致的全局推荐模型无法达到推荐结果的个性化。此外,在实际应用中,用户往往有不同的隐私需求,采用不同的隐私设置。所以简单地使用相同的隐私策略可能会给用户带来不必要的推荐精度和效率损失。
二、联邦推荐系统概述
1. 通信架构
在 FedRS 中,参与者的数据在本地存储,中间参数在服务器和参与者之间进行通信。FedRS 研究中使用了两种主要的通信架构,包括客户端服务器架构和点对点架构。
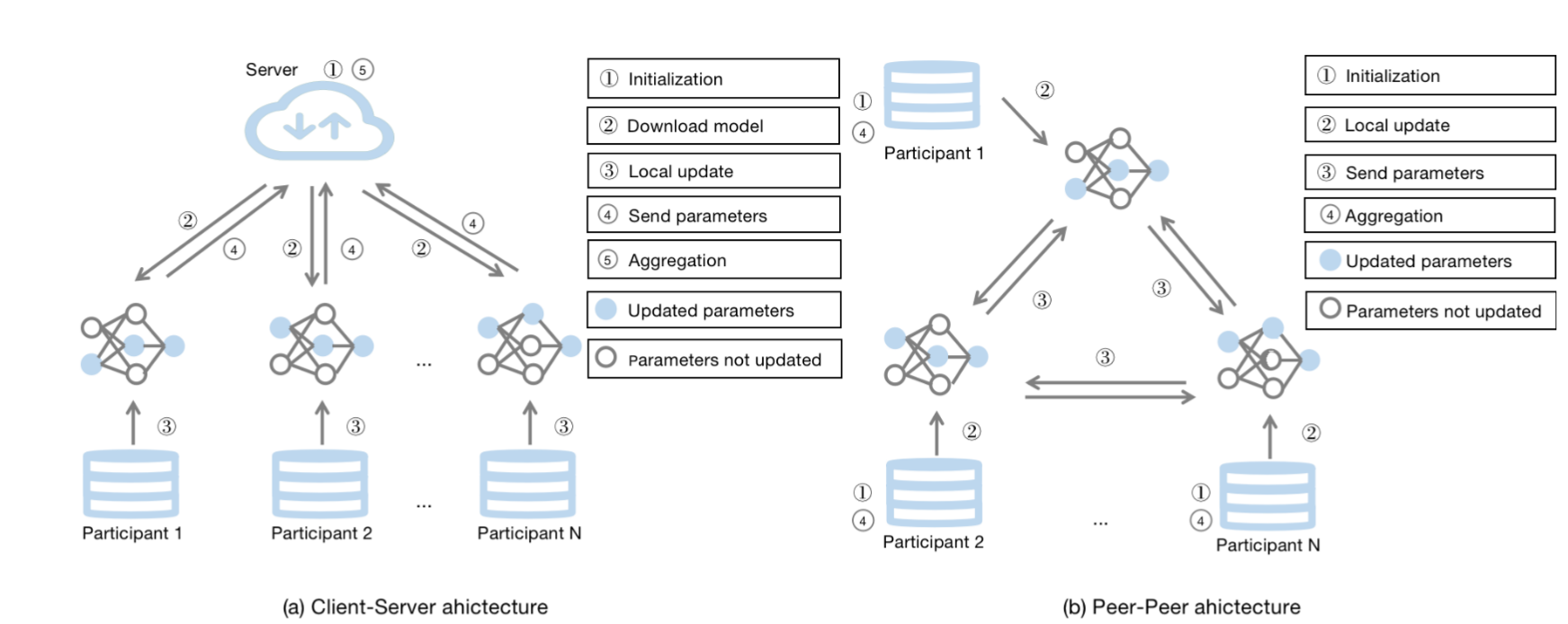
客户端-服务器架构
客户端-服务器架构是 FedRS 中使用的最常见的通信架构,如图 1(a) 所示,它依赖于受信任的中央服务器来执行初始化和模型聚合任务。在每一轮中,服务器将当前的全局推荐模型分发给一些选定的客户端。然后所选客户端使用接收到的模型和自己的数据进行本地训练,并将更新后的中间参数(如模型参数、梯度)发送到服务器进行全局聚合。客户端-服务器架构需要一个中央服务器来聚合客户端上传的中间参数。因此,一旦服务器具有单点故障,整个训练过程将受到严重影响。此外,好奇的服务器可以通过中间参数推断客户的隐私信息,留下潜在的隐私问题。
Peer-Peer 架构
考虑到FedRS中客户端-服务器架构的单点故障问题,Hegedset等人[21]设计了一种不涉及通信过程的中央服务器的点对点通信体系结构,如图1(b)所示。在每一轮通信中,每个参与者将更新后的中间参数广播给对等网络中的一些随机在线邻居,并将接收到的参数聚合到自己的全局模型中。在此架构中,可以避免与中央服务器相关的单点故障和隐私问题。然而,聚合过程发生在每个客户端上,这大大增加了客户端的通信和计算开销。
2. 分类
参与者类型
基于参与者的类型,FedRS可以分为跨设备FedRS和跨平台FedRS。
1)跨设备的参与者:跨设备的参与者指的是联邦学习设置中的客户端为每个移动用户,这种模型的特点是,参数者数量众多,但是每个参与者的数据量很小。同时,考虑到移动设备的计算能力和通信能力有限,跨设备FedRS无法处理非常复杂的训练任务。此外,由于功率和网络状态,移动设备可能会退出训练过程。因此,跨设备 FedRS 的主要挑战是如何在训练过程中提高效率和处理设备的掉队问题。
2)跨平台的参与者:跨平台的参与者一般是指不同企业或者平台的数据,例如,为了提高推荐性能,推荐系统经常整合来自多个平台(如商业平台、社交平台)的数据。然而,由于隐私和监管问题,不同的数据平台往往不能直接相互共享他们的数据。在这种情况下,跨平台 FedRS 可用于协作训练不同数据平台之间的推荐模型,而无需直接交换用户的数据。与跨设备FedRS相比,跨平台FedRS的参与者数量相对较小,每个参与者拥有相对大量的数据。跨平台FedRS的一个重要挑战是如何设计一个公平的激励机制来衡量不同数据平台的贡献和好处。此外,很难找到受信任的服务器来管理跨平台 FedRS 中的训练过程,因此在这种情况下,点对点通信架构的对等可能是一个好的选择。
推荐模型类型
根据FedRS中使用的不同推荐模型,FedRS可分为基于矩阵分解的FedRS、基于深度学习的FedRS和基于元学习的FedRS。
1)基于矩阵分解的联邦推荐模型
在基于矩阵分解模型的FedRS中,用户因子向量在客户端上本地存储和更新,只有项目因子向量[29]或项目因子向量的梯度[23][10][9][30]上传到服务器进行聚合。基于矩阵分解模型的 FedRS 可以简单地有效地捕捉用户品味,以及用户和项目之间的交互和评级信息。然而,它仍然有许多限制,例如稀疏性(要预测的评级数量远小于已知的评级)和冷启动(新用户和新项目缺乏评级)问题。
2)基于深度学习的FedRS
为了学习用户和项目的更复杂的表示并提高推荐性能,深度学习技术已广泛应用于推荐系统。然而,由于隐私法规更加严格,推荐系统很难收集足够的用户数据来构建高性能的深度学习模型。为了在满足隐私法规的同时充分利用用户数据,人们提出了许多有效的基于深度学习的FedRS。考虑到模型结构不同,基于深度学习的FedRS通常采用不同的模型更新和中间参数传输过程。例如,Perifanis等人[31]提出了一种基于NCF[34]的联合神经协同过滤(FedNCF)框架。在 FedNCF 中,客户端本地更新网络权重以及用户和项目配置文件,然后在屏蔽到服务器进行聚合后上传项目配置文件和网络权重。Wu等人[32]提出了一种基于GNN的联合图神经网络(FedGNN)框架。在 FedGNN 中,客户端本地训练 GNN 模型并从其本地子图更新用户/项目嵌入,然后将 GNN 模型的扰动梯度和项目嵌入发送到中央服务器进行聚合。此外,Huang等人[35]提出了一种基于深度结构化语义模型(DSSM[36])的联合多视图推荐框架。在FL-MVDSSM中,每个视图i根据自己的用户数据和局部共享项数据在本地训练用户和项目子模型,然后将用户和项目子模型的扰动梯度发送到服务器进行聚合。
3)基于元学习的FedRS
现有的联邦推荐研究大多建立在这样一个假设之上,即分布在每个客户端上的数据是独立同分布的(IID)。然而,在处理客户端的非iid和高度个性化的数据时,学习统一的联邦推荐模型往往表现不佳。元学习模型可以快速适应新任务,同时保持良好的泛化能力,这使得它特别适合FedRS。在基于元学习模型的FedRS中,服务器聚合客户端上传的中间参数来学习模型参数初始化,客户端在本地训练阶段微调初始模型参数以适应其本地数据。通过这种方式,基于元学习模型的FedRS可以适应客户的本地数据,以提供更个性化的推荐。虽然基于元学习的FedRS的性能通常优于学习统一的全局模型,但私人信息泄漏在模型参数初始化的学习过程中仍然可能发生。
三、联邦推荐系统的隐私保护机制
在FedRS的模型训练过程中,用户数据在本地存储,只有中间参数上传到服务器,可以在保持推荐性能的同时进一步保护用户隐私。然而,一些研究工作表明,中央服务器仍然可以基于中间参数推断一些敏感信息。例如,好奇的服务器可以根据客户端发送的非零梯度来识别用户与之交互的项目。此外,只要在连续两轮中获取用户上传的梯度,服务器也可以推断用户评分。为了进一步保护FedRS的隐私,许多研究将其他隐私保护机制纳入FedRS中,包括伪项、同态加密、秘密共享和差分隐私。本节介绍FedRS中使用的隐私机制的应用,并比较了它们的优点和局限性。
1. 伪项
为了防止服务器根据非零梯度推断用户与之交互的项目集,一些研究利用伪项来保护FedRS中的用户交互行为。伪项的关键思想是客户端不仅上传已与之交互的项目的梯度,而且还上传一些尚未使用的采样项目的梯度。例如,Lin 等人提出了一种名为 FedRec 的显式反馈场景的联邦推荐框架,其中他们设计了一种有效的混合填充策略,为未评级的项目生成虚拟评级。然而,FedRec中的混合填充策略给推荐模型引入了额外的噪声,这不可避免地影响了模型的性能。为了解决这个问题,冯等人设计了一个名为FedRec++的FedRec无损版本。FedRec++将客户端划分为普通客户端和去噪客户端。去噪客户端从普通客户端收集噪声梯度,并将噪声梯度的总和发送到服务器以消除梯度噪声。虽然伪项可以有效地保护FedRS中的用户交互行为,但它并没有修改评级项的梯度。好奇的服务器仍然可以推断用户对用户上传的梯度的评分。
2. 同态加密
为了进一步保护 FedRS 中的用户评分,许多研究试图在将它们上传到服务器之前对中间参数进行加密。同态加密机制允许对加密数据进行数学运算,因此它非常适合于FedRS中的中间参数上传和聚合过程。例如,Chai 等人提出了一种名为 FedMF 的安全联邦矩阵分解框架,其中客户端使用 Paillier 同态加密机制在将它们上传到服务器之前对项目嵌入矩阵的梯度进行加密,服务器在密文上聚合梯度。由于同态加密的特点,FedMF可以达到与传统矩阵分解相同的推荐精度。然而,FedMF会导致严重的计算开销,因为所有的计算操作都是在密文上执行的,大多数系统的时间都花在服务器更新上。此外,FedMF假设所有参与者都是诚实的,不会泄漏到服务器的密钥,这在现实中很难保证。此外,张等人提出了一种用于垂直联邦学习场景的联邦推荐方法(CLFM-VFL),其中参与者有更多的重叠用户,但用户的重叠特征更少。CLFM-VFL使用同态加密来保护每个参与者的用户隐藏向量的梯度,并对用户进行聚类以提高推荐精度和降低矩阵维数。
基于同态加密机制的FedRS可以有效地保护用户评分,同时保持推荐的准确性。此外,它可以在整合来自其他参与者的信息时防止隐私泄露。然而,同态加密在操作过程中带来了巨大的计算成本。
3. 秘密共享
作为FedRS中使用的另一种加密机制,秘密共享机制将中间参数分解为多个片段,并在参与者之间分配片段,以便只有当收集所有片段才能重建中间参数。
基于秘密共享机制的FedRS在保持推荐精度的同时保护用户评分,与基于同态加密的FedRS相比,计算成本较低。但是参与者之间片段的交换过程大大增加了通信成本。
4. 局部差分隐私
考虑到基于加密的机制导致的巨大计算或通信成本,许多研究尝试使用基于扰动的机制来适应工业场景的大规模 FedRS。局部差分隐私(LDP)机制允许统计计算,同时保证每个参与者的隐私,可用于扰动FedRS中的中间参数。例如,Dolui等人提出了一种联邦矩阵分解框架,该框架在将差分隐私发送到服务器进行加权平均之前,对项目嵌入矩阵应用差分隐私。但是,服务器仍然可以仅通过比较项目嵌入矩阵的变化来推断哪个用户评分过项目。为了在模型训练过程中实现更全面的隐私保护,Wu等人结合伪项和LDP机制来保护FedGNN中的用户交互行为和评级。首先,为了保护 FedGNN 中的用户交互行为,客户端随机采样它们未与之交互的 N 个项目,然后使用与真实嵌入梯度相同的高斯分布来生成项目嵌入的虚拟梯度。其次,为了保护 FedGNN 中的用户评分,客户端应用 LDP 模块来根据具有阈值 δ 的 L2 范数裁剪梯度,并通过添加零均值拉普拉斯噪声来扰动梯度。
局部差分隐私机制不会对 FedRS 带来繁重的计算和通信开销,但额外的噪声不可避免地会影响推荐模型的性能。因此,在实际应用场景中,我们必须考虑隐私和推荐准确性之间的权衡。
四、联邦推荐系统的安全性
除了隐私泄露的风险,推荐系统也可能面临攻击者的毒害,它们通过将精心制作的数据注入训练数据集中来提出建议作为他们的愿望。但是这些中毒攻击中的大多数都假设攻击者拥有整个训练数据集的全部先验知识。这样的假设可能对 FedRS 无效,因为 FedRS 中的数据是分布式和本地存储的每个参与者。因此,FedRS 比传统的推荐系统提供了更强的安全保证。然而,最新的研究表明,在有限的先验知识下,攻击者仍然可以对FedRS进行中毒攻击。在本节中,我们总结了一些针对FedRS的新型中毒攻击,并提供了一些防御方法。
1. 投毒攻击
有目标投毒攻击
对fedrs目标攻击的目的是增加或减少特定物品的暴露机会,通常是由经济利益驱动的。例如,Zhang等人利用人气偏差提出了一种针对fedrs的物品推广投毒攻击(PipAttack)。为了提高目标物品的排名分数,PipAttack使用流行度偏差将目标物品与嵌入空间中的流行物品对齐。此外,为了避免破坏推荐准确性和被检测到,PipAttack设计了距离约束,使恶意客户端上传的修改梯度接近正常梯度。
为了进一步降低针对性投毒攻击导致的推荐准确率下降,以及保证攻击效果所需的恶意客户端比例,Rong提出了一种针对fedr的模型投毒攻击(FedRecAttack),利用一小部分公开交互来近似用户特征矩阵,然后利用它来生成中毒梯度。
PipAttack和FedRecAttack都依赖于一些先验知识。例如,PipAttack假设攻击可以访问流行信息,FedRecAttack假设攻击者可以获得公共交互。因此,在缺乏先验知识的情况下,攻击的有效性大大降低,使得这两种攻击在所有fedr中都不具有通用性。为了使攻击者在没有先验知识的情况下对fedr进行有效的投毒攻击,Rong等为恶意客户端设计了随机逼近和用户硬挖掘两种方法来生成投毒梯度。其中,随机逼近法(A-ra)利用高斯分布近似正态用户嵌入向量,硬用户挖掘法(A-hum)利用梯度下降法对A-ra得到的用户嵌入向量进行优化,挖掘硬用户。这样,A-hum仍然可以以极小比例的恶意用户,有效地攻击fedrs。
无目标投毒攻击
针对fedr的非目标攻击的目标是降低推荐模型的整体性能,这通常是由竞争公司进行的。例如,Wu等人提出了一个针对FedRS的非目标中毒攻击,名为FedAttack,该攻击使用全局硬抽样技术[来破坏模型训练过程。更具体地说,恶意客户端从本地用户配置文件中推断用户的兴趣后,选择与用户兴趣最匹配的候选项目作为负样本,选择与用户兴趣最不匹配的候选项目作为正样本。FedAttack只是对训练样本进行修改,恶意客户端也与正常客户端相似,只是利益不同,因此即使在防御下,FedAttack也能有效地破坏FedRS的性能。
2. 防御策略
为了减少投毒攻击对fedr的影响,文献中提出了许多防御方法,可分为鲁棒聚合和异常检测。
鲁棒聚合
鲁棒聚合的目标是在高达50%的参与者是恶意的情况下保证模型的全局收敛,它选择统计上更鲁棒的值而不是上传的中间参数的平均值进行聚合。Median独立选取每一个更新后的模型参数的中值作为聚合的全局模型参数,能更好地代表分布的中心。Trimmed-Mean分别去除了每个更新后的模型参数的最大值和最小值,然后取平均值作为聚合的全局模型参数。Krum选择一个最接近其他模型的局部模型作为全局模型。MultiKrum通过使用Krum选择多个局部模型,然后将它们聚合成一个全局模型。Bulyan是Krum和Trimmed-Mean的结合,通过Krum迭代选择m个局部模型参数向量,然后对这m个参数向量执行TrimmedMean进行聚合。Norm-Bounding将接收到的局部参数剪辑到一个固定的阈值,然后将它们聚合以更新全局模型。
虽然这些鲁棒聚合策略在一定程度上提供了收敛性保证,但它们中的大多数(即Bulyan, Krum, Median和Trimmed-mean)极大地降低了fedr的性能。此外,一些新颖的攻击(例如:, PipAttack, FedAttack)利用设计良好的约束来近似正常用户的模式并规避防御,这进一步增加了防御的难度。
异常检测
异常检测策略的目的是识别恶意客户端上传的有毒模型参数,并在模型全局聚合过程中进行过滤。例如,Jiang等人提出了一种名为联邦先令攻击检测器(FSAD)的异常检测策略,用于检测联邦协同过滤场景中的中毒梯度。FSAD根据客户端上传的梯度提取4个新特征,然后利用这些基于梯度的特征训练一个半监督贝叶斯分类器,对有毒梯度进行识别和过滤。然而,在FedRS中,不同用户的兴趣差异很大,因此他们上传的参数通常差异很大,这增加了异常检测的难度。
五、联邦推荐系统的异质性
与传统的推荐系统相比,FedRS在异质性方面面临更严重的挑战,主要体现在系统异质性、统计异质性和模型异质性上,如下图所示。系统异质性是指客户端设备具有显著不同的存储、计算和通信能力。能力有限的设备极大地影响了训练效率,进一步降低了全局推荐模型的准确性;统计异质性是指不同客户端收集的数据通常不是独立同分布的(非 IID),因此,简单地训练单个全局模型很难推广到所有客户端,从而影响推荐的个性化;隐私异质性意味着不同用户和信息的隐私约束差异很大,因此简单地用相同的隐私预算处理它们会带来不必要的成本。本节介绍一些有效的方法来解决FedRS的异质性问题。
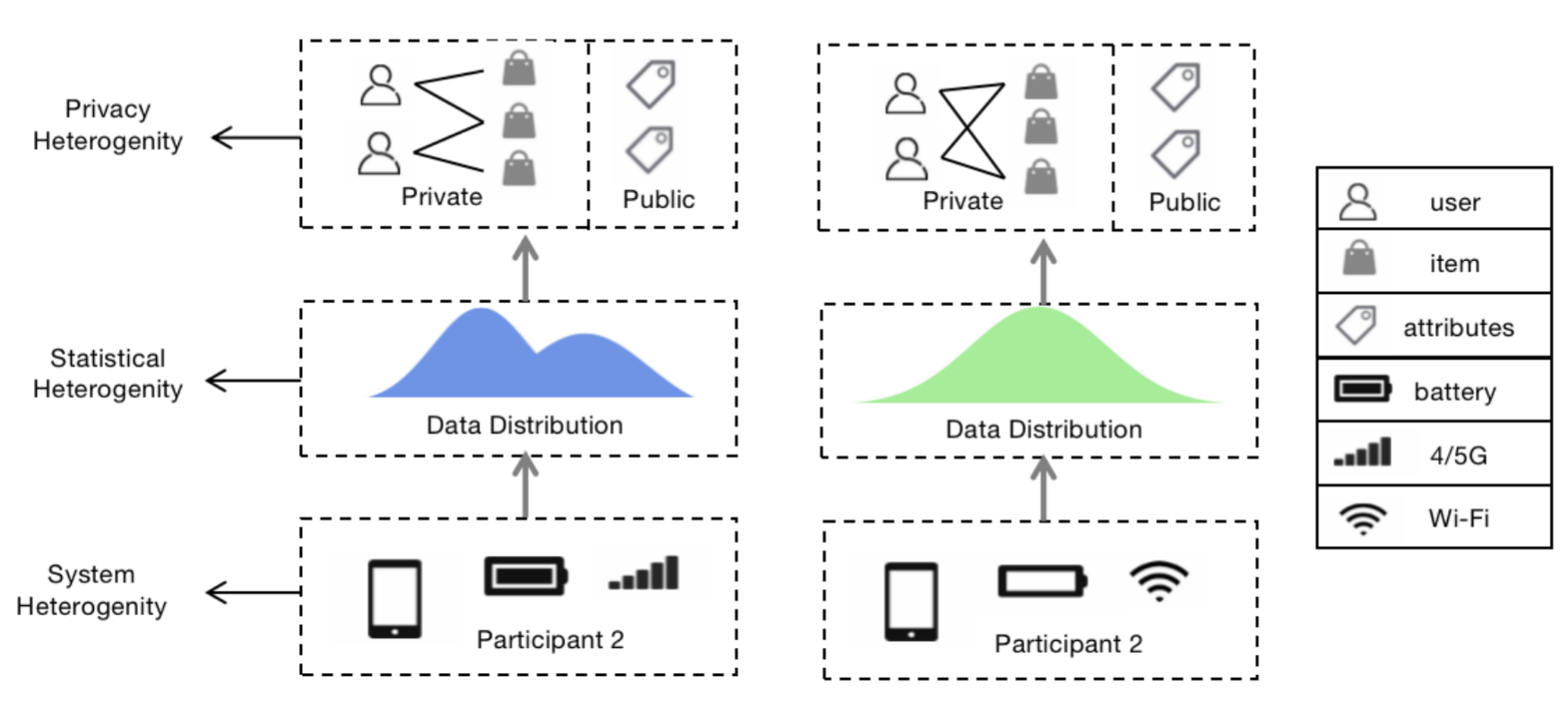
1. 系统异质性
在FedRS中,参与客户端的硬件配置、网络带宽和电池容量差异很大,导致计算能力、通信速度和存储容量不同。在训练过程中,容量有限的客户端可能成为掉队者,甚至由于网络故障、电池低等问题而退出当前的训练。系统异质性显着延迟了 FedRS 的训练过程,进一步降低了全局模型的推荐准确率。为了使训练过程兼容不同的硬件结构,容忍客户端的分散和退出问题,最常见的方法是异步通信和客户端选择。
异步通信
考虑到基于同步通信的联邦学习必须在聚合过程中等待掉队设备,提出了许多异步通信策略来提高训练效率。例如,FedSA提出了一种半异步通信方法,其中服务器根据每轮到达顺序聚合本地模型。FedAsync 使用加权平均策略来聚合基于陈旧性的局部模型,该策略在更新过程中为延迟反馈分配更少的权重。
客户端选择
客户端选择方法根据资源约束选择客户端进行更新,以便服务器可以同时聚合尽可能多的本地更新。例如,在 FedCS中,服务器向每个客户端发送资源请求以获得它们的资源信息,然后根据资源信息估计模型分布、更新和上传过程所需的时间。根据估计的时间,服务器确定哪些客户端可以参与训练过程。
2. 统计异质性
现有的联邦推荐研究大多建立在每个参与者中的数据独立且同分布(IID)的假设之上。然而,每个客户端的数据分布通常差异很大,因此在非IID数据下训练一致的全局模型很难推广到所有客户端,不可避免地忽略了客户端的个性化。为了解决FedRS的统计异质性问题,人们提出了许多有效的策略,主要有基于元学习和聚类的策略。
元学习
元学习技术被称为“学习如何学习”,旨在通过只使用少量样本,快速适应其他任务学习到的全局模型到新任务。快速适应和良好的泛化能力使其特别适合构建个性化的联邦推荐模型。例如,FedMeta使用 Model-Agnostic Meta-Learning (MAML)算法来学习一个可以快速适应客户端的初始化良好的模型,并有效地提高 FedRS 的个性化和收敛性。然而,FedMeta 需要计算二阶梯度,这大大增加了计算成本。此外,数据拆分过程也为样本有限的客户带来了巨大的挑战。基于FedMeta,Wang等人提出了一种新的元学习算法Reptile,该算法将近似的一阶导数应用于元学习更新,大大降低了客户端的计算过载。此外,Reptile 不需要数据拆分过程,这使得它也适用于样本有限的客户端。
聚类
聚类的核心思想是与同一组同质客户端联合训练个性化模型。例如,Jie等人利用历史参数聚类技术实现个性化联邦推荐,服务器聚合局部参数生成全局模型参数,对局部参数进行聚类,生成不同客户端组的聚类参数。然后客户端将聚类参数与全局参数相结合来学习个性化模型。Luoet等人提出了一种名为PerFedRec的个性化联邦推荐框架,该框架构建了一个协作图,并集成了属性信息,通过联邦GNN联合学习用户表示。基于学习到的用户表示,客户端被聚集成不同的组。每个集群学习一个集群级别的推荐模型。最后,每个客户端通过合并全局推荐模型、聚类级推荐模型和微调的局部推荐模型来获得个性化模型。尽管基于聚类的方法可以缓解统计异质性,但聚类和组合过程大大增加了计算成本。
3. 隐私异质性
实际上,不同参与者和信息的隐私限制差异很大,因此对所有参与者和信息使用相同的高级隐私预算不是必须的,而且这样甚至会增加计算或者通信成本,降低客户端的表现。
异构用户隐私
为了适应不同用户的隐私需求,Anelli等人提出了一种名为FedeRank的用户控制联邦推荐框架。FedeRank 引入了概率因子 π ∈ [0, 1] 来控制交互项更新的比例,并通过将它们设置为零来屏蔽剩余的交互项更新。通过这种方式,FedeRank 允许用户自行决定他们想要共享的数据的比例,这解决了用户隐私的异质性。
异构信息隐私
为了适应不同信息组件的隐私需求,HPFL设计了一种差异化的组件聚合策略。为了获得全局公共信息组件,服务器直接加权聚合具有相同属性的本地公共组件。为了获得全局隐私信息组件,用户和项表示在本地保存,服务器只聚合本地草稿,而不需要对齐演示。通过差异化的组件聚合策略,HPFL 可以安全地聚合用户建模场景中具有异构隐私约束的组件。
六、联邦推荐的通信成本
为了实现令人满意的推荐性能,FedRS需要在服务器和客户端之间进行多个通信。然而,现实世界的推荐系统通常是通过具有大模型大小的复杂性深度学习模型来进行的,需要更新和通信数百万个参数,这给资源有限的客户带来了严重的通信过载,并进一步影响了FedRS在大规模工业场景下的应用。本节总结了一些降低FedRS通信成本的优化方法,可分为基于重要性的更新、模型压缩、主动采样和一次性学习。
1. 基于重要性的更新
基于重要性的模型更新选择全局模型的重要组成部分,而不是整个模型进行更新和通信,可以有效减少每轮通信的参数大小。例如,Qin等人提出了一种名为PPRSF的联合框架,该框架使用4层层次结构来降低通信成本,包括召回层、排名层、重新排序层和服务层。在召回层中,服务器通过使用公共用户数据粗略地对大型库存进行排序,并为每个客户端召回相对较少的项目。这样,客户端只需要更新和通信候选项目嵌入,大大降低了服务器和客户端之间的通信成本,以及局部模型训练和推理阶段的计算成本。然而PPRSF 的召回层需要获取一些关于用户的公共信息,这引起了一定的困难和隐私问题。
Yi等人提出了一种名为Efficient-FedRec的高效联邦新闻推荐框架,该框架将新闻推荐模型分解为小型用户模型和大型新闻模型。每个客户端只请求用户模型和参与其本地点击历史的一些新闻表示进行本地训练,这大大减少了通信和计算开销。为了进一步保护特定的用户点击历史与服务器,他们使用安全聚合协议传输一组用户点击历史中涉及的联合新闻表示集。
此外,Khan等人提出了一种多臂老虎机方法(FCF-BTS),用于为所有客户端选择包含较小有效负载的全局模型的一部分。选择过程的奖励由贝叶斯汤普森采样 (BTS) 方法和高斯先验指导。实验表明,FCF-BTS 可以减少高度稀疏数据集的 90% 模型有效负载。此外,选择过程发生在服务器端,从而避免了客户端的额外计算成本。但是 FCF-BTS 在推荐准确度上导致 4% - 8% 的损失。
为了更好地平衡推荐精度和效率,Ai等人提出了一种全mlp网络,该网络使用傅里叶子层代替Transformer编码器中的自关注子层,过滤与用户实际兴趣无关的噪声数据成分,并采用自适应模型修剪技术,丢弃对模型性能没有贡献的噪声模型成分。实验表明,全mlp网络可以显著降低通信和计算成本,加快模型收敛速度。
基于重要性的模型更新策略可以大大减少通信和计算成本,但只选择重要部分进行更新不可避免地会降低推荐性能。
2. 模型压缩
模型压缩是分布式学习中的一项著名技术,它将每轮的通信参数压缩得更加紧凑。例如,Konen等人提出了两种方法(即structured updates和sketched updates))来降低联邦学习设置下的上行通信成本。结构化更新方法使用较少的变量直接从预先指定的参数化结构中学习更新。Sketched updates方法在将完整的本地更新发送到服务器之前,使用有损压缩方式对其进行压缩。这两种策略可以将通信成本降低2个数量级。
为了降低基于深度学习的FedRS中的上行通信成本,JointRec结合了低秩矩阵分解和8位概率量化方法来压缩权重更新。假设客户端n的权值更新矩阵为, a≤b,低秩矩阵分解将
分解为两个矩阵:
,其中k = b/ N,N是一个影响压缩性能的正数。 8位概率量化方法将矩阵值的位置转换为8位值后再发送给服务器。实验表明,在保持推荐性能的前提下,JointRec可以实现12.83倍的大压缩比。模型压缩方法在降低上行链路通信成本方面取得了显著效果。然而,通信成本的降低牺牲了客户端的计算资源,因此在使用模型压缩时需要考虑计算成本和通信成本之间的权衡。
3. 客户端采样
在传统的联邦学习框架中,服务器随机选择客户端参与训练过程,并平均简单地聚合局部模型,需要大量的通信才能达到令人满意的精度。客户端采样利用高效的采样策略来提高训练效率并减少通信轮次。
例如,Muhammad等人提出了一种名为FedFast的有效采样策略,以加快联邦推荐模型的训练效率,同时保持更高的精度。FadFast 由两个有效的组件组成:ActvSAMP 和 ActvAGG。ActvSAMP 使用 K-means 算法根据它们的配置文件对用户进行聚类,并从每个集群中以相等的比例对客户端进行采样。ActvAGG 将本地更新传播到同一集群中的其他客户端。这样,这些相似用户的学习过程大大加快,从而提高了FedRS的整体效率。实验表明,与FedAvg相比,FedFast将通信轮数减少了94%。然而,FedFast 面临着冷启动问题,因为它需要许多用户和项目进行训练。此外,FedFast 需要重新训练模型以支持新用户和项目。
4. 一次性学习
一次性联邦学习机制的目标是减少 FedRS的通信轮次,这将通信限制为单轮以聚合局部模型的知识。例如,Eren 等人实现了一个名为 FedSPLIT 的跨平台 FedRS 的一次性联邦学习框架。FedSPLIT 通过知识蒸馏聚合模型 ,它可以在一个小的初始通信后在服务器和客户端之间仅生成一对通信轮次的客户端特定推荐结果。实验表明,与多轮通信场景相比,FedSPLIT 实现了类似的均方根误差 (RMSE),但它不适用于参与者是个人用户的场景。
六、联邦推荐的应用和一些插常用数据集
本节介绍 FedRS 的典型应用和公共基准数据集。
1. 应用
在线服务
目前,在线服务参与了我们生活的各个领域,例如新闻、电影和音乐。服务提供商集中收集和存储大量用户的私人信息,面临隐私泄露的严重风险。用户数据可能会被服务提供商出售给第三方,或者被外部黑客窃取。FedRS可以帮助用户在保持个人隐私的同时享受个性化推荐服务,使服务提供商更加可信,保证推荐服务符合法规。例如,Tan等人设计了一个联邦推荐系统,该系统实现了各种流行的推荐算法来支持大量的在线推荐服务,并将其部署到真实的内容推荐应用程序中。
医疗保健
医疗保健推荐使患者在获得令人满意的推荐时能够享受移动应用程序的医疗服务,而不是面对面的医院。医疗数据非常私密和敏感,这意味着很难融合来自不同医院或其他组织的用户信息来提高推荐质量。在这种情况下,FedRS 可以分解数据孤岛并利用这些数据而不影响患者的隐私。例如,Song等人开发了一种基于联邦AI技术使能器(FATE)的电信联合医疗推荐平台,通过补充移动网络运营商的公共用户数据(如人口统计信息、用户行为和地理信息)来帮助医疗保健提供者提高推荐性能。此外,该平台设计了一个联邦梯度提升决策树(FGDBT)模型,提高了 9.71% 的准确率和 4% 的 F1 分数用于医疗保健推荐。该平台已部署在组织和应用于在线操作上。
广告
广告是FedRS的另一个重要应用。显示广告的平台通常面临用户数据不足和广告点击率低的问题。FedRS 能够以隐私保护的方式利用不同平台上的用户数据,可以更好地推断用户兴趣并更准确地推送广告。例如,Wu等人提出了一种名为FedCTR的本地广告CTR预测方法,该方法可以集成多平台用户行为(如广告点击行为、搜索行为和浏览行为),用于用户兴趣建模,而不需要集中存储。
电子商务
目前,推荐系统在电子商务平台(例如阿里巴巴、亚马逊)中发挥着重要作用。为了为用户提供更精确的推荐服务,此类系统试图整合更多的辅助信息(例如,用户购买能力、社交信息)。然而,这些数据通常分布在不同的平台上,由于法规和隐私问题,难以直接访问。FedRS可以在满足法规和隐私的同时有效地解决这个问题
2. 常用公开数据集
MovieLens
MovieLens评级数据集由GroupLens发布,GroupLens由用户、电影、评级和时间戳信息组成。MovieLens-100K 包含来自 943 个用户 1682 部电影的 100,000 个评分,MovieLens-1M 包含来自 3,952 部电影 6,040 个用户的 1,000,209 个评分。
FilmTrust
FilmTrust 是从 FilmTrust 网站爬取的电影评分数据集。该数据集包含来自 1,071 个电影的 1,508 个用户的 35,497 个评级。Foursquare[92]。Foursquare 数据集是一个著名的基准数据集,用于评估 Foursquare 收集的 POI 推荐模型。该数据集包含 114,324 个用户在 3,820,891 个 POI 上的 22,809,624 个全球规模的签到,具有 363,704 个社会关系。
Epinions
Epinions 数据集是从消费者评论网站 Epinions.com 构建的在线社交网络,它由用户评分和信任社交网络信息组成。该数据集包含来自 116,260 个用户的 188,478 个评分,用于 41,269 个项目。
Mind
Mind 是一个大规模数据集,用于从 Microsoft News 网站的匿名行为日志中收集新闻推荐,其中包含大约 160,000 篇英文新闻文章和 100 万个用户生成的印象日志。
LastFM
LastFM 数据集是从 Last.fm 在线音乐系统收集的,该系统由标记、音乐艺术家倾听和社会关系信息组成。该数据集包含 1,892 个用户的 17,632 个音乐艺术家的 92,834 个听力计数。
Book-Crossing
Book-Crossing 数据集是来自 Book-Crossing 社区的 4 周抓取数据集。它包含 271,379 本书的 1,149,780 个评级(显式/隐式),其中包含 278,858 个带有人口统计信息的匿名用户。
七、FUTURE DIRECTIONS
本节介绍并讨论了未来许多前瞻性研究方向。尽管上述部分已经涵盖了一些方向,但我们相信它们是 FedRS 所必需的,需要进一步研究。
1. 去中心化FedRS
目前大多数 FedRS 基于客户端-服务器通信架构,该架构面临中央服务器 引起的单点故障和隐私问题。虽然许多工作都致力于分散的联邦学习,但很少有人研究分散的FedRS。一个可行的解决方案是用点对点通信架构替换客户端-服务器通信架构,以实现完全分散的联邦推荐。例如,Heggeds等人提出了一种基于流言学习的完全去中心化矩阵分解框架,其中每个参与者将他们的全局推荐模型的副本发送给对等网络中的随机在线邻居。此外,群体学习是一个去中心化的机器学习框架,它结合了边缘计算、基于区块链的对等网络和协调,可以在不需要中央服务器的情况下保持机密性。因此,实现去中心化推荐系统也是一种很有前途的方法。
2. FedRS中的激励机制
FedRS 与多个参与者合作训练全局推荐模型,全局模型的推荐性能高度依赖于参与者提供的数据量和质量。因此,设计一种适当的激励机制来激励参与者贡献自己的数据并参与协作训练具有重要意义,特别是在跨组织联邦推荐场景中。激励机制必须能够公平有效地衡量客户对全局模型的贡献。
3. FedRS的体系结构设计
工业场景中的推荐系统通常由召回层和排名层组成,该层在服务器端生成推荐结果。考虑到用户的隐私,FedRS必须采用不同的设计。一个可行的解决方案是本地召回和排名,其中服务器将整套候选项目发送给客户端,客户端在本地生成推荐结果。然而,这种设计给客户带来了巨大的沟通、计算和内存成本,因为在现实世界的推荐系统中通常有数百万个项目。另一种有效的方法是在服务器端放置召回层和客户端的排名层,其中客户端向服务器发送加密或噪声用户嵌入以召回前 N 个候选项目,然后客户端通过排名层基于这些候选项目生成个性化推荐结果。然而,与这种方法相关的隐私泄露风险,因为召回的项目已知到服务器。
4. FedRS 中的冷启动问题
冷启动问题意味着推荐系统不能为历史交互很少的新用户生成令人满意的推荐结果。在联邦设置中,用户数据在本地存储,因此很难集成其他辅助信息(例如社会关系)来缓解冷启动问题。因此,在保证用户隐私的同时,解决冷启动问题是一个具有挑战性和前瞻性的研究方向。
5.FedRS的安全性
在现实世界中,FedRS 中的参与者可能是不可信的。因此,参与者可能会上传有毒的中间参数来影响推荐结果或破坏推荐性能。尽管已经提出了一些稳健的聚合策略和检测方法来防御联邦学习设置中的中毒攻击,但它们中的大多数都在FedRS中效果不佳。一方面,Krum、Medium 和 Trimmed-mean 等一些策略在一定程度上降低了推荐性能。另一方面,一些新的攻击使用精心设计的约束来模拟正常用户的模式,极大地增加了检测和防御的难度。目前,在保持推荐准确性的同时,对这些中毒攻击仍然没有有效的防御方法。





![[Linux]缓冲区](https://img-blog.csdnimg.cn/direct/53526bc937e14e79b577577612623067.png)