Apache Hudi 已成为管理现代数据湖的领先开放表格式之一,直接在现代数据湖中提供核心仓库和数据库功能。这在很大程度上要归功于 Hudi 提供了表、事务、更新/删除、高级索引、流式摄取服务、数据聚类/压缩优化和并发控制等高级功能。
我们已经探讨了 MinIO 和 Hudi 如何协同构建现代数据湖。这篇博文旨在建立在这些知识的基础上,并提供利用 Hive 元存储服务 (HMS) 的 Hudi 和 MinIO 的替代实现。部分源于Hadoop生态系统的起源故事,Hudi的许多大规模数据实现仍然利用HMS。通常,从遗留系统迁移的故事涉及某种程度的混合,因为所有涉及的产品中最好的产品都被用来取得成功。
Hudi 谈 MinIO:一个成功的组合
Hudi 从依赖 HDFS 到云原生对象存储(如 MinIO)的演变与数据行业从单一和不适当的传统解决方案的转变完全吻合。MinIO 的性能、可扩展性和成本效益使其成为存储和管理 Hudi 数据的理想选择。此外,Hudi 针对现代数据中的 Apache Spark、Flink、Presto、Trino、StarRocks 等的优化与 MinIO 无缝集成,以实现大规模的云原生性能。这种兼容性代表了现代数据湖架构中的一种重要模式。

HMS集成:增强数据治理和管理
虽然Hudi提供了开箱即用的核心数据管理功能,但与HMS的集成增加了另一层控制和可见性。以下是HMS集成如何使大规模Hudi部署受益:
-
改进数据治理:HMS集中管理元数据,实现数据湖的一致访问控制、沿袭跟踪和审计。这可确保数据质量、合规性并简化治理流程。
-
简化架构管理:在HMS内定义和实施Hudi表的架构,确保跨流水线和应用的数据一致性和兼容性。HMS模式演进功能允许在不破坏管道的情况下适应不断变化的数据结构。
-
增强的可见性和发现性:HMS为您的所有数据资产(包括Hudi表)提供中央目录。这有助于分析师和数据科学家轻松发现和探索数据。
入门:满足先决条件
要完成本教程,您需要设置一些软件。以下是您需要的内容的细分:
-
Docker 引擎:这个强大的工具允许您在称为容器的标准化软件单元中打包和运行应用程序。
-
Docker Compose:它充当业务流程协调程序,简化多容器应用程序的管理。它有助于轻松定义和运行复杂的应用程序。
**安装:**如果您要重新开始,Docker 桌面安装程序提供了一个方便的一站式解决方案,用于在特定平台(Windows、macOS 或 Linux)上安装 Docker 和 Docker Compose。这通常被证明比单独下载和安装它们更容易。
安装 Docker Desktop 或 Docker 和 Docker Compose 的组合后,可以通过在终端中运行以下命令来验证它们的存在:
docker-compose --version
请注意,本教程是为 linux/amd64 构建的,要使其适用于 Mac M2 芯片,您还需要安装 Rosetta 2。您可以通过运行以下命令在终端窗口中执行此操作:
softwareupdate --install-rosetta
在 Docker 桌面设置中,您还需要启用使用 Rosetta 在 Apple Silicone 上进行 x86_64/amd64 二进制仿真。为此,请导航到“设置”→“常规”,然后选中“罗塞塔”框,如下所示。

在MinIO上将HMS与Hudi集成
本教程使用 StarRock 的 demo 存储库。克隆在此处找到的存储库。在终端窗口中,导航到 documentation-samples 目录,然后 hudi 导航到文件夹,然后运行以下命令:
docker compose up
运行上述命令后,您应该会看到 StarRocks、HMS 和 MinIO 已启动并运行。
访问 MinIO 控制台 http://localhost:9000/ 并使用凭证登录 admin:password ,以查看存储桶 warehouse 是否已自动创建。

使用 Spark Scala 插入数据
执行以下命令,访问 spark-hudi 容器内的shell。
docker exec -it hudi-spark-hudi-1 /bin/bash
然后运行以下命令,这将带您进入 Spark REPL:
/spark-3.2.1-bin-hadoop3.2/bin/spark-shell
进入 shell 后,执行以下 Scala 行以创建数据库、表并将数据插入该表中:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import scala.collection.JavaConversions._
val schema = StructType(Array(
StructField("language", StringType, true),
StructField("users", StringType, true),
StructField("id", StringType, true)
))
val rowData= Seq(
Row("Java", "20000", "a"),
Row("Python", "100000", "b"),
Row("Scala", "3000", "c")
)
val df = spark.createDataFrame(rowData, schema)
val databaseName = "hudi_sample"
val tableName = "hudi_coders_hive"
val basePath = "s3a://warehouse/hudi_coders"
df.write.format("hudi").
option(org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME, tableName).
option(RECORDKEY_FIELD_OPT_KEY, "id").
option(PARTITIONPATH_FIELD_OPT_KEY, "language").
option(PRECOMBINE_FIELD_OPT_KEY, "users").
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", databaseName).
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.datasource.hive_sync.partition_fields", "language").
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hive-metastore:9083").
mode(Overwrite).
save(basePath)
就是这样。您现在已经使用 Hudi 和 HMS 设置了 MinIO 数据湖。导航回以 http://localhost:9000/ 查看您的仓库文件夹是否已填充。
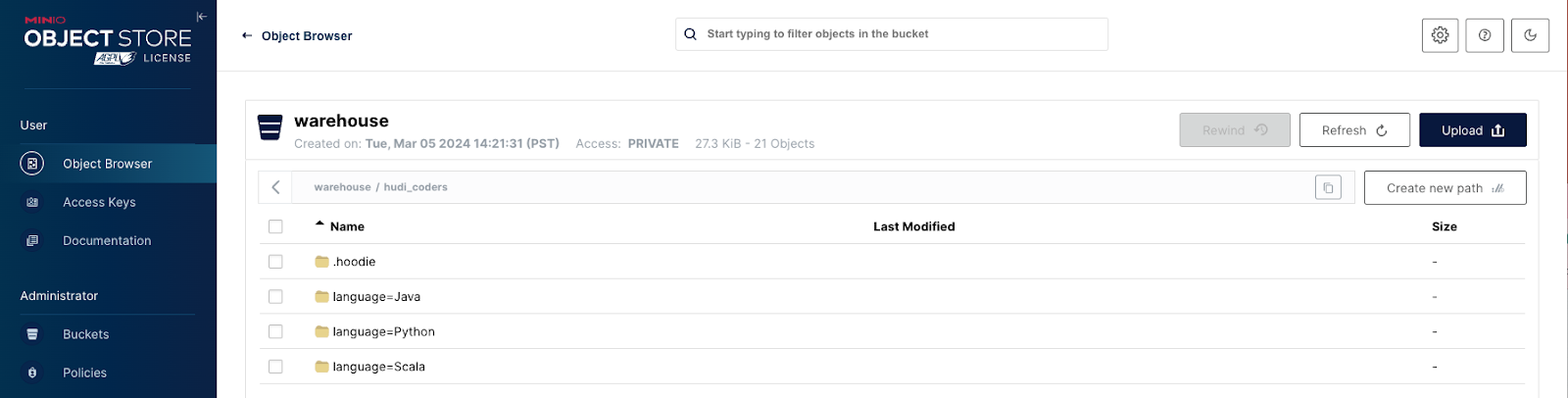
数据探索
您可以选择通过在同一 Shell 中利用以下 Scala 来进一步探索您的数据。
val hudiDF = spark.read.format("hudi").load(basePath + "/*/*")
hudiDF.show()
val languageUserCount = hudiDF.groupBy("language").agg(sum("users").as("total_users"))
languageUserCount.show()
val uniqueLanguages = hudiDF.select("language").distinct()
uniqueLanguages.show()
// Stop the Spark session
System.exit(0)
立即开始构建云原生现代数据湖
Hudi、MinIO和HMS无缝协作,为构建和管理大规模现代数据湖提供全面的解决方案。通过集成这些技术,您可以获得释放数据全部潜力所需的敏捷性、可扩展性和安全性。