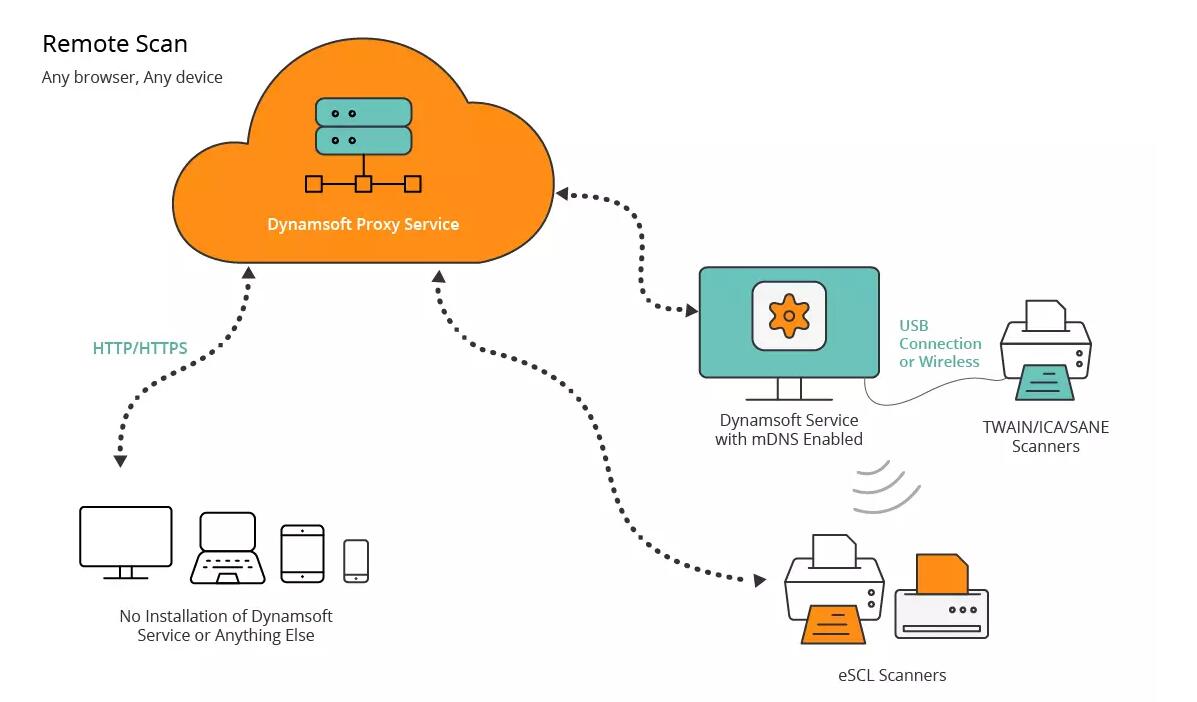
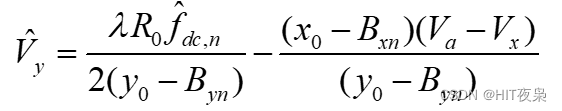摘要
本文发现泛在时间序列(TS)预测模型容易出现严重的过拟合。为了解决这个问题,我们采用了一种去冗余的方法来逐步恢复TS的真实值。具体来说,我们引入了一种双流和减法机制,这是一种深度Boosting集成学习方法。通过将信息聚合机制从加法转向减法,对普通的Transformer进行了改造。然后,我们在原始模型的每个块中加入一个辅助输出分支,构建一条通往最终预测的高速公路。该分支后续模块的输出将减去之前学习的结果,使模型能够逐层学习监督信号的残差。这种设计促进了学习驱动的输入和输出流的隐式渐进分解,使模型具有更高的通用性、可解释性和抗过拟合的弹性。由于模型中的所有聚合都是负号,因此称为Minusformer。广泛的实验表明,所提出的方法优于现有的最先进的方法,在各种数据集上平均性能提高11.9%。
论文题目:Minusformer: Improving Time Series Forecasting by Progressively Learning Residuals
论文作者:Daojun Liang, Haixia Zhang,Dongfeng Yuan,Bingzheng Zhang
论文地址:https://arxiv.org/abs/2402.02332
代码地址:https://github.com/Anoise/Minusformer
论文地址
Github代码地址

图1:所提出的减速器与其他最新先进型号的比较。结果(MSE)在所有预测长度上取平均值。模型后面的数字后缀表示模型的输入长度。Minusformer配置了两个版本的输入长度,以便与其他模型保持一致。
1 简介
“在我开始工作之前,雕塑已经在大理石块内完成了。它已经存在了,我只要把多余的材料凿掉就行了。” ——米开朗基罗
在本文中,我们利用去冗余的概念提出了一种渐进式学习方法,旨在系统地获取监督信号的成分,从而提高时间序列(TS)预测的性能。在正式启动之前,让我们仔细研究一下TS预测的传统方法。
从现实世界中记录的TS由于在复杂的瞬态条件下的演化,往往表现出无数形式的非平稳性(Anderson, 1976)。非平稳TS的特征体现在不断变化的统计性质和联合分布上(Cheng et al., 2015),这使得准确预测变得极其困难(Hyndman and Athanasopoulos, 2018)。经典的方法如ARIMA (Piccolo, 1990)、指数平滑(Gardner Jr, 1985)和Kalman滤波(Li et al., 2010)是基于时间序列的平稳性假设或统计性质来预测未来缺失值的,这些方法不再适用于非平稳情况(De Gooijer, 2010 and Hyndman, 2006)。
最近,由于其强大的非线性拟合能力,深度学习被引入TS预测(Hornik, 1991),包括基于注意力的长期预测(Zhou et al., 2021;Nie et al., 2022;Liu et al., 2023;Shabani et al., 2022)或基于图神经网络(GNNs)的预测方法(Li et al., 2018;Wu等人,2019)。然而,最新的研究表明,与多层感知器(multilayer Perceptrons, MLP)相比,使用基于注意力的方法在预测性能方面的改进并不显著(Zeng et al., 2023;Liang等人,2023)。而且它们的推理速度相对于vanilla Transformer已经变慢了(Liang et al., 2023)。此外,与MLP相比,基于gnn的方法在预测性能方面没有显着改善(Shao et al., 2022)。
受前人工作的启发,我们发现流行的深度模型,例如基于transformer的模型,在TS数据上容易出现严重的过拟合。如图2所示,尽管训练损失仍在急剧下降(橙色线),但在训练过程中过拟合发生得较早(验证损失显著增加)。尽管有许多方法可以将多变量属性嵌入到标记中(图2.a)或将单个序列嵌入到时间标记中(图2.b),但过度拟合仍然存在。将聚合方向重新定向到时间维度,例如,基于iTransformer的模型,可以略微缓解过度拟合,但其影响受到高度限制(绿线)。因此,必须开发一种针对性的网络结构,专门用于减轻TS预测中固有的过拟合问题。
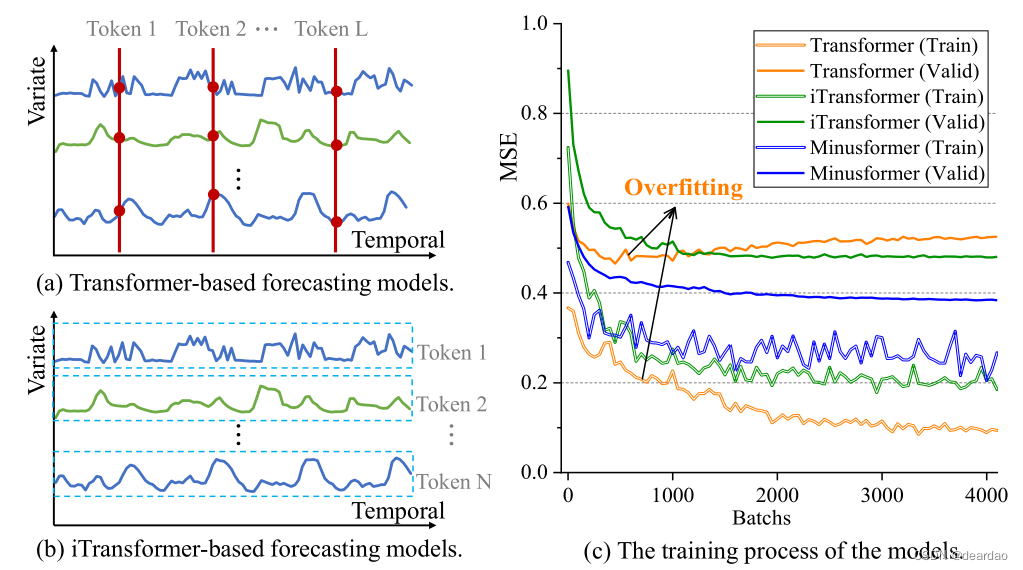
图2:时间序列在不同方向聚合时模型的概化。实验是在Traffic数据集上利用Transformer与4个块(基线)进行的。
在本文中,我们深入研究了一种去冗余方法,该方法隐式分解监督信号以逐步引导学习过程以应对过拟合问题。具体来说,我们通过修改信息聚合机制,用减法代替加法,对原有的Transformer架构进行了革新。然后,我们将辅助输出流合并到每个块中,从而构建一条通往最终预测的高速公路。该流中后续模块的输出将减去之前学习的结果,便于模型逐层渐进地学习监督信号的残差。双系统设计的结合促进了学习驱动的输入和标签的隐式渐进分解,这相当于助推集成学习(Kearns和Valiant, 1994),从而增强了模型的通用性、可解释性和抗过拟合的弹性。考虑到所有聚合都由减号组成,这种体系结构被称为Minusformer。
此外,我们提供了基于减法的模型有效性背后的理论基础。我们证明了Minusformer中的减法可以通过逐步学习监督信号的残差来有效地减小模型的方差,从而缓解过拟合问题。最后,我们在不同领域的真实TS数据集上验证了所提出的方法。大量的实验表明,该方法优于现有的SOTA方法,在各种数据集上的平均性能提高了11.9%。
2 方法
2.1 记号
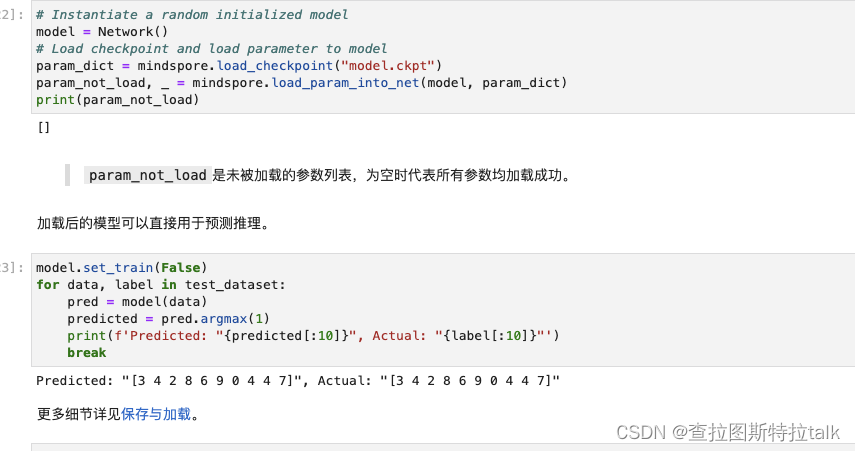
TS预测的目的是用I个历史时刻的观测值来预测 O O O个未来时刻的缺失值,可以记为 I n p u t − I − P r e d i c t − O Input-I-Predict-O Input−I−Predict−O。若将序列的特征维记为 D D D,则其输入数据可记为 X t = { s 1 t , ⋅ ⋅ ⋅ , s I t ∣ s t I ∈ R D } X_t = \{s^t_1,···,s^t_I| s_t^I∈R^D\} Xt={s1t,⋅⋅⋅,sIt∣stI∈RD}。其目标标号可表示为 Y t = { s I + 1 t , ⋯ , s I + O t ∣ s I + o t ∈ R D } Y^t = \{s_{I+1}^t, \cdots, s_{I+O}^t | s_{I+o}^t \in \mathbb{R}^D \} Yt={sI+1t,⋯,sI+Ot∣sI+ot∈RD},其中 s i t s_i^t sit是第t时刻维数为 d d d的子级数。然后,我们可以通过设计一个给定输入Xt的模型F来预测 Y ^ t \hat{Y}_t Y^t,可以表示为: Y ^ t = F ( X t ) \hat{Y}_t = F(X_t) Y^t=F(Xt)。因此,选择合适的 F F F对于提高模型的性能至关重要。为了表示简单,如果上标t在上下文中不会引起歧义,则将省略。
2.2 减法减轻过拟合
过拟合的主要原因是模型在测试集上具有低偏差和高方差(Hastie et al., 2009)。目前,TS预测模型,尤其是深度预测模型,可以包含数百万个参数。虽然跳过连接有助于通过减轻梯度消失问题来训练更深层次的网络,但参数的数量增加了模型的复杂性,这在训练高度不稳定的TS数据集时很容易导致过拟合。我们表明,减法操作是输入和输出流的隐式分解,相当于元算法的增强,降低了模型的复杂性,从而降低了过拟合的风险。如图3所示,输入流显然是
X
X
X的分解,因为:
X
=
∑
l
=
0
L
−
1
f
l
(
X
)
+
R
L
,
(
1
)
X = \sum_{l=0}^{L-1} f_{l}(X) + R_L, \ \ \ \ \ \ \ \ (1)
X=l=0∑L−1fl(X)+RL, (1)
其中
R
L
R_L
RL是残差项。分解有助于识别和理解时间序列中的底层模式。通过分离隐式组件并分别对其建模,可以提高未来预测的准确性。单独对这些组件进行建模,然后将它们重新组合以进行预测,这更容易。
此外,输出系统的思想是学习层次结构中的
L
L
L个简单块,其中每个块对前一个块的硬样本给予更多的关注(更大的权重)。这相当于Boosting集成学习过程,其中最终的预测是
L
L
L个简单块的加权和,权重由前一个块确定。设
f
l
(
x
)
f_l(x)
fl(x)表示深度模型中的第
I
I
I个块,
α
l
\alpha_l
αl表示第l个块的权重。深度模型的总体估计F(X)是L个估计的加权减法。对于样本
X
X
X,我们有:
Y
^
=
F
(
X
)
=
i
∑
l
=
0
ℏ
α
2
l
+
1
f
2
l
+
1
(
X
)
−
i
∑
l
=
0
ℏ
α
2
l
f
2
l
(
X
)
,
(
2
)
\hat{Y} = \mathcal{F}(X) = i \sum_{l=0}^{\hbar} \alpha_{2l+1} f_{2l+1}(X) - i \sum_{l=0}^{\hbar} \alpha_{2l} f_{2l}(X), \quad \quad (2)
Y^=F(X)=il=0∑ℏα2l+1f2l+1(X)−il=0∑ℏα2lf2l(X),(2)
其中,
ℏ
=
⌊
L
2
⌋
\hbar = \lfloor \frac{L}{2} \rfloor
ℏ=⌊2L⌋,
i
=
1
i = 1
i=1 如果
L
m
o
d
2
=
1
L\bmod 2 = 1
Lmod2=1, 否则
i
=
−
1
i = -1
i=−1。
2.3 深度集成学习有助于缓解过拟合
现在,我们对深度集成学习如何缓解过拟合进行了理论分析。在实践中,观测值Y经常包含加性噪声 ε \varepsilon ε: Y = Y + ε Y = \mathcal{Y} + \varepsilon Y=Y+ε,其中 ε ∼ N ( 0 , ξ ) \varepsilon \sim \mathcal{N}(0, \xi ) ε∼N(0,ξ)。则最终模型的估计误差(MSE)为:
Var
(
Y
^
)
+
(
Bias
(
Y
^
)
)
2
+
ξ
2
⏟
Test Error
=
E
[
(
Y
^
−
Y
)
2
]
+
2
E
(
ε
(
Y
^
−
Y
)
)
⏟
Training Error
.
(
3
)
\underbrace{\text{Var}(\hat{Y}) + (\text{Bias}(\hat{Y}))^2 + \xi^2}_{\text{Test Error}} = \underbrace{\mathbb{E}[ (\hat{Y} - Y )^2] + 2\mathbb{E}(\varepsilon(\hat{Y} - \mathcal{Y} ))}_{\text{Training Error}}. \quad \quad (3)
Test Error
Var(Y^)+(Bias(Y^))2+ξ2=Training Error
E[(Y^−Y)2]+2E(ε(Y^−Y)).(3)
证明如附录b所示。等式3表明,当一个模型表现出低偏差和高方差时,它倾向于表明过拟合。否则,它表现为欠拟合。对于现代复杂的深度学习模型,它们的偏差通常非常低(Goodfellow等人,2016;Zhang等人)。
定理1:在不失一般性的前提下,假设块
f
l
(
X
)
f_l(X)
fl(X)的估计误差为
e
l
e_l
el,
e
l
∼
i
.
i
.
d
N
(
0
,
ν
)
e_l \overset{i.i.d}{\sim} \mathcal{N}(0, \nu)
el∼i.i.dN(0,ν)。设
α
l
=
α
\alpha_l = \alpha
αl=α为
f
l
f_l
fl的权值,
l
∈
[
0
,
L
]
l \in [0,L]
l∈[0,L],用
μ
\mu
μ估计两个不同块的协方差,有
Var
(
Y
^
)
<
4
L
α
2
(
ν
+
μ
)
.
(
4
)
\text{Var}(\hat{Y}) < \frac{4}{L} \alpha^2 (\nu + \mu). \quad \quad (4)
Var(Y^)<L4α2(ν+μ).(4)
证据见附录B.1。显然,深度集成模型的方差受到每个块的估计误差(噪声误差)、块间协方差的约束。很明显,在深度集成模型中采用减法可以减小方差,从而减轻过拟合。相反,将Minsformer输出流的聚合操作切换为加法操作,得到的近似方差为
4
L
α
2
ν
+
3
α
2
μ
\frac{4}{L} \alpha^2 \nu + 3\alpha^2 \mu
L4α2ν+3α2μ,远远大于式2中的减法操作。此外,定理1还表明,增加层数
L
L
L并不会增加过拟合的风险,这证明了深度集成模型可以被设计的更深。
2.4 Minusformer
如图4所示,Minusformer的设计灵感来自深度集成学习,它包括两个主要数据流。一种是通过多个残差块进行减法运算分解的输入流,另一种是逐步学习被监督信号残差的输出流。在此过程中,它们会穿过多个能够提取和转换信号的神经块。基础架构简单而通用,但功能强大且易于理解。现在我们将深入研究如何将这些适当的关系合并到所建议的体系结构中。
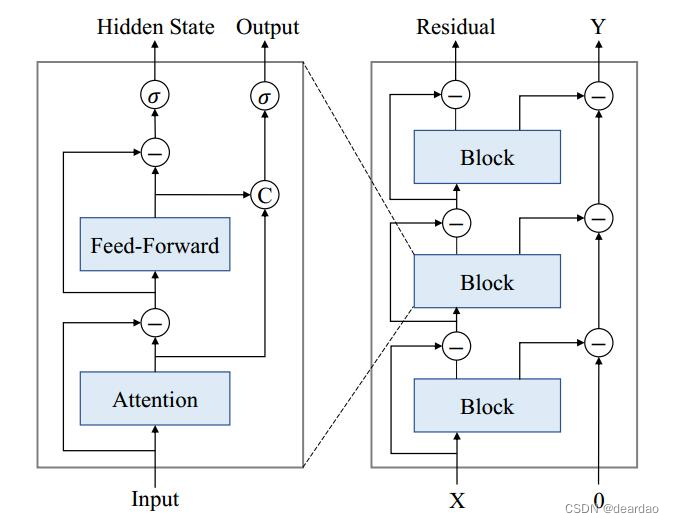
图4: Minusformer的网络架构
主干: 基础建筑主干具有分叉架构,它接受一个输入
X
l
X_l
Xl并产生两个不同的流,
R
l
R_l
Rl和
O
l
O_l
Ol。具体来说,
R
l
R_l
Rl是
X
l
X_l
Xl在神经模块内经过处理后的剩余部分,可以表示为
X
^
l
=
Block
(
X
l
)
,
(
5
a
)
R
l
=
X
l
−
X
^
l
.
(
5
b
)
\hat{X}_l = \text{Block} (X_l), \quad \quad (5a) \\ R_l = X_l - \hat{X}_l. \quad \quad (5b)
X^l=Block(Xl),(5a)Rl=Xl−X^l.(5b)
方程5表示
X
X
X的隐式分解,不同于(Wu et al., 2021;Zhou et al., 2022)和(Liang et al., 2023),但与(Oreshkin et al., 2019)相似。残留信息
R
l
R_l
Rl捕获未改变或未处理的信息,为与转换后的部分进行比较提供基础。
在随后的步骤中,我们的目的是最大限度地利用减去的部分
x
1
x_1
x1。首先,将
x
1
x_1
x1投影到与预期的标签
y
y
y相同的维度上,这个过程可以表示为
O
l
=
Linear
(
X
^
l
)
,
O_l = \text{Linear} (\hat{X}_l),
Ol=Linear(X^l),
其中,
O
l
O_l
Ol为第
l
l
l个预测器的预测结果。然后,依次从下一个预测器的输出中减去
O
l
O_l
Ol,直到实现最终预测
Y
^
\hat{Y}
Y^。这个迭代的减法过程是至关重要的,因为它促进了模型增量地精炼其理解,随着层的深入,其目标是向更准确的预测收敛。
使用注意力的缺点是,当各种属性彼此独立时,它会变得无效甚至恶化预测性能。为了减轻这种限制,我们通过从输入中减去注意力输出来实施纠正措施。这确保了注意力可以有效地利用其固有优势,提高整体表现。这个过程可以表示为
X
^
l
,
1
=
Attention
(
X
l
,
1
)
,
(
7
a
)
R
l
,
1
=
X
l
,
1
−
δ
X
^
l
,
1
.
(
7
b
)
\hat{X}_{l,1} = \text{Attention} (X_{l,1}), \quad \quad (7a)\\ R_{l,1} = X_{l,1} - \delta \hat{X}_{l,1}. \quad \quad \quad \ \ \ \ (7b)
X^l,1=Attention(Xl,1),(7a)Rl,1=Xl,1−δX^l,1. (7b)
其中
δ
\delta
δ是狄拉克函数。当注意层产生不利影响时,
δ
\delta
δ起到消除作用,从而使输入畅通无阻地流向前馈层。
目前,在整个块内,有两个流:一个由神经模块变换后的输出 X ^ l \hat{X}_l X^l组成,另一个包含从输入中减去 X ^ l \hat{X}_l X^l得到的残差 R l R_{l} Rl。在通过门机构后,它们被引导到下一个块或投射到输出空间。
门机制 :从RNN中获得灵感,我们希望每个神经模块都能自主调节信息传递的速度,类似于rnn中细胞所表现出的内在控制。因此,我们在两个流的每个区块结束时引入了一个门机制。对于残余流,其闸门机制可表示为
X
l
+
1
=
σ
(
θ
1
(
R
l
,
2
)
)
⋅
θ
2
(
R
l
,
2
)
,
(
8
)
X_{l+1} = \sigma (\theta_1(R_{l,2})) \cdot \theta_2(R_{l,2}), \quad \quad (8)
Xl+1=σ(θ1(Rl,2))⋅θ2(Rl,2),(8)
其中$ \sigma
为
s
i
g
m
o
i
d
型函数,
为sigmoid型函数,
为sigmoid型函数,\theta_1
和
和
和\theta_2
为具有不同参数的可学习神经元。同样地,对于中间的
为具有不同参数的可学习神经元。同样地,对于中间的
为具有不同参数的可学习神经元。同样地,对于中间的\hat{X}_l$,门结构可以表示为
O
l
+
1
=
σ
(
θ
3
(
[
X
^
l
,
1
,
X
^
l
,
2
]
)
)
⋅
θ
4
(
[
X
^
l
,
1
,
X
^
l
,
2
]
)
,
(
9
)
O_{l+1} = \sigma (\theta_3([\hat{X}_{l,1},\hat{X}_{l,2}])) \cdot \theta_4([\hat{X}_{l,1},\hat{X}_{l,2}]), \quad \quad (9)
Ol+1=σ(θ3([X^l,1,X^l,2]))⋅θ4([X^l,1,X^l,2]),(9)
其中方括号“[ ]”表示连接操作。方程9便于综合利用注意层和前馈层的输出。
3 实验
Minusformer对广泛使用的真实世界数据集进行了全面评估,包括多种主流TS预测应用,如能源、交通、电力、天气、交通、交易以及Monsh等数据集。
实现细节 :利用ADAM优化器(Kingma and Ba, 2015)对模型进行训练,并最小化均方误差(MSE)损失函数。训练过程过早停止,通常在10个周期内。Minusformer架构只包含嵌入层和主干架构,没有任何额外引入的超参数。超参数灵敏度分析见附录E。在模型验证过程中,采用了两个评估指标:MSE和Mean Absolute Error (MAE)。考虑到MSE和MAE这两个指标之间潜在的竞争关系,我们使用两者的平均值(MSE+MAE)/2来评估模型的整体性能。
基线:我们采用了最近的14种SOTA方法进行比较,包括ittransformer (Liu等人,2023)、PatchTST (Nie等人,2022)、Crossformer (Zhang和Yan, 2022)、SCINet (Liu等人,2022a)、TimesNet (Wu等人,2022a)、DLinear (Zeng等人,2023)、Periodformer (Liang等人,2023)、FED- former (Zhou等人,2022)、Autoformer (Wu等人,2021)、Informer (Zhou等人,2021)、LogTrans (Li等人,2019)和Reformer (Kitaev等人,2020)。特别是,N-BEATS (Oreshkin et al., 2019)和N-Hits (Challu et al., 2023)等竞争模型也用于比较单变量预测。附加在每个模型上的数字后缀表示各自模型所使用的输入长度。
3.1 主要实验结果
所有数据集都被用于多变量(多变量预测多变量)和单变量(单变量预测单变量)任务。有关数据集的详细信息可在附录c中找到。实验中使用的模型在广泛的预测长度范围内进行评估,以比较不同未来水平的表现:96、192、336和720。多变量和单变量任务的实验设置是相同的。关于完整ETT数据集的更多实验,请参见附录G。
多变量结果: 表1列出了多变量TS预测的结果,最优结果用红色突出显示,次优结果用下划线强调。由于不同方法之间的输入长度存在差异,例如,PatchTST和DLinear使用336的输入长度,而Crossformer和Periodformer在不超过最大设置的情况下搜索输入长度(Crossformer为720,Periodformer为144),我们配置了两个版本的Minusformer,每个版本都有不同的输入长度(96和336),用于性能评估。
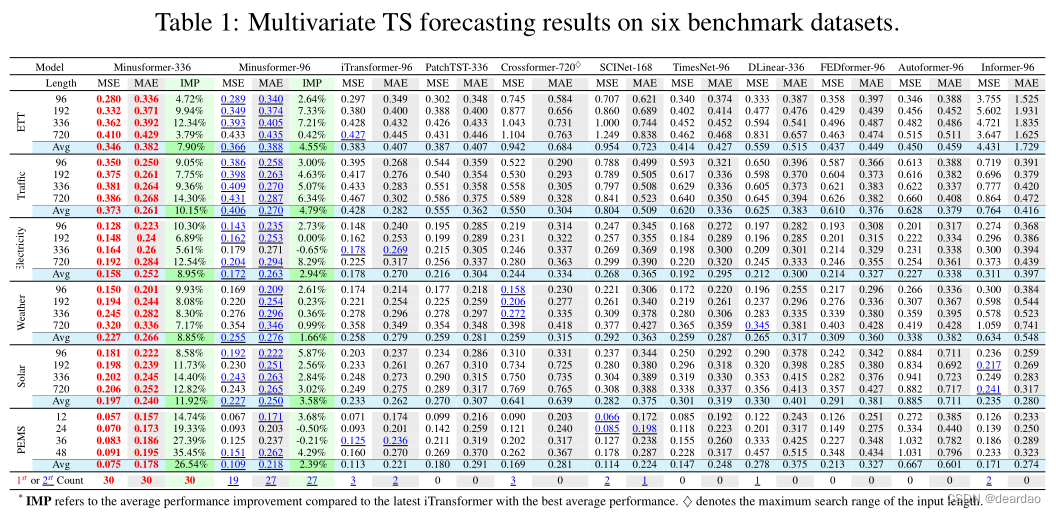
如表1所示,所提出的Minusformer在所有数据集和预测长度配置中实现了一致的SOTA性能。iTransformer和PatchTST脱颖而出,作为最新型号承认其卓越的平均性能。与它们相比,Minusformer-336的平均性能分别提高了11.9%和20.6%,实现了实质性的性能提升。接下来,我们的主要焦点转移到分析Minusformer-96的性能增益。Minusformer-96的平均性能分别提高了3.0%和13.4%。它实现了高级性能,在6个数据集上平均23个项目,每个数据集的平均性能都有一个提高(IMP)。这些实验结果证实了所提出的Minusformer在不同视界的不同数据集上具有优越的预测性能。
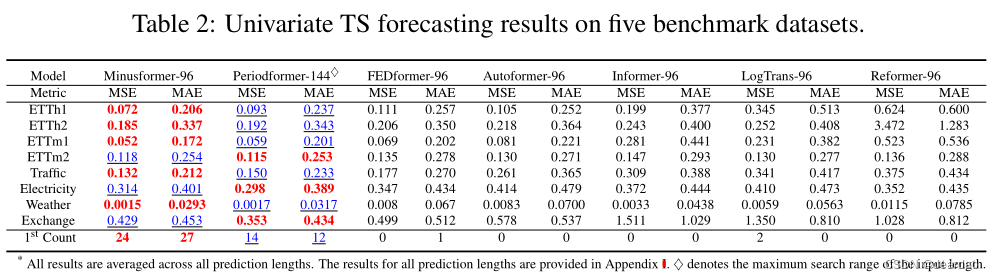
单变量结果:单变量TS预测的平均结果见表2。很明显,与基准测试相比,所提出的Minusformer在各种预测长度设置中继续保持SOTA性能。总之,与超参数搜索的Periodformer相比,Minusformer在5个数据集上平均减少了4.8%,并且平均实现了26个最佳。例如,在input-96-predict-96设置下,Minusformer对流量的MSE降低了11.2%(0.143→0.127)。显然,实验结果再次验证了Minusformer在单变量TS预测任务上的优越性。
3.2 Monash TS数据集评价
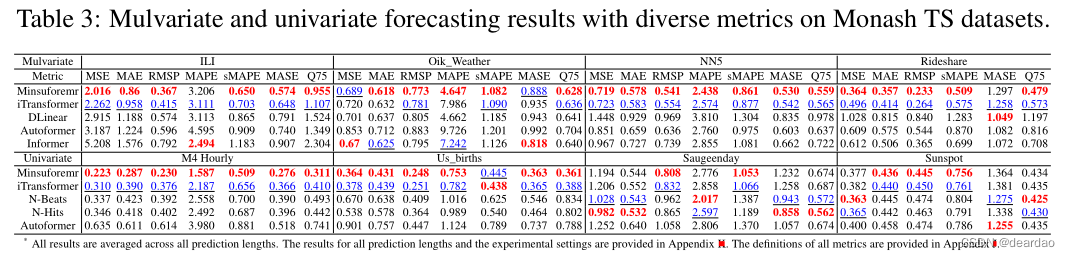
此外,我们在7个Monash TS数据集(Godahewa et al., 2021)上评估了所提出的方法。NN5、M4和Sunspot等)和7个不同的指标(如MAPE、sMAPE、MASE和Quantile等)来系统地评估我们的模型。在相同的输入长度(例如,I=96)和输出长度(例如,O={96, 192, 336和720})下,比较所有实验。如表3所示,拟议的Minusformer成为领跑者,在54项中获得41项最佳。定义和实验设置详见附录J和附录K。
3.3 比较分析
值得注意的是,一些开创性的模型在特定设置下的某些数据集上也取得了具有竞争力的表现。例如,Informer被认为是长期TS预测的开创性模型,在输入96-预测-192和-720设置的Solar-Energy数据集上展示了先进的性能。这是由于Solor-Energy数据集的每列属性都存在大量零值。这使得Informer中采用的基于KL-divergence的ProbSparse Attention在这个稀疏数据集上非常有效。此外,基于线性的方法(如DLinear)在input-336-predict- 720设置的Weather数据集上显示了有希望的结果,而基于卷积的方法(如SCINet)在input-168-predict-192设置的PEMS数据集上取得了良好的结果。这种现象可归因于两方面因素的相互作用。以前,输入设置的多样性直接影响模型的泛化。其次,其他模型表现出过度拟合以非周期波动为特征的非平稳TS的倾向。值得注意的是,Minusformer巧妙地缓解了多元TS预测中的过拟合和欠拟合挑战,从而提高了其整体性能。特别是在具有众多属性的数据集上,例如Traffic和Solor-Energy, Minusformer通过将学习到的有意义的模式馈送到每个块的输出层来实现卓越的性能。
3.4 有效性
为了验证Minusformer组件的有效性,我们进行了全面的烧蚀研究,包括组件更换和组件去除实验,如图5所示。我们使用符号“+”和“-”来表示在输入或输出流的聚合过程中使用的加法或减法操作。在只涉及输入流的情况下,很明显,与使用加法(+X)相比,使用减法(-X)时模型的平均性能更好。例如,在电力数据集上,预测误差降低了1.1%(0.178→0.176)。此外,随着模型中高速输出流的引入,将输出流的聚合方法从加法(+Y)转变为减法(-Y),将进一步提高模型的性能。之后,将门控机制(G)结合到模型中,有可能再次提高预测性能。例如,在Traffic数据集上,预测误差降低了2.4%(0.419→0.409)。总之,集成上述组件的优点有可能显著提高模型的整体性能。
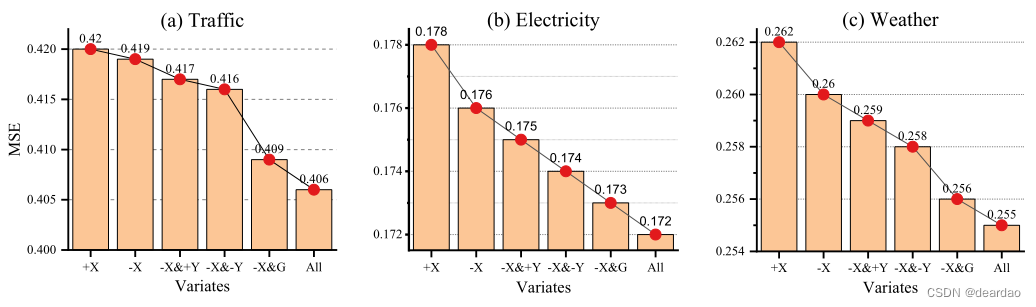
图5:Minusformer各部件的烧蚀研究。所有结果在所有预测长度上取平均值。变量X和Y表示输入和输出流,而符号“+”和“-”表示流聚合时使用的加法或减法操作。字母“G”表示为每个区块的输出添加一个门控机制。
3.5 通用性
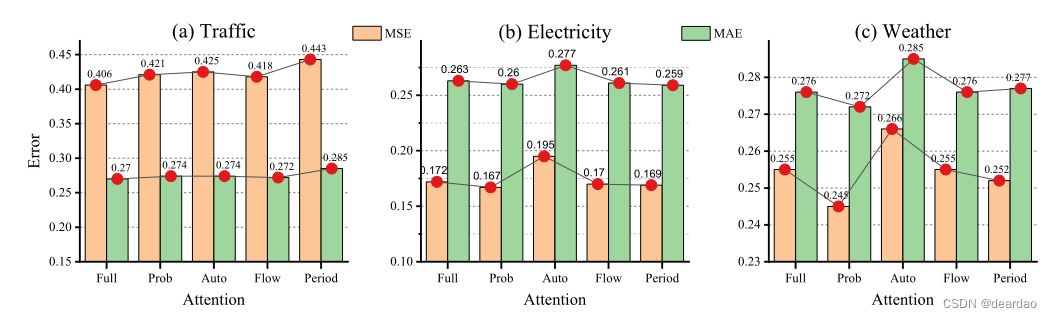
图6:使用不同注意力的Minusformer消融研究。所有结果在所有预测长度上取平均值。x轴上的勾号标签是注意力类型的缩写。附录F提供了所有预测长度的详细设置和结果。
3.6 可解释性
Minusformer的内在特性在于将每个块的输出与最终输出的形状对齐。这种对齐反过来又加速了模型学习过程的分解和可视化。如图7所示,Minusformer中每个块的输出都是可视化的,具有宽度和深度配置的变化。此外,每个块内的注意力如图10所示,与图7(a)中的模型相对应。很明显,每个块都能识别和吸收系列中有意义的模式。具体来说,对比图7(a)和图7(b),当嵌入维数较低时,每个块必须学习显著模式。然而,随着模型容量的增加,深层块体的有效性降低。例如,图7(b)中的block 3只获取单个常数的知识。此外,如图7©所示,随着模型深度的增加,浅层块的振幅明显减小,大量分量被传递到深部块。例如,图7©中的block 3表现出与图7(a)相同的行为。这表明增加Minusformer的深度可以增强其学习能力,而不会增加过拟合的风险。
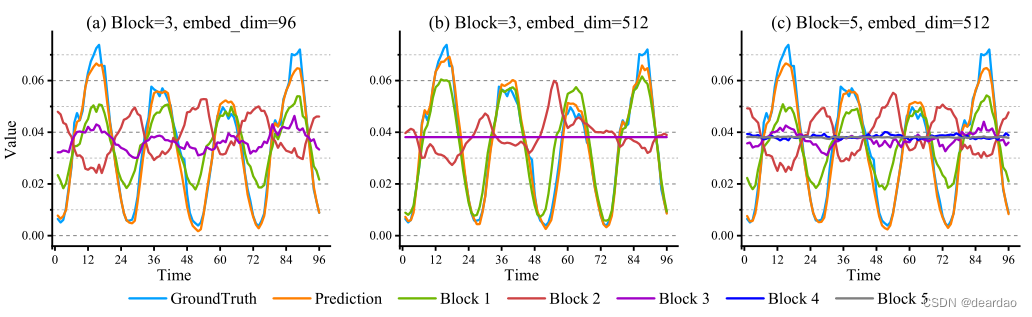
图7:Minusformer中每个块的可视化输出。实验采用Input-96-Predict-96设置在Traffic数据集上实现。所使用的模型具有相同的超参数设置和相似的性能。
3.7 走向更深
考虑到Minusformer对过拟合的鲁棒性,它可以设计得相当深入。图8说明了模型深入时的情景。当iTransformer块的数量从4个增加到8个时,会发生严重的过拟合。然而,即使Minusformer块加深到16,它继续表现出优异的性能。此外,Minusformer对超参数不太敏感,详细信息见附录E。
4 结论
在本文中,我们设计了一个专门利用减号进行信息聚合的架构,专门用于解决TS预测模型中普遍存在的过拟合问题,称为Minusformer。设计的架构促进了输入和输出流的学习驱动、隐式渐进分解,并伴随着减法有效性背后的理论基础,从而增强了模型的通用性、可解释性和抗过拟合的弹性。Minusformer对超参数不那么敏感,可以设计得非常深而不会过度拟合。大量实验证明Minusformer达到了SOTA性能。
[1] Liang D, Zhang H, Yuan D, et al. Minusformer: Improving Time Series Forecasting by Progressively Learning Residuals[J]. arXiv preprint arXiv:2402.02332, 2024.