目录
MySQL一行记录是怎么存储的?
MySQL的数据存放在哪?
表空间文件的结构是怎么样的?
InnoDB行格式有哪些?
Compact行格式是啥样的?
记录的额外信息
1、变长字段长度列表
2、NULL值列表
3、记录头信息
记录的真实数据
vachar(n)中n最大取值是多少?
单字段的情况
多字段的情况
MySQL一行记录是怎么存储的?
MySQL的数据存放在哪?
MySQL数据肯定存放在电脑的硬盘上,那么具体是在哪呢?
存储的行为是由存储引擎实现的,MySQL支持多种存储引擎,不同的存储引擎保存的文件的方式肯定也不一样。
下面以InnoDB存储引擎,数据库test 展开来说。
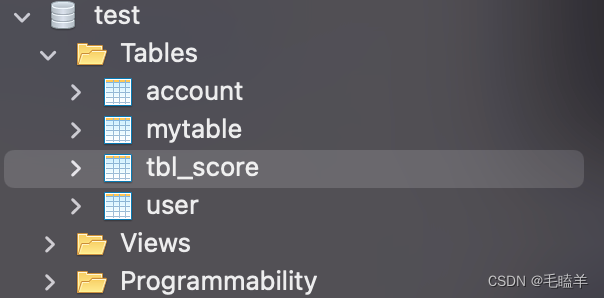
数据库的数据文件存放在哪个目录呢?

运行cd /opt/homebrew/var/mysql目录查看文件列表

 可以看到上面共有四个文件,分别对应数据库test库中的四张表。
可以看到上面共有四个文件,分别对应数据库test库中的四张表。
ibd文件保存表结构和表数据。表数据既可以存在共享表空间,也可以存放在独占表空间文件中。这个是由参数innodb_file_per_table控制的,若设置了此参数为1,则会将存储的数据、索引等信息单独存储在一个独占表空间,5.7版本之后其默认值就是1,因此每一张表的数据都存放在一个独立的.idb文件。
表空间文件的结构是怎么样的?
针对InnoDB引擎,表空间由 段(segment) 、区(extent)、页(page)、行(row)构成。大概结构如下图:

大概说明下:
行: 表中的记录都是按行进行存放的,每行记录也有不同的行格式,对应不同的存储结构。
页:记录是按照行来存储的,但是数据库的读取并不是以「行」为单位,否则一次读取(也就是一次IO操作)只能处理一行数据,效率非常低。在InnoDB中的数据是按「页」为单位来读写的,也就是说,当需要读取一条记录的时候,并不是将这一行记录从磁盘读出来,而是以页为单位,将其整体读入内存。默认每页16K,页是InnoDB存储引擎磁盘管理的最小单元,数据库每次读写都是以16kb为单位的,一次最少从磁盘中读取16K的内容到内存中,一次最少把内存中的16K内容刷新到磁盘中。
区: 一个区包含多个页,默认64个,总大小 1M。 InnoDB会预先分配一个区(通常64个连续页)给一个表的聚集索引(即主键索引)这样,当有插入操作发生时,InnoDB可以直接在这个预先分配的空间中添加新的页,而不必每次插入都去寻找空闲页。
段:表空间是由各个段组成的,段是由多个区组成。段一般分为数据段、索引段、回滚段等。索引段: 存放b+树的非叶子节点的区的集合;数据段:存放b+树的叶子节点的区的集合;混滚段:存放回滚数据的区的集合;
InnoDB行格式有哪些?
Innodb中行格式有Redundant、Compact、Dynamic、Compressed。Mysql8.0默认的行格式为 Dymatic。
Compact行格式是啥样的?
一条记录的结构,如下图:

一条完成的记录包含「记录的额外信息」和「记录的真实数据」两个部分
记录的额外信息
包含3个部分:变长字段长度列表、NULL值列表、记录头信息。
1、变长字段长度列表
varchar(n)和char(n)区别是什么?
char是定长的,varchar是变长的。变长字段实际存储的数据的长度不固定,所以存储数据的时候,也要把数据占用的大小存起来,存到「变长字段长度列表」里面,读取数据的时候才能根据这个去读取对应长度的数据。其他的Text、blob等变长字段也是这么实现的。
以下面的表举例说明:(ascii字符集下每一个字段占1个字节)
CREATE TABLE `tbl_score` (
`id` int(11) NOT NULL,
`name` VARCHAR(20) DEFAULT NULL,
`category` VARCHAR(20) DEFAULT NULL,
`score` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;表中的值:

我们看看上面三条记录的行格式中的「变长字段长度列表」是怎么存储的。
ID=1的记录:
- name列的值为xiaoming,真实数据占用的8字节(实际上会转成16进制,这里就忽略)
- category列的值为yuwen,真实数据占用的5字节(实际上会转成16进制,这里就忽略)
- id和score列不是变长字段,因此这里不用管
这些变长字段的真实数据占用的字节数会按照列的顺序逆序存放,所以「变长字段长度列表」里的内容是「 05 08」,而不是 「08 05」
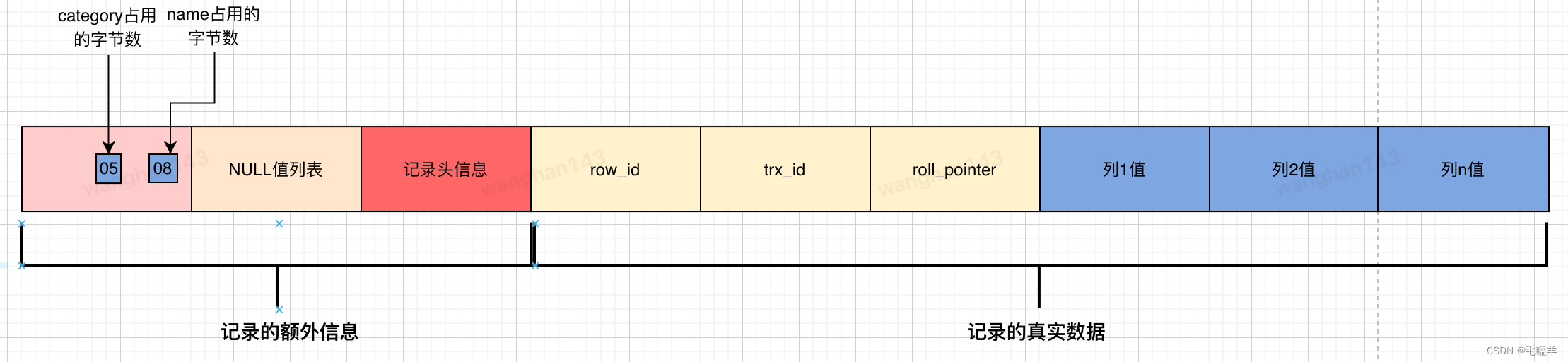
ID=3的记录:
- name列的值为wanger,真实数据占用的06字节(实际上会转成16进制,这里就忽略)
- category列的值为null,null是不会存放在行格式中记录的真实数据部分里的,所以在「变长字段长度列表」里不需要保存值为NULL的变长字段的长度
- id和score列不是变长字段,因此这里不用管
为什么「变长字段长度列表」的信息要按照逆序存放?
因为「记录头信息」中指向下一条记录的指针,指向的是下一条记录的「记录头信息」和「真实数据」之间的位置,这样的好处是向左读就是记录头信息,向右读就是真实数据,很方便。
每一个数据库表的行格式都有「变长字段长度列表」吗?
不是必须的。「变长字段长度列表」只出现在数据表中有变长字段的时候。
当数据表字段中没有变长字段的时候,比如全都是int类型或者char类型的字段 ,这个时候表对应的行格式就不会有。
2、NULL值列表
表中的某些字段可能会存储NULL值,如果这些null值存在记录的真实数据会比较浪费空间,所以会把这些null的列存储在NULL值列表中。
如果存在允许 NULL 值的列,则每个列对应一个二进制位(bit),二进制位按照列的顺序进行逆序排列。
- 二进制位的值为
1时,代表该列的值为NULL。 - 二进制位的值为
0时,代表该列的值不为NULL。
NULL 值列表必须用整数个字节的位表示(1字节8位),如果使用的二进制位个数不足整数个字节,则在字节的高位补 0。
还是用上面的数据来说明:
id=1的记录:
![]()
该记录所有列都有值,不存在NULL值,InnoDB是用整数字节的二进制位来表示NULL值列表,现在不足8位,所以在高位补充0,十六进制表示0x04
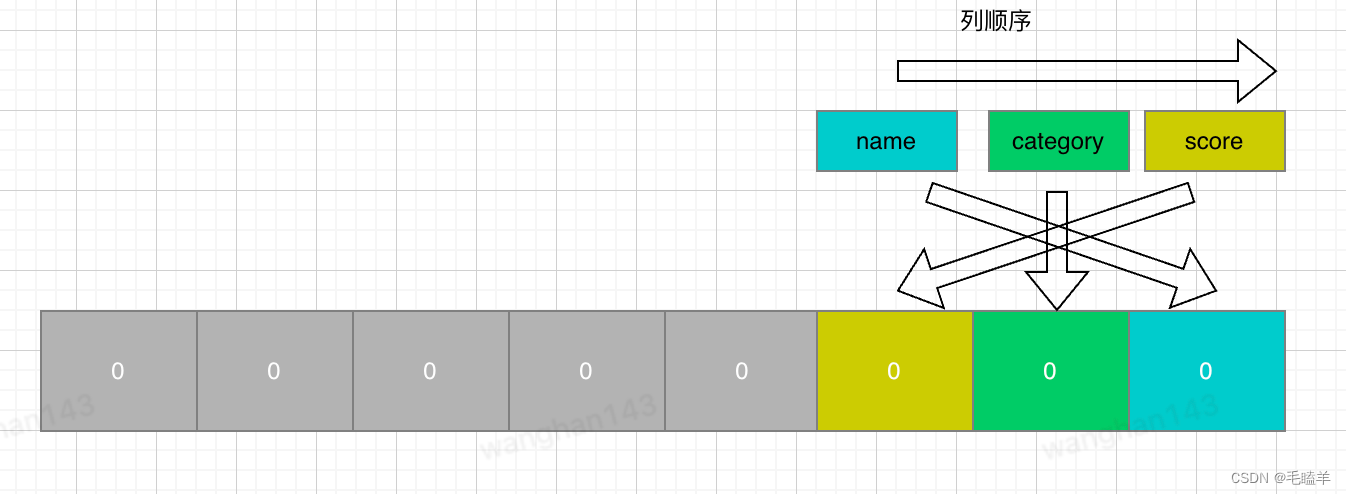
完整结构:

id=2的记录:
![]()
该记录score是NULL值,所以对于这条数据,用十六进制表示是0x04
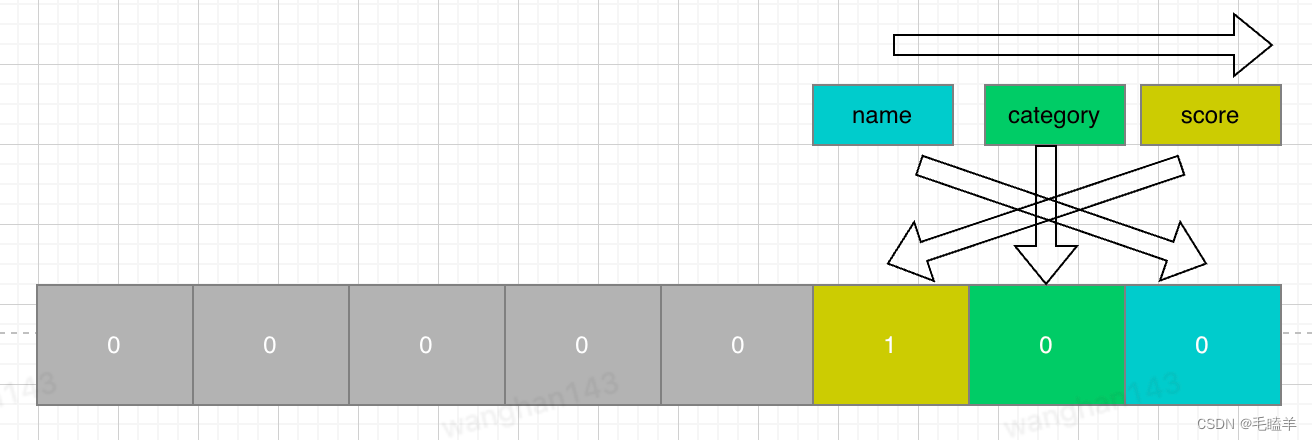

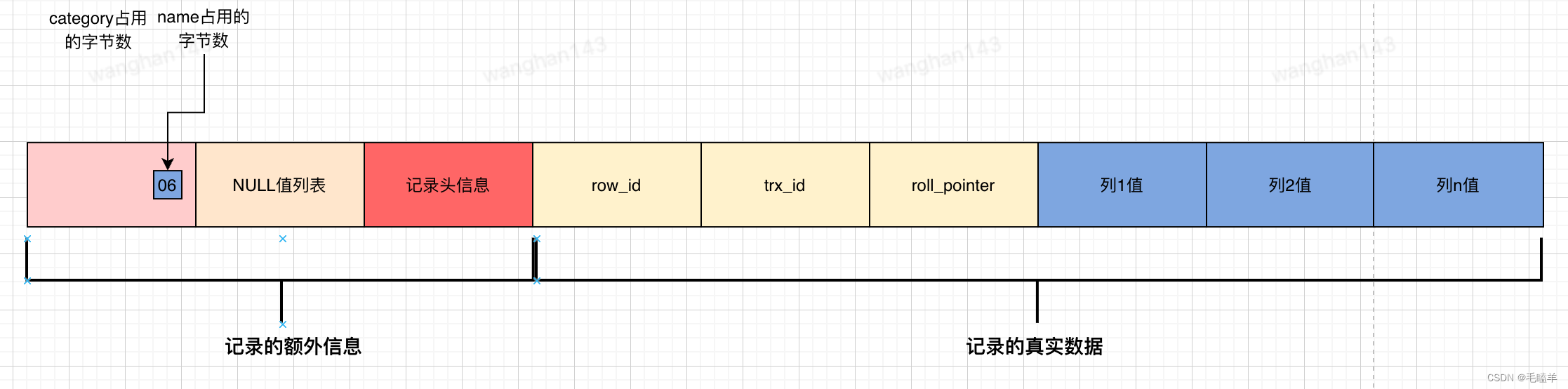
id=3 的记录:
![]()
该记录score和categroy是NULL值,所以对于这条数据,用十六进制表示是0x06


每个数据库表的行格式都有「NULL值列表」吗?
不是必须的。当数据表的字段都定义成NOT NULL的时候,表里的行格式就不会有「NULL值列表了」
在设计表结构的时候,通常建议将字段设置为NOT NULL,这样就可以节省1字节的空间(NULL值列表至少占用1字节空间)
「NULL值列表」 是固定1字节吗?如果是这样,一个记录有9个字段都是NULL,这个时候怎么办呢?
不是固定1字节的,当一条记录有9个字段值都是NULL,那么就会创建2字节的空间的「NULL值库列表」,依次类推 。
3、记录头信息
记录头信息中包含的内容主要有:
| delete_mask | 标识此条记录是否被删除 | 执行delete删除记录,并不会真正的删除记录,只是将delete_mask标识为1 |
| next_record | 下一条记录的位置 | 记录与记录之间是通过链表组织的。这个指向的是下一条记录的「记录头信息」和「真实数据」之前的位置,这样的好处是向左读就是记录头信息,向右读就是真实数据 |
| record_type | 记录的类型 | 0是表示普通记录 1是b+树非叶子节点记录 2是最小记录 3是最大记录等 |
记录的真实数据
记录真实数据出了我们自定义的表字段,还有三个隐藏字段,分别是row_id、trx_id、roll_pointer,下面具体描述:

- row_id: 如果我们建表指定了主键或者唯一约束列,那么就没有row_id这个隐藏字段了。如果没有指定主键,有没有唯一约束列,那么就会为记录添加row_id隐藏字段。row_id不是必需的,占用6个字节。
- trx_id: 事务id,对应记录是由哪个事务操作的。trx_id是必需的,占用6个字节。
- roll_pointer: 记录上一个版本的指针。roll_pointer是必需的,占用7个字节。
vachar(n)中n最大取值是多少?
MySQL规定除了text、blob等类型除外,其他所有列(不包含隐藏列和记录头信息)占用的字节长度加起来不能超过65535个字节。
意思是一行记录中除去text、blob类型的列,限制最大为65535字节,注意是一行的总长度,不是一列。
varchar(n)中的n代表的是最多存储的字符数量,并不是字节大小。计算它最大允许存储的字节数,还要看数据库表对应的字符集。
单字段的情况
CREATE TABLE tbl_3 (
`name` VARCHAR(65535) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;执行SQL后,会出现下面的截图错误

从报错信息就可以知道一行数据的最大字节数是 65535(不包含 TEXT、BLOBs 这种大对象类型),其中包含了 storage overhead。
这里面的storage overhead是什么呢? 其实就是「变长字段长度列表」和「NULL值列表」,也就是说一行数据的最大字节数是65535,其实是包含了「变长字段长度列表」和「NULL值列表」所占用的字节数的。
本例中,「NULL值列表」所占用了字节数是多少?
因为name字段是可以为NULL,所以会用1字节来表示「NULL值列表」
本例中,「变长字段长度列表」所占用的字节数是多少
「变长字段长度列表」所占用的字节数 = 所有「变长字段长度」占用的字节数之和
要先知道每个变长字段的「变长字段长度」需要用多少个字节表示,分为两种情况:
- 如果变长字段允许存储的最大字节数小于等于255字节,就会用1字节表示「变长字段长度」
- 如果变长字段允许存储的最大字节数大于255字节,就会用2字节表示「变长字段长度」
上面的例子是只有 1 个变长字段,所以「变长字段长度列表」= 1 个「变长字段长度」占用的字节数,也就是 2 字节。
因此上面的n最大值为 65535 - 2 - 1 = 65532 。
如果字符集是utf8的话,在 UTF-8 字符集下,一个字符最多需要三个字节,varchar(n) 的 n 最大取值就是 65532/3 = 21844。
// 执行失败
CREATE TABLE tbl_a (
`name` VARCHAR(21845) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8 ROW_FORMAT = COMPACT;
// 执行成功
CREATE TABLE tbl_a (
`name` VARCHAR(21844) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8 ROW_FORMAT = COMPACT;多字段的情况
有多个字段的话,要保证所有字段的长度 + 变长字段长度列表所占用的字节数 + NULL值列表所占用的字节数 <= 65535。
// 执行失败
CREATE TABLE aax (
`id` VARCHAR(255) not null,
`name` VARCHAR(21589) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8 ROW_FORMAT = COMPACT;
765(id字段所占字节) + 2(变长字段长度所占字节) + 64767(name字段所占字节) + 2(变长字段长度所占字节) + 1(NULL值列表) > 65535
// 执行成功
CREATE TABLE aax (
`id` VARCHAR(255) not null,
`name` VARCHAR(21588) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8 ROW_FORMAT = COMPACT;
765(id字段所占字节) + 2(变长字段长度所占字节) + 64764(name字段所占字节) + 2(变长字段长度所占字节) + 1(NULL值列表) < 65535行溢出后,是怎么处理的?
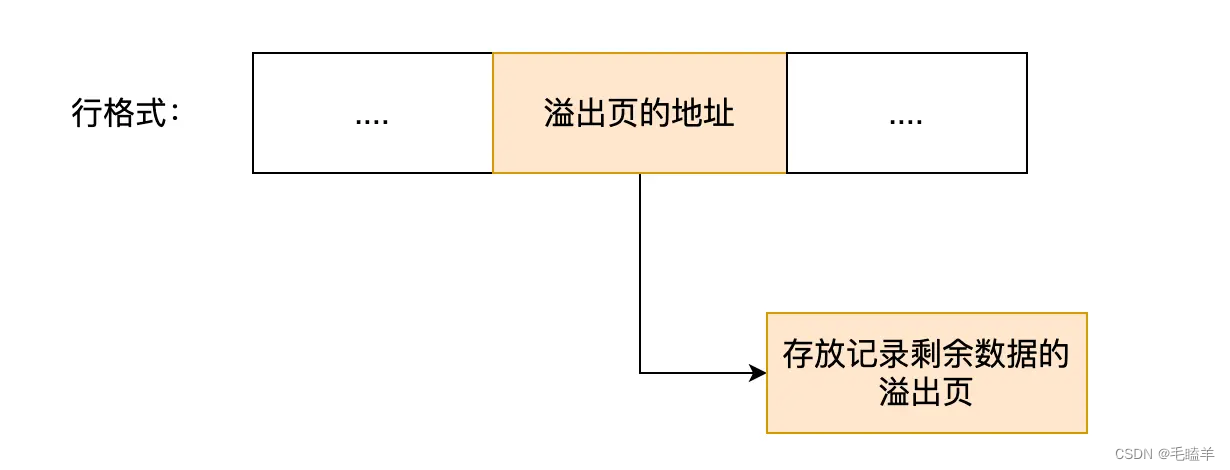
MySQL中磁盘和内存交互是以页为基本单位。一个页一般是16k,也就是16384字节,而一个varchar(n)最大长度是65535字节,另外text类型可能存储更多数据,这个时候一个页就存不了一条记录数据。这就会触发行溢出,多的数据就会存到另外的「溢出页」中。
如果一个数据页存不了一条记录,InnoDB 存储引擎会自动将溢出的数据存放到「溢出页」中。在一般情况下,InnoDB 的数据都是存放在 「数据页」中。但是当发生行溢出时,溢出的数据会存放到「溢出页」中。
当发生行溢出时,在记录的真实数据处只会保存该列的一部分数据,而把剩余的数据放在「溢出页」中,然后真实数据处用 20 字节存储指向溢出页的地址,从而可以找到剩余数据所在的页。
Compact 行格式针对行溢出的处理是这样的:当发生行溢出时,在记录的真实数据处只会保存该列的一部分数据,而把剩余的数据放在「溢出页」中,然后真实数据处用 20 字节存储指向溢出页的地址,从而可以找到剩余数据所在的页。

Compressed 和 Dynamic 这两种格式采用完全的行溢出方式,记录的真实数据处不会存储该列的一部分数据,只存储 20 个字节的指针来指向溢出页。而实际的数据都存储在溢出页中