Kafka基础教程
资料来源:Apache Kafka - Introduction (tutorialspoint.com)
Apache Kafka起源于LinkedIn,后来在2011年成为一个开源Apache项目,然后在2012年成为一流的Apache项目。Kafka是用Scala和Java编写的。Apache Kafka是基于发布-订阅( publish-subscribe)的容错消息传递系统(fault tolerant messaging system)。它是快速的,可扩展的和分布式的设计。
本教程将探索Kafka的原理,安装,操作,然后将带您完成Kafka集群的部署。最后,我们将总结实时应用和与大数据技术的集成。
1. Kafka-简介
在大数据中,使用了大量的数据。关于数据,我们面临两个主要挑战。第一个挑战是如何收集大量的数据,第二个挑战是如何分析收集到的数据。为了克服这些挑战,您必须需要一个消息传递系统。
Kafka是为分布式高吞吐量系统设计的。Kafka可以很好地替代传统的消息代理。与其他消息传递系统相比,Kafka具有更好的吞吐量、内置分区、可复制和固有的容错能力,这使得它非常适合大规模应用。
什么是消息传递系统?
消息传递系统负责将数据从一个应用程序传输到另一个应用程序,因此应用程序可以专注于数据本身,而不必担心如何共享数据。分布式消息传递基于可靠消息队列的概念。消息在客户机应用程序和消息传递系统之间异步排队。有两种类型的消息传递模式可用:一种是点对点(point-point),另一种是发布-订阅(pub-sub)消息传递系统。大多数消息传递模式遵循发布-订阅。
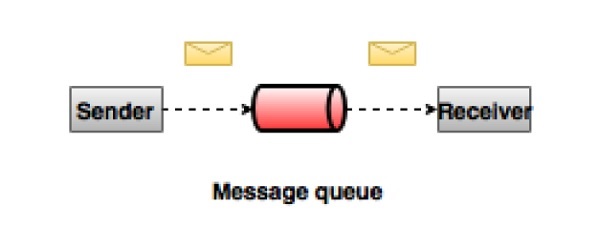
点对点的消息传递系统
在点对点系统中,消息被保存在队列中。一个或多个消费者可以使用队列中的消息,但是一个特定的消息最多只能由一个消费者使用。一旦使用者读取队列中的消息,它就会从队列中消失。该系统的典型示例是订单处理系统,其中每个订单将由一个订单处理器处理,但多个订单处理器也可以同时工作。下图描述了该结构。
发布-订阅消息传递系统
在发布-订阅系统中,消息被保存在主题中。与点对点系统不同,消费者可以订阅一个或多个主题,并使用该主题中的所有消息。在发布-订阅系统中,消息生产者称为发布者,消息消费者称为订阅者。现实生活中的一个例子是Dish TV,它发布不同的频道,如体育、电影、音乐等,任何人都可以订阅自己的频道集,并在他们订阅的频道可用时获得这些频道。

什么是Kafka?
Apache Kafka是一个分布式发布-订阅消息系统和一个健壮的队列,可以处理大量数据,并允许您将消息从一个端点传递到另一个端点。Kafka适用于离线和在线消息消费。Kafka消息被持久化在磁盘上,并在集群内复制,以防止数据丢失。Kafka是建立在ZooKeeper同步服务之上的。它可以很好地与Apache Storm和Spark集成,用于实时流数据分析。
Kafa的优点
以下是Kafa的一些优点
可靠性−Kafka具有分布式、分区、复制、容错等特点。
可扩展性−Kafka消息系统可轻松扩展而无需停机(down time)。
持久性- Kafka使用分布式提交日志,这意味着消息尽可能快地保存在磁盘上,因此它是持久的。
高性能−Kafka在发布和订阅消息方面都有很高的吞吐量。即使存储了许多TB的消息,它也能保持稳定的性能。
Kafka非常快,并保证零停机时间和零数据丢失。
Kafka使用案例
Kafka有许多使用案例,以下列出一些:
- **数据提要(Metrics)**−Kafka通常用于运营监控数据。这涉及到聚合来自分布式应用程序的统计信息,以生成操作数据的集中提要。
- 日志聚合解决方案−Kafka可以跨组织使用,从多个服务收集日志,并以标准格式提供给多个消费者。
- 流处理:-Storm和Spark Streaming等流行的框架从主题(topic)中读取数据,对其进行处理,并将处理后的数据写入新主题,供用户和应用程序使用。Kafka强大的持久性在流处理环境中也非常有用。
使用Kafka的必要性
Kafka是一个处理所有实时数据源的统一平台。Kafka支持低延迟消息传递,并在机器出现故障时提供容错保证。它有能力处理大量不同的消费者。Kafka非常快,每秒写200万次。Kafka将所有数据持久化到磁盘,这实际上意味着所有的写操作都将进入操作系统(RAM)的页面缓存。这使得将数据从页面缓存传输到网络套接字非常有效。
未完待续。。。。点个赞呗