time是python自带的模块,用于处理时间问题,提供了一系列的操作时间的函数。
以下说明针对于 python2.7,其他版本可能有所差异。
模块提供了两个种表示时间的格式:
1.时间戳,是以秒表示从“新纪元”到现在的时间,称为 UTC 或者 GMT。这个“新纪元”指的就是1970年1月1日。所以时间戳指的就是从“新纪元”到某一个时间一共过去了多少秒,可能是一个整数,也可能是一个浮点数。
2.一个包括 9 个元素的元祖,这 9 个元素分别为:
year:4位数,表示年,例如:2016
month:表示月份,范围是 1-12
day:表示天,范围是 1-31
hours:小时,范围是 0-23
minute:分钟,范围是 0-59
seconds:秒,范围是 0-59
weekday:星期,范围是 0-6,星期一是0,以此类推
Julian day:是一年中的第几天,范围是 1-366
DST:一个标志,决定是否使用夏令时,为 0 时表示不使用,为 1 时表示使用,为 -1 时,mktime() 方法会根据 date 和 time 来推测。一般情况下用不着。
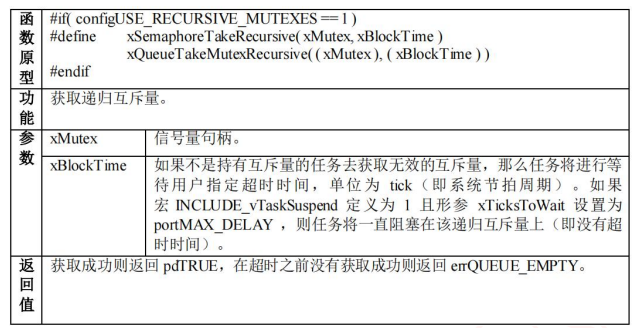
FUNCTIONS
1. asctime([tuple]) -> string
将元祖格式的时间转换成字符串格式。
例如: time.asctime((2016,5,11,12,30,50,5,163,0))
![]()
如果 tuple 没有给,将调用 localtime() 方法,获取现在的时间。
2. clock() -> floating point number
这个有点特殊,会因系统的不同而不同,在 win 平台中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用时是第一次调用以后到这次调用时间。(实际上是以WIN32上QueryPerformanceCounter()为基础,它比毫秒表示更为精确)
代码示例:
import time
if __name__ == '__main__':
time.sleep(1)
print "clock1:%s" % time.clock()
time.sleep(1)
print "clock2:%s" % time.clock()
time.sleep(1)
print "clock3:%s" % time.clock()输出:
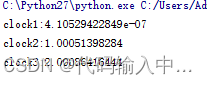
所谓的进程运行的时间,我觉得更像运行第一次调用的这段代码所需的时间,因为不管在第一次调用前用 sleep 停顿又或是进行一其他操作,其输出变化也不大。
import time
if __name__ == '__main__':
b = []
for x in range(1000):
b.append(x)
time.sleep(1)
print "clock1:%s" % time.clock()
time.sleep(1)
print "clock2:%s" % time.clock()
time.sleep(1)
print "clock3:%s" % time.clock()
我也不知道是不是我理解错误还是其他,现在先这样理解着,有问题我以后再改正。
而在 Unix 系统中(虽然 win 也是由 unix 发展而来的),它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。
同样的代码,在CentOS6.7中运行:
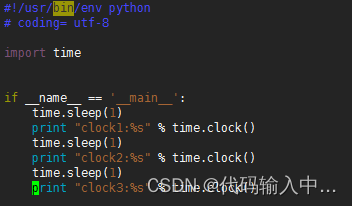
其输出为:
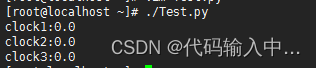
下面是一段实验代码:
import time,urllib
if __name__ == '__main__':
print 'start at:',time.ctime()
try:
ur_open = urllib.urlopen('http://www.facebook.com')
except:
print 'error',time.ctime()
time.sleep(1)
print "clock1:%s" % time.clock()
try:
ur_open = urllib.urlopen('http://www.facebook.com')
except:
print 'error',time.ctime()
time.sleep(1)
print "clock2:%s" % time.clock()
try:
ur_open = urllib.urlopen('http://www.facebook.com')
except:
print 'error',time.ctime()
time.sleep(1)
print "clock3:%s" % time.clock()我试图多次打开一个“不存在”的网站,看看所谓的“进程时间”是什么:
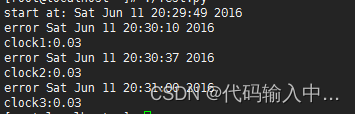
可以看到我时间花费了1分多种,但是进程时间到最后却只有 0.03 秒,参照这篇文章(戳这里),我觉得应该是进程占用 cpu 的时间,因为打开远程网页属于远程 I/O 操作,并不需要大量的 cpu 计算,所以进程时间就很短了。当然这是我的推测,暂时没有找到相应的文章说明,就先这样理解着吧,以后有错再改。
3. ctime(seconds) -> string
将一个时间戳(默认为当前时间)转换成一个时间字符串。相当于 asctime(localtime(seconds)) 。
![]()
4. gmtime([seconds]) -> (tm_year, tm_mon, tm_mday, tm_hour, tm_min, tm_sec, tm_wday, tm_yday, tm_isdst)
将一个时间戳格式的转换为UTC时区(0时区,中国为 UTC+8)的元祖格式。如果没有给参数,则默认为本地时间。

然而我实际的时间是14点,14 = 6 + 8。所以要注意下时区。
5. localtime([seconds]) -> (tm_year,tm_mon,tm_mday,tm_hour,tm_min, tm_sec,tm_wday,tm_yday,tm_isdst)
将一个时间戳转换为当前时区的元祖格式。如果没有给参数,则默认为本地时间。

6. mktime(tuple) -> floating point number
将一个元祖格式的时间转换为时间戳格式。
![]()
7. sleep(seconds)
线程将推迟指定的时间后运行,单位为秒。其精度为亚秒级。
关于精度级别:
分钟级:以分钟为单位,即速度按分钟计算,7200转/分
秒级:以秒为单位,即速度按秒计算,1GHz/秒
亚秒级:没有达到秒的速度,即1GHz/1.2秒
8. time() -> floating point number
返回当前时间的时间戳。
如果系统的时钟支持,可能会出现分数的形式。
9. strftime(format[, tuple]) -> string
把一个代表时间的元组转换为指定格式的字符串,如果没有传入 tuple ,将调用 localtime() 。如果元组中任何一个元素越界(不在范围内),将抛出 ValueError 错误。
关于format的表格:
| 格式 | 含义 | 备注 |
| %a | 本地(locale)简化星期名称 | |
| %A | 本地完整星期名称 | |
| %b | 本地简化月份名称 | |
| %B | 本地完整月份名称 | |
| %c | 本地相应的日期和时间表示 | |
| %d | 一个月中的第几天(01 - 31) | |
| %H | 一天中的第几个小时(24小时制,00 - 23) | |
| %I | 第几个小时(12小时制,01 - 12) | |
| %j | 一年中的第几天(001 - 366) | |
| %m | 月份(01 - 12) | |
| %M | 分钟数(00 - 59) | |
| %p | 本地am或者pm的相应符 | 1 |
| %S | 秒(01 - 61) | 2 |
| %U | 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 | 3 |
| %w | 一个星期中的第几天(0 - 6,0是星期天) | 3 |
| %W | 和%U基本相同,不同的是%W以星期一为一个星期的开始。 | |
| %x | 本地相应日期 | |
| %X | 本地相应时间 | |
| %y | 去掉世纪的年份(00 - 99) | |
| %Y | 完整的年份 | |
| %Z | 时区的名字(如果不存在为空字符) | |
| %% | ‘%’字符 |
备注:
1.“%p”只有与“%I”配合使用才有效果。
2.文档中强调确实是0 - 61,而不是59,闰年秒占两秒。
3.当使用strptime()函数时,只有当在这年中的周数和天数被确定的时候%U和%W才会被计算。
例子:
![]()
10. strptime(string, format) -> struct_time
将字符串格式的时间转换成元祖格式的。是上面方法的逆向。
![]()
总结:





![推荐系统遇上深度学习(一四二)-[微软复旦]CTR预估中的对比学习框架CL4CTR](https://img-blog.csdnimg.cn/img_convert/c52bc3c50d548c29cbff856d01ed0545.jpeg)