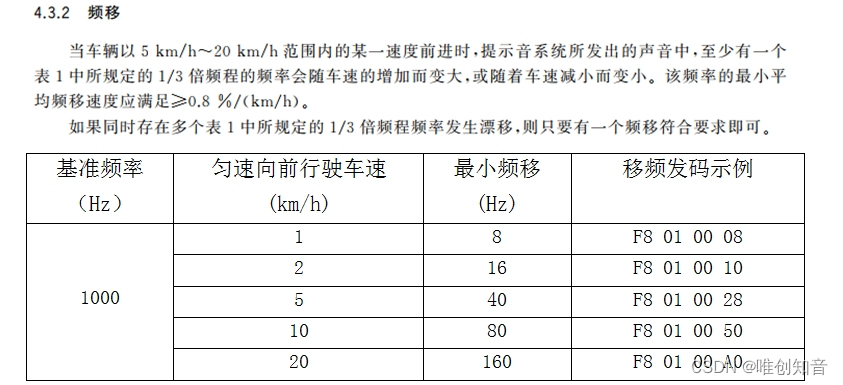
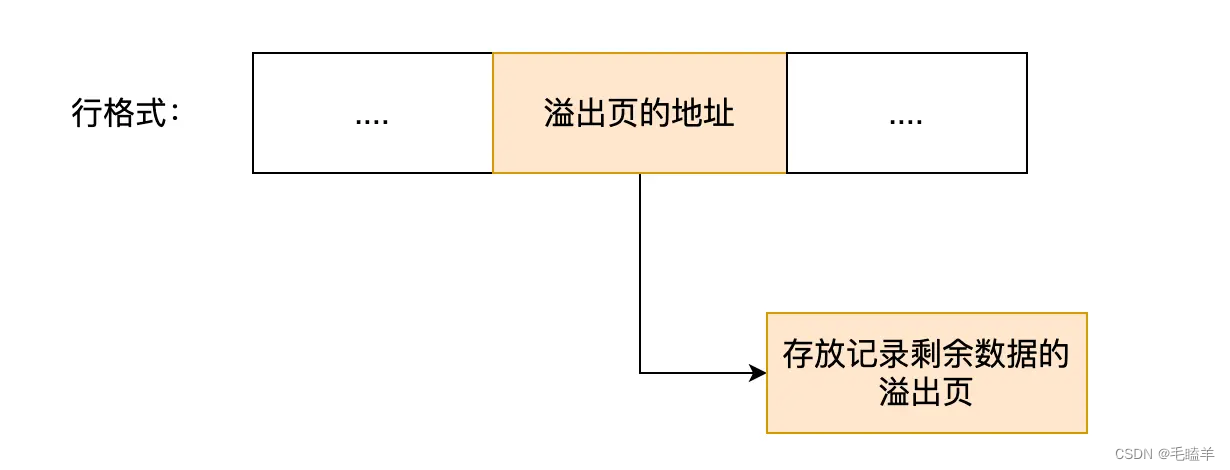
1.特征图可视化,这种方法是最简单,输入一张照片,然后把网络中间某层的输出的特征图按通道作为图片进行可视化展示即可。
2.特征图可视化代码如下:
def featuremap_visual(feature,
out_dir=None, # 特征图保存路径文件
save_feature=True, # 是否以图片形式保存特征图
show_feature=True, # 是否使用plt显示特征图
feature_title=None, # 特征图名字,默认以shape作为title
num_ch=-1, # 显示特征图前几个通道,-1 or None 都显示
nrow=8, # 每行显示多少个特征图通道
padding=10, # 特征图之间间隔多少像素值
pad_value=1 # 特征图之间的间隔像素
):
import matplotlib.pylab as plt
import torchvision
import os
# feature = feature.detach().cpu()
b, c, h, w = feature.shape
feature = feature[0]
feature = feature.unsqueeze(1)
if c > num_ch > 0:
feature = feature[:num_ch]
img = torchvision.utils.make_grid(feature, nrow=nrow, padding=padding, pad_value=pad_value)
img = img.detach().cpu()
img = img.numpy()
images = img.transpose((1, 2, 0))
# title = str(images.shape) if feature_title is None else str(feature_title)
title = str('hwc-') + str(h) + '-' + str(w) + '-' + str(c) if feature_title is None else str(feature_title)
plt.title(title)
plt.imshow(images)
if save_feature:
# root=r'C:\Users\Administrator\Desktop\CODE_TJ\123'
# plt.savefig(os.path.join(root,'1.jpg'))
out_root = title + '.jpg' if out_dir == '' or out_dir is None else os.path.join(out_dir, title + '.jpg')
plt.savefig(out_root)
if show_feature: plt.show()
3.结合resnet网络整体可视化(主要将其featuremap_visual函数插入forward中,即可),整体代码如下:
resnet网络结构在我博客:
残差网络ResNet(超详细代码解析) :你必须要知道backbone模块成员之一 - tangjunjun - 博客园
"""
@author: tangjun
@contact: 511026664@qq.com
@time: 2020/12/7 22:48
@desc: 残差ackbone改写,用于构建特征提取模块
"""
import torch.nn as nn
import torch
from collections import OrderedDict
def Conv(in_planes, out_planes, **kwargs):
"3x3 convolution with padding"
padding = kwargs.get('padding', 1)
bias = kwargs.get('bias', False)
stride = kwargs.get('stride', 1)
kernel_size = kwargs.get('kernel_size', 3)
out = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias)
return out
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = Conv(inplanes, planes, stride=stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = Conv(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Resnet(nn.Module):
arch_settings = {
18: (BasicBlock, (2, 2, 2, 2)),
34: (BasicBlock, (3, 4, 6, 3)),
50: (Bottleneck, (3, 4, 6, 3)),
101: (Bottleneck, (3, 4, 23, 3)),
152: (Bottleneck, (3, 8, 36, 3))
}
def __init__(self,
depth=50,
in_channels=None,
pretrained=None,
frozen_stages=-1
# num_classes=None
):
super(Resnet, self).__init__()
self.inplanes = 64
self.inchannels = in_channels if in_channels is not None else 3 # 输入通道
# self.num_classes=num_classes
self.block, layers = self.arch_settings[depth]
self.frozen_stages = frozen_stages
self.conv1 = nn.Conv2d(self.inchannels, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(self.block, 64, layers[0], stride=1)
self.layer2 = self._make_layer(self.block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(self.block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(self.block, 512, layers[3], stride=2)
# self.avgpool = nn.AvgPool2d(7)
# self.fc = nn.Linear(512 * self.block.expansion, self.num_classes)
self._freeze_stages() # 冻结函数
if pretrained is not None:
self.init_weights(pretrained=pretrained)
def _freeze_stages(self):
if self.frozen_stages >= 0:
self.norm1.eval()
for m in [self.conv1, self.norm1]:
for param in m.parameters():
param.requires_grad = False
for i in range(1, self.frozen_stages + 1):
m = getattr(self, 'layer{}'.format(i))
m.eval()
for param in m.parameters():
param.requires_grad = False
def init_weights(self, pretrained=None):
if isinstance(pretrained, str):
self.load_checkpoint(pretrained)
elif pretrained is None:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, a=0, mode='fan_out', nonlinearity='relu')
if hasattr(m, 'bias') and m.bias is not None: # m包含该属性且m.bias非None # hasattr(对象,属性)表示对象是否包含该属性
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def load_checkpoint(self, pretrained):
checkpoint = torch.load(pretrained)
if isinstance(checkpoint, OrderedDict):
state_dict = checkpoint
elif isinstance(checkpoint, dict) and 'state_dict' in checkpoint:
state_dict = checkpoint['state_dict']
if list(state_dict.keys())[0].startswith('module.'):
state_dict = {k[7:]: v for k, v in checkpoint['state_dict'].items()}
unexpected_keys = [] # 保存checkpoint不在module中的key
model_state = self.state_dict() # 模型变量
for name, param in state_dict.items(): # 循环遍历pretrained的权重
if name not in model_state:
unexpected_keys.append(name)
continue
if isinstance(param, torch.nn.Parameter):
# backwards compatibility for serialized parameters
param = param.data
try:
model_state[name].copy_(param) # 试图赋值给模型
except Exception:
raise RuntimeError(
'While copying the parameter named {}, '
'whose dimensions in the model are {} not equal '
'whose dimensions in the checkpoint are {}.'.format(
name, model_state[name].size(), param.size()))
missing_keys = set(model_state.keys()) - set(state_dict.keys())
print('missing_keys:', missing_keys)
def _make_layer(self, block, planes, num_blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, num_blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
outs = []
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
outs.append(x)
featuremap_visual(x)
x = self.layer2(x)
outs.append(x)
featuremap_visual(x)
x = self.layer3(x)
outs.append(x)
featuremap_visual(x)
x = self.layer4(x)
outs.append(x)
# x = self.avgpool(x)
# x = x.view(x.size(0), -1)
# x = self.fc(x)
return tuple(outs)
def featuremap_visual(feature,
out_dir=None, # 特征图保存路径文件
save_feature=True, # 是否以图片形式保存特征图
show_feature=True, # 是否使用plt显示特征图
feature_title=None, # 特征图名字,默认以shape作为title
num_ch=-1, # 显示特征图前几个通道,-1 or None 都显示
nrow=8, # 每行显示多少个特征图通道
padding=10, # 特征图之间间隔多少像素值
pad_value=1 # 特征图之间的间隔像素
):
import matplotlib.pylab as plt
import torchvision
import os
# feature = feature.detach().cpu()
b, c, h, w = feature.shape
feature = feature[0]
feature = feature.unsqueeze(1)
if c > num_ch > 0:
feature = feature[:num_ch]
img = torchvision.utils.make_grid(feature, nrow=nrow, padding=padding, pad_value=pad_value)
img = img.detach().cpu()
img = img.numpy()
images = img.transpose((1, 2, 0))
# title = str(images.shape) if feature_title is None else str(feature_title)
title = str('hwc-') + str(h) + '-' + str(w) + '-' + str(c) if feature_title is None else str(feature_title)
plt.title(title)
plt.imshow(images)
if save_feature:
# root=r'C:\Users\Administrator\Desktop\CODE_TJ\123'
# plt.savefig(os.path.join(root,'1.jpg'))
out_root = title + '.jpg' if out_dir == '' or out_dir is None else os.path.join(out_dir, title + '.jpg')
plt.savefig(out_root)
if show_feature: plt.show()
import cv2
import numpy as np
def imnormalize(img,
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True
):
if to_rgb:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)
return (img - mean) / std
if __name__ == '__main__':
import matplotlib.pylab as plt
img = cv2.imread('1.jpg') # 读取图片
img = imnormalize(img)
img = torch.from_numpy(img)
img = torch.unsqueeze(img, 0)
img = img.permute(0, 3, 1, 2)
img = torch.tensor(img, dtype=torch.float32)
img = img.to('cuda:0')
model = Resnet(depth=50)
model.init_weights(pretrained='./resnet50.pth') # 可以使用,也可以注释
model = model.cuda()
out = model(img)
运行结果
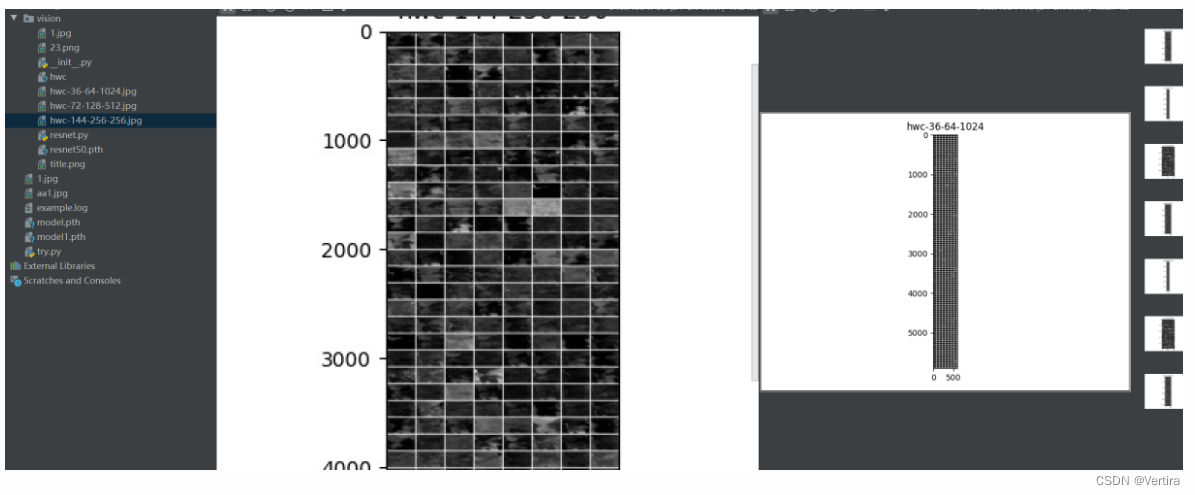
参考:
PyTorch模型训练特征图可视化 - tangjunjun - 博客园 (cnblogs.com)

![[dataworks]从mysql导入数据、将结果导入到mysql、处理写错表名问题、创建依赖任务](https://img-blog.csdnimg.cn/direct/5b6f3bae440f49dda210b03858a34ca6.png)