关于如何得到Mindspore lite所需要的.ms模型
- 一、.ckpt模型文件转.mindir模型
- 二、.mindir模型转.ms模型
- 三、其它
- 3.1 代码
- 3.2 数据
- 四、参考文档
一、.ckpt模型文件转.mindir模型
由于要得到ms模型,mindspore的所有模型里面,是必须要用mindir模型才可以进行转换的,因此我们是必须先拿到mindir模型~

此过程并不复杂,需要注意的是,要在昇腾910的npu环境下训练得到的ckpt模型文件才可以转换,其它如cpu、gpu下得到的模型均不可以,所以可以用启智AI平台来,按照昇思官方给的示例就可以转成。
这里可以用启智AI平台,有免费的npu提供,速度也很快!
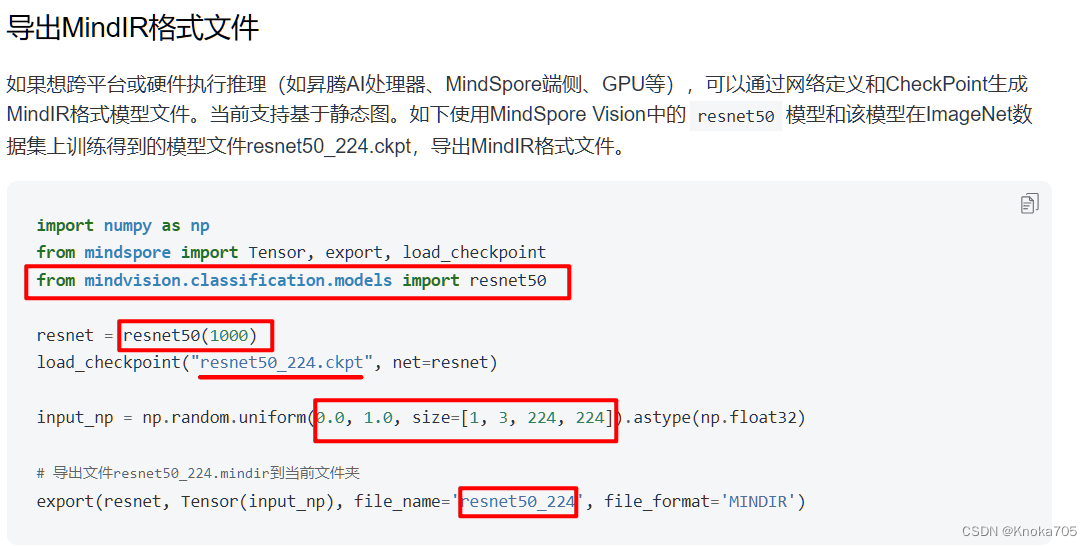
input_np为训练/推理过程输入网络的数据(其中一个),可以先打印出来确定其内容和类型,我这个案例里面用的是(10,1),即一个二维数字,10列1行,这也是为什么数据是这个样子的原因;
其它调用模型、网络都用自己搭建的,简单调一下就可以一下子转成了;
二、.mindir模型转.ms模型
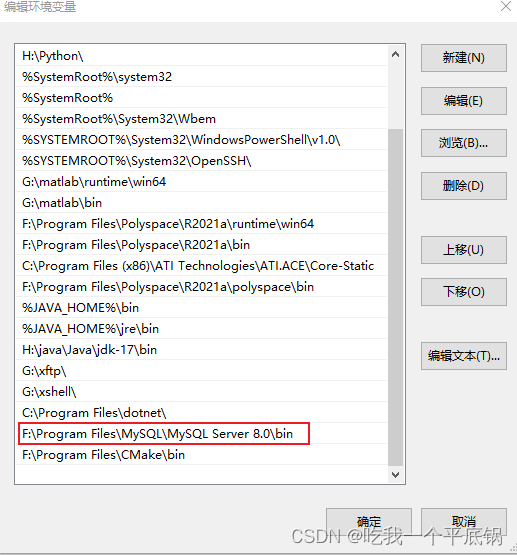
需要用官方所提供的转换工具,下载版本最好和mindspore版本对应,下载后设置环境变量时候,最好是用管理员模式powershell设置,设置指令如下
$env:PATH = "C:\Users\l\Desktop\ls\mindspore-lite-2.2.0-win-x64\tools\converter\lib;" + $env:PATH
路径需要替换为自己的mindspore lite地址,后面按照转换示例走一下就可以转换得到,主要容易出错的是环境变量的设置

三、其它
3.1 代码
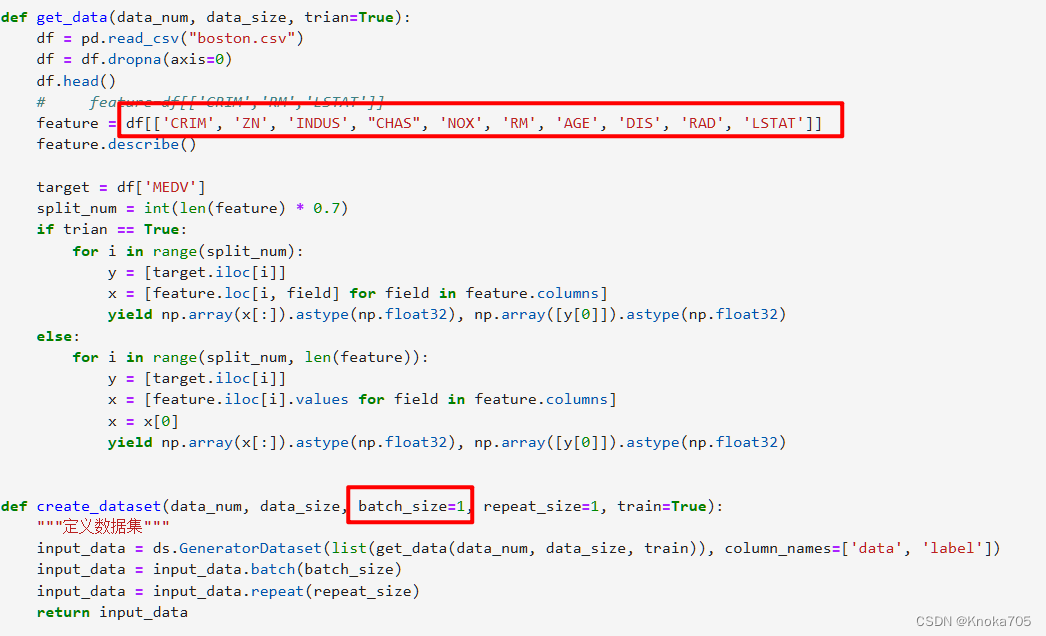
此部分为模型训练和保存代码,注意模型训练所用的data数据列为’CRIM’, ‘ZN’, ‘INDUS’, “CHAS”, ‘NOX’, ‘RM’, ‘AGE’, ‘DIS’, ‘RAD’, 'LSTAT’几列,并不是13列全用
import numpy as np
import mindspore as ms
from mindspore import ops, nn
import mindspore.dataset as ds
import mindspore.common.initializer as init
import pandas as pd
from mindspore import context
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend")
def get_data(data_num, data_size, trian=True):
df = pd.read_csv("boston.csv")
df = df.dropna(axis=0)
df.head()
# feature=df[['CRIM','RM','LSTAT']]
feature = df[['CRIM', 'ZN', 'INDUS', "CHAS", 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'LSTAT']]
feature.describe()
target = df['MEDV']
split_num = int(len(feature) * 0.7)
if trian == True:
for i in range(split_num):
y = [target.iloc[i]]
x = [feature.loc[i, field] for field in feature.columns]
yield np.array(x[:]).astype(np.float32), np.array([y[0]]).astype(np.float32)
else:
for i in range(split_num, len(feature)):
y = [target.iloc[i]]
x = [feature.iloc[i].values for field in feature.columns]
x = x[0]
yield np.array(x[:]).astype(np.float32), np.array([y[0]]).astype(np.float32)
def create_dataset(data_num, data_size, batch_size=1, repeat_size=1, train=True):
"""定义数据集"""
input_data = ds.GeneratorDataset(list(get_data(data_num, data_size, train)), column_names=['data', 'label'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
class MyNet(nn.Cell):
"""定义网络"""
def __init__(self, input_size=32):
super(MyNet, self).__init__()
self.fc1 = nn.Dense(10, 1, weight_init=init.Normal(0.02))
self.relu = nn.ReLU()
def construct(self, x):
x = self.relu(self.fc1(x))
return x
class MyL1Loss(nn.LossBase):
"""定义损失"""
def __init__(self, reduction="mean"):
super(MyL1Loss, self).__init__(reduction)
self.abs = ops.Abs()
def construct(self, base, target):
x = self.abs(base - target)
return self.get_loss(x)
class MyMomentum(nn.Optimizer):
"""使用ApplyMomentum算子定义优化器"""
def __init__(self, params, learning_rate, momentum=0.9, use_nesterov=False):
super(MyMomentum, self).__init__(learning_rate, params)
self.moments = self.parameters.clone(prefix="moments", init="zeros")
self.momentum = momentum
self.opt = ops.ApplyMomentum(use_nesterov=use_nesterov)
def construct(self, gradients):
params = self.parameters
success = None
for param, mom, grad in zip(params, self.moments, gradients):
success = self.opt(param, mom, self.learning_rate, grad, self.momentum)
return success
class MyWithLossCell(nn.Cell):
"""定义损失网络"""
def __init__(self, backbone, loss_fn):
super(MyWithLossCell, self).__init__(auto_prefix=False)
self.backbone = backbone
self.loss_fn = loss_fn
def construct(self, data, label):
out = self.backbone(data)
return self.loss_fn(out, label)
def backbone_network(self):
return self.backbone
class MyTrainStep(nn.TrainOneStepCell):
"""定义训练流程"""
def __init__(self, network, optimizer):
"""参数初始化"""
super(MyTrainStep, self).__init__(network, optimizer)
self.grad = ops.GradOperation(get_by_list=True)
def construct(self, data, label):
"""构建训练过程"""
weights = self.weights
loss = self.network(data, label)
grads = self.grad(self.network, weights)(data, label)
return loss, self.optimizer(grads)
# 生成多项式分布的数据
dataset_size = 64
ds_train = create_dataset(2048, dataset_size)
# 网络
net = MyNet()
# 损失函数
loss_func = MyL1Loss()
# 优化器
opt = MyMomentum(net.trainable_params(), 0.0001)
# 构建损失网络
net_with_criterion = MyWithLossCell(net, loss_func)
# 构建训练网络
train_net = MyTrainStep(net_with_criterion, opt)
# 执行训练,每个epoch打印一次损失值
epochs = 50
for epoch in range(epochs):
for train_x, train_y in ds_train:
train_net(train_x, train_y)
# print(train_x.shape)
# print(train_x.shape)
# print(train_x,train_y)
loss_val = net_with_criterion(train_x, train_y)
# print(loss_val)
class MyMAE(nn.Metric):
"""定义metric"""
def __init__(self):
super(MyMAE, self).__init__()
self.clear()
def clear(self):
self.abs_error_sum = 0
self.samples_num = 0
def update(self, *inputs):
y_pred = inputs[0].asnumpy()
y = inputs[1].asnumpy()
error_abs = np.abs(y.reshape(y_pred.shape) - y_pred)
self.abs_error_sum += error_abs.sum()
self.samples_num += y.shape[0]
def eval(self):
return self.abs_error_sum / self.samples_num
class MyWithEvalCell(nn.Cell):
"""定义验证流程"""
def __init__(self, network):
super(MyWithEvalCell, self).__init__(auto_prefix=False)
self.network = network
def construct(self, data, label):
outputs = self.network(data)
return outputs, label
# 获取验证数据
ds_eval = create_dataset(128, dataset_size, 1, train=False)
# 定义评估网络
eval_net = MyWithEvalCell(net)
eval_net.set_train(False)
# 定义评估指标
mae = MyMAE()
# 执行推理过程
for eval_x, eval_y in ds_eval:
output, eval_y = eval_net(eval_x, eval_y)
mae.update(output, eval_y)
print("output is {} label is {}".format(output, eval_y))
mae_result = mae.eval()
print("mae on val_set: ", mae_result)
ms.save_checkpoint(net, "./MyNet.ckpt")
运行上述代码,可以得到ckpt模型,接下来是进行推理,验证数据形式
net = MyNet()
ms.load_checkpoint("MyNet.ckpt", net=net)
ls=[[0.00632,18,2.31,0,0.538,6.575,65.2,4.09,1,296]]
np_array = np.array(ls)
input_np = np_array.astype(np.float32)
output = net(ms.Tensor(input_np))
print(output)
运行可以发现,能够得到推理结果,代表数据形式正确
即为一个二维列表-》numpy形式-》tensor形式
然后可以按照示例,根据自己代码进行模型转换,得到mindir模型文件
import numpy as np
import mindspore as ms
net = MyNet()
ms.load_checkpoint("MyNet.ckpt", net=net)
ls=[[0.00632,18,2.31,0,0.538,6.575,65.2,4.09,1,296]]
np_array = np.array(ls)
input_np = np_array.astype(np.float32)
ms.export(net, ms.Tensor(input_np), file_name='mind', file_format='MINDIR')
3.2 数据
即为波斯顿房价预测案例数据,这里就不再放了,只放个简单示例,可以自己直接去搜寻并下载
CRIM,ZN,INDUS,CHAS,NOX,RM,AGE,DIS,RAD,TAX,PIRATIO,B,LSTAT,MEDV
0.00632,18,2.31,0,0.538,6.575,65.2,4.09,1,296,15.3,396.9,4.98,24
0.02731,0,7.07,0,0.469,6.421,78.9,4.9671,2,242,17.8,396.9,9.14,21.6
0.02729,0,7.07,0,0.469,7.185,61.1,4.9671,2,242,17.8,392.83,4.03,34.7
0.03237,0,2.18,0,0.458,6.998,45.8,6.0622,3,222,18.7,394.63,2.94,33.4
0.06905,0,2.18,0,0.458,7.147,54.2,6.0622,3,222,18.7,396.9,5.33,36.2
0.02985,0,2.18,0,0.458,6.43,58.7,6.0622,3,222,18.7,394.12,5.21,28.7
0.08829,12.5,7.87,0,0.524,6.012,66.6,5.5605,5,311,15.2,395.6,12.43,22.9
0.14455,12.5,7.87,0,0.524,6.172,96.1,5.9505,5,311,15.2,396.9,19.15,27.1
0.21124,12.5,7.87,0,0.524,5.631,100,6.0821,5,311,15.2,386.63,29.93,16.5
0.17004,12.5,7.87,0,0.524,6.004,85.9,6.5921,5,311,15.2,386.71,17.1,18.9
0.22489,12.5,7.87,0,0.524,6.377,94.3,6.3467,5,311,15.2,392.52,20.45,15
0.11747,12.5,7.87,0,0.524,6.009,82.9,6.2267,5,311,15.2,396.9,13.27,18.9
0.09378,12.5,7.87,0,0.524,5.889,39,5.4509,5,311,15.2,390.5,15.71,21.7
0.62976,0,8.14,0,0.538,5.949,61.8,4.7075,4,307,21,396.9,8.26,20.4
0.63796,0,8.14,0,0.538,6.096,84.5,4.4619,4,307,21,380.02,10.26,18.2
四、参考文档
1、mindspore教程:https://www.mindspore.cn/tutorials/zh-CN/r1.7/advanced/train/save.html
2、华为mindspore入门-波士顿房价回归:https://blog.csdn.net/weixin_47895059/article/details/123964083
3、mindspore推理模型转换:https://www.mindspore.cn/lite/docs/zh-CN/r1.3/use/converter_tool.html