数据挖掘,计算机网络、操作系统刷题笔记39
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
【35】数据挖掘,计算机网络、操作系统刷题笔记35
【36】数据挖掘,计算机网络、操作系统刷题笔记36
【37】数据挖掘,计算机网络、操作系统刷题笔记37
【38】数据挖掘,计算机网络、操作系统刷题笔记38
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记39
- @[TOC](文章目录)
- 数据挖掘:复合分析
- 交叉分析
- pandas.pivot_table透视表
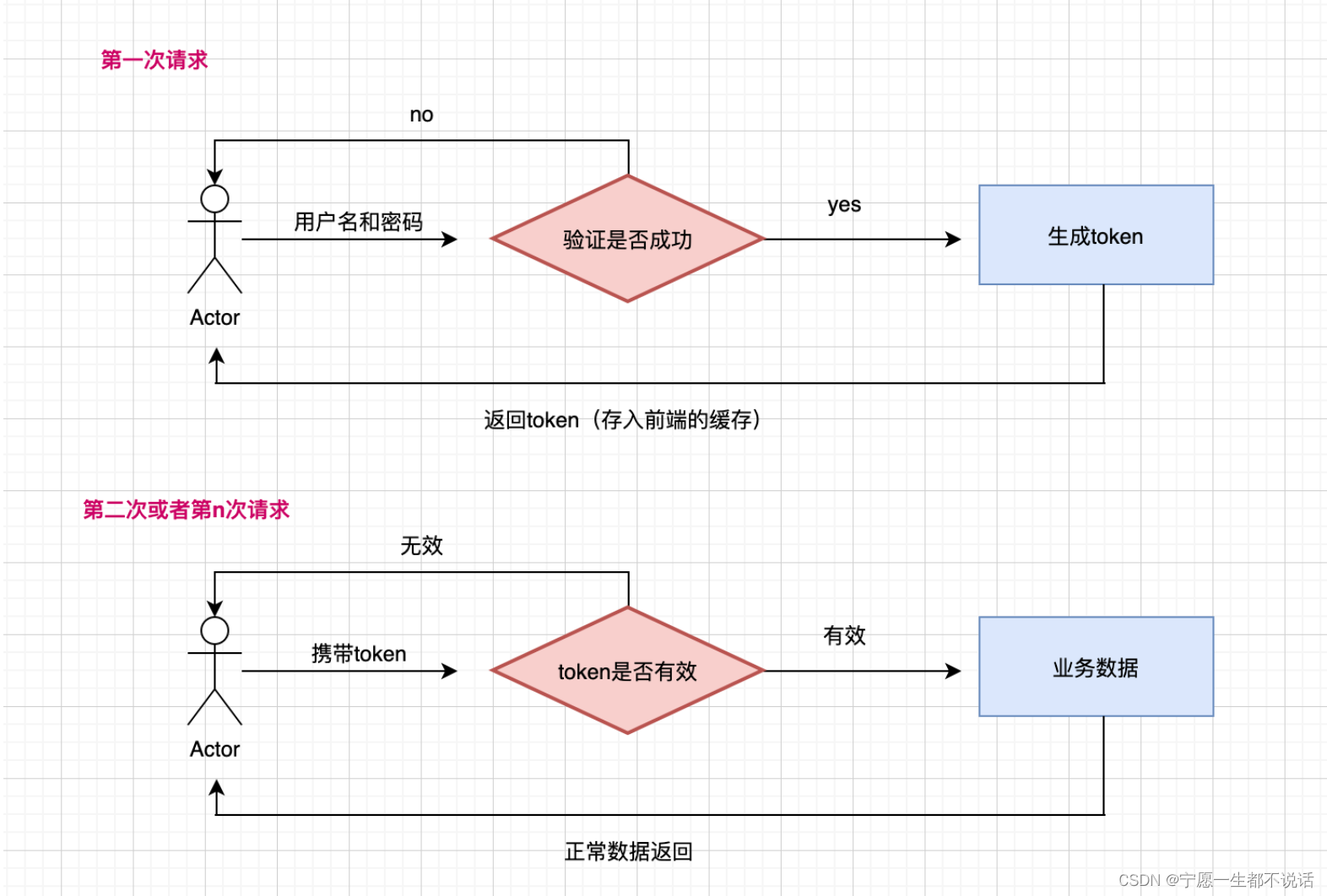
- 下列关于入侵检测系统探测器获取网络流量的方法中正确的是( )
- 应用层下面是表示层,表示层为应用层提供服务,表示层是处理所有与数据表示及运输有关的问题,包括转换、加密和压缩。
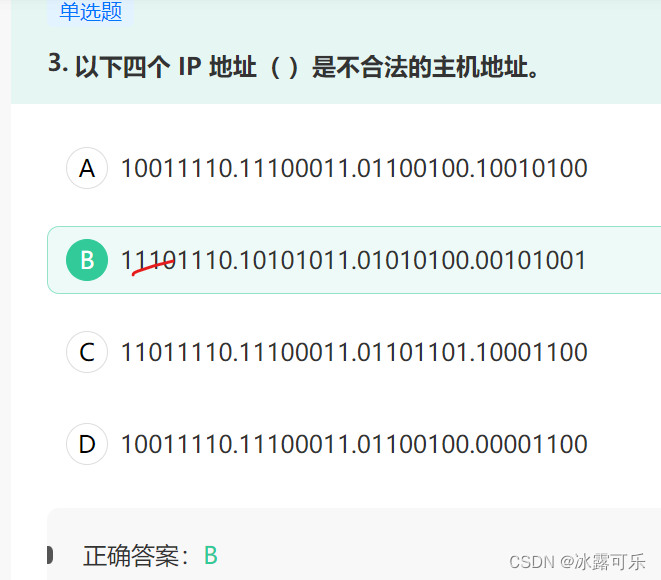
- 合法的主机地址指的是A、B、C类IP地址,
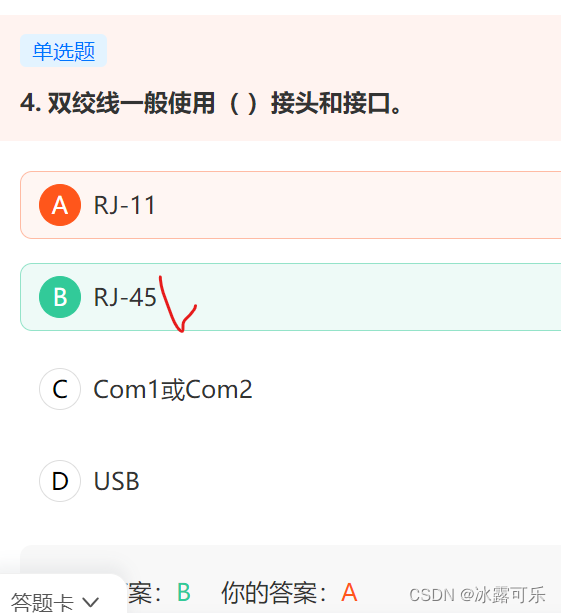
- RJ-11电话接口,RJ-45网络接口
- 下列HTTP错误代码描述正确的是:( )
- 多处理机的各自独立型操作系统说明在运行过程中各个作业开始时被哪个处理机处理,就一直被那个处理机处理,直至任务完成。
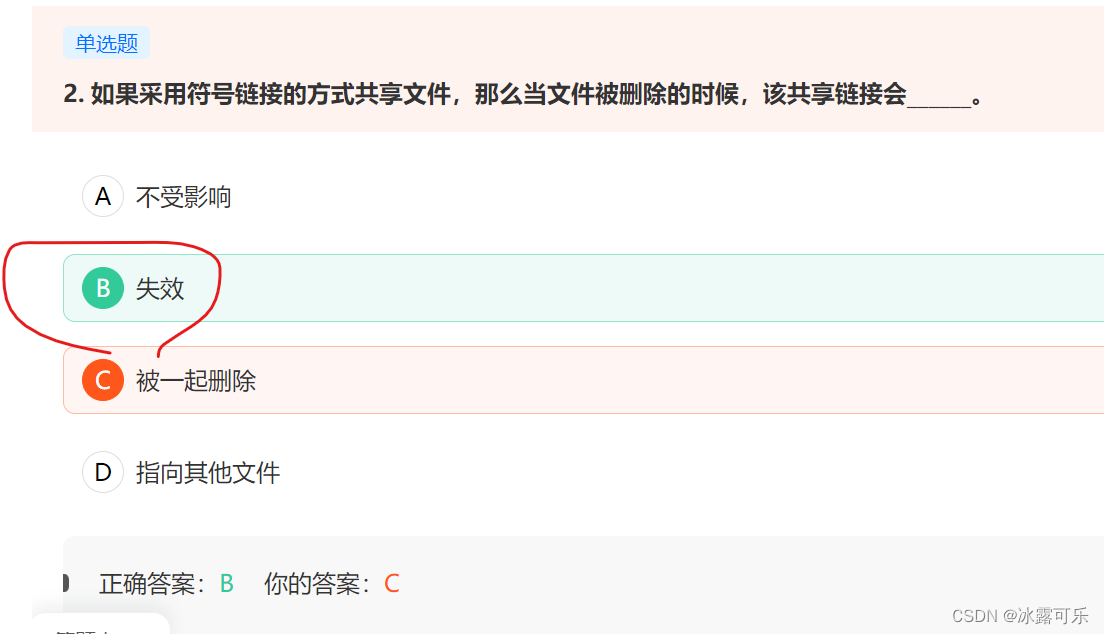
- 符号链接就是快捷方式啊,删除文件,快捷方式不会被删除,但是会失效
- 位示图法用于()
- 页表表项中的访问位是由CPU置位的,页表表项中的存在位是由操作系统代码置位的
- 能够装入内存任何位置的代码程序必须是()。
- 一般情况下,分时系统中处于就绪状态的进程最多。
- 作业从后备作业到被调度程序选中的时间称为()。
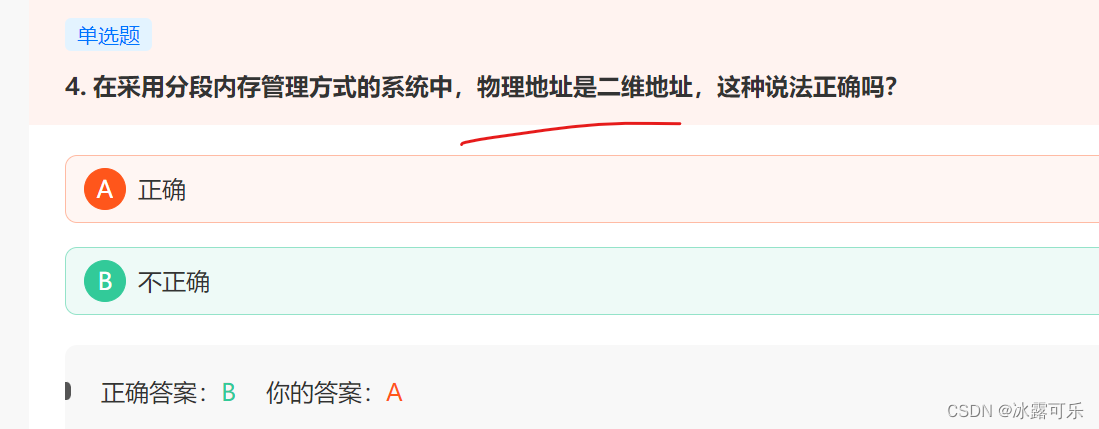
- 分段逻辑地址空间由一组段组成二维地址 物理地址是一维
- 总结
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记39
- @[TOC](文章目录)
- 数据挖掘:复合分析
- 交叉分析
- pandas.pivot_table透视表
- 下列关于入侵检测系统探测器获取网络流量的方法中正确的是( )
- 应用层下面是表示层,表示层为应用层提供服务,表示层是处理所有与数据表示及运输有关的问题,包括转换、加密和压缩。
- 合法的主机地址指的是A、B、C类IP地址,
- RJ-11电话接口,RJ-45网络接口
- 下列HTTP错误代码描述正确的是:( )
- 多处理机的各自独立型操作系统说明在运行过程中各个作业开始时被哪个处理机处理,就一直被那个处理机处理,直至任务完成。
- 符号链接就是快捷方式啊,删除文件,快捷方式不会被删除,但是会失效
- 位示图法用于()
- 页表表项中的访问位是由CPU置位的,页表表项中的存在位是由操作系统代码置位的
- 能够装入内存任何位置的代码程序必须是()。
- 一般情况下,分时系统中处于就绪状态的进程最多。
- 作业从后备作业到被调度程序选中的时间称为()。
- 分段逻辑地址空间由一组段组成二维地址 物理地址是一维
- 总结
数据挖掘:复合分析
之前讲得都是单因子分析
现在开始复合分析

交叉分析
仅仅是行列分析
还是不客观
那么数据之间的关联呢?
这就是交叉分析
任意取两列,判断他们的联系
多个字段拿出来做分析啥的
用代码演示
我们现在特别想知道离职率是否和部门有关系???即,不同的部门之间的离职率,是否有关联呢?
用代码把每个部门的那些下标取出来,indices
def f1():
# 交叉分析
df = pd.read_csv('HR_comma_sep.csv')
# 关注hr中各个部门的left和部门有关吗?
# 部门的离职分布是啥呢?
indices = df.groupby('department').indices
print(indices) # 这个indices是不同部门,对应的那些行下标
{'IT': array([ 61, 62, 63, ..., 14932, 14933, 14938], dtype=int64), 'RandD': array([ 301, 302, 303, 304, 305, 453, 454, 455, 456,
457, 605, 606, 607, 608, 609, 833, 834, 835,
836, 837, 985, 986, 987, 988, 989, 1061, 1062,
1063, 1064, 1065, 1217, 1218, 1219, 1291, 1292, 1293,
1294, 1295, 1296, 1368, 1369, 1370, 1371, 1372, 1373,
1445, 1446, 1447, 1448, 1449, 1450, 1522, 1523, 1524,
1525, 1526, 1598, 1599, 1600, 1601, 1602, 1675, 1676,
1677, 1678, 1679, 1751, 1752, 1753, 1754, 1755, 1827,
1828, 1829, 1830, 1831, 1903, 1904, 1905, 1906, 1907,
1979, 1980, 1981, 1982, 1983, 2055, 2056, 2057, 2058,
2059, 2131, 2132, 2133, 2134, 2135, 2207, 2208, 2209,
2210, 2211, 2283, 2284, 2285, 2286, 2287, 2359, 2360,
2361, 2362, 2363, 2435, 2436, 2437, 2438, 2439, 2511,
2512, 2513, 2514, 2515, 2588, 2589, 2590, 2591, 2592,
2593, 2665, 2666, 2667, 2668, 2669, 2670, 2742, 2743,
2744, 2745, 2746, 2747, 2819, 2820, 2821, 2822, 2823,
2824, 2896, 2897, 2898, 2899, 2900, 2972, 2973, 2974,
2975, 2976, 3049, 3050, 3051, 3052, 3053, 3125, 3126,
3127, 3128, 3129, 3201, 3202, 3203, 3204, 3205, 3277,
3278, 3279, 3280, 3281, 3353, 3354, 3355, 3356, 3357,
3429, 3430, 3431, 3432, 3433, 3505, 3506, 3507, 3508,
3509, 3581, 3582, 3583, 3584, 3585, 3657, 3658, 3659,
3660, 3661, 3733, 3734, 3735, 3736, 3737, 3809, 3810,
3811, 3812, 3813, 3885, 3886, 3887, 3888, 3889, 3962,
3963, 3964, 3965, 3966, 3967, 4039, 4040, 4041, 4042,
4043, 4044, 4116, 4117, 4118, 4119, 4120, 4121, 4193,
4194, 4195, 4196, 4197, 4198, 4270, 4271, 4272, 4273,
4274, 4346, 4347, 4348, 4349, 4350, 4423, 4424, 4425,
4426, 4427, 4499, 4500, 4501, 4502, 4503, 4575, 4576,
4577, 4578, 4579, 4651, 4652, 4653, 4654, 4655, 4727,
4728, 4729, 4730, 4731, 4803, 4804, 4805, 4806, 4807,
4879, 4880, 4881, 4882, 4883, 4955, 4956, 4957, 4958,
4959, 5031, 5032, 5033, 5034, 5035, 5107, 5108, 5109,
5110, 5111, 5183, 5184, 5185, 5186, 5187, 5259, 5260,
5261, 5262, 5263, 5336, 5337, 5338, 5339, 5340, 5341,
5413, 5414, 5415, 5416, 5417, 5418, 5490, 5491, 5492,
5493, 5494, 5495, 5567, 5568, 5569, 5570, 5571, 5572,
5644, 5645, 5646, 5647, 5648, 5720, 5721, 5722, 5723,
结果是一个字典,每个部门,它对应的下标行数,都有的
这样的话,你就可以索引这些行了
然后咱们将销售sales和it部门的left的离职率values取出来
算算这俩部门,他们的相关性
用t分布检验,如果pvalue在0.05一下,拒绝认为他们相关,如果在0.05之上,接受他们俩部门的离职率是相关的
import numpy as np
import scipy.stats as ss
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
def f1():
# 交叉分析
df = pd.read_csv('HR_comma_sep.csv')
# 关注hr中各个部门的left和部门有关吗?
# 部门的离职分布是啥呢?
indices = df.groupby('department').indices
# print(indices) # 这个indices是不同部门,对应的那些行下标
sales_values = df['left'].iloc[indices['sales']].values # 获取离职率中那些sales的行数据,把离职率拿出来
technical_values = df['left'].iloc[indices['IT']].values
# t分布检验俩分布是否有关联--看看销售部门
print(ss.ttest_ind(sales_values, technical_values))
if __name__ == '__main__':
f1()
Ttest_indResult(statistic=1.6165666737332176, pvalue=0.10603064390656178)
pvalue是大于0.05的
看来销售和技术是相关的
一般销售业绩不咋地,技术这里研发意义也不大,裁员也就多
这还是单因子的分析
那么复合因子,两两字段,不同部门两两之间的离职率是否相关呢???
这就是交叉分析
下面,我们要算,各个部门之间的相关系
看看他们的pvalue,是什么状况?
同理,用t分布检验,如果pvalue在0.05一下,拒绝认为他们相关【那么直接可以把pavlue干为-1,无关】,如果在0.05之上,接受他们俩部门的离职率是相关的
这里就是要用到算法设计的逻辑思维了
怎么一次性交叉分析完 ?
刚刚不是一个,单独写俩部门吗
我们现在要自动化让算法求不同部门,22之间的pvalue
好说,根据部门与部门遍历来算一次呗
那总的所有部门都是哪些??
# 现在呢,我们要把这个不同部门之间22的相关性分析出来
# 首先你看看都有哪些部门?
print(indices.keys())
dict_keys(['IT', 'RandD', 'accounting', 'hr', 'management', 'marketing', 'product_mng', 'sales', 'support', 'technical'])
10个部门,不同名字不一样
OK,我们之前手动一个个提取,现在我们要遍历,每个部门,和其他部门之间自动提取,计算pvalue
import numpy as np
import scipy.stats as ss
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
def f1():
# 交叉分析
df = pd.read_csv('HR_comma_sep.csv')
# 关注hr中各个部门的left和部门有关吗?
# 部门的离职分布是啥呢?
indices = df.groupby('department').indices
# print(indices) # 这个indices是不同部门,对应的那些行下标
sales_values = df['left'].iloc[indices['sales']].values # 获取离职率中那些sales的行数据,把离职率拿出来
technical_values = df['left'].iloc[indices['IT']].values
# t分布检验俩分布是否有关联--看看销售部门
# print(ss.ttest_ind(sales_values, technical_values))
# 现在呢,我们要把这个不同部门之间22的相关性分析出来
# 首先你看看都有哪些部门?
# print(indices.keys())
dict_keys = list(indices.keys()) # 我们需要把它转为数组,方便遍历哦
# 现在我们要遍历,每个部门,和其他部门之间自动提取,计算pvalue
# 先定义一个matrix矩阵,接受结果
n = len(dict_keys) # 10个部门
ans_pvalue = np.zeros([n, n]) # 接受结果是10*10的矩阵
for i in range(n):
for j in range(n):
# 取第i个部门的left和第j个部门的left,求pvalue
pvalue = ss.ttest_ind(df['left'].iloc[indices[dict_keys[i]]].values,
df['left'].iloc[indices[dict_keys[j]]].values)[1] # 注意,这里是一个object哦,取【1】是pvalue
if pvalue < 0.05:
ans_pvalue[i][j] = -1 # 拒绝无关
else:
ans_pvalue[i][j] = pvalue
# 然后ans_p就是22部门之间的相关关系,越大关系越紧密,越小越没关系
sns.heatmap(ans_pvalue)
plt.show()
if __name__ == '__main__':
f1()
TypeError: 'dict_keys' object is not subscriptable
这是因为这个东西是字典,不是数组,需要转数组,list()强行转化即可
得到
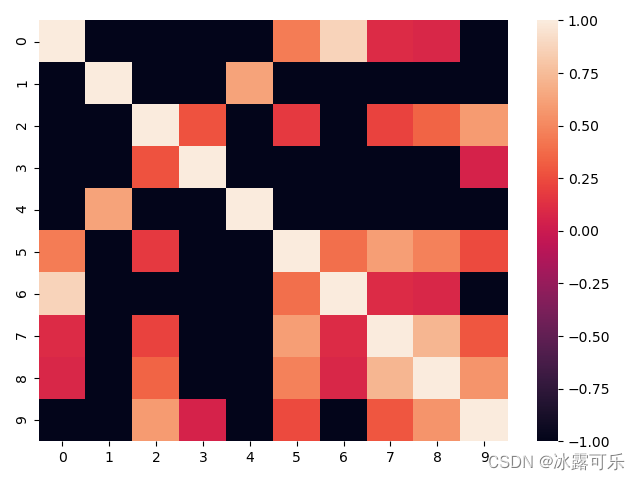
你看看,ans_p就是不同部门之间22的pvalue
小于0.05的直接没关系了
上面黑色的不看,非黑色就是有关系
比如
我们把那个标签打上
# 然后ans_p就是22部门之间的相关关系,越大关系越紧密,越小越没关系
sns.heatmap(ans_pvalue, xticklabels=dict_keys, yticklabels=dict_keys)
plt.show()
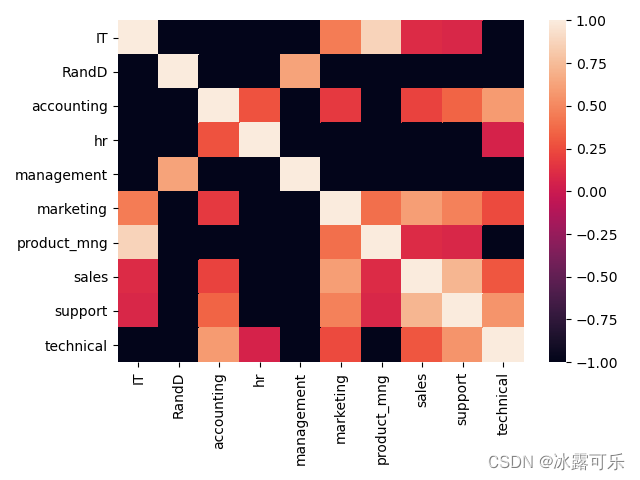
你看看IT和product_mng俩部门之间关系很大
也就是产品经理没活干,程序员都他妈得离职
所以这俩部门之间关系极大
这些就是复合交叉分析
还有一种是透视表
pandas.pivot_table透视表
def f2():
# 交叉分析
df = pd.read_csv('HR_comma_sep.csv')
# 直接用pd做一个透视表,关注value是离职率【平均的
# 横坐标是五年晋升情况,和薪水
# 纵坐标是工作事故,
# 看看这样的搭配下,那些交叉特征容易离职?
piv_tb = pd.pivot_table(df, values='left', index=['promotion_last_5years','salary'],
columns=['Work_accident'], aggfunc=np.mean) # 聚合方式是values的均值
print(piv_tb)
# 然后用热力图展示
sns.heatmap(data=piv_tb, vmin=0, vmax=1) # 热力图展示
Work_accident 0 1
promotion_last_5years salary
0 high 0.082996 0.000000
low 0.331728 0.090020
medium 0.230683 0.081655
1 high 0.000000 0.000000
low 0.229167 0.166667
medium 0.028986 0.023256
你看看横坐标是晋升与否,同时又看看薪水高低,搭配起来
然后你看看事故发生率,搭配为纵坐标
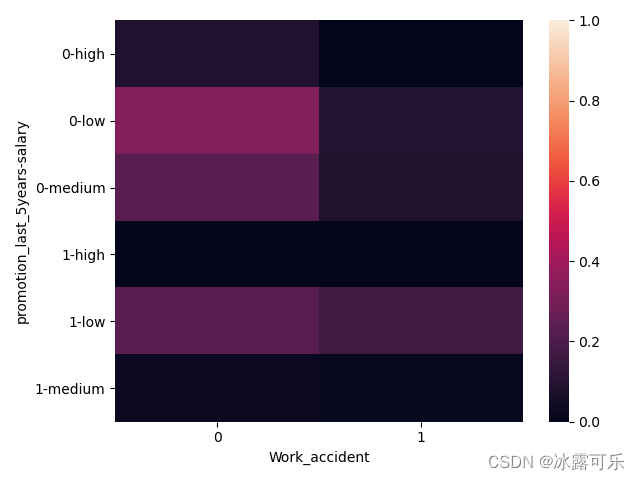
这样的话,就美滋滋了——透视表把所有的相关的数据的平均离职率算出来了
你看看
没有晋升的,也没有事故的,工资还低的这种人,它最可能离职
0.33的离职率很高了
决策者看到这个表,应该考虑这种人,要涨点工资还是咋地
热力图也贼爽,组合搭配,它给你展示出来了,爽的一笔
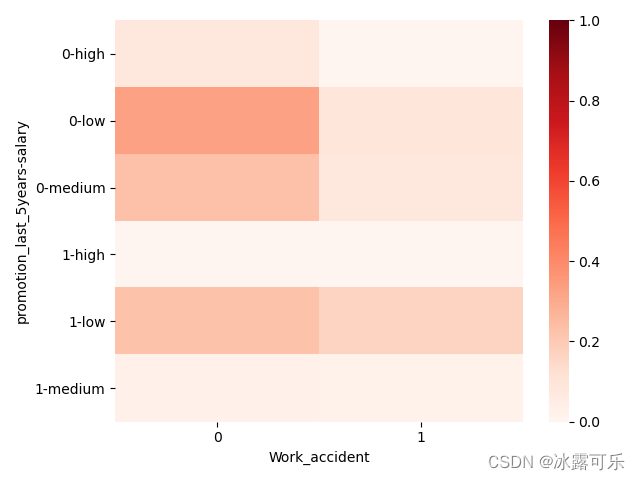
如果觉得颜色有点骚
赞换成红色的那个色系,color map=cmap
seaborn里面我们有学过调色板哦
def f2():
# 调整字体
sns.set_context(font_scale=1.5) # 1.5倍
# 交叉分析
df = pd.read_csv('HR_comma_sep.csv')
# 直接用pd做一个透视表,关注value是离职率【平均的
# 横坐标是五年晋升情况,和薪水
# 纵坐标是工作事故,
# 看看这样的搭配下,那些交叉特征容易离职?
piv_tb = pd.pivot_table(df, values='left', index=['promotion_last_5years','salary'],
columns=['Work_accident'], aggfunc=np.mean) # 聚合方式是values的均值
print(piv_tb)
# 然后用热力图展示
sns.heatmap(data=piv_tb, vmin=0, vmax=1, cmap=sns.color_palette("Reds", n_colors=256)) # 热力图展示
plt.show() # 用256种颜色
if __name__ == '__main__':
f2()
下列关于入侵检测系统探测器获取网络流量的方法中正确的是( )
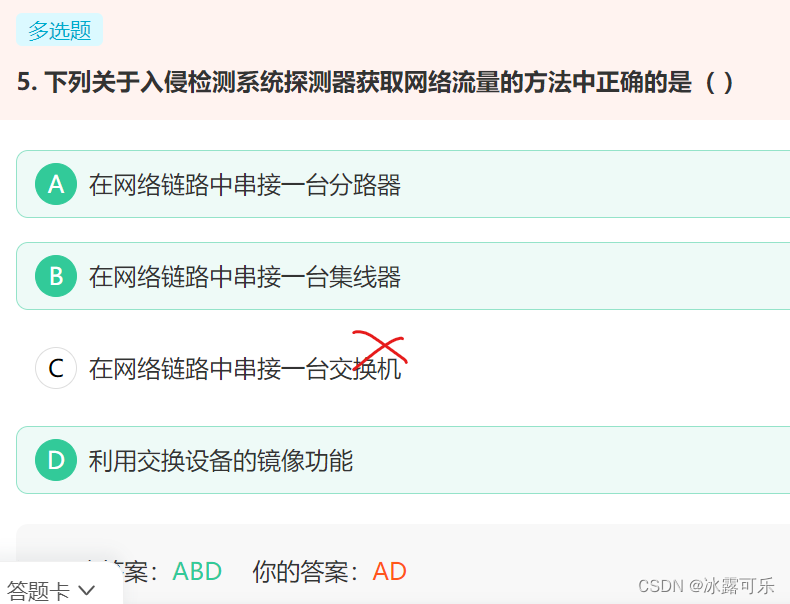
链接:https://www.nowcoder.com/questionTerminal/25525076c040488198bcac29daace014
来源:牛客网
根据网络拓扑结构的不同,入侵检测系统(IDS)的探测器可以通过以下3种方式部署在被检测的网络中。
①流量镜像方式。
网络接口卡与交换设备的监控端口连接,通过交换设备的镜像(Span/Mirror)功能将流向各端口的数据包复制一份给监控端口,探测器从监控端口获取数据包并进行分析和处理。
②串接集线器设备。
网络链路中串接一台集线器改变网络拓扑结构,通过集线器(共享式监听方式)获取数据包。例如,可以在Inteiaaet边界路由器与交换机之问串接一台集线器,然后将探测器连接在集线器的某个端口上。
③串接TAP设备。
在网络链路中串接一台分路器(TAP),通过TAP设备对交换式网络中的数据包进行分析和处理。例如,可以在Internet边界路由器与交换机之间串接一台TAP设备,然后将入侵检测系统的探测器连接到TAP设备的相应端口上。
交换机是根据记录着MAC地址与设备端口映射关系的地址查询表,只在源端口和目的端口之间传递数据包,**而该交换机的其他端口并不能接收到该数据包。**如果在网络链路中串接一台交换机,简单地将IDS的探测器连接到该交换机某个端口中,则探测器将获取不到相应的数据包,即不能获取网络流量
应用层下面是表示层,表示层为应用层提供服务,表示层是处理所有与数据表示及运输有关的问题,包括转换、加密和压缩。
合法的主机地址指的是A、B、C类IP地址,
A类地址以0开头
B类地址以10开头
C类地址以110开头
D类地址以1110开头,D类地址用于IP多播
RJ-11电话接口,RJ-45网络接口
下列HTTP错误代码描述正确的是:( )
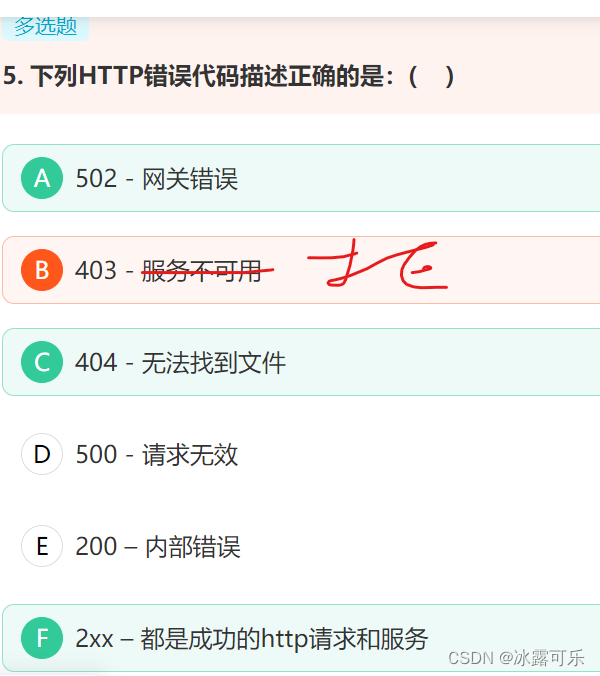
链接:https://www.nowcoder.com/questionTerminal/578179c8149941b3876ae019298af2aa
来源:牛客网
100 Continue 继续。客户端应继续其请求
101 Switching Protocols 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议
200 OK 请求成功。一般用于GET与POST请求
201 Created 已创建。成功请求并创建了新的资源
202 Accepted 已接受。已经接受请求,但未处理完成
203 Non-Authoritative Information 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本
204 No Content 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档
205 Reset Content 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域
206 Partial Content 部分内容。服务器成功处理了部分GET请求
300 Multiple Choices 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择
301 Moved Permanently 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
302 Found 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI
303 See Other 查看其它地址。与301类似。使用GET和POST请求查看
304 Not Modified 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源
305 Use Proxy 使用***。所请求的资源必须通过***访问
306 Unused 已经被废弃的HTTP状态码
307 Temporary Redirect 临时重定向。与302类似。使用GET请求重定向
400 Bad Request 客户端请求的语法错误,服务器无法理解
401 Unauthorized 请求要求用户的身份认证
402 Payment Required 保留,将来使用
403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求
404 Not Found 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面
405 Method Not Allowed 客户端请求中的方法被禁止
406 Not Acceptable 服务器无法根据客户端请求的内容特性完成请求
407 Proxy Authentication Required 请求要求的身份认证,与401类似,但请求者应当使用进行授权
408 Request Time-out 服务器等待客户端发送的请求时间过长,超时
409 Conflict 服务器完成客户端的PUT请求是可能返回此代码,服务器处理请求时发生了冲突
410 Gone 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置
411 Length Required 服务器无法处理客户端发送的不带Content-Length的请求信息
412 Precondition Failed 客户端请求信息的先决条件错误
413 Request Entity Too Large 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息
414 Request-URI Too Large 请求的URI过长(URI通常为网址),服务器无法处理
415 Unsupported Media Type 服务器无法处理请求附带的媒体格式
416 Requested range not satisfiable 客户端请求的范围无效
417 Expectation Failed 服务器无法满足Expect的请求头信息
500 Internal Server Error 服务器内部错误,无法完成请求
501 Not Implemented 服务器不支持请求的功能,无法完成请求
502 Bad Gateway 作为网关或者工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
503 Service Unavailable 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中
504 Gateway Time-out 充当网关或的服务器,未及时从远端服务器获取请求
505 HTTP Version not supported 服务器不支持请求的HTTP协议的版本,无法完成处理
多处理机的各自独立型操作系统说明在运行过程中各个作业开始时被哪个处理机处理,就一直被那个处理机处理,直至任务完成。
链接:https://www.nowcoder.com/questionTerminal/5893b1e696b9439e9e21cfaf2fd51c19
来源:牛客网

A. 不论什么样的操作系统,管理程序都是必不可少的,管理程序要负责资源的调度等等
B. 紧耦合说明各个处理机联系紧密,与独立型矛盾。应该为紧内聚。
C. 工作负荷不确定,正如前面说的,任务一旦被提交运行,就全权交给对应处理机,系统不会进行处理机的负载均衡
D. 由于任务一直被初始提交时的处理机处理,避免了和其他处理机上运行的任务接触,提高了可靠性
符号链接就是快捷方式啊,删除文件,快捷方式不会被删除,但是会失效
位示图法用于()

磁盘空间的管理: 空闲表法,空闲链表法,位示图和成组链接法
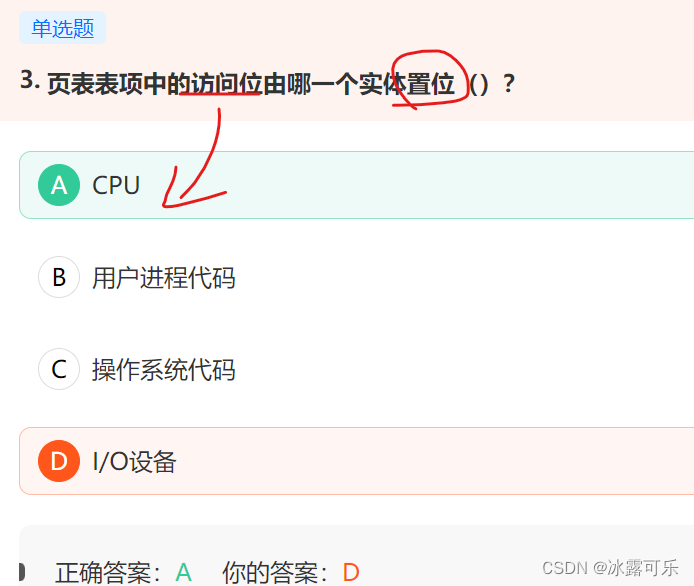
页表表项中的访问位是由CPU置位的,页表表项中的存在位是由操作系统代码置位的
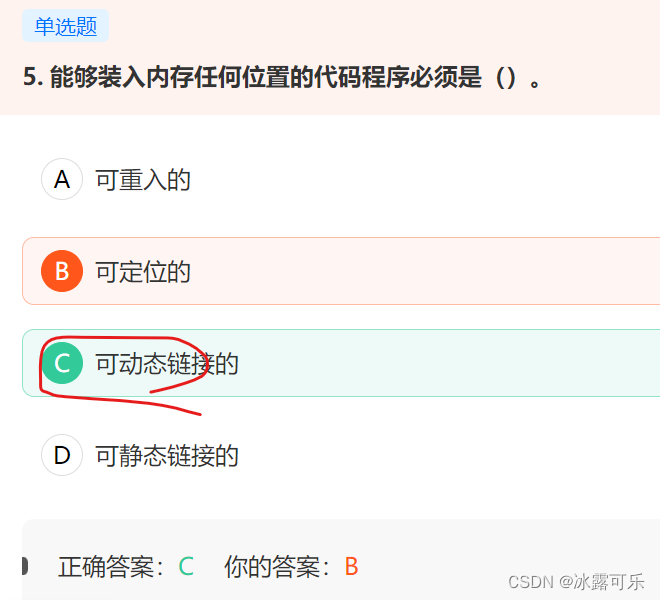
能够装入内存任何位置的代码程序必须是()。
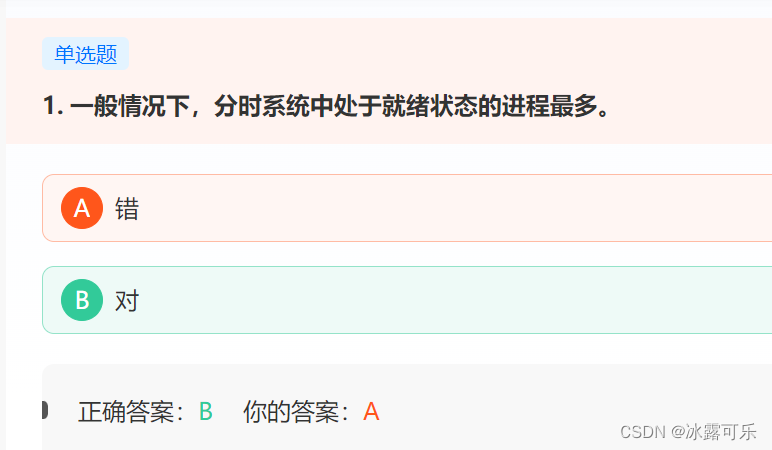
一般情况下,分时系统中处于就绪状态的进程最多。
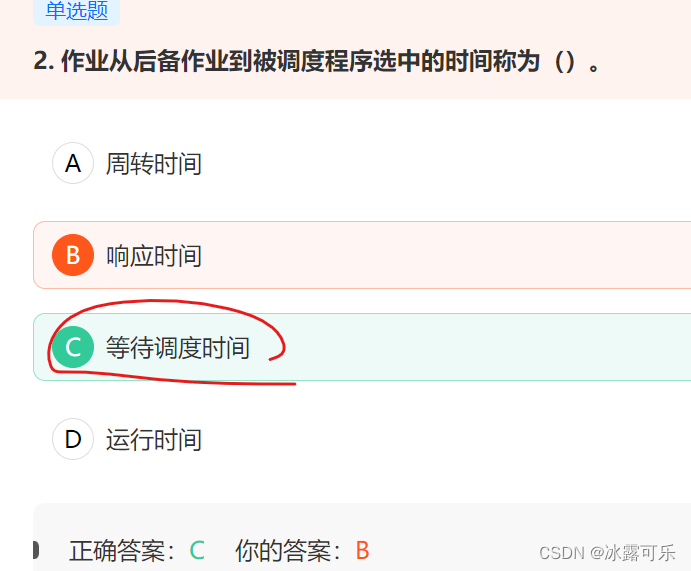
作业从后备作业到被调度程序选中的时间称为()。
响应时间=进程运行结束的时间—进程到达的时间
分段逻辑地址空间由一组段组成二维地址 物理地址是一维
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。