目录
一、实验目的
二、实验说明
三、实验过程
3.1 创建快排算法源码
3.2 makefile的创建与编译
3.3 主机文件配置与运行监测
四、实验结果与分析
4.1 结果一及分析
4.2 结果二及分析
五、实验思考与总结
5.1 实验思考
5.2 实验总结
END~
一、实验目的
1.1 掌握多台主机快排算法的编写。
1.2 实现多台主机快排算法的编译运行。
二、实验说明
华为鲲鹏云主机、openEuler 20.03 操作系统;
设置的四台主机名称及ip地址如下:
122.9.37.146 zzh-hw-0001
122.9.43.213 zzh-hw-0002
116.63.11.160 zzh-hw-0003
116.63.9.62 zzh-hw-0004
三、实验过程
3.1 创建快排算法源码
以下步骤均在四台主机上以 zhangsan 用户执行。
首先输入如下命令创建 quicksort 目录存放该程序的所有文件, 并进入 quicksort 目录(四台主机都执行)
mkdir /home/zhangsan/quicksort
cd /home/zhangsan/quicksort
然后输入vim quick_sort.cpp,创建快排算法源码 quick_sort.cpp(四台主机都执行),代码输入成功后输入:wq保存文件。关键代码如下:
注:此部分代码在原教程的基础上添加了串行快排算法,并同样计算出了耗时,便于与并行快排算法的性能进行比较,体现并行化的优势。
// Serial Quick Sort
gettimeofday(&start, NULL);
serialQuickSort(array, 0, n - 1);
gettimeofday(&stop, NULL);
double serialTime = (stop.tv_sec - start.tv_sec) * 1000 +
(stop.tv_usec - start.tv_usec) / 1000;
cout << "串行快速排序数组长度为 " << n << " 时所花时间:" << serialTime << " ms" << endl;
// Parallel Quick Sort
for (int i = 0; i < n; i++) array[i] = rand_r(&seed); // Reset array
gettimeofday(&start, NULL);
#pragma omp parallel
{
#pragma omp single nowait
{
parallelQuickSort(array, 0, n - 1);
}
}
gettimeofday(&stop, NULL);
double parallelTime = (stop.tv_sec - start.tv_sec) * 1000 +
(stop.tv_usec - start.tv_usec) / 1000;
cout << "并行快速排序数组长度为 " << n << " 时所花时间:" << parallelTime << " ms" << endl;3.2 makefile的创建与编译
首先输入vim Makefile,进行编辑,输入如下内容,需注意缩进:
CC = g++
CCFLAGS = -I . -O2 -fopenmp
LDFLAGS = # -lopenblas
all: quicksort
quicksort: quick_sort.cpp
${CC} ${CCFLAGS} quick_sort.cpp -o quicksort ${LDFLAGS}
clean:
rm quicksort保存后输入make进行编译,最后可得到一个可执行文件quicksort,如下绿色英文所示:

3.3 主机文件配置与运行监测
首先输入vim /home/zhangsan/quicksort/hostfile开始配置主机文件,具体内容如下

然后输入vim run.sh编写脚本文件,内容如下
app=${1}
if [ ${app} = "quicksort" ]; then
./quicksort ${2} ${3}
fi此处较原教程做出了如下改动,将数组长度设为可变,作为命令行参数输入,而原教程中数组长度固定为8000000。做出此改动,便于观察数组长度与程序耗时之间的联系。
具体的调整代码如下:
srand(time(NULL));
if (argc != 3) {
cout << "Usage: " << argv[0] << " thread-num array-len\n";
exit(-1); }
int t = atoi(argv[1]);
int n = atoi(argv[2]);
int *array = new int[n];除此之外,还添加了串行快速排序的代码,便于观察并行相对串行的优势。
四、实验结果与分析
4.1 结果一及分析
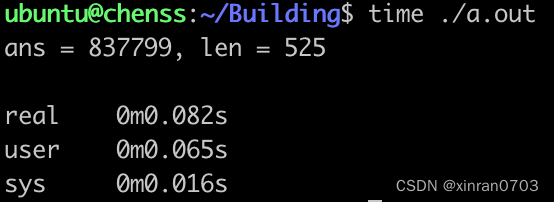
首先采用教程默认的数组长度-8000000进行测试,结果如下
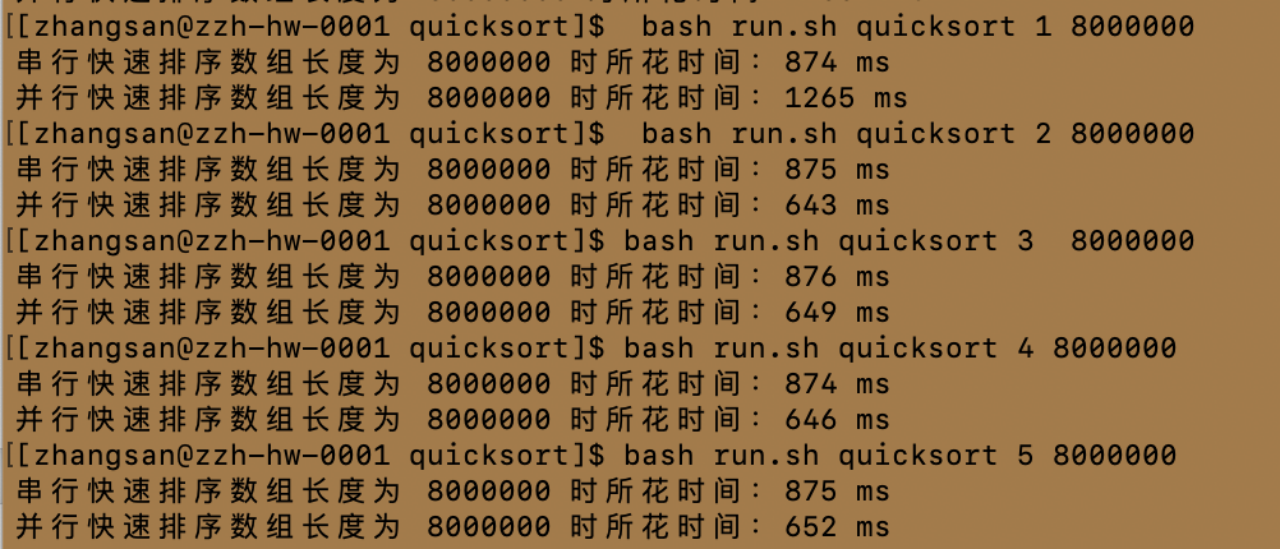

整理数据如下:
| 处理机数量 | 数组长度 | 串行排序耗时 | 并行排序耗时 |
| 1 | 8000000 | 874 | 1265 |
| 2 | 8000000 | 875 | 643 |
| 3 | 8000000 | 876 | 649 |
| 4 | 8000000 | 874 | 646 |
| 5 | 8000000 | 875 | 652 |
| 6 | 8000000 | 874 | 654 |
| 7 | 8000000 | 874 | 663 |
| 8 | 8000000 | 875 | 674 |
将上述结果进行可视化,如下:

从实验结果中观察到如下现象
①对于串行快速排序,时间基本稳定在 874-876 毫秒之间。
②对于并行快速排序,随着线程数的增加,时间逐渐减少,但在 43线程及以上时基本保持稳定在 640-670 毫秒之间。
可认为此情况下的最佳进程数为2
对实验结果做出以下分析
①串行快速排序的性能稳定: 无论数组长度如何,串行快速排序的性能基本保持稳定。这是因为串行排序没有涉及到线程间的同步和通信,所以性能受到硬件资源限制的影响较小。
②并行快速排序的性能随线程数增加而提升: 随着线程数的增加,并行快速排序的性能逐渐提升。这是因为并行排序可以充分利用多核处理器的优势,在多个线程同时工作时可以更快地完成排序任务。
③并行快速排序性能在一定范围内趋于稳定: 当线程数达到一定数量后,进一步增加线程数并不会显著提升性能。这是因为在一定程度上,增加线程数可能会增加线程间的竞争同步开销、通信开销,导致性能提升不再明显。
4.2 结果二及分析
此部分尝试改变数组长度,研究数组长度对实验结果的影响
①增加数组长度

与之前情况类似,在处理机数量从1到2的过程,性能提升是最多的。
②缩小数组长度

将上述实验数据进行可视化,如下所示:

可以看到数组长度为99999时,依旧是处理机数量从1到2时性能提升最大,之后达到阈值。 处理机数量为8时变慢1ms,考虑开销增加的原因。
五、实验思考与总结
5.1 实验思考
①链接过程进行了什么操作?静态链接器和动态链接器的区别是什么?
链接过程是编译后的一个关键步骤,负责将程序的各个组成部分,包括源代码编译产生的目标文件和所需的库文件,组合形成一个单一的可执行文件。
此过程中,链接器执行多项任务:首先,进行符号解析以识别和匹配每个目标文件中定义的和引用的变量与函数;其次,进行地址和空间分配,为代码和数据设定内存地址并规划它们在可执行文件中的布局;接着,合并所有目标文件中的代码和数据,确保它们在内存中顺序存放;然后,处理库链接,将程序引用的库代码整合到可执行文件中;紧接着,执行重定位,调整代码和数据地址以保证程序运行时正确性;最后,生成可执行文件,使其能够直接在操作系统上运行。
静态链接器在程序编译时将所有必需的库和代码整合到最终的可执行文件中,导致生成的文件体积较大,但启动速度快,适用于独立发行的软件,因为它们不依赖外部库。
相比之下,动态链接器在程序运行时才加载和解析库,使得可执行文件更小,但可能增加启动时的解析和加载时间。动态链接允许多个程序共享内存中的库代码,节省空间,并且便于库的更新,无需重新编译依赖它的程序。这两种链接方式各有优势,选择哪一种取决于程序的特定需求和运行环境。
②简述快排算法的并行化原理
算法并行化的原理是将任务分解成独立子任务,分配到多个处理器上同时执行,以减少总体计算时间。关键在于确保子任务的独立性,有效管理数据划分、通信和同步,以及实现负载均衡,从而提升计算效率。
5.2 实验总结
在华为鲲鹏平台上进行的快速排序算法实验中,我们深入研究了快速排序算法在串行与并行环境下的性能表现。串行快速排序显示出良好的稳定性,无论数组长度如何变化,执行时间均稳定在874-876毫秒之间,说明其性能受硬件资源限制较小,且不受线程间同步和通信的影响。并行快速排序则随着线程数的增加表现出显著的性能提升,尤其是在从单线程过渡到双线程时最为明显,之后当线程数增至4线程以上时,执行时间稳定在640-670毫秒之间,表明在本实验中最佳线程数为2,此时多核处理器的优势得到了充分发挥。然而,当线程数超过某个阈值后,性能提升不再显著,因为额外的同步和通信开销抵消了并行化的优势。此外,数组长度的改变也对性能有显著影响,在数组长度较大时,从单线程到双线程的性能提升最为显著,而在数组长度较小时,多线程环境下的性能提升幅度有所降低。
通过在华为鲲鹏平台上编译运行快速排序算法程序,我掌握快速排序算法的编写和编译运行技能。通过这些实验,我深入理解了快速排序算法在串行与并行环境下的性能特点,以及线程数和数据规模对算法效率的影响。这些知识对于优化算法性能和设计高效计算应用具有重要意义。
END~


生活不是函数,问题和答案不是一一对应的关系!