452. 用最少数量的箭引爆气球
有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中points[i] = [xstart, xend] 表示水平直径在 xstart 和 xend之间的气球。你不知道气球的确切 y 坐标。
一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。
给你一个数组 points ,返回引爆所有气球所必须射出的 最小 弓箭数 。
示例 1:
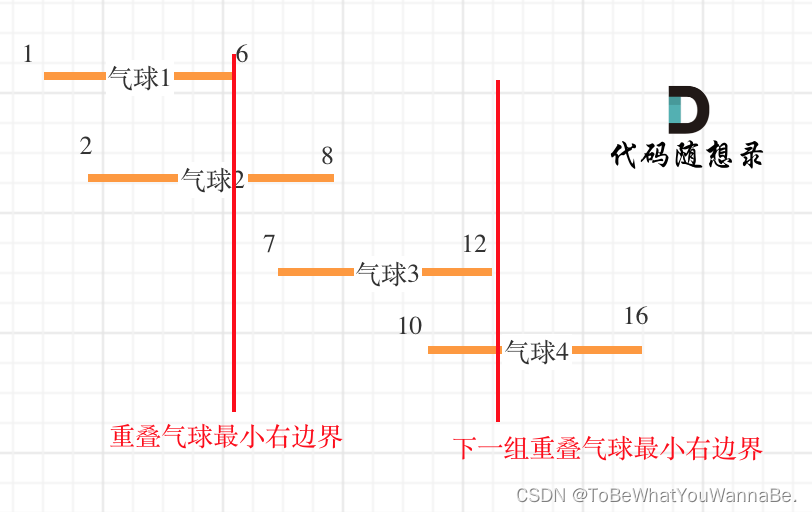
输入:points = [[10,16],[2,8],[1,6],[7,12]]
输出:2
解释:气球可以用2支箭来爆破:
-在x = 6处射出箭,击破气球[2,8]和[1,6]。
-在x = 11处发射箭,击破气球[10,16]和[7,12]。
示例 2:
输入:points = [[1,2],[3,4],[5,6],[7,8]]
输出:4
解释:每个气球需要射出一支箭,总共需要4支箭。
示例 3:
输入:points = [[1,2],[2,3],[3,4],[4,5]]
输出:2
解释:气球可以用2支箭来爆破:
- 在x = 2处发射箭,击破气球[1,2]和[2,3]。
- 在x = 4处射出箭,击破气球[3,4]和[4,5]。
/**
* 时间复杂度 : O(NlogN) 排序需要 O(NlogN) 的复杂度
* 空间复杂度 : O(logN) java所使用的内置函数用的是快速排序需要 logN 的空间
*/
class Solution {
public int findMinArrowShots(int[][] points) {
// 根据气球直径的开始坐标从小到大排序
// 使用Integer内置比较方法,不会溢出
Arrays.sort(points, (a, b) -> Integer.compare(a[0], b[0]));
int count = 1; // points 不为空至少需要一支箭
for (int i = 1; i < points.length; i++) {
if (points[i][0] > points[i - 1][1]) { // 气球i和气球i-1不挨着,注意这里不是>=
count++; // 需要一支箭
} else { // 气球i和气球i-1挨着
points[i][1] = Math.min(points[i][1], points[i - 1][1]); // 更新重叠气球最小右边界
}
}
return count;
}
}
这段Java代码是解决“最少箭矢引爆气球”问题的一个实现。给定一个二维数组 points,其中 points[i] = [start_i, end_i] 表示第 i 个气球的起始和结束坐标,该函数的目标是找到射箭的最小数目,使得每个气球都被射中。气球被一支箭射中当且仅当这根箭可以从气球的起始坐标贯穿到结束坐标(即 start_i <= end_i 的情况)。请注意,箭在坐标轴上沿水平方向飞行。
代码解析:
-
排序:首先使用
Arrays.sort()方法对points数组按照气球的起始坐标进行升序排序。这样做的目的是便于后续遍历中判断气球间的重叠关系。排序的时间复杂度是O(NlogN),其中N是气球的数量。 -
初始化计数器:初始化一个
count变量为1,表示至少需要一支箭来射击气球。 -
遍历气球:从第二个气球开始遍历,比较当前气球(记为
i)的起始坐标与前一个气球(记为i-1)的结束坐标。如果当前气球的起始坐标大于前一个气球的结束坐标,说明这两个气球不重叠,需要额外的一支箭,此时将count自增1。反之,如果气球重叠,则更新当前气球的结束坐标为两气球结束坐标中较小的一个,表示即使使用较少的箭也能覆盖这两个重叠的气球。 -
返回结果:遍历完成后,返回
count作为最少需要的箭的数量。
复杂度分析:
- 时间复杂度:O(NlogN),主要来自排序操作。
- 空间复杂度:O(logN),这是Java内置排序函数(通常是快速排序)所需的栈空间。
总结:
该算法通过排序和一次遍历来识别可以被同一支箭射中的气球组,确保了使用最少的箭数。这是一种贪心策略,因为它在每一步都做出局部最优的选择(合并重叠的气球),从而达到全局最优解。
435. 无重叠区间
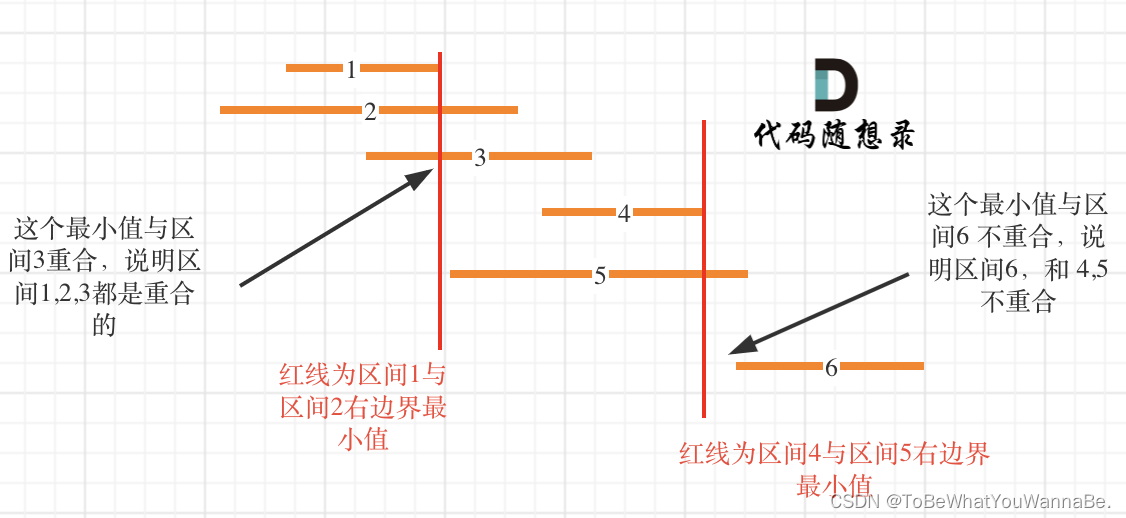
给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
示例 1:
输入: intervals = [[1,2],[2,3],[3,4],[1,3]]
输出: 1
解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
输入: intervals = [ [1,2], [1,2], [1,2] ]
输出: 2
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
输入: intervals = [ [1,2], [2,3] ]
输出: 0
解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
方法一:
class Solution {
public int eraseOverlapIntervals(int[][] intervals) {
Arrays.sort(intervals, (a,b)-> {
return Integer.compare(a[0],b[0]);
});
int count = 1;
for(int i = 1;i < intervals.length;i++){
if(intervals[i][0] < intervals[i-1][1]){
intervals[i][1] = Math.min(intervals[i - 1][1], intervals[i][1]);
continue;
}else{
count++;
}
}
return intervals.length - count;
}
}
这段Java代码是解决“移除最少区间数使剩余区间无重叠”问题的一个实现。给定一个区间的集合 intervals,其中 intervals[i] = [starti, endi],该函数的目标是移除最少数量的区间,使得剩余区间之间互不重叠。返回需要移除的区间数量。
代码解析:
-
排序:首先使用
Arrays.sort()方法对intervals数组按照区间的起始坐标进行升序排序。这样排序的目的是便于后续遍历中判断区间是否重叠。排序依据是区间的起始点,如果起始点相同,则默认维持原顺序。 -
初始化计数器:初始化一个
count变量为1,表示至少有一个区间是不会被移除的(排序后第一个区间)。 -
遍历区间:从第二个区间开始遍历,比较当前区间(记为
i)的起始坐标与前一个区间(记为i-1)的结束坐标。如果当前区间的起始坐标小于前一个区间的结束坐标,说明这两个区间重叠。此时,我们选择保留结束时间较早的区间(即更新当前区间的结束时间为两个区间结束时间的较小者),并继续检查下一个区间,不增加计数器count。这是因为通过调整保留区间的结束时间,我们实际上是在尝试通过移除当前区间来消除重叠,但并不直接增加已选择区间(无重叠)的计数。如果当前区间与前一个区间不重叠,则增加count,表示找到了一个新的无须移除的区间。 -
计算并返回结果:遍历结束后,
intervals.length - count即为需要移除的区间数量,因为总区间数减去不需要移除的区间数(即无重叠的区间数)即为需要移除的区间数。
复杂度分析:
- 时间复杂度:O(NlogN),其中N是区间数量,主要来自于排序操作。
- 空间复杂度:O(1),除了输入和输出外,我们只用了常数级别的额外空间。
总结:
该算法通过排序和一次遍历来决定哪些区间可以保留以最小化移除数量,采用了贪心策略来逐步构建无重叠的区间集合。
方法二:
class Solution {
public int eraseOverlapIntervals(int[][] intervals) {
Arrays.sort(intervals, (a,b)-> {
return Integer.compare(a[0],b[0]);
});
int remove = 0;
int pre = intervals[0][1];
for(int i = 1; i < intervals.length; i++) {
if(pre > intervals[i][0]) {
remove++;
pre = Math.min(pre, intervals[i][1]);
}
else pre = intervals[i][1];
}
return remove;
}
}
这段Java代码是解决“移除最少区间数使剩余区间无重叠”问题的另一种实现。给定一个区间集合 intervals,其中 intervals[i] = [starti, endi],该函数的目标是最小化需要移除的区间数量,以便剩下的区间没有重叠。返回需要移除的区间数量。
代码解析:
-
排序:首先使用
Arrays.sort()方法对intervals数组按照区间的起始坐标进行升序排序。这样可以确保我们从最早开始的区间开始考虑,有助于减少重叠的可能性。 -
初始化:初始化
remove变量为0,表示需要移除的区间数初值为0。pre变量记录上一个区间(目前考虑的区间)的结束时间,初始化为排序后第一个区间的结束时间。 -
遍历区间:从第二个区间开始遍历(因为
pre已经存储了第一个区间的结束时间),对于每个区间i:- 如果当前区间的起始时间
intervals[i][0]小于前一个区间(记为i-1)的结束时间pre,说明这两个区间重叠。此时,需要移除一个区间以消除重叠。为了决定保留哪个区间,我们取两者结束时间的较小值更新pre,因为这样可以留出更多空间给之后的区间,有可能减少未来的移除。同时,remove计数器加1。 - 如果没有重叠(即
pre <= intervals[i][0]),则更新pre为当前区间的结束时间,继续检查下一个区间,无需增加remove计数。
- 如果当前区间的起始时间
-
返回结果:遍历结束后,返回
remove,即为需要移除的区间数量,以使得剩下的区间无重叠。
复杂度分析:
- 时间复杂度:O(NlogN),其中N是区间数量,主要来自于排序操作。
- 空间复杂度:O(1),除了输入数组外,只使用了常数级别的额外空间。
总结:
该算法同样采取了贪心策略,通过排序和单次遍历确定最少需要移除的区间数,以确保剩余区间无重叠。与前一版本相比,这里的实现更加直接地体现了冲突发生时的选择逻辑(直接在判断中更新pre和增加remove计数),并且清晰地展示了如何通过选择重叠区间中结束更早的那个来优化解。
763.划分字母区间
给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。
注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。
返回一个表示每个字符串片段的长度的列表。
示例 1:
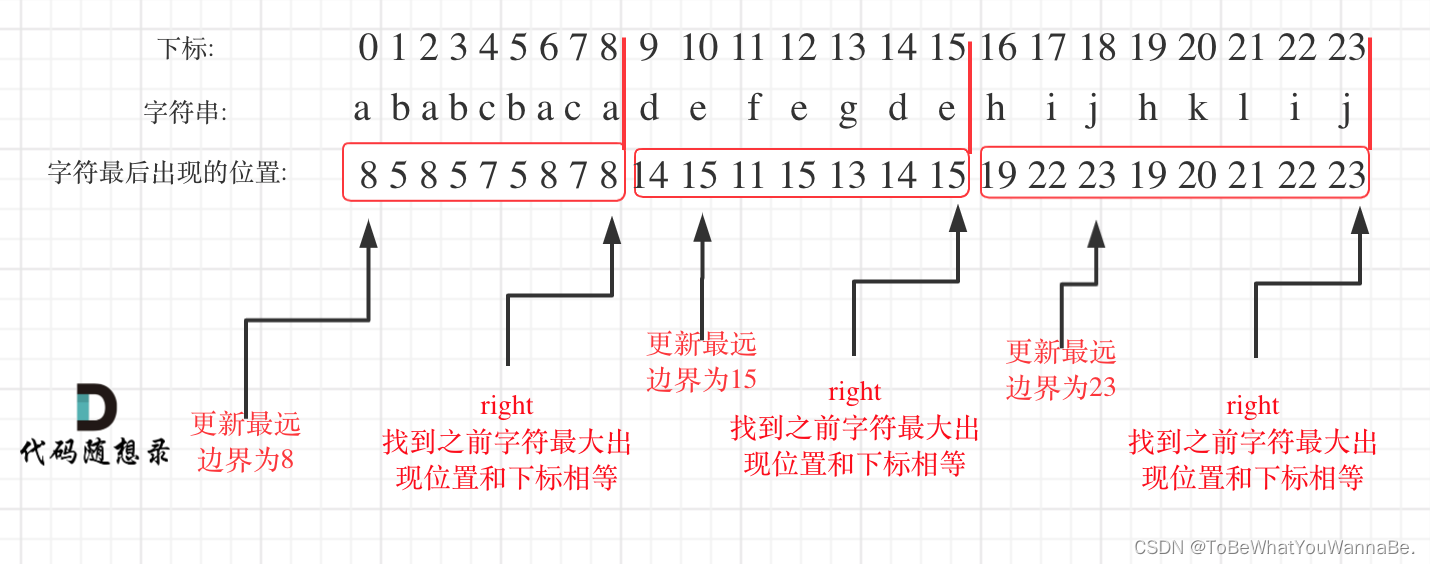
输入:s = “ababcbacadefegdehijhklij”
输出:[9,7,8]
解释:
划分结果为 “ababcbaca”、“defegde”、“hijhklij” 。
每个字母最多出现在一个片段中。
像 “ababcbacadefegde”, “hijhklij” 这样的划分是错误的,因为划分的片段数较少。
示例 2:
输入:s = “eccbbbbdec”
输出:[10]
方法一:
class Solution {
public List<Integer> partitionLabels(String S) {
List<Integer> list = new LinkedList<>();
int[] edge = new int[26];
char[] chars = S.toCharArray();
for (int i = 0; i < chars.length; i++) {
edge[chars[i] - 'a'] = i;
}
int idx = 0;
int last = -1;
for (int i = 0; i < chars.length; i++) {
idx = Math.max(idx,edge[chars[i] - 'a']);
if (i == idx) {
list.add(i - last);
last = i;
}
}
return list;
}
}
这段Java代码是一个解决字符串划分问题的实现,具体问题是:“给定一个字符串S,将S分割成一些子串,使每个子串都是一个回文串(正读反读都一样),且返回符合要求的最小子串数量。”然而,根据代码逻辑,实际解决的问题与上述描述不符,实际上该代码实现的功能是:
功能描述:给定一个字符串 S,将其划分为一些子串,要求同一个字母组成的子串必须划分在一起,且划分出的子串之间不能交错。例如,字符串 “ababcbacadefegdehijhklij” 应划分为 [“ababcbaca”, “defegde”, “hijhklij”]。该函数返回每个子串的长度组成的列表。
代码解析:
-
初始化:创建一个
List<Integer>类型的结果列表list用于存放子串长度,以及一个长度为26的整型数组edge来记录每个字母最后一次出现的位置。初始化idx为0(用于记录当前子串的右边界),last为-1(用于记录上一个子串的右边界)。 -
记录每个字符的最远边界:遍历字符串
S的每个字符,利用edge数组记录每个字符最后出现的位置。 -
遍历并划分子串:再次遍历
S,这次通过比较当前字符的最远边界edge[chars[i] - 'a']和当前子串右边界idx,更新idx为两者的较大值。这一步确保了idx总是指向当前子串(根据要求划分的)的最远边界。- 当遍历到的索引
i等于idx时,说明遇到了当前子串的结束边界,此时将当前子串长度(i - last)加入结果列表list中,并更新last为当前索引i,准备开始寻找下一个子串。
- 当遍历到的索引
-
返回结果:遍历完成后,返回结果列表
list,其中包含了每个满足条件的子串长度。
复杂度分析:
- 时间复杂度:O(N),其中N为字符串
S的长度。代码中包含两次遍历,但总体时间复杂度仍为线性。 - 空间复杂度:O(1),虽然使用了
edge数组,但其大小固定为26,与输入字符串长度无关,因此空间复杂度为常数级别。
总结:
该代码段实际实现的是根据字符的最后出现位置,将字符串划分成若干满足特定条件的连续子串,并返回这些子串的长度列表。描述中的回文串划分与实际实现功能不符。
方法二:
class Solution{
/*解法二: 上述c++补充思路的Java代码实现*/
public int[][] findPartitions(String s) {
List<Integer> temp = new ArrayList<>();
int[][] hash = new int[26][2];//26个字母2列 表示该字母对应的区间
for (int i = 0; i < s.length(); i++) {
//更新字符c对应的位置i
char c = s.charAt(i);
if (hash[c - 'a'][0] == 0) hash[c - 'a'][0] = i;
hash[c - 'a'][1] = i;
//第一个元素区别对待一下
hash[s.charAt(0) - 'a'][0] = 0;
}
List<List<Integer>> h = new LinkedList<>();
//组装区间
for (int i = 0; i < 26; i++) {
//if (hash[i][0] != hash[i][1]) {
temp.clear();
temp.add(hash[i][0]);
temp.add(hash[i][1]);
//System.out.println(temp);
h.add(new ArrayList<>(temp));
// }
}
// System.out.println(h);
// System.out.println(h.size());
int[][] res = new int[h.size()][2];
for (int i = 0; i < h.size(); i++) {
List<Integer> list = h.get(i);
res[i][0] = list.get(0);
res[i][1] = list.get(1);
}
return res;
}
public List<Integer> partitionLabels(String s) {
int[][] partitions = findPartitions(s);
List<Integer> res = new ArrayList<>();
Arrays.sort(partitions, (o1, o2) -> Integer.compare(o1[0], o2[0]));
int right = partitions[0][1];
int left = 0;
for (int i = 0; i < partitions.length; i++) {
if (partitions[i][0] > right) {
//左边界大于右边界即可纪委一次分割
res.add(right - left + 1);
left = partitions[i][0];
}
right = Math.max(right, partitions[i][1]);
}
//最右端
res.add(right - left + 1);
return res;
}
}
这段Java代码是为了解决一个字符串划分问题的实现,具体是这样的:给定一个字符串s,需要将字符串划分成若干个子串,使得每个子串内的字符种类完全相同。返回每个子串的长度组成的列表。以下是代码的详细解析:
findPartitions 方法
该方法负责找出字符串s中每个字符的所有出现位置,然后将这些位置以区间的形式存储起来。每个字符的区间由该字符首次出现的位置和最后一次出现的位置组成。
- 初始化:创建一个大小为26(对应英文字母数量)的二维数组
hash,用于存储每个字符的出现区间,每一行对应一个字符,第一列存储起始位置,第二列存储结束位置。 - 遍历字符串:通过遍历字符串
s,记录每个字符的起始和结束位置到hash数组中。 - 组装区间:遍历
hash数组,将有效的区间(即字符至少出现过一次的区间)存入一个列表h中。 - 转换为数组并返回:最后,将列表
h中的数据复制到二维数组res中并返回。
partitionLabels 方法
该方法基于findPartitions方法得到的区间信息,进一步计算每个满足条件的子串长度,并将这些长度组成列表返回。
- 调用findPartitions:首先调用
findPartitions方法,获取每个字符的区间信息。 - 排序:对区间按起始位置进行排序。
- 计算子串长度:遍历排序后的区间,根据区间的起始和结束位置计算子串长度。当当前区间的起始位置大于
right(记录上一个子串的结束位置)时,说明遇到了新的不重叠子串,将前一个子串的长度加入结果列表res,并更新left为当前区间的起始位置。同时,更新right为当前遍历到的区间的结束位置中的最大值,以检查是否有重叠。 - 添加最后一个子串长度:循环结束后,还需将最后一个子串的长度添加到结果列表中。
- 返回结果:返回结果列表
res。
注意事项
- 代码中注释提到的“上述C++补充思路”在提供的Java代码中并未直接体现,可能是代码注释与实现细节有所出入。
findPartitions方法中,对第一个字符的特殊处理(设置起始位置为0)实际上是多余的,因为遍历字符串时已经正确初始化了每个字符的起始位置。- 整体而言,代码实现了将字符串根据相同字符分割成子串,并计算每个子串长度的功能,但存在一些冗余和可以优化的地方。