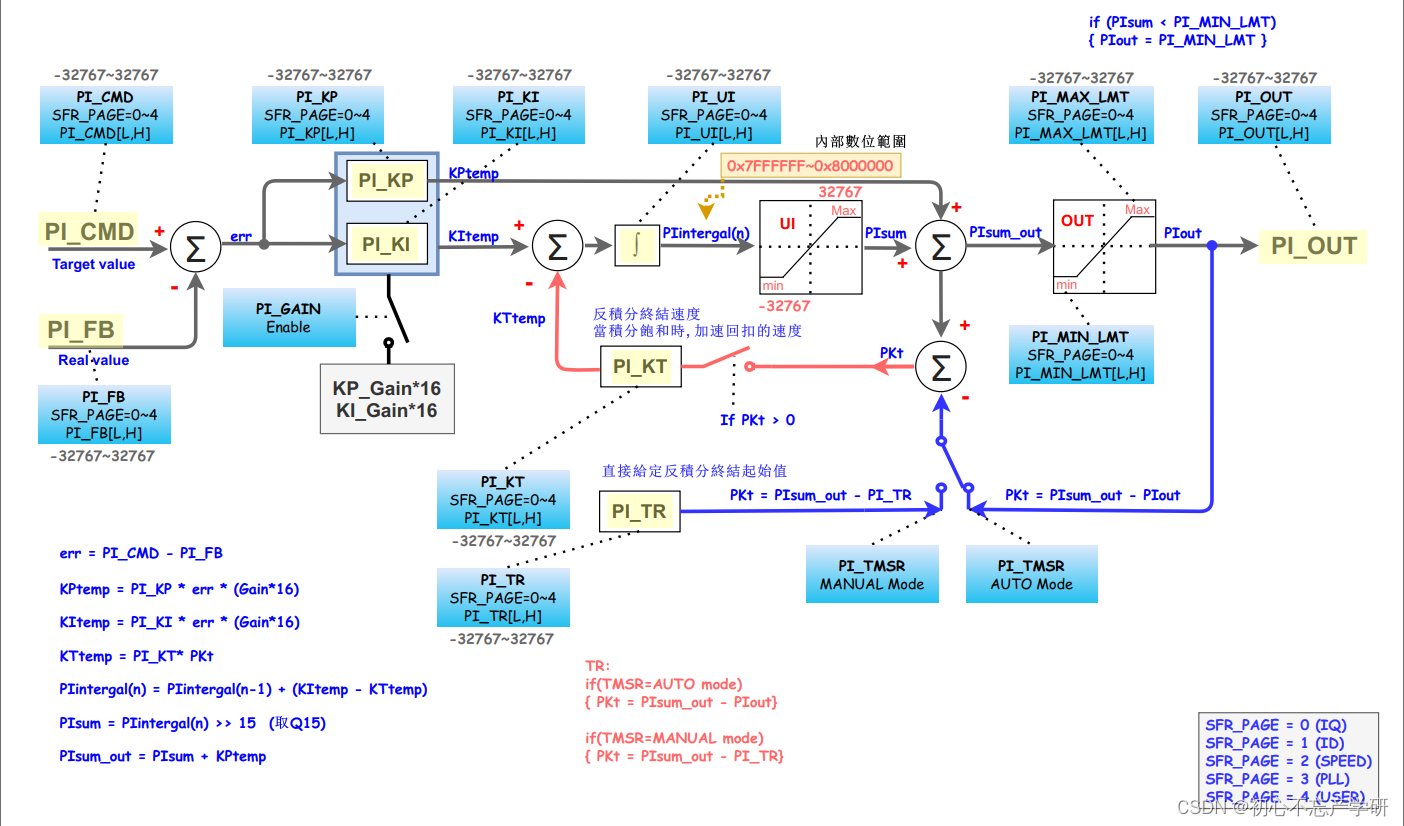
1 概念
Redis 所有的数据都是存储在内存中的, 如果不进行任何的内存回收, 那么很容易出现内存爆满的情况。因此,在某些情况下需要对占用的内存空间进行释放。
Redis 中内存的释放主要分为两类
Redis 中内存的释放主要分为两类:
- 内存回收: 将过期的 key 清除,以减少内存占用
- 内存淘汰: 在内存使用达到上限(max_memory), 按照一定的策略删除一些键,以释放内存空间
两者都是通过删除 key (及其对应的 value) 来达到释放空间的效果。
区别在于前者清除的是用户明确不需要的 key, 而后者清除的则是用户可能仍然需要的 key。
2 内存回收
2.1 过期策略
在内存中的大量 key 中, 如何清除其中已经过期的 key 呢?
常用的方式有 3 种
- 定时过期
- 惰性过期
- 定期过期
定时过期
为每个 key 都创建一个定时器, 时间到了, 就将这个 key 清除。
该策略可以立即清除过期的数据, 对内存很友好。但是会占用大量的 CPU 资源去处理过期的数据, 从而影响缓存的响应时间和吞吐量。
惰性过期
key 过期了, 不进行处理。当后续访问到这个 key 时, 才会判断该 key 是否已过期, 过期则清除。
该策略可以最大化地节省 CPU 资源, 却对内存非常不友好。极端情况可能出现大量的过期 key 没有再次被访问, 从而不会被清除, 占用大量内存。
定期过期
将所有的 key 维护在一起, 每隔一段时间就从中扫描一定的数量的 key(采样), 并清除其中已经过期的 key。
通过调整定时扫描的时间间隔和每次扫描的耗时, 可以在不同情况下使得 CPU 和内存资源达到最优的平衡效果。
在 Reids 的实现中是通过 惰性过期 + 定期过期 2 种策略配合, 达到内存回收的效果。
2.2 惰性过期 在 Redis 中的实现
前提: Redis 中一个对象的过期时间存放在 dictEntry 的 v.s64 中, 至于 dictEntry 的设计可以看一下后面的附录。
Redis 大部分读写对象的命令, 在执行前都会调用 expireIfNeeded 函数做一个过期检查
- 如果 key 已经过期了, 将其删除
- 如果 key 未过期, 不做任何处理
expireIfNeeded 函数的定义如下
int expireIfNeeded(redisDb *db, robj *key) {
// key 未过期返回 0
if (!keyIsExpired(db,key)) return 0;
// 下面的逻辑都是 Key 过期的逻辑处理
// 当前的节点是从节点, 返回 1, 然后结束
// 为了保持主从数据的一致, 从节点不会主动清除数据, 都是主节点同步消息在删除
if (server.masterhost != NULL) return 1;
// 已经删除过期键个数 + 1
server.stat_expiredkeys++;
// 向从节点和 AOF 文件传播 key 过期信息, 清除过期 key
propagateExpire(db,key,server.lazyfree_lazy_expire);
// 发送事件通知
notifyKeyspaceEvent(NOTIFY_EXPIRED,"expired",key,db->id);
// lazyfree-lazy-expire 配置参数 (版本 4.0 以上支持), 默认为 0
// 根据配置, 同步或异步删除 key (异步删除: 先将 key 逻辑删除, 然后在通过后台的线程池进行真正的空间释放)
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) : dbSyncDelete(db,key);
}
int keyIsExpired(redisDb *db, robj *key) {
// 从过期字典中获取 key 对应的过期时间, 实际就是获取 dictEntity 的 v 中的 s64 值 (dictEntity.v.s64)
mstime_t when = getExpire(db,key);
mstime_t now;
// 没有过期时间
if (when < 0) return 0;
// redis 在加载数据中
if (server.loading) return 0;
// 获取当前的事件
if (server.lua_caller) {
// 有 lua 脚本在执行中, 当前时间等于脚本开始执行前的时间
now = server.lua_time_start;
} else if (server.fixed_time_expire > 0) {
// 有缓存时间, 线使用缓存时间
// server.mstime 这个时间会在调用执行命令函数的 call() 前进行更新
// 这样可以避免一些批量操作的命令, 比如 RPOPLPUSH 等命令, 这些命令会执行过程中可能多次访问这个 key
// 而在多次的访问过程中, 可能出现上一次访问未过期, 下次访问已经过期了, 通过这个缓冲时间可以解决这个问题
now = server.mstime;
} else {
// 其他情况, 直接获取当前时间
now = mstime();
}
// 当前时间是否大于 key 的过期时间
return now > when;
}
expireIfNeeded 的调用时机, 基本都是在各个命令内部。 以 String 的 get 命令为例, 大体的流程如下
/**
* get 命令对应的执行函数
* 需要的参数都封装在 client 对象中
*/
void getCommand(client *c) {
// getGenericCommand -> lookupKeyReadOrReply -> lookupKeyRead -> lookupKeyReadWithFlags
// getGenericCommand 经过几个函数最终调用到 lookupKeyReadWithFlags
getGenericCommand(c);
}
robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) {
robj *val;
// expireIfNeeded 返回 > 0, 过期了
if (expireIfNeeded(db,key) == 1) {
// 省略过期处理
// 过期的处理, 然后 return null
}
// 非过期处理, 查找然后返回
val = lookupKey(db,key,flags);
if (val == NULL)
server.stat_keyspace_misses++;
else
server.stat_keyspace_hits++;
return val;
}
上面就是 get 指令的中的惰性过期的过程, 其他命令的逻辑差不多, 核心就是一个 expireIfNeeded 函数。
2.3 定期过期在 Redis 中的实现
Redis 默认是 16 个数据库, 每个数据库会将设置了过期时间的 key 放到各自的一个独立的字典中, 称为过期字典 (redisDb 对象的 dict *expires 属性)。
然后 Redis 默认会按照每秒 10 次的频率(可以通过 redis.conf 中的 hz 配置)进行过期扫描。
扫描的过程不会遍历整个过期字典,而是按照以下策略进行
- 从过期字典中随机选择 20 个 key
- 删除其中已经过期的键
- 如果超过 25% 的键被删除, 则重复步骤 1, 2, 3, 没有超过, 就结束这次扫描
- 同时为防止重复循环, 导致线程卡死, 增加了每 16 次抽样, 就做一次扫描时间的上限的检查 (默认是慢模式下, 上限是 25 毫秒, 如果是快模式,扫描上限是 1 毫秒), 超过就结束循环
定期过期删除的实现主要在 /activeExpireCycle 函数, 大体的逻辑如下
/**
* 过期循环清除
* 为了便于理解, 这里对函数的逻辑做了一点小调整和删除一些非必要的逻辑, 但是整体的逻辑不变
* @type 模式, 取值有 2 个 ACTIVE_EXPIRE_CYCLE_SLOW (0, 慢模式), ACTIVE_EXPIRE_CYCLE_FAST (1, 快模式)
*/
void activeExpireCycle(int type) {
// 静态变量, 当前处理的数据库索引
// 静态的效果, 这个变量执行后的值不会被清空, 每次调用这个方法, 是上一次执行的值
// 这样就可以保证 16 个数据库, 每次方法执行完, 下次进来可以执行到下一个数据库, 循环起来,而不是每次进来都从第 0 个开始
static unsigned int current_db = 0;
// 上一次清理是否是因为时间超时结束循环的, 同样是静态变量
static int timelimit_exit = 0;
// 上一次快速循环循环的时间, 同样是静态变量
static long long last_fast_cycle = 0;
// 当前时间
long long start = ustime(),
// 本次循环清除是快速循环, 上一次是时间超时获取 2 次快速循环的时间差在 2 毫秒内, 不执行
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
// 上一次循环是因为时间超时结束的, 本次快速循环不进行
if (!timelimit_exit) return;
// 上次快速循环距离当前时间在 1000 * 2 = 2 毫秒内, 也不进行快速循环
if (start < last_fast_cycle + ACTIVE_EXPIRE_CYCLE_FAST_DURATION*2) return;
last_fast_cycle = start;
}
// 计算循环的上限毫秒限制
// server.hz 默认等于 10, ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 等于 25
// 1000000 * 25 / 10 / 100 = 25000 单位: 微秒, 即 25 毫秒
long long timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100;
// ACTIVE_EXPIRE_CYCLE_FAST_DURATION = 1000
// 如果是快模式, 修改为 1000 微秒, 即 1 毫秒超时
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = ACTIVE_EXPIRE_CYCLE_FAST_DURATION;
// CRON_DBS_PER_CALL = 16, 每次循环处理的数据库数量
int dbs_per_call = CRON_DBS_PER_CALL;
// 遍历当前数据库的次数
int iteration = 0;
// 遍历循环 16 个数据库
for (int j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
// 清理过期的 key 个数
int expired;
// 计算本次处理的数据库
redisDb *db = server.db+(current_db % server.dbnum);
current_db++;
do {
// 开始循环清除当前数据库中过期的 key
// 遍历次数 + 1
iteration++;
// dictSize 获取整个过期字典的已经使用大小
unsigned long num = dictSize(db->expires);
// num == 0 表示整个字典没有数据, 跳出循环,处理下一个数据库
if (num == 0) {
break;
}
// 计算整个过期字典的总大小
unsigned long slots = dictSlots(db->expires);
// DICT_HT_INITIAL_SIZE = 4, 每个字典初始化时的默认值
// num > 0, 字典中有数据了, slots 大于 4, 表示当前的字典扩容过了
// num && slots > DICT_HT_INITIAL_SIZE, 当前的字典扩容过同时里面有数据
// num * 100 / slots < 1 计算当前使用的数据占整个字典的百分比是否小于 1%
// Redis 认为, 如果一个字典中的使用率小于 1%, 花时间去进行清理是一个昂贵的操作
// 应该停下来,等待更好的时间再进行调整
// 所以简单理解: 当这个字典中使用的空间小于 1%, 这里跳过了这个数据的处理
if (num && slots > DICT_HT_INITIAL_SIZE && (num * 100 / slots < 1))
break;
expired = 0;
// ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP = 20
// 本次从过期字典中获取多少个 key, 如果字典中的已经使用的 key 大于 20, 则只取 20 个, 否则有多少取多少
if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)
num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP;
// 循环 num 次从字典中获取 key
while (num--) {
dictEntry *de;
// 从过期字典中随机获取一个 key, 获取不到, 就停止本次循环
if ((de = dictGetRandomKey(db->expires)) == NULL) break;
// 尝试释放这个 key, 如果 key 释放成功, 过期次数 + 1
if (activeExpireCycleTryExpire(db,de,now)) expired++;
}
// 0xf = 15, iteration 表示遍历了 15 次
if ((iteration & 0xf) == 0) {
// 计算消耗时间
int elapsed = ustime()-start;
// 消耗时间超过了限制时间, 结束本次循环
if (elapsed > timelimit) {
// 超过时间限制标识设置为 true, 本次循环清除超时了, 结束本次循环清除
timelimit_exit = 1;
break;
}
}
// 本次清理的过期 key 超过了 25%, 继续, 否则结束
// ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP = 20
// 每次抽取的个数最大为 20 个, 控制 25%, 20 * 25% = 5 个
// 也就是过期的个数大于 5 就是大于 25%, (ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4 = 5)
} while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
}
// 省略各种分析数据的记录
}
调用 activeExpireCycle 的入口有 2 个
- Redis 定时事件触发
/**
* Reids 启动时, 向事件轮询中注册的唯一一个定时事件(默认 100 毫秒执行一次), 执行的函数
*/
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
...
// 数据库扫描
databasesCron();
...
}
void databasesCron(void) {
// 过期功能开启中, 默认为开启
if (server.active_expire_enabled) {
// 主节点
if (server.masterhost == NULL) {
// 慢模式循环清除
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
} else {
// 从节点处理
expireSlaveKeys();
}
}
...
}
- 事件轮询中, 进入阻塞前的调用函数
void beforeSleep(struct aeEventLoop *eventLoop) {
...
// 过期功能开启中同时为主节点
if (server.active_expire_enabled && server.masterhost == NULL)
// 快模式循环清除
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
...
}
3 内存淘汰
3.1 淘汰算法
为了能够腾出内存空间, 需要在一大群对象中选择某一些进行淘汰, 哪么应该基于什么标准进行选择呢?
比较常见的算法有 2 个: LRU 和 LFU。
LRU (Least Recently Used): 最近最少使用算法, 根据数据的历史访问记录进行淘汰数据,优先移除最近最少使用的数据。
简单理解就是根据对象的访问时间, 优先淘汰访问时间最早的对象。
LFU (Least Frequently Used): 最少频率使用算法, 根据数据的访问频率频率进行淘汰数据, 优先移除最近使用频率最少的数据。
简单理解就是根据对象的访问次数, 优先淘汰访问次数最少的对象。
3.2 Redis 内存淘汰策略
在 LFU 和 LRU 的基础上, Redis 提供了 8 种淘汰策略
| 策略 | 说明 |
|---|---|
| noeviction | 默认策略, 不会删除任何数据, 但是拒绝所有写入操作并返回客户端错误信息 (error)OOM command not allow when used memory。此时 Redis 只响应读操作。 |
| volatile-lru | Least Recently Used, 最近最少使用。在所有设置了 expire 的 key 中删除最近最少使用的键值对, 即距离上次访问时间最久的。 |
| allkeys-lru | Least Recently Used, 最近最少使用。在所有的 key 中删除最近最少使用的键值对, 即距离上次访问时间最久的。 |
| volatile-lfu | Least Frequently Used, 最不经常使用。在所有设置了 expire 的 key 中删除最不经常使用的键值对, 即访问次数最少的。 |
| allkeys-lfu | Least Frequently Used, 最不经常使用。在所有的 key 中删除最不经常使用的键值对, 即访问次数最少的。 |
| volatile-random | 在所有设置了 expire 的 key 中随机选择删除 |
| allkeys-random | 在所有的 key 中随机选择删除。 |
| volatile-ttl | Time To Live, 存活时间。 在所有设置了 expire 的 key 中删除 ttl 值最多的。 |
volatile-lru, volatile-random, volatile-ttl, 在没有符合条件的 key 的情况下, 会按照 noeviction 的策略进行处理。
3.3 Redis 对象淘汰判断标准设计
在上面介绍的几种策略可以知道, 要判断一个对象是否可以被淘汰, 需要对象自身存放使用策略对应的数据, 以便于判断
比如:
- 2 个 lru 策略, 需要对象自身保存好上次访问的时间
- 2 个 lfu 策略, 需要对象自身保存好访问次数
- ttl 策略, 需要对象自身保存好过期时间
- 2 个 random 策略, 不需要保存额外的数据, 通过随机一个数, 根据这个数从字典中获取数据即可
3.3.1 Redis 对象的设计
正常情况下, 当我们向 Redis 中存入一对键值对, 实际可以拆分为 2 个对象, 一个 key, 一个 value。
其中 key 可以明确为是一个字符串, 所以存入到 Redis 的键值对的 key 会被封装为 sds 对象。
但是 value 可以类型可以很多, 为了行为的统一等, 需要对 value 做一个封装, 落实到源码中就是一个 redisObject 对象, 其定义如下
typedef struct redisObject {
/**
* 标识这个对象的数据类型, 常说的 String, Hash, List 等
*/
unsigned type:4;
/**
* 可以理解为数据类型的具体实现类型
* 比如数据类型为 List, 在具体的实现中可以是 ArrayList LinkedList 等
*/
unsigned encoding:4;
/**
* LRU_BITS = 24,
* 一个 24 位的变量, 表示对象最后一次被程序访问的时间或者访问的次数, 与内存回收有关
* 暂时知道有这个对象即可, 后面有分析
*/
unsigned lru:LRU_BITS;
/**
* 被引用的次数, 当 refcount 为 0 的时候, 表示该对象已经不被任何对象引用, 则可以进行垃圾回收了
*/
int refcount;
/**
* 一个指针, 指向具体的数据
*/
void *ptr;
} robj;
一个对象的 lru 和 lfu 计算后的值, 都是存放在这个对象的 lru 字段中的, 但是 lru 和 lfu 的计算方式是不一样的。
3.3.2 lru 策略, 对象的访问时间设计
3.3.2.1 全局时间 lruclock
在 Redis 的中维护了一个全局的变量 lruclock, 表示当前时间的一个相对值。
/**
* redisServer 可以看做整个 Redis 运行时的上下文, 保存的数据, 配置等都在这个结构体中
*/
struct redisServer {
unsigned int lruclock = getLRUClock();
}
unsigned int getLRUClock(void) {
// LRU_CLOCK_RESOLUTION = 1000
// mstime() 当前时间毫秒, 当前时间的毫秒/LRU_CLOCK_RESOLUTION = 当前时间的毫秒/1000 = 变为单位秒
// LRU_CLOCK_MAX = ((1<<LRU_BITS)-1) = 1<<24-1 = redisObject lru 字段的最大值
// (当前的时间 / 1000) & (1<<24-1) 确保时间的精度是秒, 同时不会超过 24 位的整数的最多值
// 整个全局时间的进度为秒, 2 个对象的访问时间差如果在秒内, 得到的是他们的访问时间是一样的
// 得到一个当前时间的相对值
return (mstime()/LRU_CLOCK_RESOLUTION) & LRU_CLOCK_MAX;
}
同时这个时间会在 Redis 的定时任务 serverCron 中定时的更新为最新的值
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// serverCron 默认是 100 毫秒执行一次
unsigned int lruclock = getLRUClock();
atomicSet(server.lruclock,lruclock);
}
3.3.2.2 对象的访问时间设计
Redis 每次通过 key 在数据库中查询对应的 value 时, 在找到时, 就会进行 lru 字段的更新
robj *lookupKey(redisDb *db, robj *key, int flags) {
// 从字典中获取 key 对应的 dictEntry (字典的设计可以看一下后面的附录)
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
// 获取 key 对应的 dictEntry 的存在
// 获取 dictEntry 的 value 也就是 redisObject 对象
robj *val = dictGetVal(de);
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 && !(flags & LOOKUP_NOTOUCH)) {
// 没有在进行 RDB 或 AOF 操作, 并且 flags 没有设置 LOOKUP_NOTOUCH
// 淘汰策略设置的的 LFU 策略
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
// 其他策略, 更新 lru 为全局的 lruclock
val->lru = LRU_CLOCK();
}
}
} else {
// key 不存在, 返回 null
return NULL;
}
}
unsigned int LRU_CLOCK(void) {
unsigned int lruclock;
// LRU_CLOCK_RESOLUTION = 1000
// 1000/server.hz 就是上面定时任务 serverCron 的执行时间
// <= 1000 说明 serverCron 的执行时间小于 1 秒, 直接获取 server.lruclock 的值
// 如果大于 1000, 就调用 getLRUClock() 实时获取当前的时间, 因为频率太低了, 会造成更多的对象的访问时间一样
if (1000/server.hz <= LRU_CLOCK_RESOLUTION) {
atomicGet(server.lruclock,lruclock);
} else {
lruclock = getLRUClock();
}
return lruclock;
}
3.3.3 lfu 策略, 对象的访问频率设计
对象的 lfu 同样是存放在 redisObject 的 lru:LRU_BITS 字段。 这个 24 bits 字段, 被分为两部分
- 高 16 位用来记录访问时间 (单位为分钟,ldt, last decrement time)
- 低 8 位用来记录相对的访问次数, 简称 counter (logc, logistic counter)
Redis 中对 LFU 的实现比较特殊, 通过时间衰减的方式近似达到了 LFU 的效果。
大体的思路如下:
- 对象创建时, 初始访问次数为 5 (避免刚创建出来, 对象就被回收), 同时记录下当前时间, 单位分钟
- 对象被访问时, 获取当前时间, 单位分钟, 当前时间 - 对象本身记录的时间, 得到相差多少分钟, 访问次数就减少多少
- 然后对象的访问次数 + 1, 再次记录下当前时间
这样对象在单位分钟内, 访问越频繁, 访问次数越大, 同时随着时间的推移, 没有进行访问, 访问次数会逐渐减少, 从而达到了 LFU 的效果。
ldt 记录的是最近一次访问的时间, 16 位, 所以最大值为 65535, 单位是分钟, 差不多 45 天左右。
也就是一个对象如果一直被访问, 到了第 45 天后, 这个值又会重新回到 0 开始计算。
ldt 的计算
unsigned long LFUGetTimeInMinutes(void) {
// & 65535 保证时间的范围在 0 ~ 65535 之间, 不会超过 16 数值的大小
return (server.unixtime/60) & 65535;
}
同 lru 一样, lruclock 的计算, 后面的时间比前面的时间小,
说明后面的时间到了下一轮的重新开始了, 这时只需要后面的时间 + 65535 - 前面的时间, 就能得到 2 个时间的差值了。
logc 记录的是一个相对的访问次数。
本身只有 8 位, 也就是最大值为 255, 也就是一个对象只能保存 255 次访问次数, 这个基本不同满足日常的使用。
所以 Redis 内部设计了一个随机公式, 控制访问次数的增长, 即每次访问, 访问次数加不加一, 通过随机判断。
uint8_t LFULogIncr(uint8_t counter) {
// 当前的访问次数已经达到了最大值了
if (counter == 255)
return 255;
// 产生一个随机数
double r = (double)rand()/RAND_MAX;
// 获取一个基础值, 当前的次数 - 对象初始化的默认次数 (LFU_INIT_VAL = 5)
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
// 1.0 / 基础值 * server.lfu_log_factor (默认值, 10, 可配置) + 1, 得到一个数
double p = 1.0/(baseval*server.lfu_log_factor+1);
// 得到的数大于随机出来的数, 访问次数 + 1
if (r < p) counter++;
return counter;
}
官方的测试数据 (可以简单看成, counter = 5, 在 100 - 1000w 次的调用, lfu_log_factor 不同取值下, 最终的 counter 的值)
| lfu_log_factor 取值 | 100 次 | 1000 次 | 10w 次 | 100w 次 | 1000w 次 |
|---|---|---|---|---|---|
| 0 | 104 | 255 | 255 | 255 | 255 |
| 1 | 18 | 49 | 255 | 255 | 255 |
| 10 | 10 | 18 | 142 | 255 | 255 |
| 100 | 8 | 11 | 49 | 143 | 255 |
lfu_log_factor 设置为 10 的情况下, 在 100w 次的访问中, 访问次数才达到为 255, 也就是最大值。
基本可以满足 10w 次的使用
3.3.3.1 counter 衰减机制
每个对象被返回时, counter 都会先进行一个衰减操作, 然后再通过上面的随机公式进行判断次数是否需要增加。
衰减的过程如下
unsigned long LFUDecrAndReturn(robj *o) {
// 右移 8 为, 也就是得的了高位的 16 位, 即 ldt, 得到上次记录的时间
unsigned long ldt = o->lru >> 8;
// 得到当前保存的次数
unsigned long counter = o->lru & 255;
// lfu_decay_time 衰减时间, 默认 1, 单位分钟
// 如果没有配置 lfu_decay_time, 则默认不进行衰减, counter 当前是多少就是多少
// 获取 2 次访问的时间差 / lfu_decay_time, 得到经过了多少个时间段
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
// 最新的次数 = 当前的次数 - 经过了多少个时间段, 小于 0 时, 设置为 0
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
// 距离上次访问相差多少分钟
unsigned long LFUTimeElapsed(unsigned long ldt) {
unsigned long now = LFUGetTimeInMinutes();
if (now >= ldt) return now-ldt;
return 65535-ldt+now;
}
3.3.3.2 对象的访问频率设计
Redis 每次通过 key 在数据库中查询对应的 value 时, 在找到时, 就会进行 lru 字段的更新
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 && !(flags & LOOKUP_NOTOUCH)) {
// 淘汰策略设置的的 LFU 策略
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
val->lru = LRU_CLOCK();
}
}
} else {
return NULL;
}
}
void updateLFU(robj *val) {
// 通过衰减机制, 得到最新的 counter
unsigned long counter = LFUDecrAndReturn(val);
// 通过随机公式, 得到最新的 counter
counter = LFULogIncr(counter);
// 将最新的 counter 和 当前时间保存到 lru 字段中
val->lru = (LFUGetTimeInMinutes()<<8) | counter;
}
3.4 Redis 内存淘汰策略的实现
Redis 的内存的实现方式都是通过随机采样 + 比较 lru 值决定是否淘汰的方式实现的。
大体过程如下:
- Redis 启动时, 会初始一个默认容量为 16 的待淘汰数据池 evictionPoolEntry (本质就是一个数组)
- 每个存入到 Redis 的对象 (redisObject) 都会在初始其 24 位的 lru 字段 (lru: 一个相对的访问时间, lfu: 一个相对的访问次数)
- 后面每次访问 Redis 的对象时, 更新其 lru 字段的值
- 同时每次执行一个 Redis 命令时, 就会判断一下当前的内存是否足够, 如果不够, 就计算出需要释放多少内存, 然后进行内存淘汰
内存淘汰的过程如下:
4.1 首次淘汰
从数据字典或过期字典 (由配置的淘汰策略决定) 中随机抽样选出最多 N 个数据放入到一个样例池。
数据量 N: 由 redis.conf 配置的 maxmemory-samples 决定, 默认值是 5。 配置为 10 将非常接近真实 LRU 效果。
采样参数 maxmemory-samples 配置的数值越大, 就越能精确的查找到待淘汰的缓存数据, 但是也消耗更多的 CPU 计算, 执行效率降低。
同时为了避免长时间找不到足够的数据填充样例池, 强制写死了单次寻找数据的最大次数是 maxsteps = N*10。
4.2 再次淘汰
遍历整个样例池, 遍历的对象通过 lru 计算处理的值, 只要比待淘汰数据池中的任意一条数据的小, 就将该数据填充至待淘汰数据池。
第一次淘汰时, 待淘汰数据池为空, 所以第一次淘汰时, 会将所有的样例数据填充到待淘汰数据池中, 这个池子后面就都会有数据, 一直存在着。
后续的淘汰时, 样例池 中的数据就有可能进入到待淘汰数据池中, 也有可能不进入。
4.3 执行淘汰
从待淘汰数据池的尾部向前找到第一个可以删除的 key (此时找到的 key 就是值最小/大的, 既空闲时间最大/访问次数最小/存活时间最小), 对其进行淘汰
4.4 继续淘汰
计算删除了一个 key 后内存释放了多少, 如果没达到要求的释放量, 就回到步骤 4.1 继续淘汰
3.4.1 Redis 内存淘汰策略的代码实现
入口: 每个命令的执行处
int processCommand(client *c) {
...
// 有设置最大内存 同时当前没有 lua 脚本超时的情况
if (server.maxmemory && !server.lua_timedout) {
// 有必要时, 尝试释放内存
int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
// 内存不够 同时执行的命令是变更命令 或者 当前的客户端开启了事务, 同时执行的命令不是 exec
if (out_of_memory && (c->cmd->flags & CMD_DENYOOM || (c->flags & CLIENT_MULTI && c->cmd->proc != execCommand))) {
flagTransaction(c);
// 响应 -OOM command not allowed when used memory > 'maxmemory’
addReply(c, shared.oomerr);
return C_OK;
}
}
...
}
int freeMemoryIfNeededAndSafe(void) {
// 当前有 lua 脚本执行超时或者真正加载数据, 返回成功
if (server.lua_timedout || server.loading) return C_OK;
// 是否内存如果有必要的话
return freeMemoryIfNeeded();
}
释放内存的核心函数
int freeMemoryIfNeeded(void) {
// 如果是从节点同时配置了从节点忽略内存配置, 直接返回
if (server.masterhost && server.repl_slave_ignore_maxmemory) return C_OK;
// mem_reported 保存了整个 Redis 已经使用的内存
// mem_tofree 经过计算本次应该释放的内存, 等于当前已经使用的内存 - 用于主从复制的复制缓冲区大小 - 配置的 maxmemory
// mem_freed 已经释放了多少内存
size_t mem_reported, mem_tofree, mem_freed;
long long delta;
// 从节点个数
int slaves = listLength(server.slaves);
// 判断当前的内存状态, 如果足够, 直接返回
if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)
return C_OK;
// 如果配置的策略为 noeviction
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
goto cant_free;
mem_freed = 0;
// 没有达到需要的内存大小, 继续循环
while (mem_freed < mem_tofree) {
static unsigned int next_db = 0;
sds bestkey = NULL;
int bestdbid;
redisDb *db;
dict *dict;
dictEntry *de;
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) || server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
// LRU + LFU + TTL 策略
// 淘汰池
struct evictionPoolEntry *pool = EvictionPoolLRU;
while(bestkey == NULL) {
// 遍历 16 个数据库
for (i = 0; i < server.dbnum; i++) {
db = server.db+i;
// 根据 volatile 或 all 选择对应的数据字典
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ? db->dict : db->expires;
// 获取字典的数据大小, keys 为当前数据库的 key 的数量
if ((keys = dictSize(dict)) != 0) {
evictionPoolPopulate(i, dict, db->dict, pool);
total_keys += keys;
}
}
// 没有可以处理的 keys
if (!total_keys) break;
// EVPOOL_SIZE = 16
for (k = EVPOOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
bestdbid = pool[k].dbid;
// 从数据库中获取对应的节点
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
de = dictFind(server.db[pool[k].dbid].dict, pool[k].key);
} else {
de = dictFind(server.db[pool[k].dbid].expires, pool[k].key);
}
// 释放缓存
if (pool[k].key != pool[k].cached)
sdsfree(pool[k].key);
pool[k].key = NULL;
pool[k].idle = 0;
// 找到的释放对象存在, 先跳出这次循环
if (de) {
bestkey = dictGetKey(de);
break;
} else {
// 不存在, 进行循环查找
}
}
}
} else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM || server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM) {
// random 策略
}
// 删除找到的 key
if (bestkey) {
db = server.db+bestdbid;
// 将 key 封装为 redisObject 对象
robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
// 传播 key 过期信息到主从复制和 AOF 文件
propagateExpire(db,keyobj,server.lazyfree_lazy_eviction);
// 获取当前的内存大小
delta = (long long) zmalloc_used_memory();
// 同步删除或异步删除 key
if (server.lazyfree_lazy_eviction) {
dbAsyncDelete(db,keyobj);
else
dbSyncDelete(db,keyobj);
}
// 计算本次释放的内存
delta -= (long long) zmalloc_used_memory();
mem_freed += delta;
// 释放创建的 key redisObject 对象
decrRefCount(keyobj);
keys_freed++;
// 如果有从节点, 推送缓冲区的数据
if (slaves) flushSlavesOutputBuffers();
// 支持异步清除 同时 清除了 16 个 key
if (server.lazyfree_lazy_eviction && !(keys_freed % 16)) {
// 再次判断内存情况, 如果内存足够了
if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
// 更新已经释放的缓存大小 = 需要释放的缓存大小
mem_freed = mem_tofree;
}
}
}
// 本次释放没有处理成功任何一个 key
if (!keys_freed) {
goto cant_free;
}
}
return C_OK;
cant_free:
// 没有内存可以分配了, 做唯一可以做的一件事: 检查是否有 lazyfree 线程在执行释放内存任务, 有进行等待
// 知道没有任务或者已有的内存达到了需要释放的内存
while(bioPendingJobsOfType(BIO_LAZY_FREE)) {
// 当前的内存达到了现在需要的释放的内存, 结束检查
if (((mem_reported - zmalloc_used_memory()) + mem_freed) >= mem_tofree)
break;
usleep(1000);
}
return C_ERR;
淘汰池的填充
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
int j, k, count;
// 采样结果数组, 最大容量为 mamemory_samples 的大小
dictEntry *samples[server.maxmemory_samples];
// 从 sampledict 字典中采样 server.maxmemory_samples 个 key 存放到 samples, 同时返回总共采样的多少个
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
for (j = 0; j < count; j++) {
unsigned long long idle;
sds key;
robj *o;
dictEntry *de;
de = samples[j];
key = dictGetKey(de);
if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) {
if (sampledict != keydict) de = dictFind(keydict, key);
o = dictGetVal(de);
}
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
// LRU 算法
idle = estimateObjectIdleTime(o);
} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
// LRU 算法
idle = 255 - LFUDecrAndReturn(o);
} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
// TTL 算法
idle = ULLONG_MAX - (long)dictGetVal(de);
} else {
serverPanic("Unknown eviction policy in evictionPoolPopulate()");
}
k = 0;
// 从 evictionPoolEntry 淘汰池中找到第一个闲置时间比当前淘汰 key 大的
while (k < EVPOOL_SIZE && pool[k].key && pool[k].idle < idle)
k++;
if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) {
// 如果找到的 key 比淘汰池中闲置时间最小的 key 还小, 同时淘汰池没有空间了, 则跳过这个 key
continue;
} else if (k < EVPOOL_SIZE && pool[k].key == NULL) {
// 插入的位置为空, 直接进入到下面的赋值节点
} else {
// 核心就是将找到的位置 k 空出来
// 最后的位置为空
if (pool[EVPOOL_SIZE-1].key == NULL) {
// 将原本 k 位置和后面的数据向后移动 1 位
sds cached = pool[EVPOOL_SIZE-1].cached;
memmove(pool+k+1, pool+k, sizeof(pool[0])*(EVPOOL_SIZE-k-1));
pool[k].cached = cached;
} else {
// 插入的位置不为空
// 将原本 k 位置前面的数据往前移动 1 位, 原本的第一位丢弃
k--;
sds cached = pool[0].cached;
if (pool[0].key != pool[0].cached) sdsfree(pool[0].key);
memmove(pool,pool+1,sizeof(pool[0])*k);
pool[k].cached = cached;
}
}
// 把找到的 key 放到 k 的位置
int klen = sdslen(key);
// EVPOOL_CACHED_SDS_SIZE = 255
if (klen > EVPOOL_CACHED_SDS_SIZE) {
// 创建一个新的 key 赋值给 pool[k].key
pool[k].key = sdsdup(key);
} else {
// 从 key 中拷贝 klen + 1 的长度到 pool[k].cached
memcpy(pool[k].cached,key,klen+1);
sdssetlen(pool[k].cached,klen);
pool[k].key = pool[k].cached;
}
pool[k].idle = idle;
pool[k].dbid = dbid;
}
}
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count) {
unsigned long j;
unsigned long tables;
unsigned long stored = 0, maxsizemask;
unsigned long maxsteps;
// 字典中的数据量小于需要的个数, 取的个数变为字典的数据大小
if (dictSize(d) < count) count = dictSize(d);
// 最大次数 = 次数 * 10
maxsteps = count*10;
/* 如果字典在 rehash 中, 尝试 count 一样次数的 rehash */
for (j = 0; j < count; j++) {
if (dictIsRehashing(d))
_dictRehashStep(d);
else
break;
}
// 获取总的 HashTable 个数, 如果在 rehash 中就是 2 个, 否则 1 个
tables = dictIsRehashing(d) ? 2 : 1;
// 获取数组大小的掩码, 用于计算索引值
maxsizemask = d->ht[0].sizemask;
if (tables > 1 && maxsizemask < d->ht[1].sizemask)
maxsizemask = d->ht[1].sizemask;
// 随机获取一个位置
unsigned long i = random() & maxsizemask;
unsigned long emptylen = 0;
// 获取到的个数没达到需要的个数 或者尝试的次数还没达到 0
while(stored < count && maxsteps--) {
for (j = 0; j < tables; j++) {
// 如果字典在 rehash 中, 同时当前处理的是第一个字典, 处理的位置小于 rehash 下次处理的位置,
// 则跳过这个位置, 直接到 rehash 下次处理的位置
// 因为第一个字典 rehash 下次处理的位置前的数据都迁移到第二个字典中了
if (tables == 2 && j == 0 && i < (unsigned long) d->rehashidx) {
// 防止获取数据的位置 i 超过第二个字典的大小
if (i >= d->ht[1].size)
i = d->rehashidx;
else
continue;
}
// 超过了数组的长度
if (i >= d->ht[j].size) continue;
// 获取对应位置的数据
dictEntry *he = d->ht[j].table[i];
// 对应的位置为 null
if (he == NULL) {
emptylen++;
// 获取 null 数据的次数大于 5 次 同时 大于需要的过期 key 的个数
if (emptylen >= 5 && emptylen > count) {
// 重新计算获取的位置 i, 重新获取
i = random() & maxsizemask;
emptylen = 0;
}
} else {
emptylen = 0;
while (he) {
// he 本身是链表, 计算从链表中获取到的个数, 够了结束, 不够就 i+1, 从字典的下一个位置继续获取
*des = he;
des++;
he = he->next;
stored++;
if (stored == count) return stored;
}
}
}
i = (i+1) & maxsizemask;
}
return stored;
}
dictGetSomeKeys 函数简单理解就是, 通过 random() 得到一个随机数, 这个随机数 & 数组大小的掩码, 得到一个位置, 从这个位置向后获取 count 个过期 key。
这个处理的过程中
- 有可能字典在 rehash 中, 数据分布在 2 个字典中, 所以有时第一个字典获取不到需要到第二个字典获取
- 需要的过期 key 的个数小于等于 5 个, 通过计算得到的位置获取到的数据连续都为 null, 则重新通过 random() 计算一个新的位置
- 为了防止长时间的需要, 在外面还计算了最大的循环次数
从上面的代码实现可以看出, Redis 内部对 LRU + LFU 的实现都是不是很正式的实现, 带有一定的误差和随机性。
其本身考虑主用是从性能上做的折中。比如传统的 LRU 算法, 需要将所有的数据维护一个双向链表
- 访问节点, 如果节点存在, 则将该节点移动到链表的头节点, 并返回节点值, 不存在就返回 null
- 新增节点, 节点不存在, 就在链表的头部新增节点, 如果节点存在, 则更新节点数据, 然后将节点移动到链表的头节点
需要消耗的内存在维护链表的 + 节点的挑战, 对于一个大规模的数据, 这个消耗是非常大的。
所以 Redis 采用了其思想, 通过另外的方式达到类似的效果。
4 附录: Redis 几个对象的介绍
4.1 Redis 中的字典
4.2.1 HashTable
存储在 Redis 中的基本都是键值对, 而这种键值对存储, 同时可以通过 key 快速查询到对应的 value, 最合适的实现就是 HashTable 了。
而实现 HashTable 的底层结构,基本就是一个数组或者链表, 同时为了解决 hash 冲突, 数组或链表的每个节点定义为一个链表。
Redis 中对 HashTable 的实现也是如此, 大体如下

Redis 中实现的 HastTable 叫做 dictht (Dictionary Hash Table)
对应的定义如下:
typedef struct dictht {
// 存放节点的数组
dictEntry **table;
// HashTable 的大小, 2 的幂次方
unsigned long size;
// HashTable 的大小掩码, 用于计算索引值
unsigned long sizemask;
// HashTable 中已经使用的节点个数
unsigned long used;
} dictht;
真实存储数据的链表节点的定义如下:
typedef struct dictEntry {
// 存储的键值对的 key
void *key;
// 存储的键值对的 value
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 指向下一个节点
struct dictEntry *next;
} dictEntry;
key + v(value) + next 一个简单的链表定义。
有点特殊的就是对应着 value 属性的 v 的定义是一个联合体, 会在不同场景下使用不同的字段,
比如一个键值对的过期时间就存放在 s64 中, 这个 value 存放的值就放在 val 中。
一个 dictEntry 的字段存放内容大体如下:

4.2.2 字典
在使用 HashTable 时, 都需要提前声明好容量, 而随着程序的运行, 存放到 HashTable 的数据会越来越多, 最终达到上限, 这时就需要进行扩容了。
在 Java 的 HashMap 的扩容过程
- 创建一个更大容量的数组
- 将 HashMap 中旧数组一次性迁移到新的数组中
- 清除掉旧数组
这个扩容没多大问题, 但是放到 Redis 中合适吗?
- Redis 是一个存内存的数据库, 所有的数据都存放在内存中, 基本是 GB 级别的数据量, 每次扩容迁移的数据量很多
- Redis 是一个单线程的数据库, 一次只能处理一个事情, 如果全力在做扩容, 那么其他的请求将无法处理
所以 Redis 采用了一种 渐进式 rehash 的方法解决扩容缩容的问题, 过程如下
- 维护 2 个 dictht, 一个是真实存储数据的 HashTable A, 一个是扩容后存储数据的 TableTable B + 一个 rehash 位置的索引, 初始值为 0
- 在 rehash >=0 期间, 每次对 HashTable 进行操作, 除了正常的操作外, 还会将 A rehash 位置的数据都迁移到 B, 然后 rehash + 1
- 随着对 HashTable 的不断操作, 最终 A 中的数据都会迁移到 B, 这时将 rehash 设置为 -1
基于上面的渐进式 rehash 分析, 实际是需要 2 个 dictht, 所以 Redis 在此至上多封装了一层
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; // 2 个 HashTable
long rehashidx; // rehash 的索引
unsigned long iterators;
} dict;
这个就是 Redis 中的字典, 用于存储键值对的结构。
在将这个结构放到一个 redisDb 就是我们常见的 Redis 数据库了
typedef struct redisDb {
dict *dict;
dict *expires;
....
} redisDb;
redisDb 就是我们常说的 Redis 16 个数据库的定义了。 每个数据库中都有 2 个字典
- dict 正常的字典, 存储没有设置过期时间的键值对
- expires 过期字典, 存储设置了过期时间的键值对
4.2 Redis 的内存待淘汰池
struct evictionPoolEntry {
unsigned long long idle; // 对象空闲时间 (使用的算法是 LFU 则是逆频率)
sds key; // 待淘汰的键值对的 key
sds cached; // 缓存的 key 名称 SDS 对象
int dbid; // 待淘汰键值对的 key 所在的数据库 ID
};
5 参考
Redis源码解析-LRU
Redis内存兜底策略——内存淘汰及回收机制