基于YOLOv5的火灾检测系统的设计与实现
- 概述
- 系统架构
- 主要组件
- 代码结构
- 功能描述
- YOLOv5检测器
- 视频处理器
- 主窗口
- 详细代码说明
- YOLOv5检测器类
- 视频处理类
- 主窗口类
- 使用说明
- 环境配置
- 运行程序
- 操作步骤
- 检测示例
- 图像检测
- 视频检测
- 实时检测
- 数据集介绍
- 数据集获取
- 数据集规模
- YOLOv5模型介绍
- YOLOv5概述
- 官方模型
- 训练过程
- 数据准备
- 模型训练
- 模型评估
- 模型优化
- 模型部署
- 结论
- 完整资料地址
概述
本报告介绍了一种基于YOLOv5深度学习模型的火灾检测系统。该系统能够对图像和视频中的火灾进行检测,并通过PyQt5实现图形用户界面(GUI),允许用户加载图像、视频文件,或使用摄像头进行实时检测。检测结果会显示在界面上,并且可以保存检测结果。本报告将详细描述系统的架构、功能实现、使用说明、检测示例、数据集获取与介绍、YOLOv5模型介绍以及训练过程。
系统架构
主要组件
- YOLOv5检测器:利用预训练的YOLOv5模型进行火灾检测。
- 视频处理器:处理视频流并进行火灾检测,输出处理后的帧和检测信息。
- 主窗口:提供用户界面,允许用户进行操作。
代码结构
代码主要包括以下几个部分:
- YOLOv5检测器类 (
YoloV5Detector): 负责加载YOLOv5模型并进行图像和视频帧的检测。 - 视频处理器类 (
VideoProcessor): 继承自QThread,处理视频流并发出信号更新UI。 - 主窗口类 (
MainWindow): 继承自QMainWindow,提供用户界面和交互功能。
功能描述
YOLOv5检测器
YoloV5Detector类用于加载YOLOv5模型并进行火灾检测。其主要功能包括:
- 加载模型:使用
torch.hub.load方法加载自定义训练的YOLOv5模型,如yolov5s_fire.pt。 - 图像检测:读取图像文件并使用模型进行火灾检测,返回检测结果。
- 视频帧检测:对视频帧进行火灾检测,返回检测结果。
视频处理器
VideoProcessor类继承自QThread,用于在单独的线程中处理视频流。其主要功能包括:
- 视频读取:打开视频文件或摄像头。
- 帧处理:对每一帧进行火灾检测,并将检测结果发送到主窗口进行显示。
- 信号发射:发射处理后的帧、每秒帧数(FPS)、处理进度、检测到的对象数量和各类对象数量的信号。
- 停止:停止视频处理并释放资源。
主窗口
MainWindow类继承自QMainWindow,提供用户界面,允许用户加载图像、视频或打开摄像头进行火灾检测。其主要功能包括:
- 打开图像:选择并加载图像进行检测。
- 打开视频:选择并加载视频文件进行检测。
- 打开摄像头:使用摄像头进行实时检测。
- 显示结果:在界面上显示检测结果、每秒帧数(FPS)、处理进度、检测到的对象数量和各类对象数量。
- 保存结果:将当前检测结果保存为图像文件。
详细代码说明
以下是代码中关键部分的详细说明:
YOLOv5检测器类
class YoloV5Detector:
def __init__(self):
# 加载自定义训练的YOLOv5模型进行火灾检测
self.model = torch.hub.load('ultralytics/yolov5', 'custom', path="./yolov5s_fire.pt")
def detect_image(self, image_path):
# 读取图像文件并进行检测
image = cv2.imread(image_path)
results = self.model(image)
return results
def detect_frame(self, frame):
# 对视频帧进行检测
results = self.model(frame)
return results
视频处理类
class VideoProcessor(QThread):
frame_processed = pyqtSignal(np.ndarray)
fps_signal = pyqtSignal(float)
progress_signal = pyqtSignal(str)
object_count_signal = pyqtSignal(int)
category_count_signal = pyqtSignal(dict)
def __init__(self, video_path=None, use_camera=False, output_dir='output'):
super().__init__()
self.video_path = video_path
self.use_camera = use_camera
self.running = False
self.paused = False
self.mutex = QMutex()
self.condition = QWaitCondition()
self.detector = YoloV5Detector()
self.out = None
self.output_dir = output_dir
def run(self):
self.running = True
if self.use_camera:
cap = cv2.VideoCapture(0)
else:
cap = cv2.VideoCapture(self.video_path)
if not cap.isOpened():
return
# 创建唯一的文件名以当前时间命名
current_time = time.strftime("%Y%m%d_%H%M%S")
os.makedirs(self.output_dir, exist_ok=True)
output_file = os.path.join(self.output_dir, f'output_{current_time}.mp4')
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
if fps == 0: # 如果无法获取fps,设置为默认值
fps = 30
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
self.out = cv2.VideoWriter(output_file, fourcc, fps, (width, height))
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
duration = total_frames / fps
last_time = time.time()
frame_count = 0
while self.running:
self.mutex.lock()
if self.paused:
self.condition.wait(self.mutex)
self.mutex.unlock()
ret, frame = cap.read()
if not ret:
break
results = self.detector.detect_frame(frame)
annotated_frame = results.render()[0]
self.frame_processed.emit(annotated_frame)
object_count = len(results.xyxy[0]) # 检测到的对象数量
categories = results.names # 对象类别名称
category_counts = {category: (results.pred[0][:, -1] == i).sum().item() for i, category in categories.items()}
non_zero_category_counts = {cat: count for cat, count in category_counts.items() if count > 0}
self.object_count_signal.emit(object_count)
self.category_count_signal.emit(non_zero_category_counts)
if self.out:
self.out.write(annotated_frame)
frame_count += 1
if frame_count % 10 == 0:
current_time = frame_count / fps
progress_text = f'{self.format_time(current_time)} / {self.format_time(duration)}'
self.progress_signal.emit(progress_text)
current_time = time.time()
show_fps = 1.0 / (current_time - last_time)
last_time = current_time
self.fps_signal.emit(show_fps)
cap.release()
if self.out:
self.out.release()
def format_time(self, seconds):
mins, secs = divmod(seconds, 60)
return f'{int(mins):02}:{int(secs):02}'
def pause(self):
self.paused = True
def resume(self):
self.paused = False
self.condition.wakeAll()
def stop(self):
self.running = False
self.resume()
self.wait()
主窗口类
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle('YOLOv5 Object Detection')
self.setGeometry(100, 100, 1000, 700)
self.layout = QVBoxLayout()
self.label = QLabel(self)
self.layout.addWidget(self.label)
self.fps_label = QLabel(self)
self.fps_label.setFont(QFont('Arial', 14))
self.layout.addWidget(self.fps_label)
self.object_count_label = QLabel(self)
self.object_count_label.setFont(QFont('Arial', 14))
self.layout.addWidget(self.object_count_label)
self.category_count_label = QLabel(self)
self.category_count_label.setFont(QFont('Arial', 14))
self.layout.addWidget(self.category_count_label)
self.progress_label = QLabel(self)
self.progress_label.setFont(QFont('Arial', 14))
self.layout.addWidget(self.progress_label)
self.slider = QSlider(Qt.Horizontal)
self.slider.setRange(0, 100)
self.slider.setValue(0)
self.slider.sliderPressed.connect(self.pause_video)
self.slider.sliderReleased.connect(self.resume_video)
self.layout.addWidget(self.slider)
button_layout = QHBoxLayout()
self.btn_image = QPushButton('Open Image', self)
self.btn_image.setFont(QFont('Arial', 14))
self.btn_image.clicked.connect(self.open_image)
button_layout.addWidget(self.btn_image)
self.btn_video = QPushButton('Open Video', self)
self.btn_video.setFont(QFont('Arial', 14))
self.btn_video.clicked.connect(self.open_video)
button_layout.addWidget(self.btn_video)
self.btn_camera = QPushButton('Open Camera', self)
self.btn_camera.setFont(QFont('Arial', 14))
self.btn_camera.clicked.connect(self.open_camera)
button_layout.addWidget(self.btn_camera)
self.btn_save = QPushButton('Save Result', self)
self.btn_save.setFont(QFont('Arial', 14))
self.btn_save.clicked.connect(self.save_result)
button_layout.addWidget(self.btn_save)
self.layout.addLayout(button_layout)
self.container = QWidget()
self.container.setLayout(self.layout)
self.setCentralWidget(self.container)
self.cap = None
self.current_frame = None
self.video_processor = None
def open_image(self):
self.stop_video_processing()
file_name, _ = QFileDialog.getOpenFileName(self, 'Open Image', '', 'Images (*.png *.xpm *.jpg *.jpeg *.bmp)')
if file_name:
self.show_loading_message(True)
results = YoloV5Detector().detect_image(file_name)
self.current_frame = results.render()[0]
self.display_image(self.current_frame)
self.fps_label.setText('')
self.progress_label.setText('')
self.object_count_label.setText('')
self.category_count_label.setText('')
self.show_loading_message(False)
def open_video(self):
self.stop_video_processing()
file_name, _ = QFileDialog.getOpenFileName(self, 'Open Video', '', 'Videos (*.mp4 *.avi *.mov *.mkv)')
if file_name:
self.show_loading_message(True)
self.start_video_processing(file_name)
def open_camera(self):
self.stop_video_processing()
self.show_loading_message(True)
self.start_video_processing(use_camera=True)
def show_loading_message(self, show):
self.btn_image.setEnabled(not show)
self.btn_video.setEnabled(not show)
self.btn_camera.setEnabled(not show)
self.btn_save.setEnabled(not show)
if show:
QApplication.setOverrideCursor(Qt.WaitCursor)
else:
QApplication.restoreOverrideCursor()
def start_video_processing(self, video_path=None, use_camera=False):
self.video_processor = VideoProcessor(video_path=video_path, use_camera=use_camera)
self.video_processor.frame_processed.connect(self.display_image)
self.video_processor.fps_signal.connect(self.update_fps)
self.video_processor.progress_signal.connect(self.update_progress)
self.video_processor.object_count_signal.connect(self.update_object_count)
self.video_processor.category_count_signal.connect(self.update_category_count)
self.video_processor.start()
self.show_loading_message(False)
def stop_video_processing(self):
if self.video_processor is not None:
self.video_processor.stop()
self.video_processor = None
def pause_video(self):
if self.video_processor is not None:
self.video_processor.pause()
def resume_video(self):
if self.video_processor is not None:
self.video_processor.resume()
def update_fps(self, fps):
self.fps_label.setText(f'FPS: {fps:.2f}')
def update_progress(self, progress):
self.progress_label.setText(progress)
def update_object_count(self, count):
self.object_count_label.setText(f'Object Count: {count}')
def update_category_count(self, category_counts):
category_count_text = 'Category Counts: ' + ', '.join([f'{cat}: {count}' for cat, count in category_counts.items()])
self.category_count_label.setText(category_count_text)
def display_image(self, frame):
self.current_frame = frame
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
height, width, channel = frame.shape
bytes_per_line = 3 * width
convert_to_Qt_format = QImage(rgb_frame.data, width, height, bytes_per_line, QImage.Format_RGB888)
p = convert_to_Qt_format.scaled(1000, 600, aspectRatioMode=1)
self.label.setPixmap(QPixmap.fromImage(p))
def save_result(self):
if self.current_frame is not None:
file_name, _ = QFileDialog.getSaveFileName(self, 'Save Image', '', 'Images (*.png *.jpg *.jpeg *.bmp)')
if file_name:
cv2.imwrite(file_name, self.current_frame)
elif self.video_processor:
self.video_processor.stop()
self.video_processor.wait()
self.video_processor = None
使用说明
环境配置
-
安装Python 3.x。
-
安装必要的Python库: pyqt5、pytorch等
运行程序
-
下载或克隆项目代码。
-
确保YOLOv5模型文件(如
yolov5s_fire.pt)位于项目目录中。 -
运行主程序:
python main.py
操作步骤
- 打开图像:点击“Open Image”按钮,选择图像文件进行火灾检测。
- 打开视频:点击“Open Video”按钮,选择视频文件进行火灾检测,检测结果自动保存在output文件夹中。
- 打开摄像头:点击“Open Camera”按钮,使用摄像头进行实时火灾检测,检测结果自动保存在output文件夹中。
- 保存结果:点击“Save Result”按钮,将当前检测结果保存为图像文件。
检测示例
图像检测
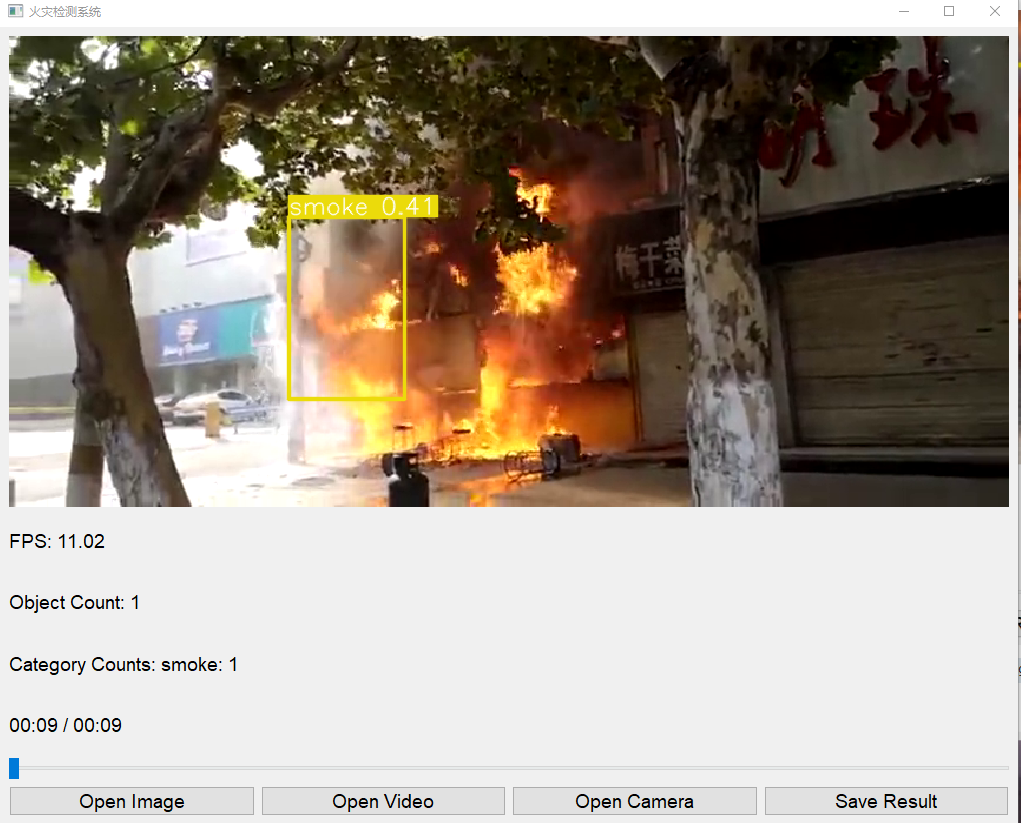
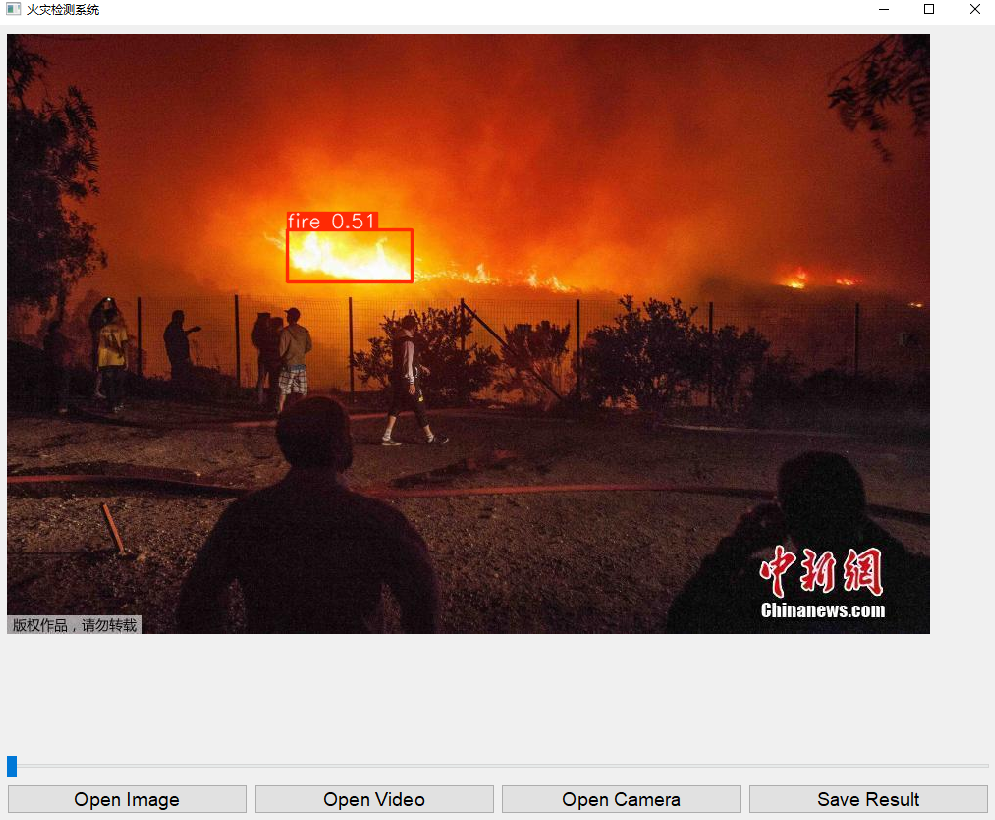
加载一张火灾图像,系统会在图像上标注出火灾区域,并显示检测到的对象数量和各类对象数量。
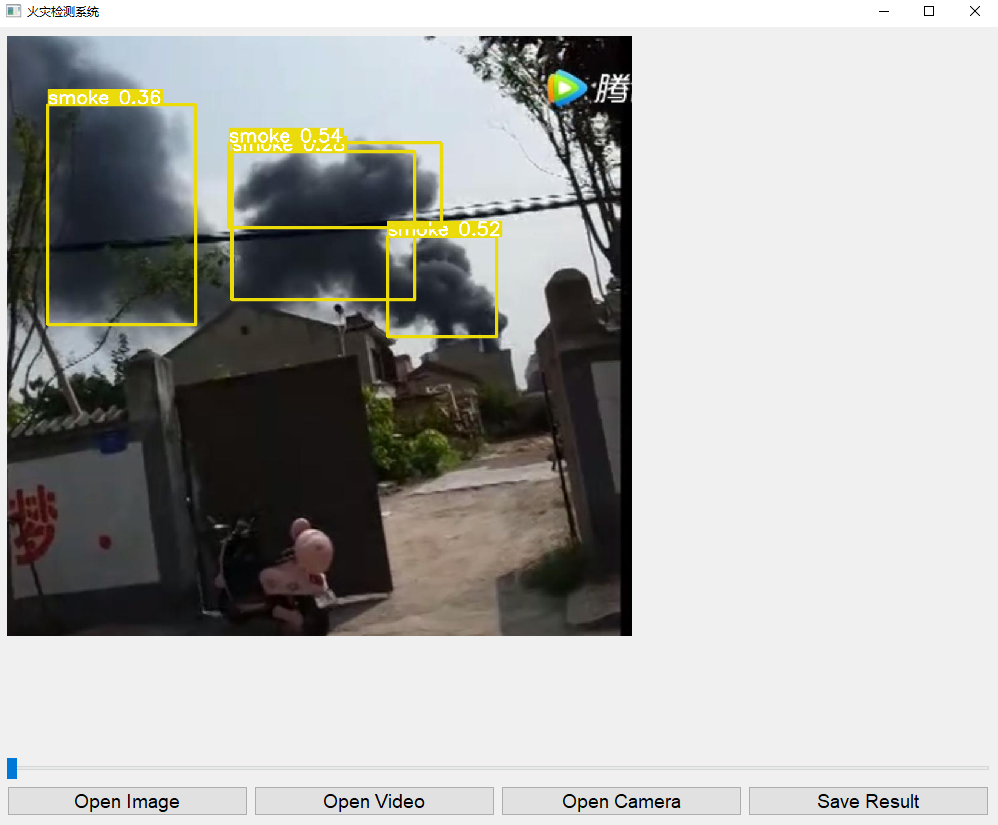
视频检测
加载一个包含火灾场景的视频文件,系统会对视频进行逐帧检测,并在界面上显示处理后的帧、每秒帧数、处理进度、检测到的对象数量和各类对象数量。
实时检测
通过摄像头进行实时火灾检测,系统会实时显示检测结果并更新相关信息。
数据集介绍
数据集获取
火灾检测模型的训练数据集可以从多个公开的火灾图像和视频数据库中获取。常见的数据集来源包括:
- Kaggle:Kaggle上有许多公开的火灾图像数据集,可以通过搜索“fire dataset”获取。
- 公共安全数据库:一些公共安全组织和研究机构会发布火灾检测相关的数据集。
- 自行收集:通过网络爬虫技术从互联网上收集火灾图像和视频。
数据集规模
一个典型的火灾检测数据集可能包含以下内容:
- 图像数量:约5000至10000张火灾图像,覆盖不同的火灾场景、光照条件和拍摄角度。
- 视频数量:约50至200个火灾视频,每个视频时长约1至5分钟,分辨率为720p或1080p。
- 标注信息:每张图像和每段视频的火灾区域和类别标注信息,包括火焰、烟雾等。
YOLOv5模型介绍
YOLOv5概述
YOLOv5(You Only Look Once)是一种实时目标检测模型,由Ultralytics开发。相比于之前的YOLO版本,YOLOv5在精度和速度方面有了显著提升。其主要特点包括:
- 端到端训练:支持从头开始训练模型,使用PyTorch实现。
- 高效推理:具有较高的推理速度,适用于实时目标检测。
- 模块化设计:易于扩展和修改,支持自定义数据集和模型。
官方模型
YOLOv5提供了多种预训练模型,包括:
- YOLOv5s:轻量级模型,适用于资源受限的设备。
- YOLOv5m:中等规模模型,在精度和速度之间取得平衡。
- YOLOv5l:大型模型,适用于精度要求较高的任务。
- YOLOv5x:超大型模型,具有最高的检测精度。
每种模型都可以在COCO数据集上进行预训练,并支持迁移学习,以适应特定任务。
训练过程
数据准备
- 数据标注:使用标注工具(如LabelImg)对火灾图像和视频进行标注,生成YOLO格式的标注文件。
- 数据划分:将数据集划分为训练集、验证集和测试集,比例通常为70:20:10。
模型训练
-
配置文件:创建YOLOv5的配置文件,包括模型结构、超参数和训练参数。
-
数据加载:使用YOLOv5的Dataloader加载训练数据。
-
训练
:运行训练脚本,开始模型训练。训练过程中会输出训练日志和模型检查点。
python train.py --data data/fire.yaml --cfg models/yolov5s.yaml --weights yolov5s.pt --epochs 100
模型评估
- 验证集评估:使用验证集评估模型性能,计算平均精度(mAP)、召回率、准确率等指标。
- 测试集评估:使用测试集对最终模型进行评估,确保模型的泛化能力。
模型优化
- 超参数调整:根据评估结果调整学习率、批量大小、数据增强策略等超参数。
- 迁移学习:使用预训练模型进行迁移学习,提高模型在特定任务上的表现。
模型部署
- 模型保存:将训练好的模型保存为权重文件(如
yolov5s_fire.pt)。 - 集成到系统:将模型集成到火灾检测系统中,实现实时检测功能。
结论
本报告详细介绍了基于YOLOv5的火灾检测系统,包括系统架构、功能实现、使用说明、检测示例、数据集获取与介绍、YOLOv5模型介绍以及训练过程。该系统通过PyQt5提供了友好的用户界面,支持图像、视频和实时摄像头的火灾检测,具有较高的检测精度和速度。未来可以进一步优化模型和系统,以提升火灾检测的准确性和实时性。
完整资料地址
- yolov5预训练模型地址:https://github.com/ultralytics/yolov5
- 本文项目完整链接:链接:https://pan.baidu.com/s/1G460kKohHO11Sn8m8eJccg?pwd=l1uf
- 包含: PyQT用户交互页面、训练好的火灾检测模型(yolov5s)、几张测试图片与 一段测试视频
- 提取码:l1uf
- 数据集:链接:https://pan.baidu.com/s/1Xqnu-h2Hwcja1X2V5vKVHQ?pwd=nx61
- 提取码:nx61
- 解压密码:root