Scikit-Learn梯度提升决策树
-
- 1、梯度提升决策树(GBDT)
-
- 1.1、Boosting方法
- 1.2、GBDT的原理
- 1.3、GBDT回归的损失函数
- 1.4、梯度下降与梯度提升
- 1.5、随机森林与GBDT
- 1.6、GBDT的优缺点
- 2、Scikit-Learn梯度提升决策树(GBDT)
-
- 2.1、Scikit-Learn GBDT回归
-
- 2.1.1、Scikit-Learn GBDT回归API
- 2.1.2、GBDT回归实践(加州房价预测)
- 2.2、Scikit-Learn GBDT分类
-
- 2.2.1、Scikit-Learn GBDT分类API
- 2.2.2、GBDT分类实践(鸢尾花分类)
- 2.3、GBDT参数调优与选择
1、梯度提升决策树(GBDT)
梯度提升决策树(GBDT)是集成学习Boosting提升中的一种重要算法。GBDT在机器学习知识结构中的位置如下:

梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一种迭代的决策树算法,它通过构造一组弱学习器(决策树),并把多颗决策树的结果累加起来作为最终的预测输出。该算法将决策树与集成思想进行了有效的结合
1.1、Boosting方法
我们已经知道,Bagging方法在训练过程中,各基分类器之间无强依赖,可以进行并行训练
与Bagging方法不同,Boosting方法在训练基分类器时采用串行的方式,各个基分类器之间有依赖
Boosting的基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重。预测时,根据各层分类器的结果的加权得到最终结果

- Boosting:串行,将基分类器层层叠加
- Bagging:并行,各基分类器之间无强依赖
1.2、GBDT的原理
梯度提升决策树算法的流程如下:
-
初始化:设定一个初始预测值,通常为所有样本目标变量的均值,这个初始预测值代表了我们对目标变量的初始猜测
-
迭代训练:GBDT是一个迭代算法,通过多轮迭代来逐步改进模型。在每一轮迭代中,GBDT都会训练一棵新的决策树,目标是减少上一轮模型的残差。残差是预测值与真实值之间的误差,新的树将学习如何纠正这些残差
-
计算残差:在每轮迭代开始时,计算当前模型对训练数据的预测值与实际观测值之间的残差。这个残差代表了前一轮模型未能正确预测的部分
-
拟合残差:以当前残差为新的学习目标变量,训练一棵新的决策树。这棵树将尝试纠正上一轮模型的错误,以减少残差
-
更新模型:将新训练的决策树与之前的模型进行组合,更新预测值。具体地,将新树的预测结果与之前模型的预测结果累加,得到更新后的模型
-
-
终止/集成:当达到预定的迭代次数或残差变化小于阈值时停止迭代。将所有决策树的预测结果相加,得到最终的集成预测结果。这个过程使得模型能够捕捉数据中的复杂关系,从而提高预测精度
GBDT的核心点在于不断迭代,每一轮迭代都尝试修正上一轮模型的错误,逐渐提高模型的预测性能
GBDT算法流程的数学描述参考文章:https://blog.csdn.net/u010366748/article/details/111060108
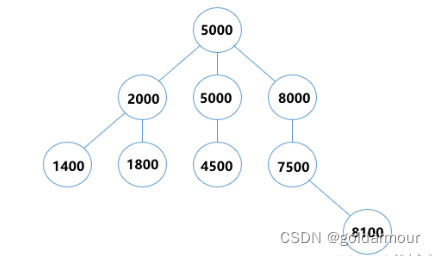
例如,使用GBDT预测年龄:

-
第一个弱分类器(第一棵树)预测一个年龄(如20岁),计算发现误差有10岁
-
第二个弱分类器(第二棵树)拟合残差10,预测值6,计算发现差距还有4岁
-
第三个弱分类器(第三棵树)继续拟合残差4,预测值3,发现误差只有1岁了
-
第四个弱分类器(第四课树)用1岁拟合剩下的残差,完成
最终,四个弱分类器(四棵树)的结论累加起来,得到30岁这个标准答案。实际在工程应用中,GBDT计算负梯度,使用负梯度近似残差
1.3、GBDT回归的损失函数
回归任务下,GBDT在每一轮迭代时对每个样本都会有一个预测值,此时的损失函数为均方差损失函数:

损失函数的负梯度计算如下:

可以看到,当损失函数选用均方误差损失时,每次拟合的值就是真实值减预测值,即残差
1.4、梯度下降与梯度提升
负梯度方向是梯度下降最快的方向。梯度下降与梯度提升两种迭代优化算法都是在每一轮迭代中,利用损失函数负梯度方向的信息,更新当前模型。但两者是完全不同的概念
梯度下降中,模型是以参数化形式表示,从而模型的更新等价于参数的更新

梯度提升中,模型并不需要进行参数化表示,而是直接定义在函数空间中,从而大大扩展了可以使用的模型种类

梯度提升与梯度下降的主要区别如下:
| 比较项 | 梯度下降 | 梯度提升 |
|---|---|---|
| 模型定义空间 | 参数空间 | 函数空间 |
| 优化规则 | θ t \theta_t θt= θ t − 1 \theta_{t-1} θt−1+ Δ θ t \Delta\theta_t Δθt | f t ( x ) f_t(x) ft(x)= f t − 1 ( x ) f_{t-1}(x) f |