文章目录
Spark运行架构与MapReduce区别
一、Spark运行架构
二、Spark与MapReduce区别
Spark运行架构与MapReduce区别
一、Spark运行架构
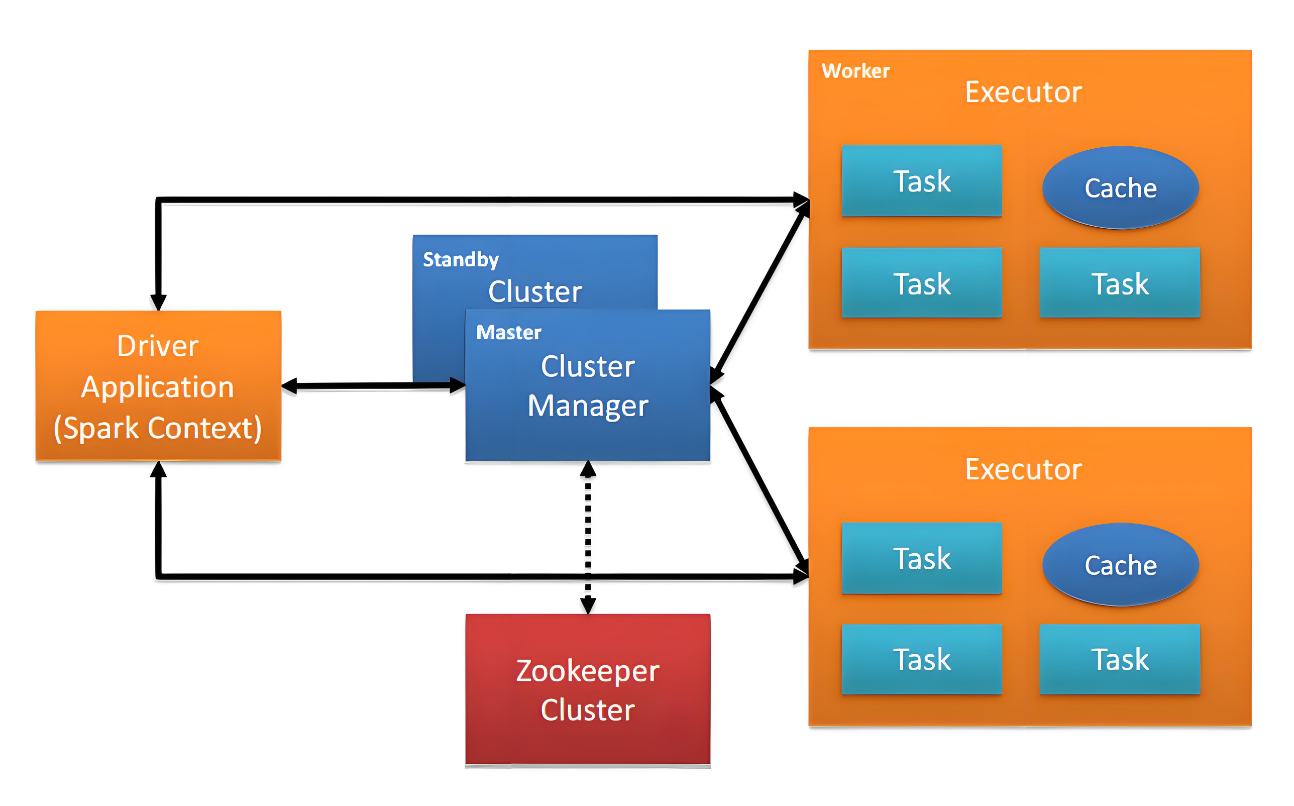
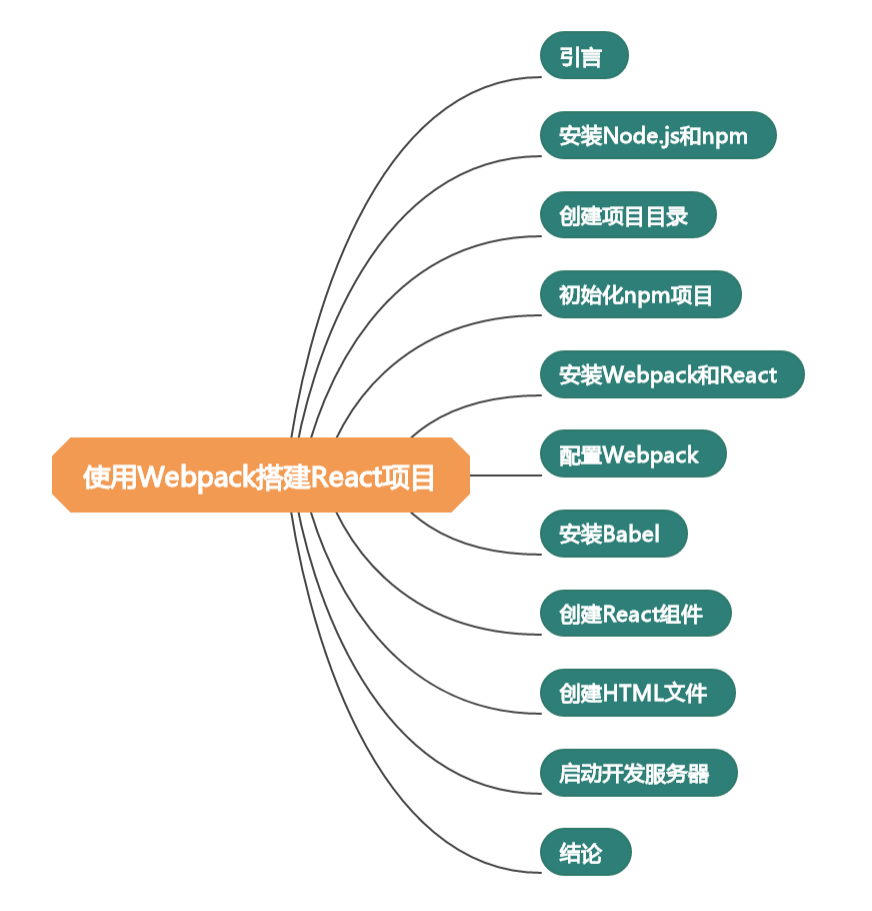
- Master:Spark集群中资源管理主节点,负责管理Worker节点。
- Worker:Spark集群中资源管理的从节点,负责任务的运行。
- Application:Spark用户运行程序,包含Driver端和在各个Worker运行的Executor端。
- Driver:用来连接Worker的程序,Driver可以将Task发送到Worker节点处理这些数据。每个Spark Application都有独立的Driver,Driver负责任务(Tasks)的分发和结果回收。如果task的计算结果非常大就不要回收了,可能会造成oom。
- Executor:Worker节点上运行的进程,负责执行Task,将数据存储在内存或者磁盘中,并将结果返回给Driver。每个Application都有各自独立的一批Executors。
- Task:被发送到某个Executor上的工作单元。
二、Spark与MapReduce区别
Apache Spark 和 Hadoop MapReduce 都是用于大规模数据处理的分布式计算框架,但它们在架构设计、数据处理方式和应用场景等方面存在显著差异。以下是两者的主要区别:
1) 数据处理方式
MapReduce:采用基于磁盘的处理方式,每个任务的中间结果需要写入磁盘,然后再读取进行下一步处理。这种方式增加了磁盘 I/O 操作,导致处理速度较慢。
Spark:利用内存进行数据处理,将中间结果存储在内存中,减少了磁盘读写操作,从而显著提高了处理速度。特别是在需要多次迭代计算的场景下,Spark 的性能优势更加明显。
2) 编程模型
MapReduce:提供了相对低级的编程接口,主要包含 Map 和 Reduce 两个操作,开发者需要编写较多的代码来实现复杂的数据处理逻辑。
Spark:提供了更高级的编程接口,如 RDD(弹性分布式数据集)和 DataFrame,支持丰富的操作算子,使得开发者可以以更简洁的方式编写复杂的处理逻辑。此外,Spark支持SQL处理批/流数据。
3) 任务调度
MapReduce:采用多进程模型,每个Task任务作为一个独立的JVM进程运行。
Spark:采用多线程模型,在同一个进程中管理多个Task任务,资源调度更为高效。
4) 资源申请
MapReduce:采用细粒度资源调度,每个 MapReduce Job 运行前申请资源,Job运行完释放资源。如果一个Application中有多个 MapReduce Job,每个Job独立申请和释放资源。
Spark:采用粗粒度资源调度。Application运行前,为所有的Spark Job申请资源,所有Job执行完成后,统一释放资源。
5) 数据处理能力
MapReduce:主要用于批处理任务,不适合实时数据处理。
Spark:适用于批量/实时数据处理。通过 SparkStreaming 和 StructuredStreaming 模块,支持实时数据流处理。
6) 容错机制
MapReduce:通过将中间结果写入磁盘,实现任务失败后的重试和恢复。
Spark:采用 RDD 的血统(lineage)机制,记录数据集的生成过程。当节点发生故障时,Spark 可以根据血统信息重新计算丢失的数据分区,实现高效的容错。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨

![[创业之路-352]:从创业和公司经营的角度看:分析美国的三大财务报表](https://i-blog.csdnimg.cn/direct/02bacb6412074880b012819d585daf3a.png)

![[论文阅读]PMC-LLaMA: Towards Building Open-source Language Models for Medicine](https://i-blog.csdnimg.cn/direct/6e8a84040dac47cc9b3071876c17ca21.png)