240618-Hive笔记-4
4.2 Insert
4.2.1 将查询结果插入表中
1) 语法
INSERT (INTO | OVERWRITE) TABLE tablename [PARTITION
(partcol1=val1,partcol2=val2 ...)] select_stamement;关键字说明:
(1) INTO: 将结果追加到目标表
(2) OVERWRITE: 用结果覆盖原有数据
2) 案例
(1) 新建一张表
hive (default) >
create table student1(
id int,
name string
)
row format delimited fields terminated by '\t'(2) 根据查询结果插入数据
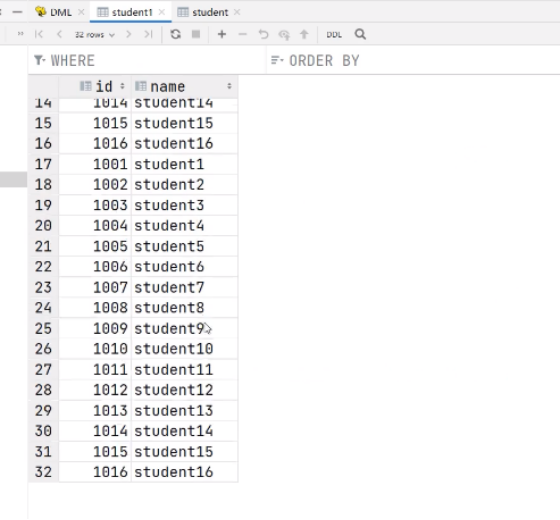
hive (default) > insert overwrite table student3
select
id,
name
from student;
4.2.2 将给定Values插入表中
1) 语法
INSERT (INTO | OVERWRITE) TABLE tablename [PARTITION
(partocol1[val1],partcol2[=val2] ...] VALUES values_row [,
values_row ...]2) 案例
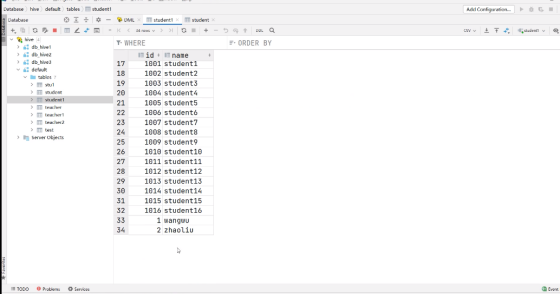
hive (default) > insert into table student1
values(1,'wangwu'),(2,'zhaoliu');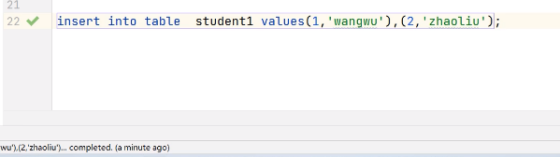
追加成功:
4.2.3 将查询结果写入目标路径
1) 语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory
[ROW FORMAT row_format] [STORED AS
file_format] select_statement;2) 案例
insert overwrite local directory '/opt/module/datas/student' ROW
FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
select id,name from student;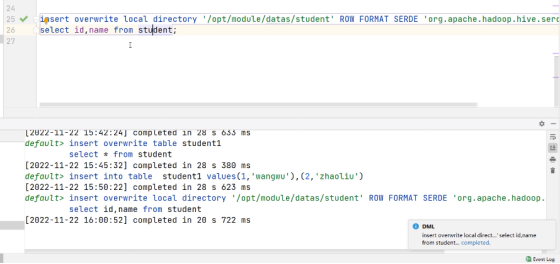
4.2 Export & Import
Export导出语句可将表的数据和元数据信息一并到处的HDFS路径,Import可将Export导出的内容导入Hive,表的数据和元数据信息都会恢复。Export和Import可用于两个Hive实例之间的数据迁移。
1) 语法
--导出
EXPORT TABLE tablename TO 'export_target_path'
--导入
IMPORT [EXTERNAL] TABLE new_or_original_tablename FROM 'source_path' [LOCATION 'import_target_path']2) 案例
--导出
hive>
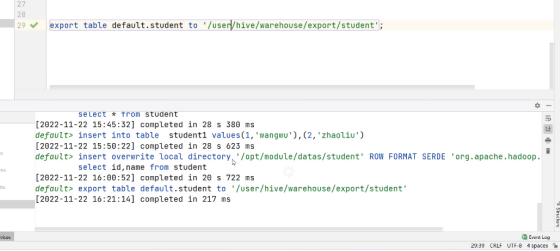
export table default.student to '/user/hive/warehouse/export/student';
--导入
hive>
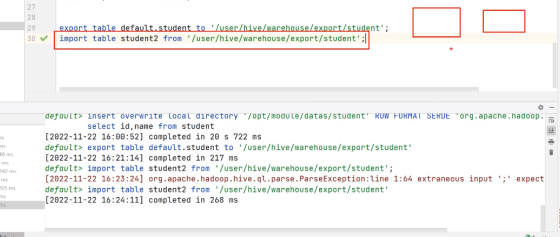
import table student2 from '/user/hive/warehouse/export/student';执行export代码:
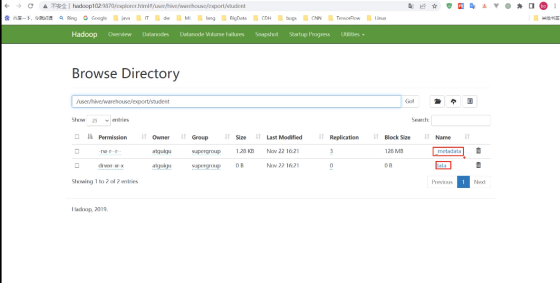
查看结果:
执行Import代码:
第 6 章 查询
6.1 基础语法
1) 官网的地址:
LanguageManual Select - Apache Hive - Apache Software Foundation
2) 查询语句语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference -- 从什么表查
[WHERE where_condition] -- 过滤
[GROUP BY col_list] -- 分组查询
[HAVING col_list] -- 分组后过滤
[ORDER BY col_list] -- 排序
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number] -- 限制输出的行数6.2 基本查询(Select ... From)
6.2.1 数据准备
(1) 原始数据
1.在/opt/module/hive/datas/路径上创建dept.txt文件,并赋值如下内容:
部门编号 部门名称 部门位置id
[atguigu@hadoop102 datas]$ vim dept.txt
10 行政部 1700
20 财务部 1800
30 教学部 1900
40 销售部 17002.在/opt/module/hive/datas/路径上创建emp.txt文件,并赋值如下内容:
员工编号 姓名 岗位 薪资 部门
[atguigu@hadoop102 datas]$ vim emp.txt
7369 张三 研发 800.00 30
7499 李四 财务 1600.00 20
7521 王五 行政 1250.00 10
7566 赵六 销售 2975.00 40
7654 侯七 研发 1250.00 30
7698 马八 研发 2850.00 30
7782 金九 \N 2450.0 30
7788 银十 行政 3000.00 10
7839 小芳 销售 5000.00 40
7844 小明 销售 1500.00 40
7876 小李 行政 1100.00 10
7900 小元 讲师 950.00 30
7902 小海 行政 3000.00 10
7934 小红明 讲师 1300.00 30创建文件dept.txt :

(1) 创建部门表
hive (default)>
create table if not exists dept(
deptno int, -- 部门编号
dname string, -- 部门名称
loc int -- 部门位置
)
row format delimited fields terminated by '\t';
(2) 创建员工表
hive (default)>
create table if not exists emp(
empno int, -- 员工编号
ename string, -- 员工姓名
job string, -- 员工岗位(大数据工程师、前端工程师、java工程师)
sal double, -- 员工薪资
deptno int -- 部门编号
)
row format delimited fields terminated by '\t';
(3) 导入数据
hive (default)>
load data local inpath '/opt/module/hive/datas/dept.txt' into table dept;
load data local inpath '/opt/module/hive/datas/emp.txt' into table emp;