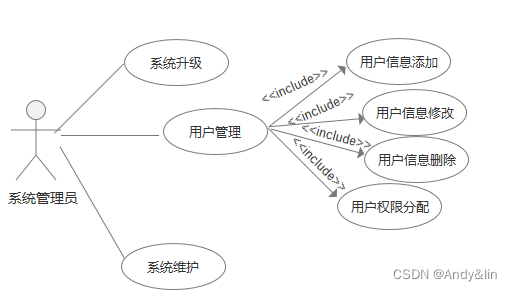
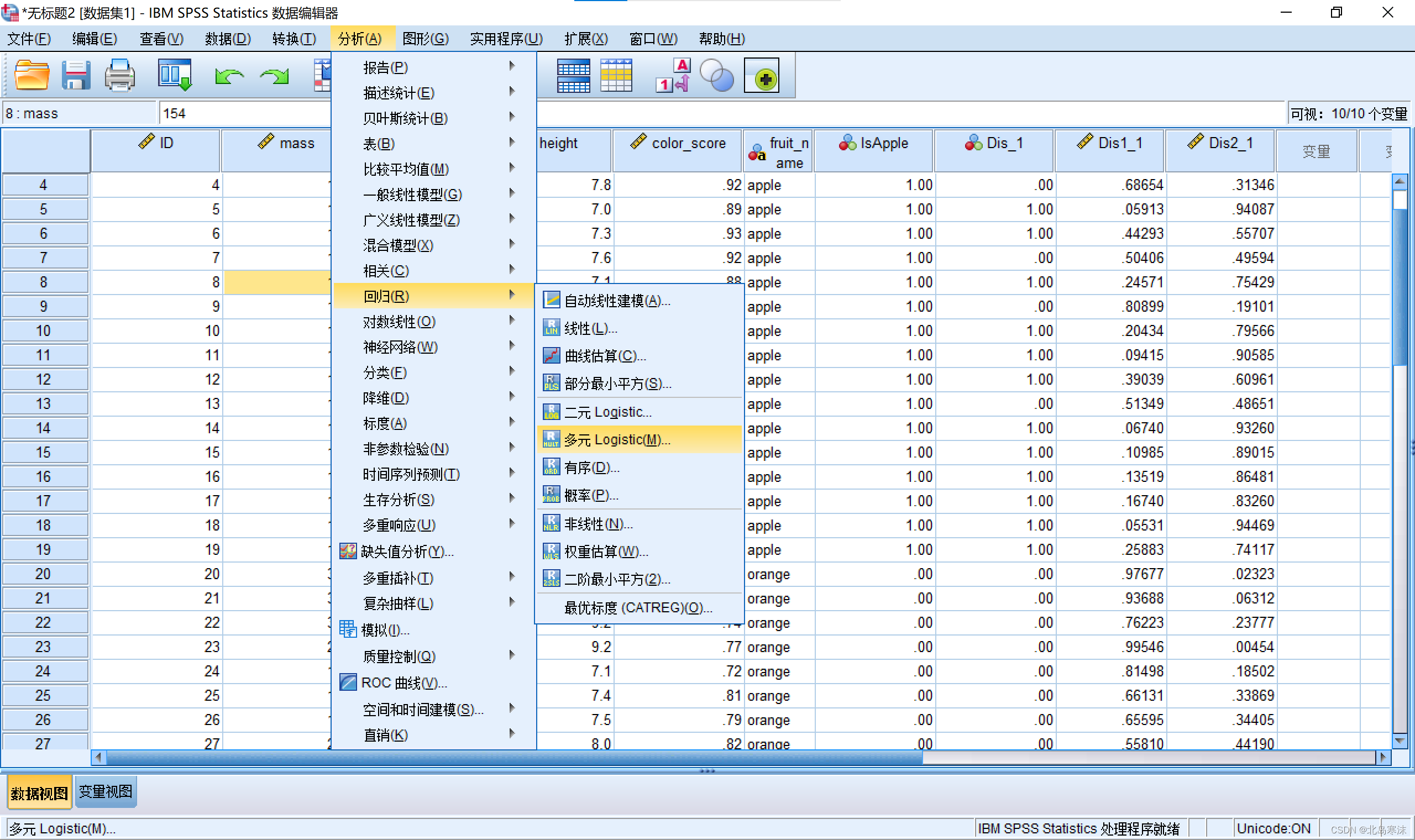
我将这个链接池和批量入库封装了一个工具类上传了pypi,可以直接import使用
使用也较为简单,导入PooledDBhelper的DBhelper,调用DBhelper.PooledDBhelper()方法传入数据库链接信息创建一个链接池即可
pip install PooledDBhelper==1.0.0
-------------------------------
正文
众所周知,不管是爬虫也好后端也好,Python开发最常用的ORM就是sqlAlchemy,他很完善很强大,但是为了更快更轻,不用学习新的语法,而且可以理解一些sql概念而不是直接使用工具。
我们先来维护一个链接池,然后做一个sqlhelper工具类,实现更简单好用的数据存储入库。
数据库:现在的数据库很多,关系型数据库 MySQL(MariaDB), PostgreSQL 等,NoSQL数据库,还有NewSqL数据库。但MySQL(Mariadb)从易获取性、易使用性、稳定性、社区活跃性方面都有较大优势,所以,我们在够用的情况下都选择MySQL。
数据库客户端模块:然后我们选择PyMySQL这个库,它可以和Python 3的异步模块aysncio结合起来,形成了aiomysql 模块,后面我们写异步爬虫时就可以对数据库进行异步操作了。链接池模块: 我们考虑到创建和释放数据库连接是一个很耗时的操作,所以通常创建一个连接池,需要就获取,用完则放回连接池。这个模块有主要有两个模块PooledDB和PersistentDB,我们选择PooledDB
一个简单的链接池案例:引入pymysql和PooledDB,实例化PooledDB在参数中传入数据库链接配置,creator参数选择pymysql,得到一个链接池,使用链接池的connection()方法获取一个链接,使用链接的cursor()方法获得游标,然后execute()执行sql,从cursor.fetchall()中获取结果即可。下面task函数就是简单的使用,然后如果需要我们可以开线程去跑。
import pymysql
from dbutils.pooled_db import PooledDB
test_POOL=PooledDB(
creator=pymysql,
maxconnections=10,
mincached=2,
blocking=True,
host='127.0.0.1',
# sshtunnel='',
port=3306,
user='root',
password='root',
database='jxc',
charset='utf8'
)
def task(num):
sql = "SELECT * FROM duty"
conn=test_POOL.connection()
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute(sql)
data = cursor.fetchall()
print(num, '-' * 8)
for i in data:
print(i)
conn.close()
from threading import Thread
for i in range(32):
t=Thread(target=task,args=(i,))
t.start()查询的方法就像上面这样,接下来我们写一个类
包含创建链接池和一些数据库操作,具体解释一下解释使用dbutils库 传入数据库链接信息创建一个链接池,我这用了一个{}接受参数也方便后面做扩展。
import pymysql
from pymysql.cursors import DictCursor
from dbutils.pooled_db import PooledDB
class PooledDBhelper:
def __init__(self, dbconfig: {}):
'''
:param dbconfig: {
'host': '192.168.0.1',
'user': 'username',
'password': 'password',
'port': 3306,
'db': 'db_name'
}
'''
self.pool = self.connectionPool(dbconfig)
def connectionPool(self, dbconfig):
try:
pool = PooledDB(
creator=pymysql,
maxconnections=10, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
# 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
blocking=True,
host=dbconfig['host'],
user=dbconfig['user'],
passwd=dbconfig['password'],
db=dbconfig['db'],
cursorclass=DictCursor
)
return pool
except Exception as e:
raise Exception("数据库链接失败(create connect failed):{}".format(e))写完这个类我们就可以通过 pool=PooledDBhelper(dbconfig)获得一个链接池了,这个池一般开局注册一个作为全局变量,而不是每次数据库操作新注册一个池子。
if __name__ == "__main__":
pool=PooledDBhelper({
'host': '192.168.0.1',
'user': 'username',
'password': 'password',
'port': 3306,
'db': 'db_name'
})然后接下来我们继续给这个类添加功能,常用的两个执行一个sql语句获取一条结果(或插入单条)和执行一个sql语句获取多条结果这个直接就写了,分别用了两种写法
def task(self, sql, *args):
'''
fetchall
:param sql:
:param args:
:return:
'''
conn = self.pool.connection()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
try:
cursor.execute(sql, args)
data = cursor.fetchall()
except Exception as e:
raise ("SQL execution failure", e)
else:
return data
finally:
cursor.close()
conn.close()
def fetchone(self, sql):
with self.pool.connection() as connection:
connection.autocommit = True
with connection.cursor() as cursor:
'''
在创建连接的时候,增加参数 autocommit = 1 ,当发生update等操作时,会实时更新到数据库内。避免 conn.commit() 来提交到数据库
如果没有设置自动提交,也没有手动提交,当进行插入或更新等操作时,只在本地客户端能看到更新,在其他客户端或数据库内,数据无变化。
适合实时操作,随时少量、频繁的更新'''
row=cursor.execute(sql)
result = cursor.fetchone()
connection.commit()
return result最后我们做最主要的一个功能,因为爬虫的数据库操作,大部分都是入库,我们做一个批量入库,
因为大部分时候我们爬的数据都是一个[{"k":"v"}] 这样的形式,所以我做了一个只需传入字典列表
自动获取字典的key作为字段,value作为内容的入库
def insert_many(self, many_data, table_name):
'''
:param [{"k1":"v1","k2":"v2"},{"k1":"v3","k2":"v4"}]:
:param table_name:
:return: affected_rows
'''
values = [tuple(i.values()) for i in many_data]
keys = list(many_data[-1].keys())
sql_1 = "insert into `{}`(`{}`) values({})".format(table_name, '`,`'.join(many_data[-1].keys()),
','.join([''.join('%s') for _ in keys]))
try:
with self.pool.connection() as conn:
with conn.cursor() as cursor:
row_number = cursor.executemany(sql_1, values)
conn.commit()
return "Successful affected_rows: {}".format(row_number)
except Exception as e:
conn.rollback()
return "ERROR:{}".format(e)好接下来做一些入库的操作,看看好不好用
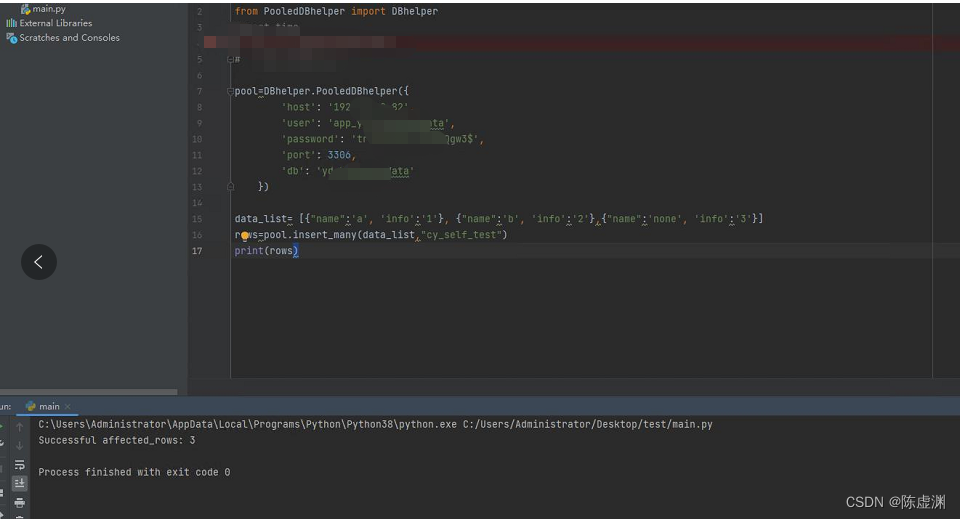
if __name__ == "__main__":
pool=PooledDBhelper({
'host': '192.168.0.1',
'user': 'username',
'password': 'password',
'port': 3306,
'db': 'db_name'
})
data_list= [{"name":'a', 'info':'1'}, {"name":'b', 'info':'2'},{"name":'none', 'info':'3'}]
rows=pool.insert_many(data_list,"cy_self_test")
print(rows)
result_list=pool.task("select * from cy_self_test")
print(result_list)
query = "insert into `cy_self_test`({}) values {}".format("`name`,`info`", ("cy","world"))
pool.fetchone(query)
query="select * from cy_self_test where id=1"
result=pool.fetchone(query)
print(result)然后整个封装起来,我们就获得了一个数据库工具类,做数据库链接池,支持批量插入和查询,基于PooledDB代码封装,并且简化了开发人员的操作。
下一节讲怎么把一个代码包传到pypi