游戏推荐系统开题报告
一、引言
随着信息技术和网络技术的飞速发展,电子游戏已成为人们日常生活中不可或缺的一部分。然而,面对海量的游戏资源,用户往往难以找到适合自己的游戏。因此,构建一个高效、准确的游戏推荐系统显得尤为重要。本报告旨在探讨游戏推荐系统的设计与实现,以期为游戏爱好者提供更加个性化的游戏体验。
二、研究背景与意义
- 研究背景
近年来,电子游戏市场持续繁荣,游戏种类和数量不断增加。然而,由于游戏市场的庞大和复杂性,用户往往难以从海量的游戏资源中筛选出符合自己兴趣的游戏。此外,随着大数据和人工智能技术的不断发展,为游戏推荐系统的研究提供了更多的可能性。
- 研究意义
游戏推荐系统可以帮助用户快速找到适合自己的游戏,提高游戏体验。同时,游戏推荐系统也可以为游戏开发者提供有价值的市场信息和用户反馈,帮助他们优化游戏设计。因此,本研究对于提高用户体验和推动游戏市场发展具有重要意义。
三、研究目标与内容
- 研究目标
本研究旨在构建一个基于用户兴趣和行为的游戏推荐系统,实现以下目标:
(1)通过分析用户的历史游戏数据,挖掘用户的游戏兴趣和偏好;
(2)利用机器学习算法,为用户推荐符合其兴趣和偏好的游戏;
(3)优化推荐算法,提高推荐系统的准确性和效率。
- 研究内容
(1)数据收集与预处理:收集用户的历史游戏数据,包括游戏类型、评分、游戏时长等,并进行数据清洗和预处理;
(2)特征提取与选择:从用户数据中提取与游戏推荐相关的特征,如用户兴趣、游戏类型偏好等;
(3)推荐算法设计与实现:基于用户特征和机器学习算法,设计并实现游戏推荐算法;
(4)系统测试与优化:对推荐系统进行测试,并根据测试结果对算法进行优化。
四、研究方法与技术路线
- 研究方法
本研究将采用以下方法:
(1)文献综述:通过查阅相关文献,了解游戏推荐系统的研究现状和趋势;
(2)数据挖掘:运用数据挖掘技术对用户历史数据进行分析和挖掘;
(3)机器学习:利用机器学习算法对用户特征进行建模和预测;
(4)实验验证:通过实验验证推荐系统的准确性和效率。
- 技术路线
(1)数据收集:从游戏平台或第三方数据源收集用户历史游戏数据;
(2)数据预处理:对数据进行清洗、转换和标准化处理;
(3)特征提取:从预处理后的数据中提取与游戏推荐相关的特征;
(4)算法设计:基于提取的特征和机器学习算法,设计游戏推荐算法;
(5)系统实现:将算法集成到游戏推荐系统中,实现用户注册、登录、游戏推荐等功能;
(6)系统测试:对推荐系统进行测试,包括功能测试和性能测试;
(7)优化迭代:根据测试结果对算法进行优化,提高推荐系统的准确性和效率。
五、预期成果与创新点
- 预期成果
(1)构建一个基于用户兴趣和行为的游戏推荐系统;
(2)实现用户注册、登录、游戏推荐等功能;
(3)提高游戏推荐系统的准确性和效率;
(4)为游戏爱好者提供更加个性化的游戏体验。
- 创新点
(1)采用多源数据融合的方法,提高用户特征的准确性和丰富性;
(2)结合用户行为和兴趣,设计一种新型的推荐算法;
(3)利用实时反馈机制,不断优化推荐算法,提高用户体验。
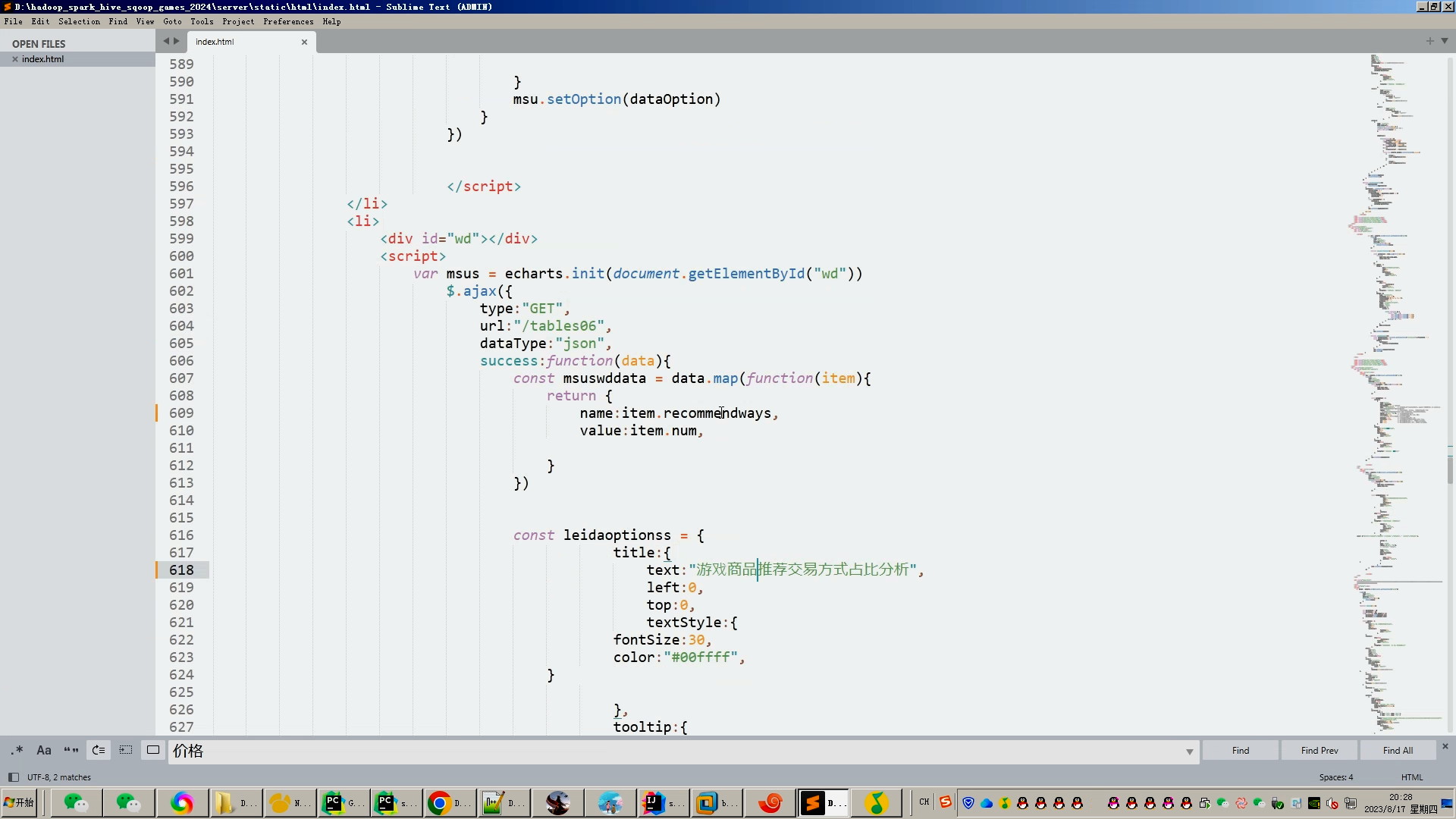
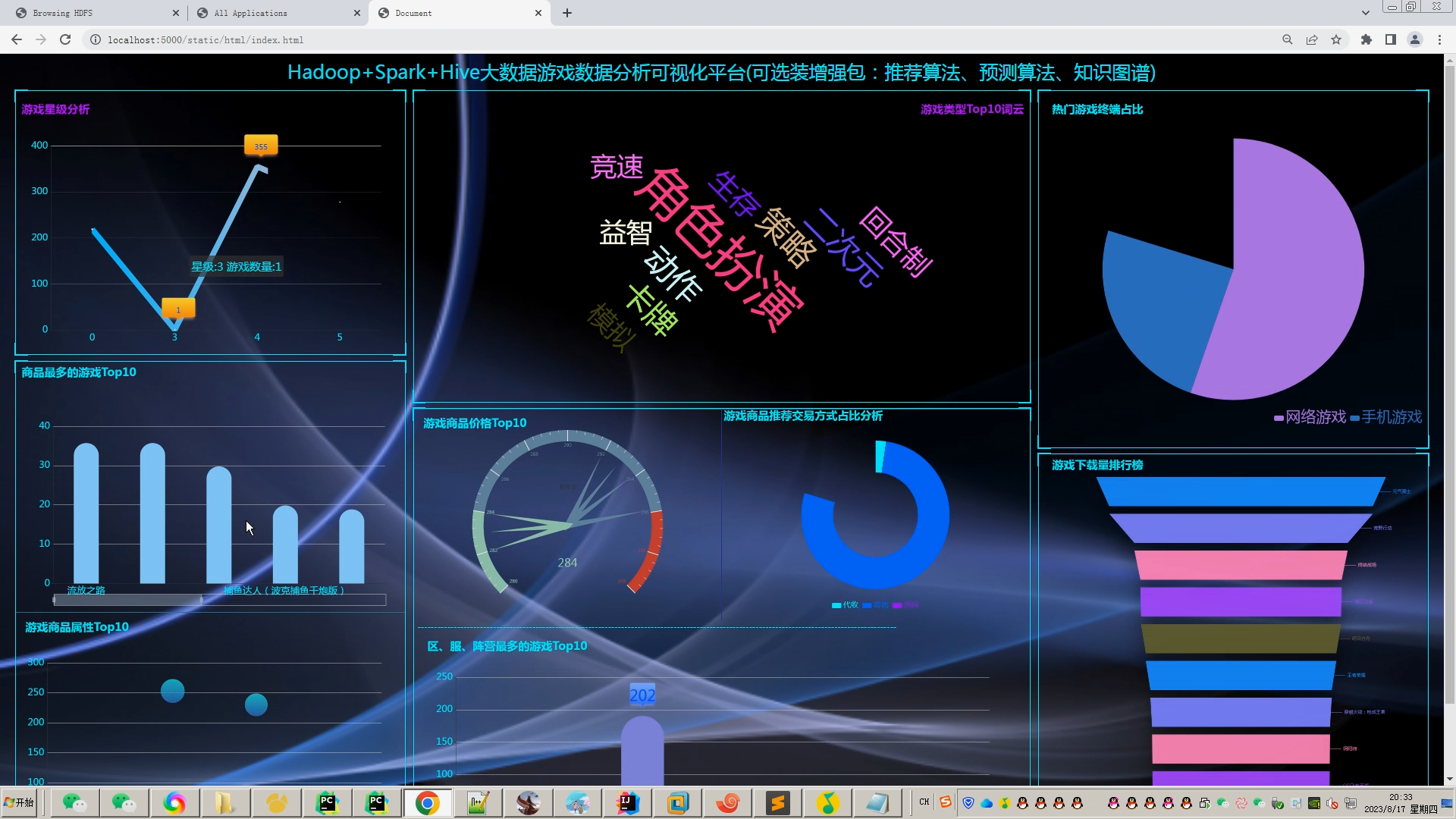
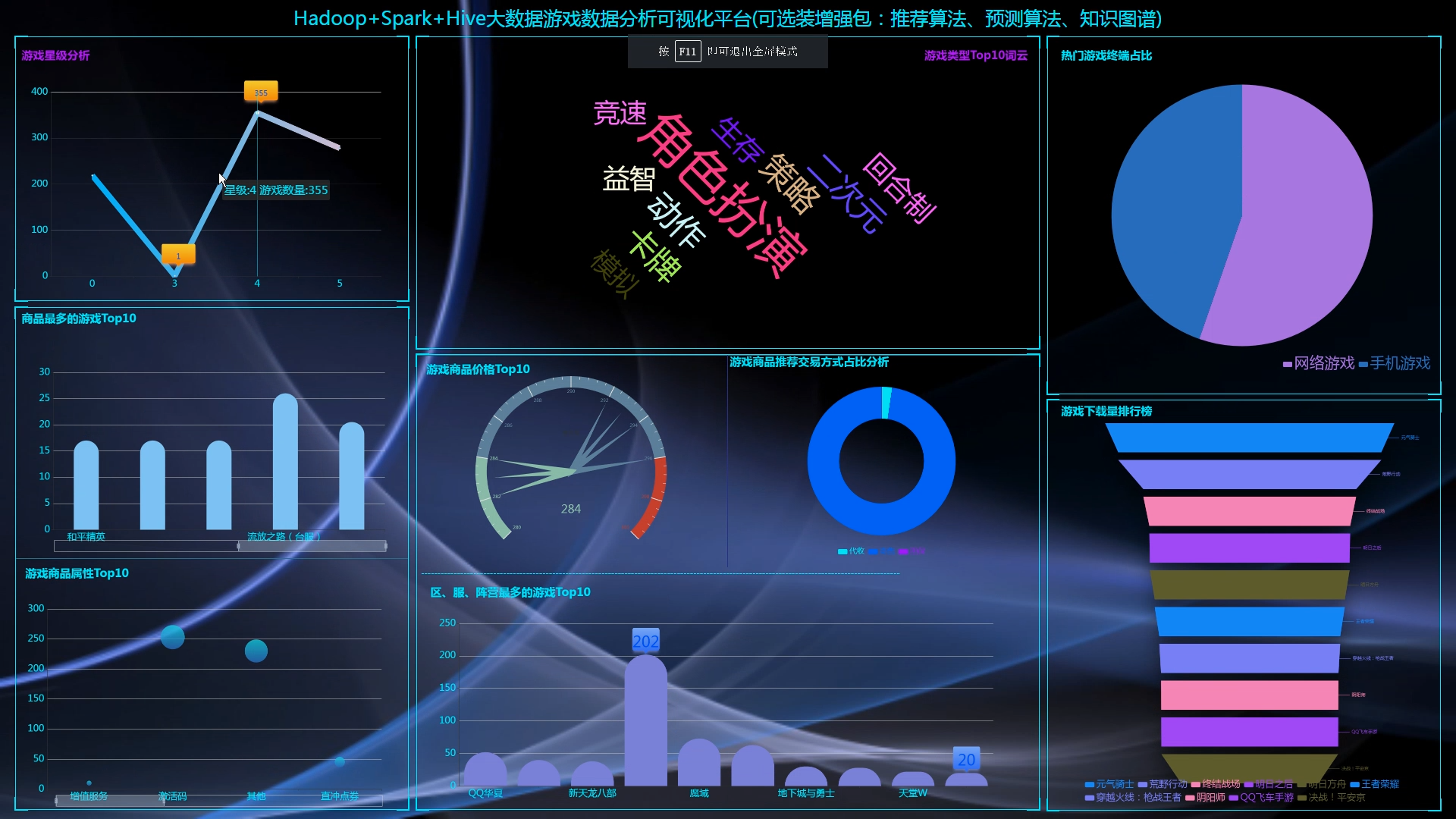
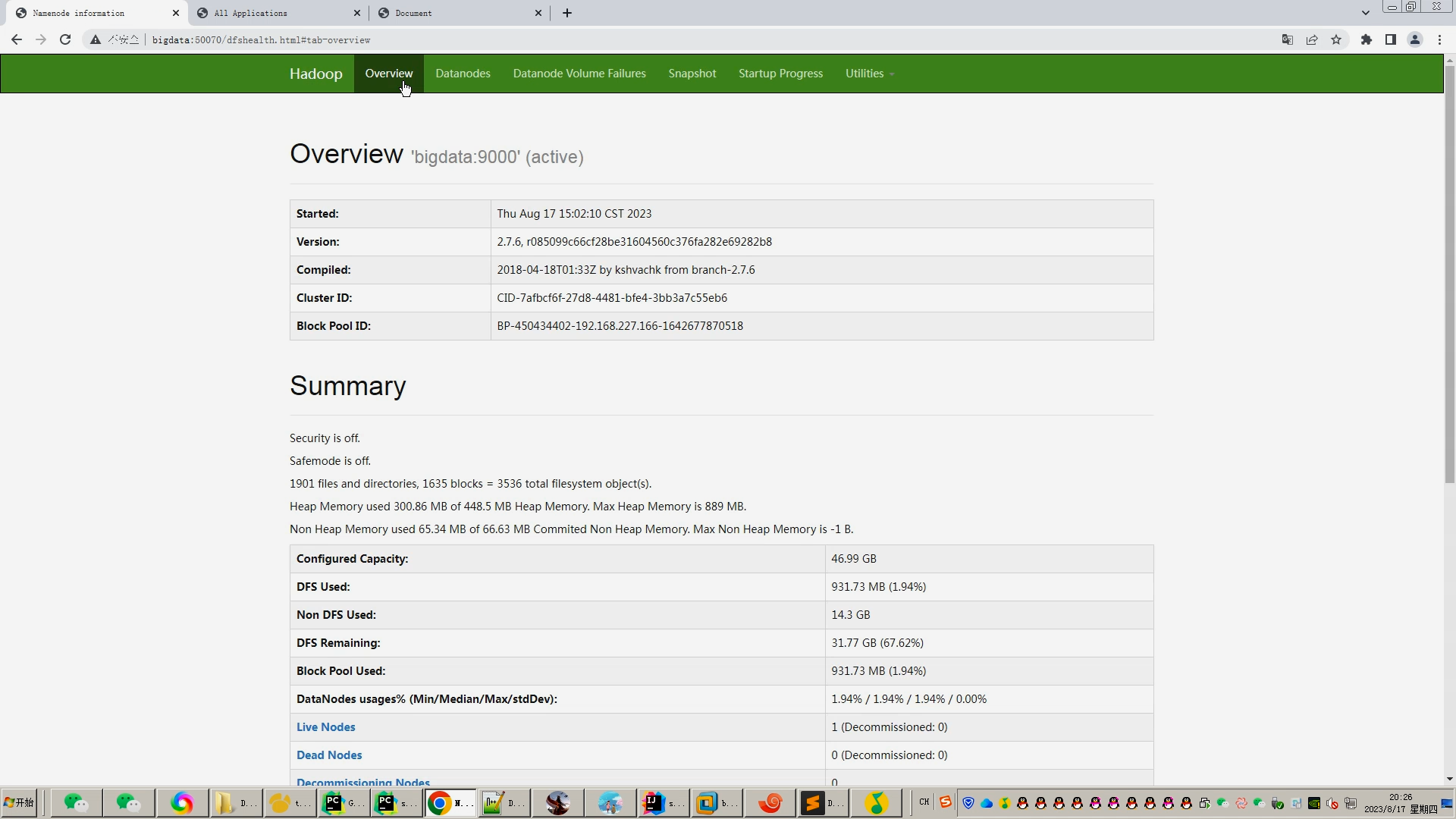

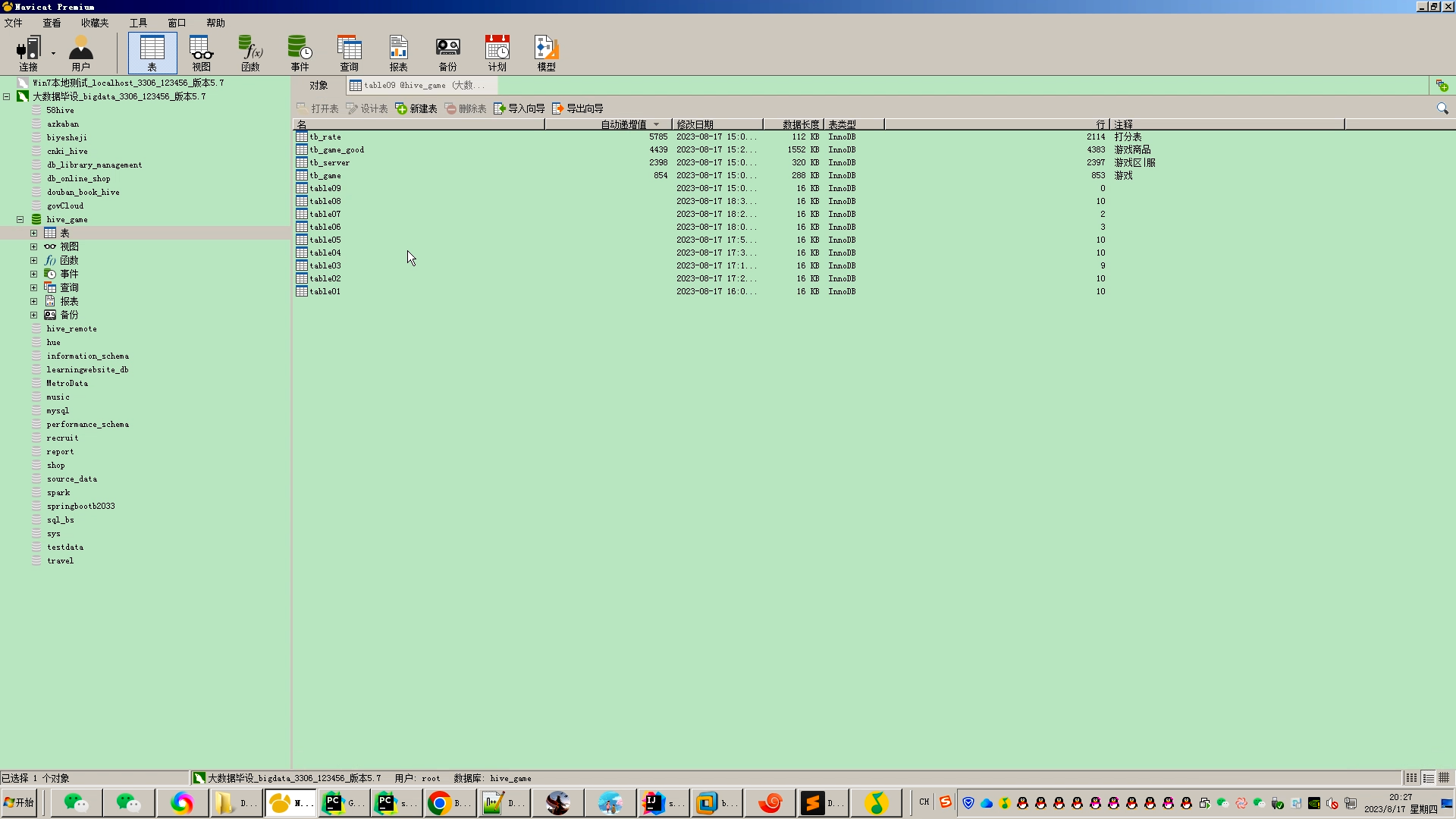

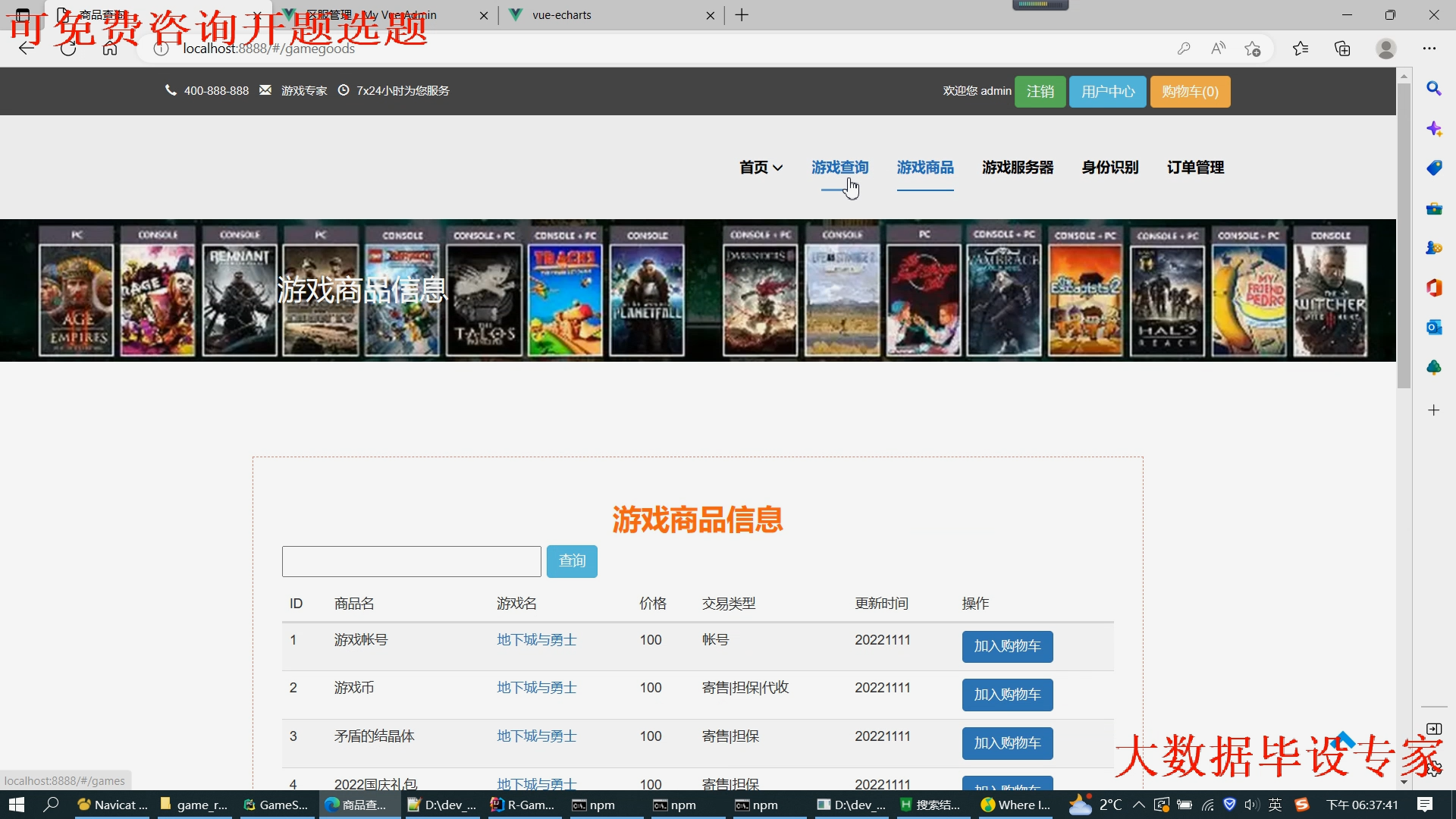
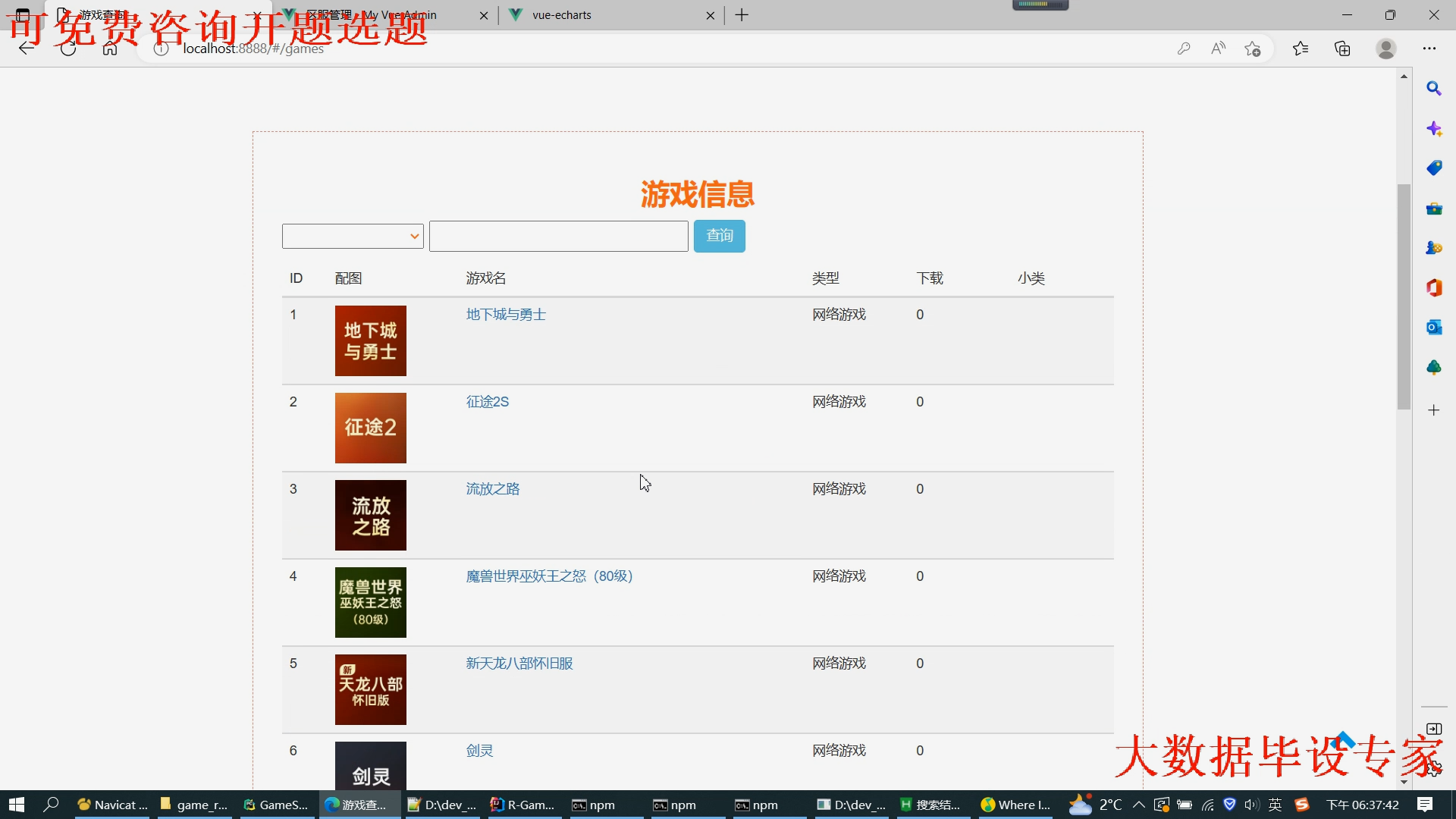
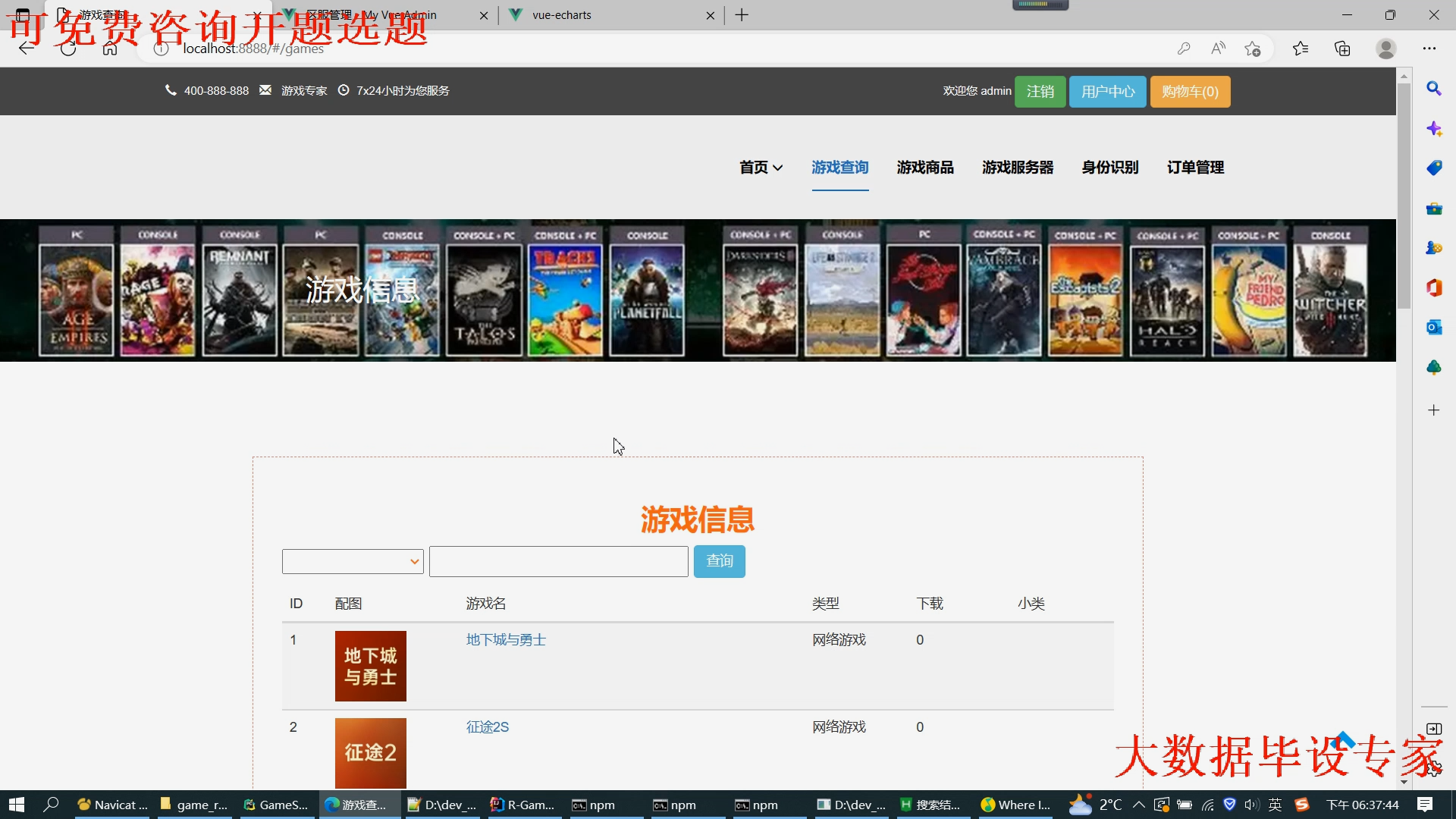
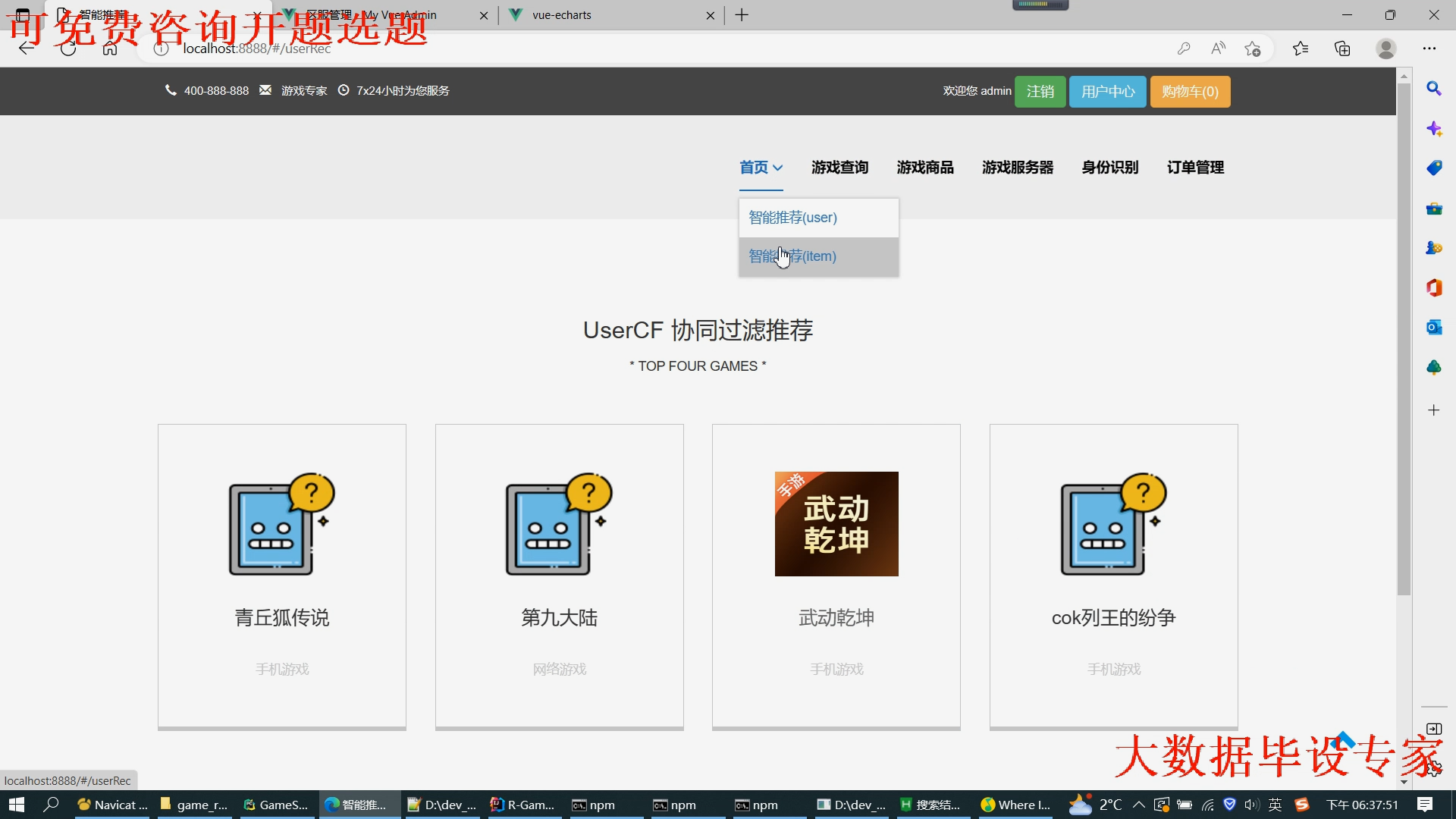
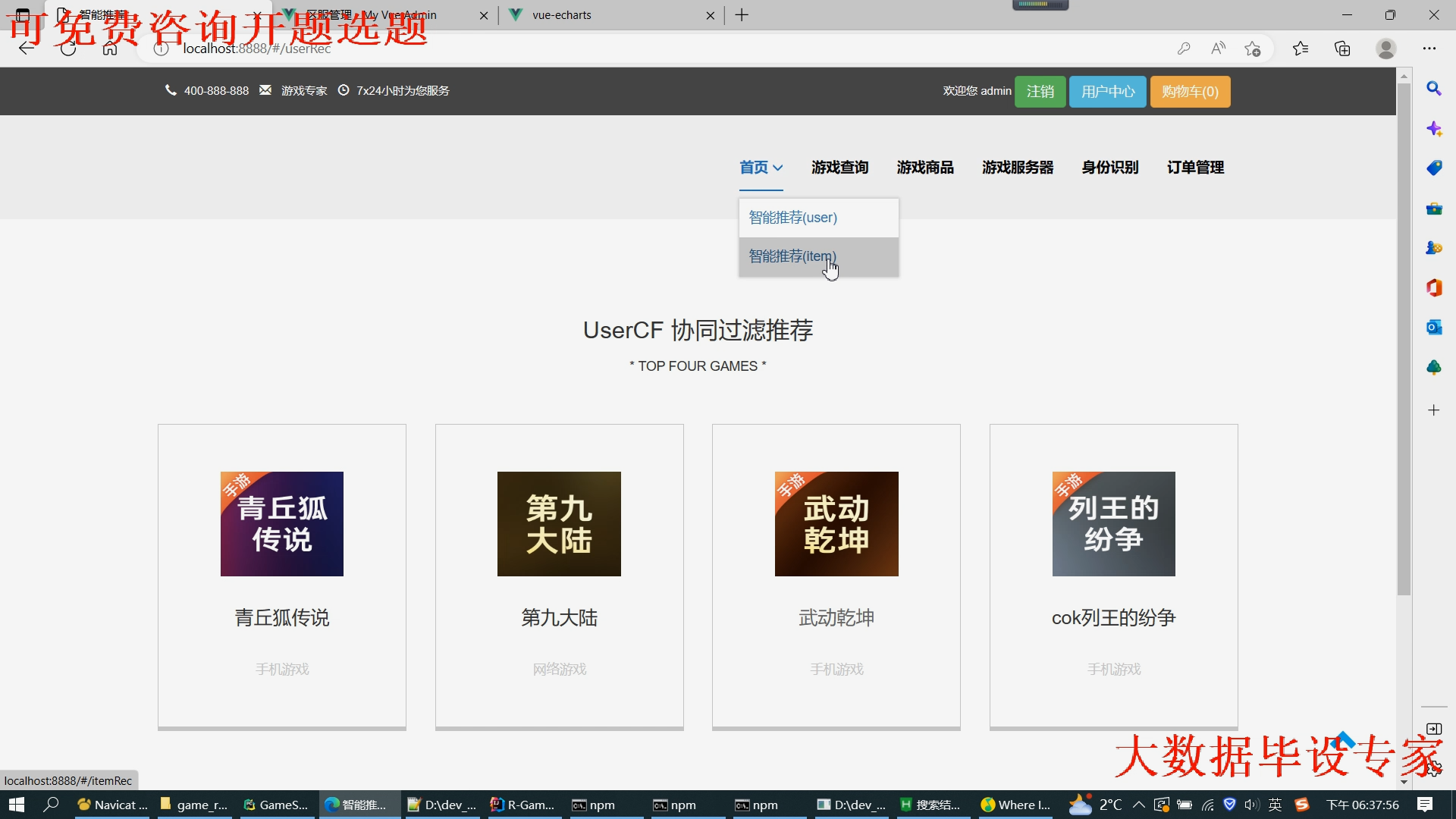
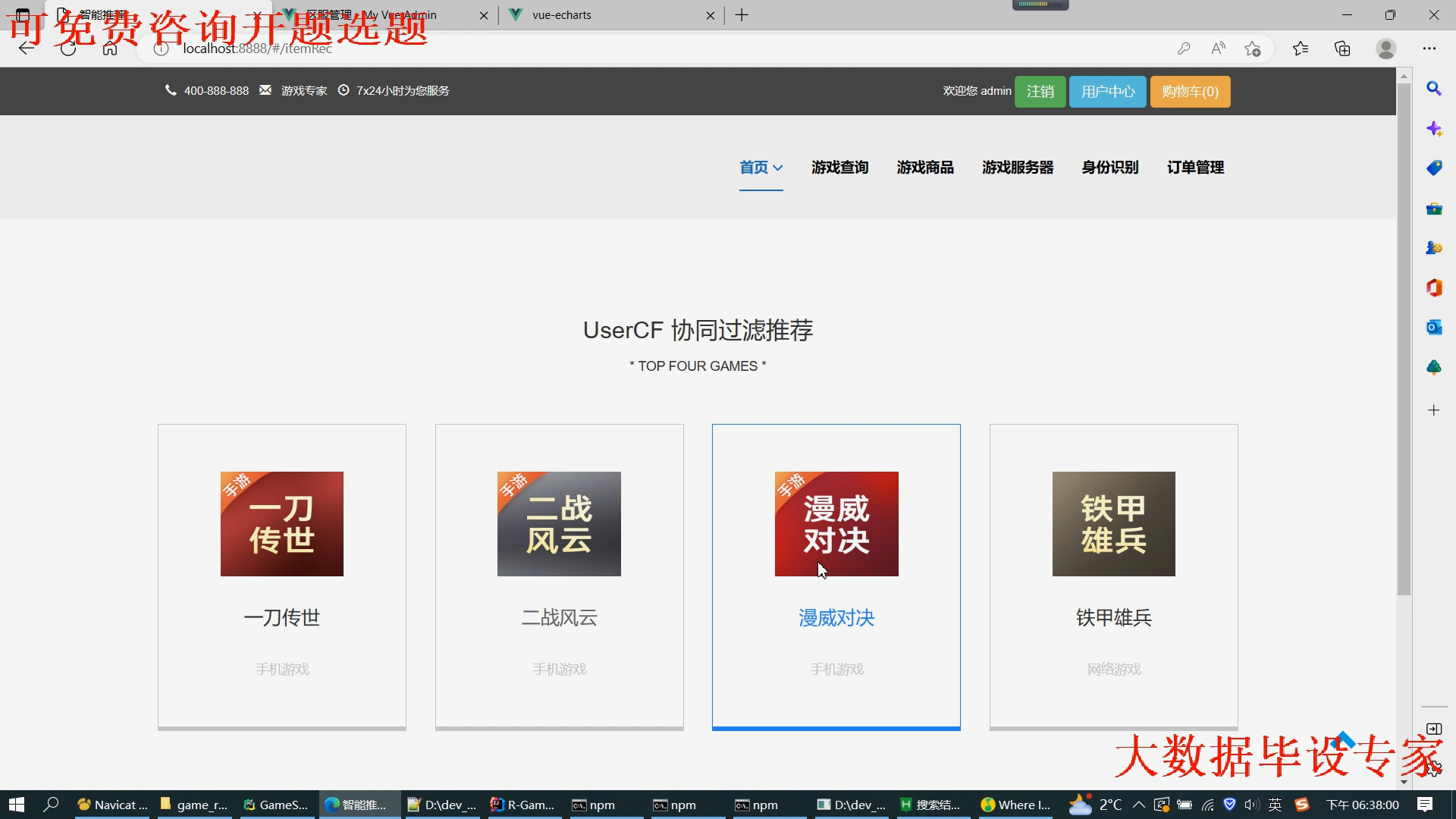
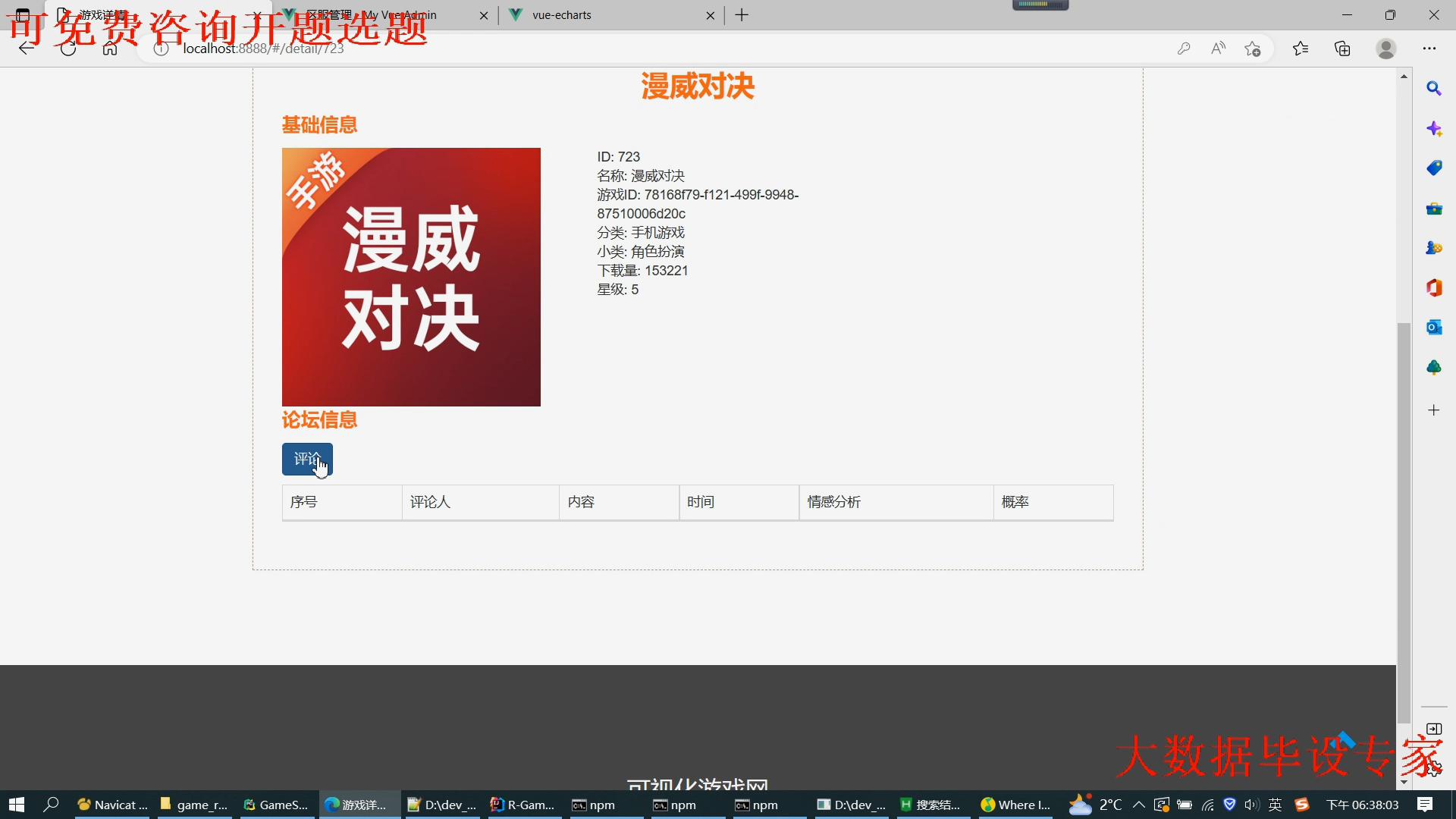
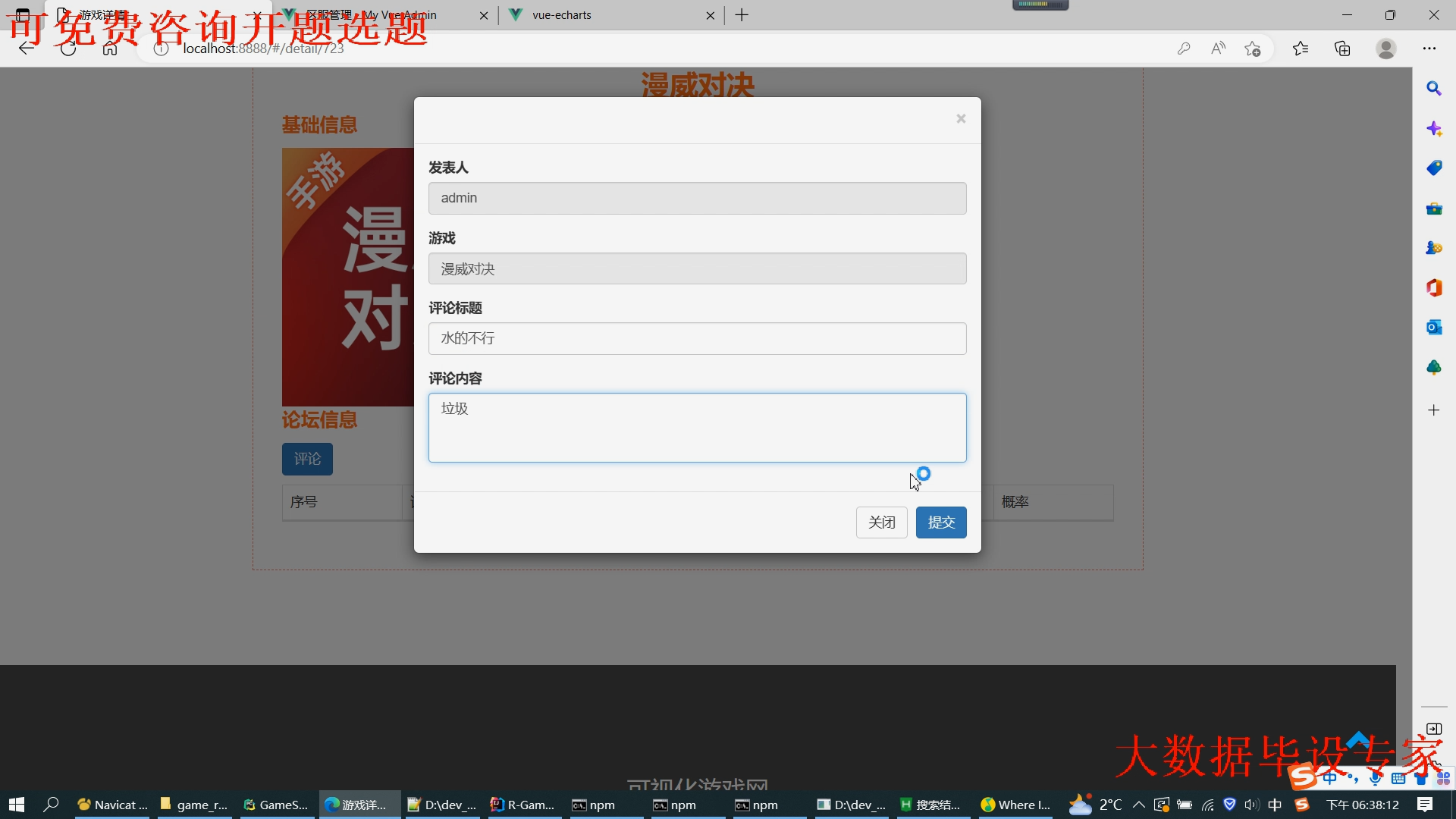
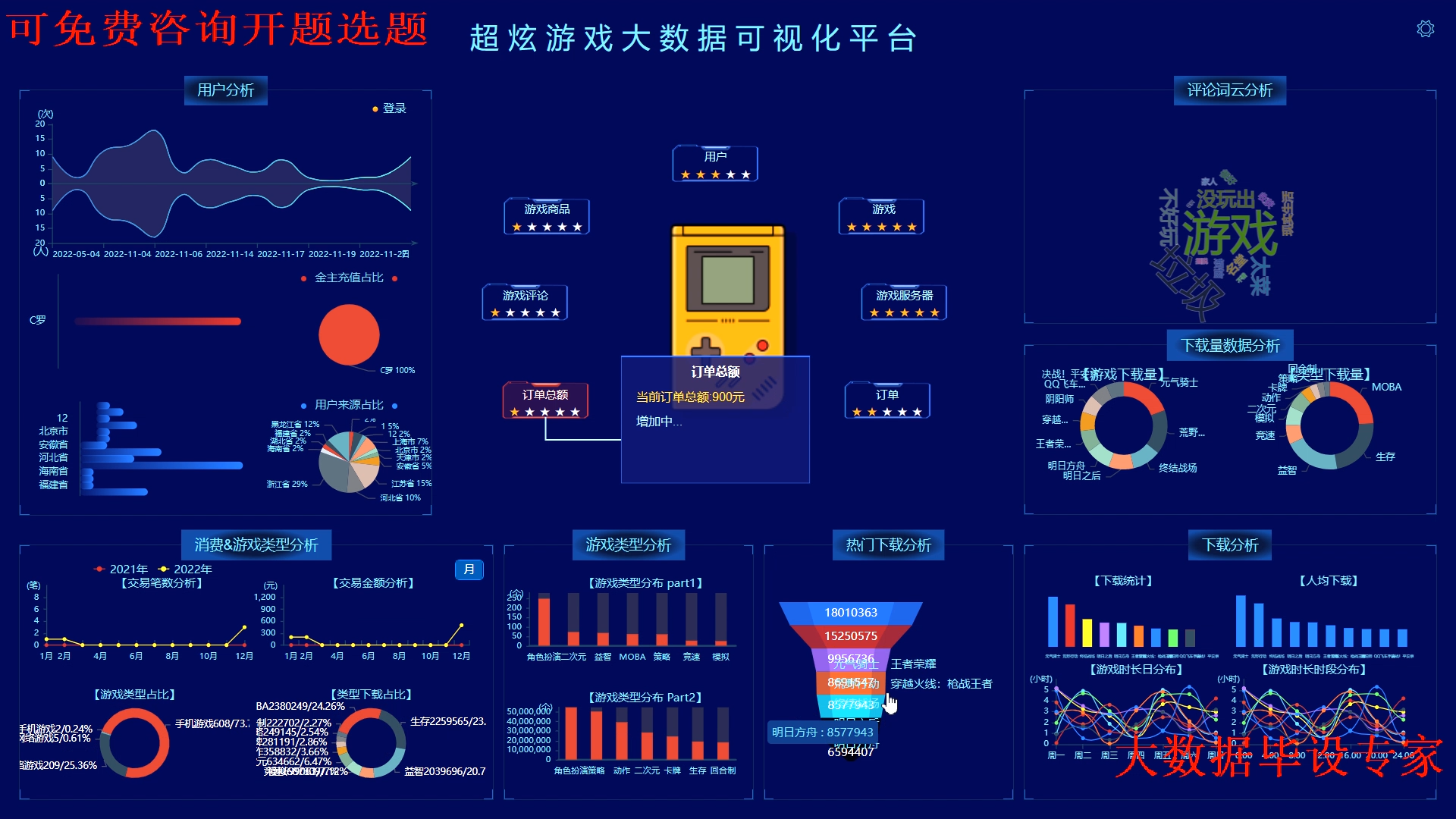
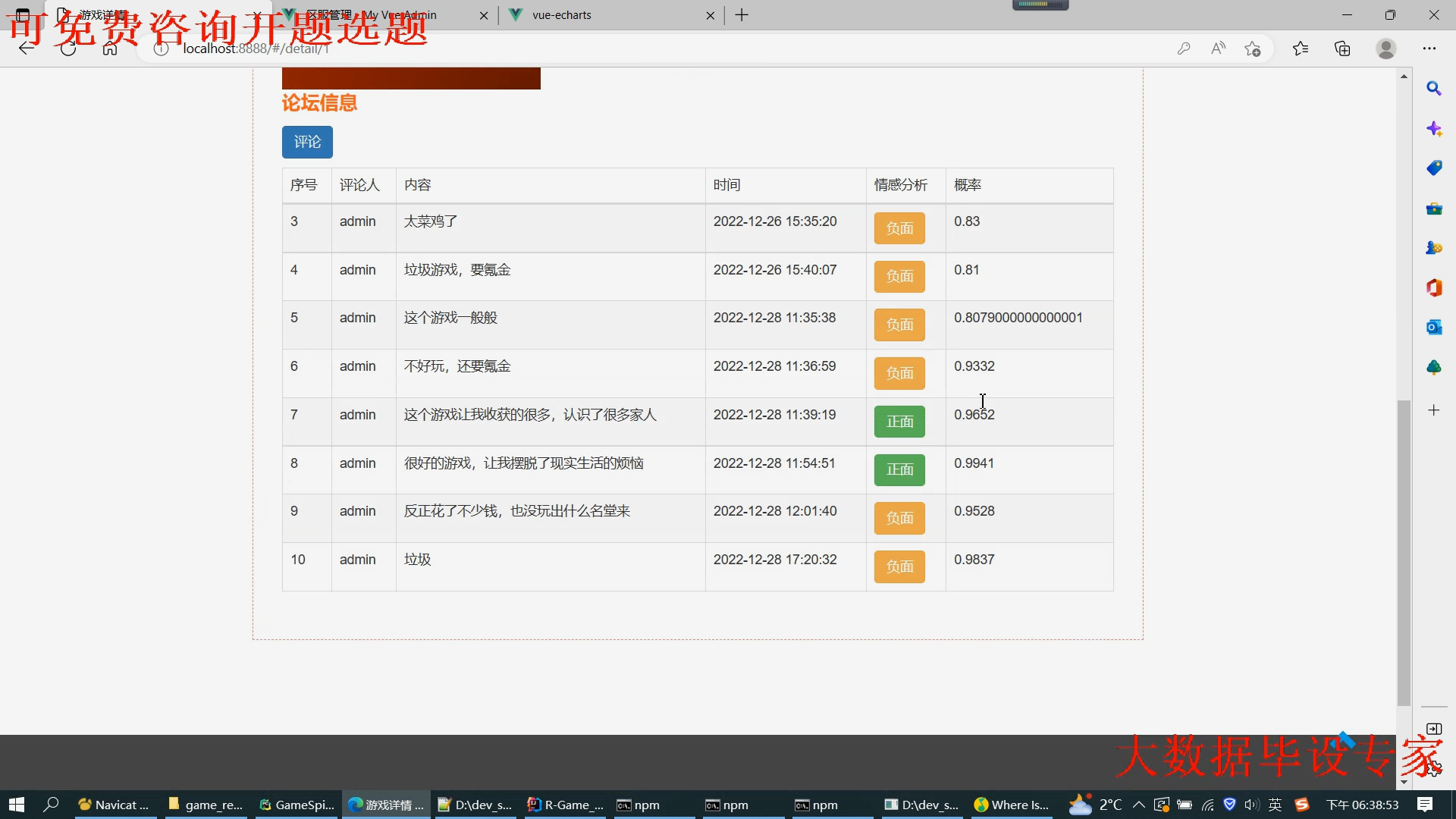
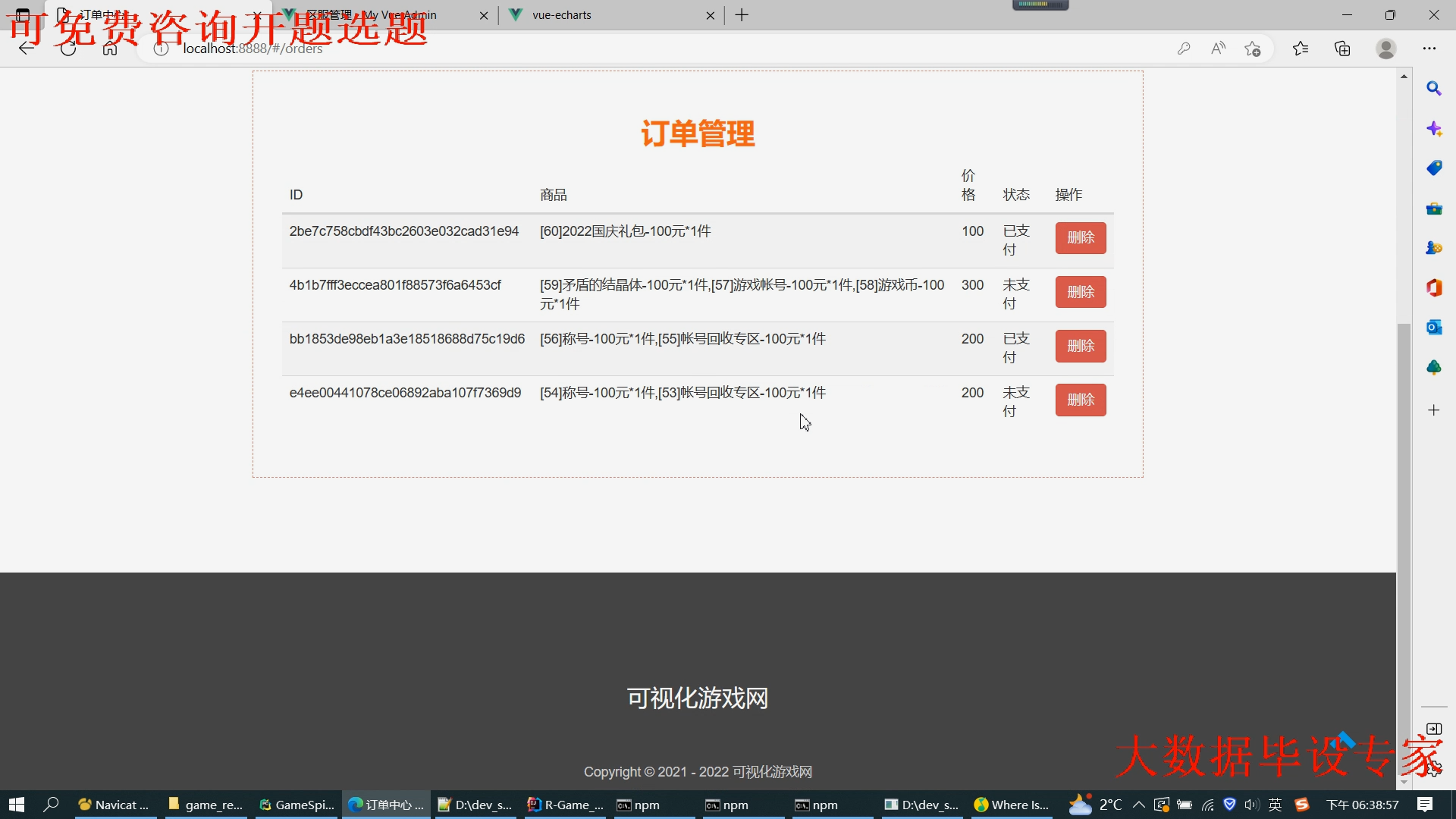
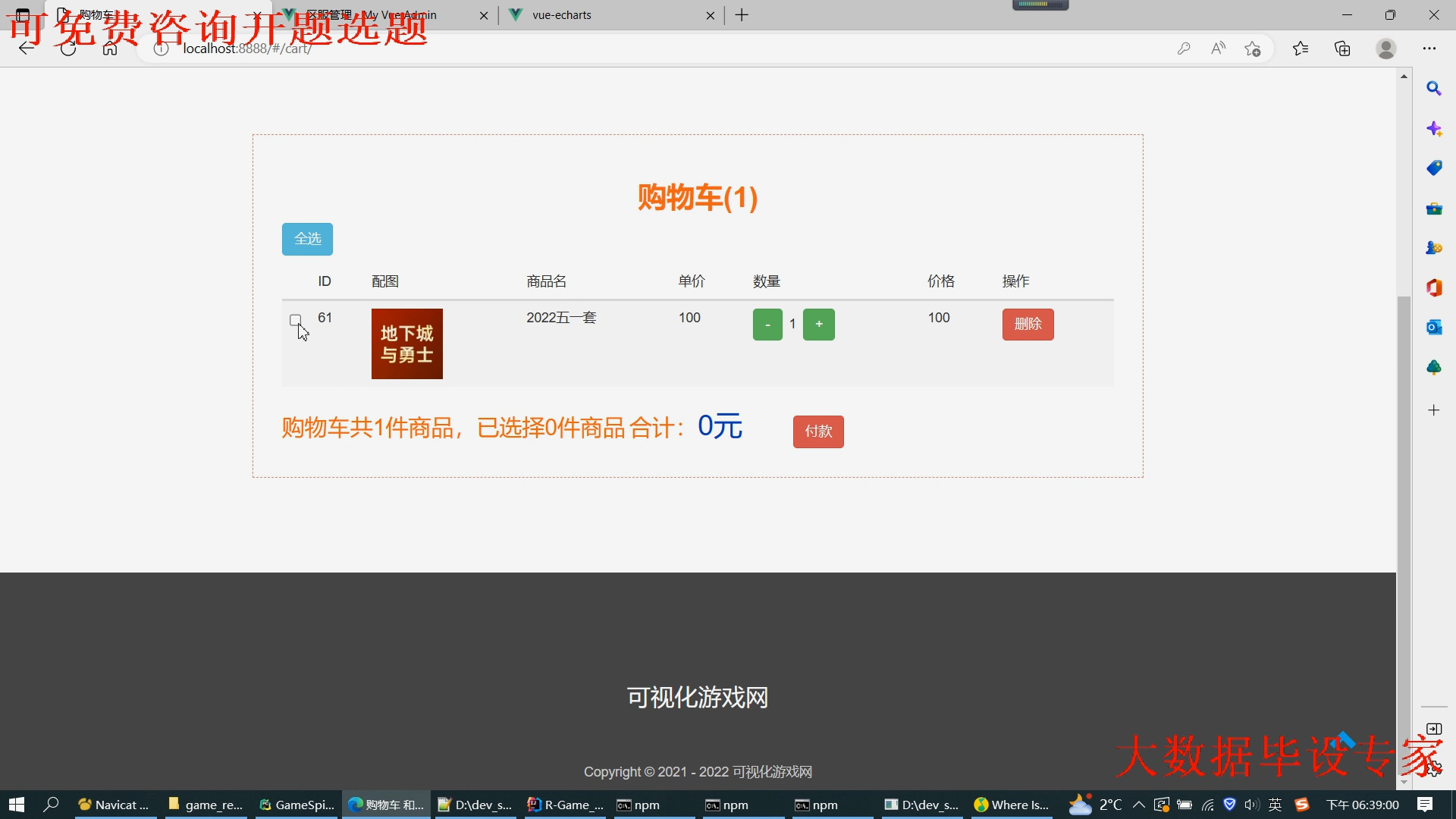
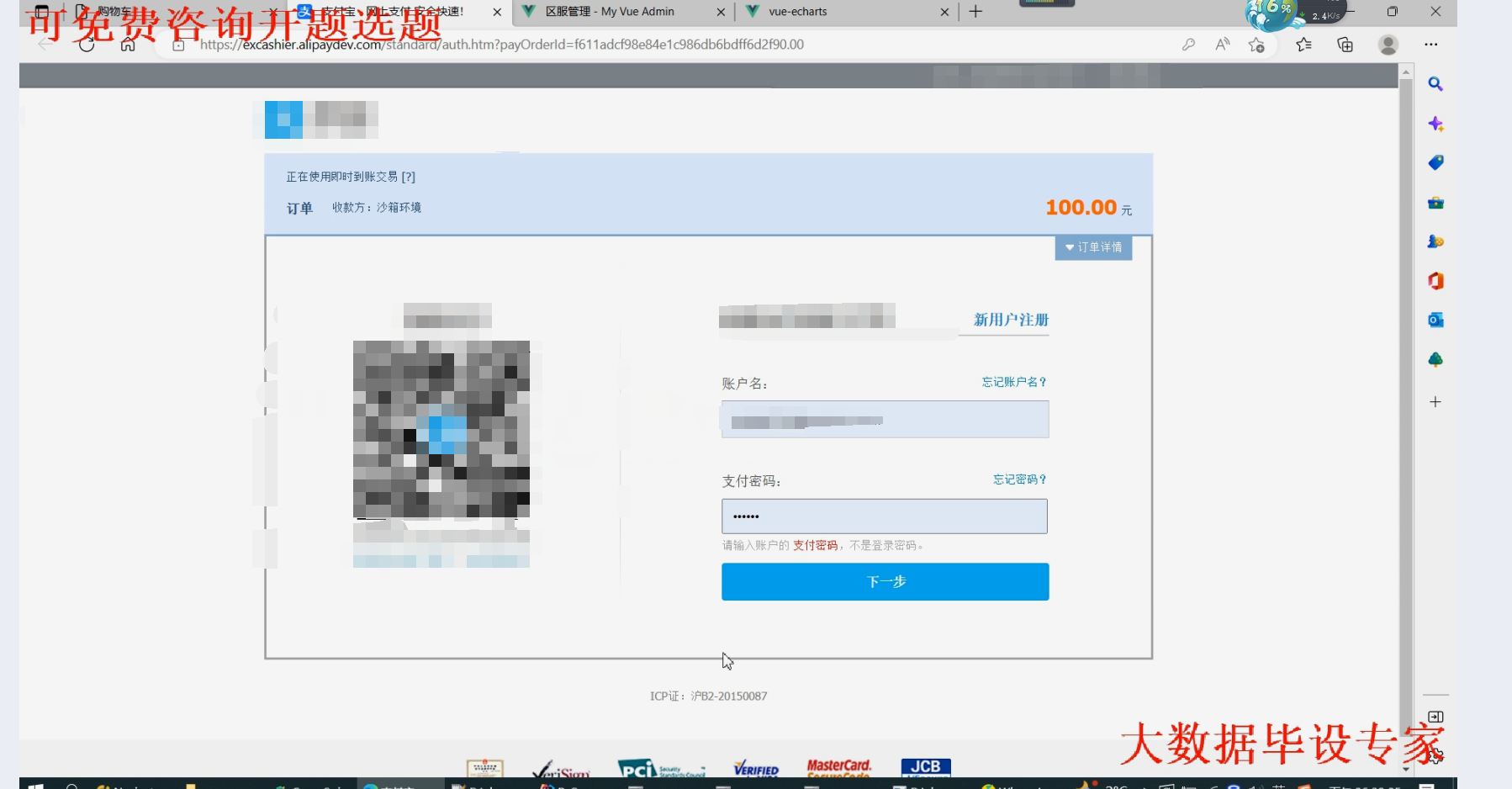
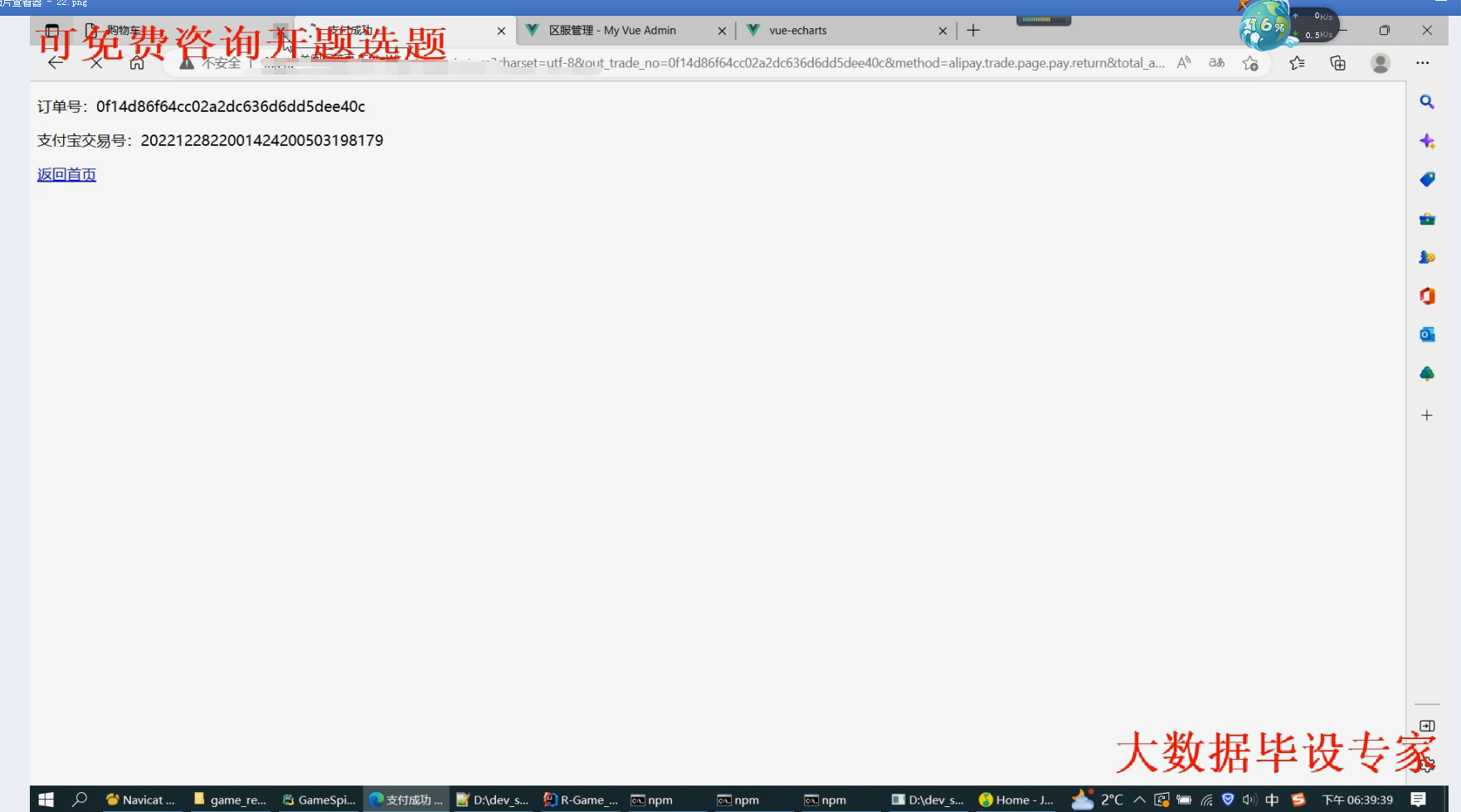
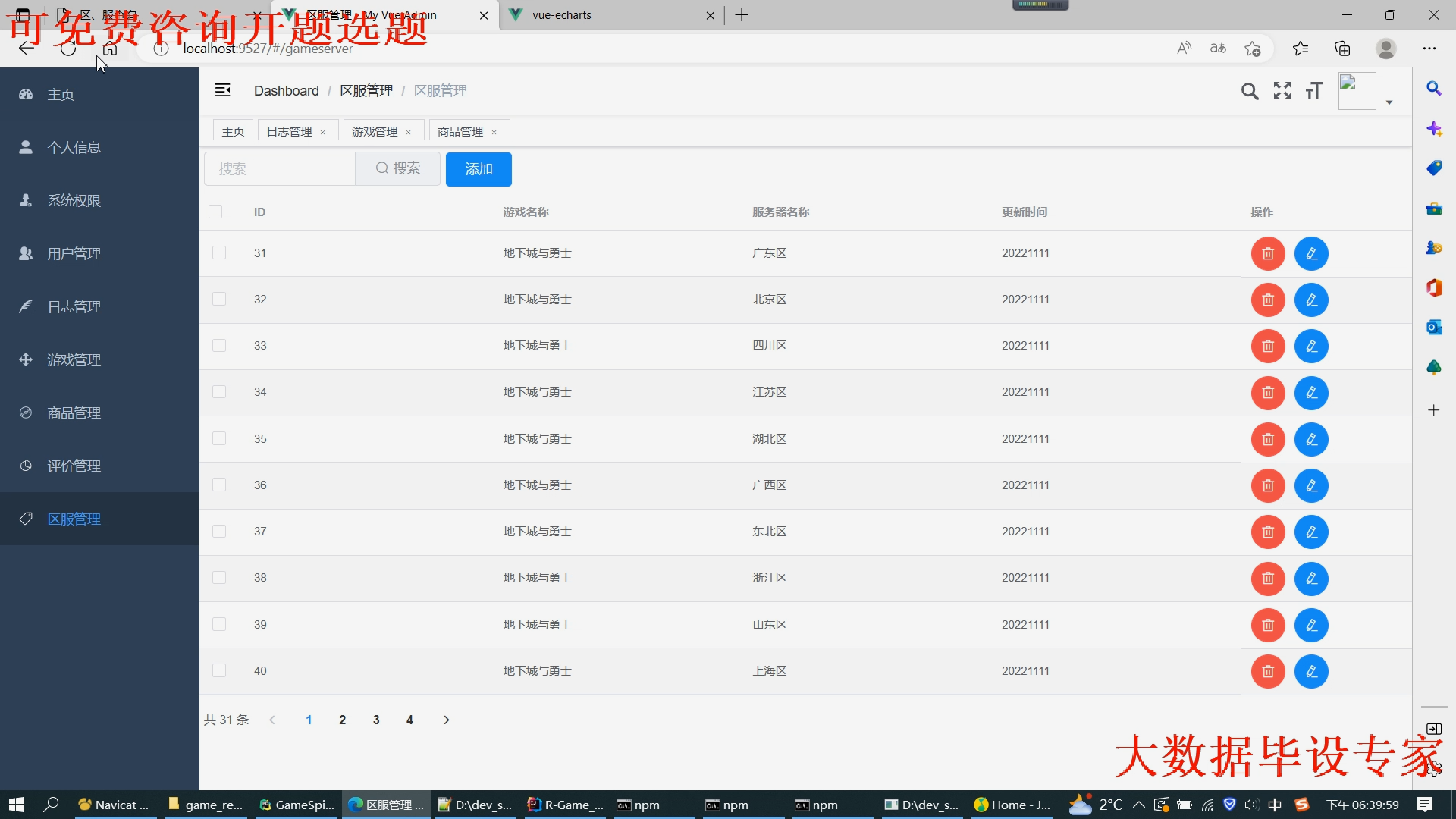
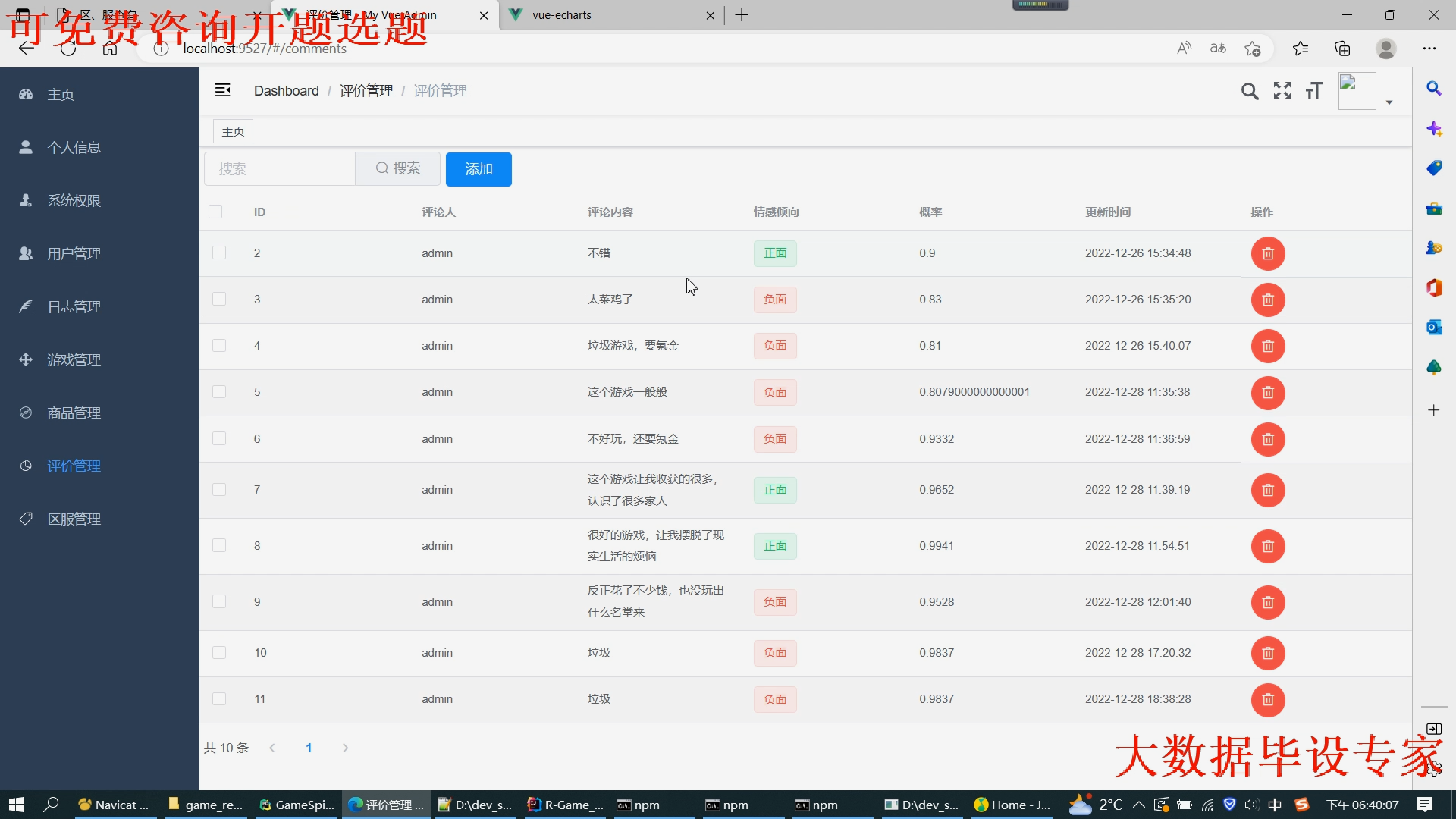


核心算法代码分享如下:
from pyspark import SparkContext, SQLContext
from pyspark.sql import functions as F
from pyspark.sql.types import StringType
import re
import os
import glob
from pyspark.sql.types import StringType, StructField, IntegerType, DoubleType, StructType
# 指定文件夹路径
folder_path = './file' # 替换为你的文件夹路径
# 使用glob模块查找文件夹中的所有.txt文件
txt_files = glob.glob(os.path.join(folder_path, '*.txt'))
# 遍历所有文件
text_data=[]
for txt_file in txt_files:
with open(txt_file, 'r' ,errors='ignore') as file: # 以读取模式打开文件,并指定编码为utf-8
content = file.read() # 读取文件内容
upper_content = content.upper() # 将内容转换为大写
words = re.findall(r'\b\w+\b', upper_content)
#print(words)
for word in words :
#print(word)
text_data.append(word)
# 创建一个 SparkContext 和 SQLContext
sc = SparkContext("local", "Letter Counting")
sqlContext = SQLContext(sc)
# 假设我们有一个 RDD 包含文本数据
#text_data = ["Hello, World!", "Spark is fun.", "PySpark is great."]
text_rdd = sc.parallelize(text_data)
# 将 RDD 中的文本拆分成字符,并过滤出字母
def extract_letters(text):
return [char for char in text if char.isalpha()]
letter_rdd = text_rdd.flatMap(lambda x: extract_letters(x))
# 将 RDD 转换为 DataFrame(在 PySpark 2.0 中,DataFrame API 更为推荐)
letter_df = sqlContext.createDataFrame(letter_rdd.map(lambda x: (x,)), ["letter"])
# 对字母进行分组并计数
letter_counts = letter_df.groupBy("letter").count().orderBy("letter")
# 显示结果
letter_counts.show(truncate=False)
sum_value = letter_counts.agg({"count": "sum"}).collect()[0][0]
print(sum_value) # 输出:12
# 定义数据的模式
schema = StructType([
StructField("letter", StringType(), True),
StructField("count", IntegerType(), True)
])
# 将RDD转换为DataFrame
df = sqlContext.createDataFrame(letter_counts.rdd, schema)
# 显示DataFrame的内容
df.show()
# 注册DataFrame为临时视图,以便可以使用Spark SQL查询它
df.createOrReplaceTempView("tb_letter")
# 使用Spark SQL查询数据
#query_results = sqlContext.sql("SELECT letter,ROUND(count/"+str(sum_value)+", 3) p FROM tb_letter")
query_results = sqlContext.sql("SELECT letter,ROUND(count/"+str(sum_value)+", 3) p FROM tb_letter")
query_results.show()
# 停止 SparkContext
sc.stop()