Large language model inference optimizations on AMD GPUs — ROCm Blogs
大型语言模型(LLMs)已经改变了自然语言处理和理解,促进了在多个领域中的众多人工智能应用。LLMs在包括AI助手、聊天机器人、编程、游戏、学习、搜索和推荐系统在内的多个领域具有各种有前景的用例。这些应用利用LLMs的能力提供个性化和互动的体验,增强了用户的参与度。
LLMs使用变换器架构来解决梯度消失和爆炸的问题。该架构允许轻松并行化自我关注,使其能够有效地利用多个GPU。其他架构,如递归神经网络(RNN)及其变体(例如LSTM和GRU),在处理长单词序列时存在困难。
尽管具有令人印象深刻的能力,但像GPT和Llama这样的LLMs在用于商业应用之前需要积极的优化,由于它们的大参数规模和自回归顺序处理行为。已经做了许多努力,通过使用GPU的计算容量(TFLOPs)和内存带宽(GB/s)来提高LLMs的吞吐量、延迟和内存占用。
我们将通过比较AMD的MI250和MI210 GPU上的Llama-2-7B和Llama-2-70B模型的性能指标来讨论这些优化技术。
模型特点:Llama2-7b和Llama2-70b
Llama2-7b和70b模型能够处理32,000个词汇。这些模型可以处理最大长度为4,096个令牌序列。Llama2通过采用以下新特征优化了其训练和推理性能:
• *Sigmoid线性单元(SiLU)激活*:替换了常用的线性整流单元(ReLU),以减少消失的梯度问题,实现更平滑的激活。
• *旋转位置嵌入*:减少了经典绝对位置嵌入层的计算成本,同时保持了令牌序列的位置信息。
• *预归一化*:LlamaRMSNorm模块归一化了*输入*而不是*输出*,这减少了梯度消失和爆炸问题。
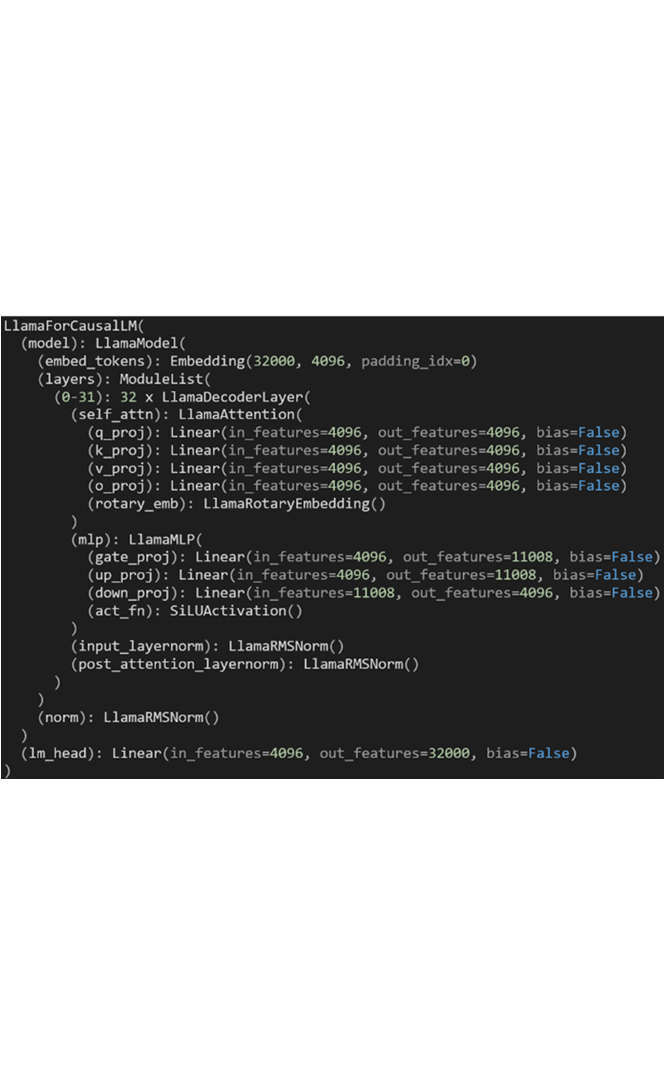
在Llama-2-7b模型中,自我关注模块中有32个注意力头;每个头有128维。多层感知器(MLP)模块的中间大小有11,008,它由三层组成:`gate_proj`、`up_proj`和`down_proj`。

基于它们的行为,大型语言模型(LLMs)被归类为以下几种:
• *遮蔽语言模型(MLM)*:在提供的上下文词汇之间预测一个新的遮蔽词。BERT就是MLM的一个例子。
• *因果语言模型(CLM)*:在提供的上下文词汇之后预测下一个词。一个众所周知的CLM例子是GPT文本生成。CLM也被称为自回归的标记生成模型,因为其按顺序处理行为。
在这篇博客中,我们更专注于讨论Llama2 CLM。

在CLM(因果语言模型)中,生成令牌分为以下两个阶段:
• *首个令牌生成时间(TTFT)*:生成第一个令牌所需要的时间。填充前延迟被定义为跨请求的平均TTFT。在下面的图中,TTFT是从输入提示“The largest continent”生成“in”所需要的时间。
• *每个输出令牌的时间(TPOT)*:以自回归方式生成每个输出令牌所花费的时间。输出解码延迟被定义为跨请求的平均TPOT,通常使用输出解码阶段所需的时间来估算。在下图中,TPOT是“the”的解码延迟。
TTFT和TPOT被用来计算CLM中的延迟:
延迟 = TTFT + TPOT * (max_new_tokens - 1)
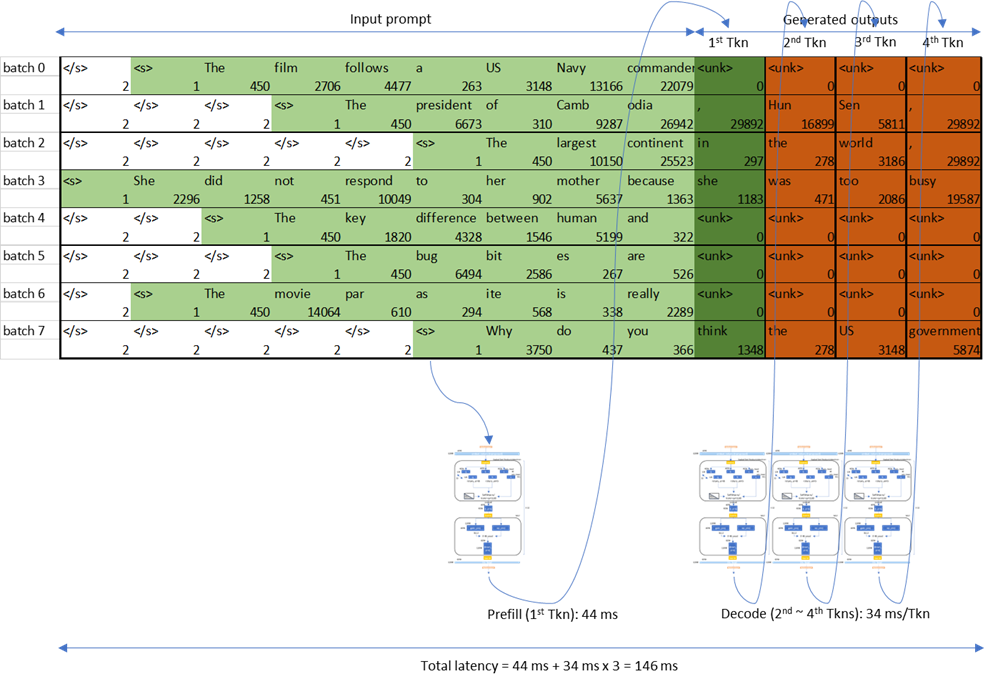
在*预填充*阶段之后的输入维度,在词嵌入之后,与*批次大小*输入序列长度*成比例。预填充阶段的令牌是同时被处理的。然而,*输出解码*阶段的输入,在词嵌入之后,与*批次大小*成比例;这一阶段的令牌是顺序处理的。这就是为什么当批次大小为1时输出解码操作由高且窄的GEMM(或者是GEMV)组成的原因。
为了简单起见,我们采用了贪婪解码方式来生成令牌,它已知是从输出对数中解码令牌时开销最小的。在实际的聊天机器人场景中,允许生成丰富和出人意料的输出令牌时,最好考虑基于采样的解码以及更高的束宽度。但是,在贪婪解码方案中,自回归的CLM从模型输出对数生成排名第一的令牌。
设备特性:MI210
AMD的Instinct™ MI210在FP16数据类型下的最大计算能力为181 TFLOPs。要完全利用矩阵核心的性能,GEMM的矩阵尺寸应足够大。具有大批次的LLM预填充解码阶段使用大输入矩阵,并且能从矩阵核心的高性能中获益。使用MI210,在提示序列长度和批次大小都很大的预填充阶段,GEMM操作是计算受限的。
MI210能够提供最大的双倍数据速率(DDR)内存带宽,达到1.6 TB/s。输出解码顺序处理令牌。这种自回归解码只有序列长度的一个维度(这使得高且窄的GEMT或GEMV)其中操作是内存受限的。由于LLM输出令牌生成的这种顺序性质,输出解码从DDR带宽中受益。
MI250由MI210的两个图形计算模块(GCD)组成。因此,MI250具有MI210两倍的计算能力、内存大小和内存带宽。LLM可以在MI250的两个硅片上用张量并行(TP)、流水线并行(PP)或数据并行(DP)的模型并行方式进行赋值。这种数据并行可以使LLM的吞吐量翻倍,同时存在两倍模型参数复制的开销。由于缺少开销,张量并行广泛被使用,因其有能力将更大的LLM适配到具有一些集合操作同步开销的高容量MI250 DDR上。

在前面的图表中,请注意,单个MI250 GCD的瓶颈线与MI210的相似。
软件设置
在主机上安装ROCm
要在主机上安装ROCm 6.0,请参阅[安装指南](ROCm installation options — ROCm installation (Linux))。
设置docker
要设置官方的[PyTorch ROCm Docker容器](https://hub.docker.com/r/rocm/pytorch/tags),请使用以下命令:
docker run -it --network=host --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 8G --name llm_optimization rocm/pytorch:rocm6.0_ubuntu22.04_py3.9_pytorch_2.0.1配置库和工具集
运行以下命令来安装PyTorch 2.3夜间版本:
pip3 uninstall torch torchvision torchaudio pytorch-triton-rocm -y
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm6.0有关库的设置,请参考Hugging Face的transformers。
有关工具集的设置,请参考[文本生成推理 (TGI)]。
在MI210上Llama-2-7b的优化比较
• Prefill 延迟

• 输出解码延迟
默认机器学习框架
PyTorch 2支持两种运行模式:急切模式和编译模式。急切模式是PyTorch的默认模式,在这种模式下,模型的运算符会在运行时遇到时顺序执行。编译模式在LLM推理优化技术中有所涵盖。
为了运行LLM解码器模型(例如,Llama-2),Hugging Face提供了transformers库在PyTorch之上运行模型。
transformers库在其[APIs]中使用多种令牌生成选项作为参数。在这篇博客中,为了公平地比较每种优化的性能,采用了这些选项:
• *预填充*:使用2048序列长度的提示符,随着批量大小的增加,预填充延迟会增加,因为预填充期间的大型GEMM计算是计算受限的。
• *输出解码*:当批量大小增加时,输出解码延迟并不会大幅增加,因为这个阶段的GEMM的算术强度仍然受到内存带宽的限制。
LLM推理优化技术
在这里,我们讨论各种LLM推理优化技术。
PyTorch编译模式
在[PyTorch编译模式]中,模型被合成为图形,然后降级为主要运算符。这些运算符使用TorchInductor进行编译,它使用OpenAI的Triton作为GPU加速的基础模块。PyTorch编译模式的一个优点是其GPU内核是用Python编写的,这使得修改和扩展它们变得更容易。由于模型运算在运行前就已融合,PyTorch编译模式通常会提供更高的性能,这使得部署高性能内核变得容易。
为了在PyTorch编译模式下运行LLM解码器模型(例如,Llama2),必须显式地将模型的特定层次指定为编译目标。PyTorch编译模式要求在LLM解码器模型的输入批量大小和序列长度在运行时可能改变的情况下重新编译。为了支持动态输入形状的重新编译,请设置参数`dynamic=True`。
for i in range(model.config.num_hidden_layers):
model.model.decoder.layers[i].self_attn = torch.compile(model.model.decoder.layers[i].self_attn, backend="inductor", mode="default", dynamic=True)• *预填充*:预填充延迟显著降低。但是,对于LLM解码器模型,它仍然会因为各种批量大小和输入序列长度而遭受巨大的初始重新编译开销。预填充延迟是在初始重新编译(预热)之后测量的。
• *输出解码*:输出解码延迟略有改善,因为模型部分编译了。然而,由于部分密钥/值缓存的动态形状,图形回落到了急切模式。有一种努力来解决这个问题(被称为[静态密钥/值缓存](Accelerating Generative AI with PyTorch II: GPT, Fast | PyTorch))。静态密钥/值缓存与`torch.compile`一起使用时,可以显著提高输出解码性能,但我们的博客并未涵盖此内容。
Flash Attention v2
Flash Attention(flash_attention)算法旨在解决在transformer的多头注意力(MHA)模块中,查询、密钥和值组件所需的大量内存移动问题。通过将部分查询平铺并存储在更快的缓存内存中,而不是在MHA计算期间不断从较慢的外部DDR内存中读取,这一目标得以实现。`flash_attention v2`](https://arxiv.org/abs/2307.08691)可以在长输入序列长度上最大化并行性,与原生的MHA相比,可以显著提升性能。
您可以无缝地使用最新的Hugging Face transform库中的*flash_attention v2模块*来自ROCm。
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(model_id, attn_implementation="flash_attention_2")• *预填充*:Flash Attention模块显著降低了大批量大小和长序列长度的预填充处理延迟,因为MHA矩阵的维度与这些成比例。这导致了flash attentions的更大收益。
• 输出解码:- flash_attention在输出解码阶段效果不明显,因为序列长度仅为1。
内存高效多头注意力
内存高效的多头注意力(Xformers)是Meta提供的一系列可定制模块,用于优化变换器模型。Xformers的主要特点是内存高效的多头注意力(MHA)模块,它可以在多头注意力处理过程中显著减少内存流量。这个模块采用与`flash_attention`相似的算法来减少DDR读写带宽。
你可以无缝地将Xformers的内存高效MHA模块适用于ROCM集成到Hugging Face的变换器库中。
- *预填充*:与`flash_attention v2`出于相同的原因,内存高效的MHA在处理大批量尺寸和长序列长度时也显著减少了预填充处理延迟。
- *输出解码*:Xformers在输出解码阶段效果不明显,因为序列长度仅为1。
分页注意力(vLLM)
分页注意力(paged_attention)是vLLM推理系统的一种算法,可以有效减少内存消耗,并在输出解码阶段将延迟降低两到四倍。分页注意力通过使用虚拟内存和分页来管理输出解码阶段的键值缓存(K-V缓存),减少内存碎片。传统的K-V缓存会为输出的最大令牌长度(根据模型的不同为2,048或4,096)预分配内存,如果实际解码长度更短,就可能导致内存碎片。这种基于分页的虚拟内存可以在波束搜索大和多个请求并行运行时节省K-V缓存内存。vLLM的paged_attention模块适用于ROCM目前是可用的。
- *预填充*:分页注意力在预填充阶段效果不明显,因为这个阶段不使用K-V缓存。
- *输出解码*:分页注意力可以显著降低解码延迟。
PyTorch TunableOp
PyTorch TunableOp允许你使用高性能的rocblas和hipblaslt库进行GEMM。它会对LLM进行性能分析,并准备每个MHA和MLP模块的最佳性能GEMM内核。在运行时,会启动最佳性能GEMM内核,而不是PyTorch内建的GEMM内核。
PyTorch TunableOp目前已经可用。
- *预填充*:结合`flash_attention v2`,PyTorch TunableOp在不同批量大小下显示出显著的性能提升。
- *输出解码*:结合分页注意力,PyTorch TunableOp也显著降低了高瘦GEMM(或GEMV)的延迟。因此,输出解码性能最大限度地受益于rocBLAS和hipBLASLt GEMMs。
多GPU LLM推理优化
- 预填充延迟

• 输出解码延迟

Hugging Face 文本生成推理
在进行多GPU推理和训练的扩展时,需要使用模型并行技术,例如张量并行(TP)、流水线并行(PP)或数据并行(DP)。张量并行(TP)因为不会导致流水线泡沫而被广泛使用;数据并行(DP)虽然吞吐量高,但需要将参数的副本复制到GPU的DDR中。
在这篇博客中,我们使用TP技术将模型分布在多个GPU上,并使用Hugging Face的文本生成推理(TGI)来测量多GPU的大型语言模型(LLM)推理性能。Hugging Face的TGI实现包括兼容ROCm的`flash_attention`和`paged_attention`,与PyTorch TunableOp的兼容性,以及对ROCm启用的量化(如GPTQ)的支持,这些特点使得它成为一个好选择。
一台服务器配备了4块MI250显卡,总共拥有8个图形计算核心(GCDs)。每个GCD拥有64 GB的HBM内存。


为了充分利用多个MI250 GPU,您需要考虑GPU GCDs之间的互连带宽,因为GCD间的连接吞吐量是不均匀的。例如,在TP=4的情况下,联合使用GCD#0、1、4、6将提供最佳性能,因为集体操作(如全归约或全集合)在TP中会造成较少的同步开销。
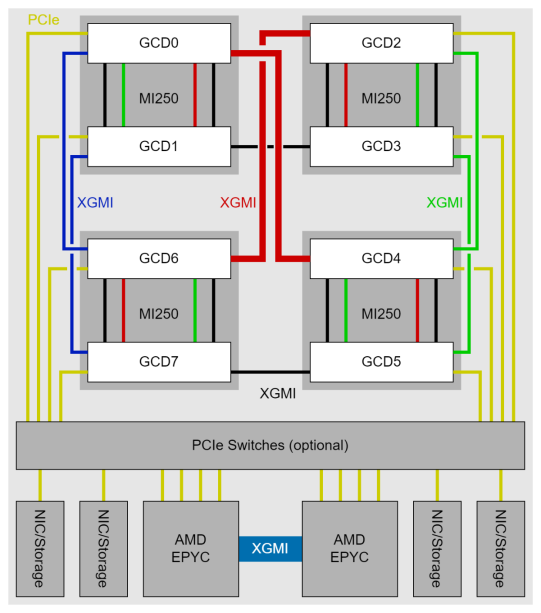

在启用非统一内存访问(NUMA)平衡时,GPU必须等待来自页面错误的内存管理单元(MMU)的预先通知器变更。因此,我们推荐禁用NUMA平衡,以避免定期自动平衡干扰GPU操作。
echo 0 > /proc/sys/kernel/numa_balancing• 填充阶段(Prefill) 和 输出解码阶段(Output decoding):使用8 GCDs (TP=8)的案例展示了比使用4 GCDs (TP=4)更好的填充和输出解码延迟。延迟增强并没有翻倍,因为同步每一层的多头自注意力(MHA)和多层感知机(MLP)的集体操作也是一个巨大的延迟瓶颈。
总结
在这篇博客中,我们介绍了几种软件优化技术,用于在AMD CDNA2 GPUs上部署最先进的大型语言模型(LLMs)。这些包括PyTorch 2编译、Flash Attention v2、`paged_attention`、PyTorch TunableOp以及多GPU推理。这些优化技术已经被AI社区广泛采纳。使用这些优化,根据批量大小和输入序列长度,你可以享受高达三倍的即开即用加速。