互联网上有一个最简单而又强大的技术库,叫做pandas_ta。这个python库为你提供了一个简化的API,让你从时间序列中提取技术分析指标。今天我将和大家一起学习这个库。记得点赞、收藏~
虽然你可能会将这些函数应用于股票价格,但你可以对任何与股票价格配对的时间序列进行操作,例如,情绪甚至经济指标。
它利用具有 130 多个指标和实用程序函数以及 60 多个 TA Lib 烛台模式的 Pandas 包。包括许多常用的指标,例如:蜡烛图(cdl_pattern)、简单移动平均线(sma)、移动平均线收敛散度(macd)、赫尔指数移动平均线(hma)、布林带(bbands)、平衡交易量(obv )、aroon、Squeeze等等。
文章目录
- 技术交流
- 为什么使用pandas_ta?
- 使用方便
- 与 pandas DataFrame兼容
- 安装 pandas_ta
- 股票价格数据
- 生成股票数据
- 创建备份
- 应用pandas_ta strategy: SMA
- 布林带
- 写在最后
技术交流
技术要学会分享、交流,不建议闭门造车。 本文技术由粉丝群小伙伴推荐分享。源码、数据、技术交流提升,均可加交流群获取,群友已超过3000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88191,备注:来自CSDN +技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
为什么使用pandas_ta?
使用方便
通常有几种方法可以从股票价格中提取技术分析指标,其中一种是手动编辑完整的处理过程。如果只需要使用像移动平均线这样的简单指标,这种方法实现起来比较轻松,但当我们需要使用更复杂的数学模型时,此时就会想到想是否有这样的python库来轻松实现,其实这就是API的作用,它们调解低级代码的复杂性,提供一个简化的高级接口。
与 pandas DataFrame兼容
在存储股票信息时,我能想到的第一个方法是通过使用Pandas DataFrame。这种方法在Python用户中非常普遍,其实,使用 pandas_ta 将会更简单,还有其他常见的存储股票价格等多维数据的方法,比如说使用JSON文件。
import pandas as pd
import pandas_ta as ta
df = pd.DataFrame() # 一个空的DataFrame
# 导入数据
df = pd.read_csv("path/to/symbol.csv", sep=",")
# 如果你安装了 yfinance
df = df.ta.ticker("aapl")
# VWAP要求DataFrame索引是一个DatetimeIndex。
# 用DataFrame中合适的列替换datetime
df.set_index(pd.DatetimeIndex(df["datetime"]),
inplace=True)
# 计算结果返回并添加到DataFrame中去
df.ta.log_return(cumulative=True,
append=True)
df.ta.percent_return(cumulative=True,
append=True)
# 查看下包含结果的列
df.columns
# 查看下具体数据
df.tail()
# 继续后期处理
安装 pandas_ta
与其他许多安装起来有些困难的库相比,这个库既容易安装,又能作为 pandas 的一个扩展功能。
$ pip install pandas_ta
具体使用方法,参见下文。
股票价格数据
股市数据获取,推荐你查看这篇文章。
请注意,pandas_ta 要求数据以特定的格式结构化。
-
日期需要采用pandas.datetime格式。
-
列必须是OCHL格式
OCHL指的是金融业中一些常用的指标,用于存储价格随时间的变化。开盘价、收盘价、最高价和最低价。不同的技术分析指标可能只需要其中的一列或多列,所以拥有全部四列将使我们能够模拟库中的大多数可用指标。
为了演示目的,使用如下程序将生成一个程序性的OCHL股票。
from scipy.stats import skewnorm
import plotly.graph_objects as go
import plotly.express as px
import pandas_ta as ta
import pandas as pd
import numpy as np
import random
# 高低差的正态分布
def create_pdf(sd, mean, alfa):
# 反转阿尔法的信号
x = skewnorm.rvs(alfa, size=1000000)
print(x)
def calc(k, sd, mean):
return (k*sd)+mean
x = calc(x, sd, mean) # 分布标准化
return x
def graph_stock(df_original):
# Time_column是一个字符串
df = df_original.copy()
pd.options.plotting.backend = "plotly"
# 需要用索引创建一个列,否则plot就不会画出它
df['date'] = df.index
#fig = px.line(df, x='time', y=['price', 'price_2'])
fig = px.line(df, x='date', y=df.columns)
fig.show()
# 保存为png
#fig.write_image("csvfiles/btc.mark2mkt.png")
def graph_OCHL(df_OCHL, title):
#fig_1 = px.line(df, x=df.index, y=df.columns, title=title)
fig_2 = go.Figure(data=go.Ohlc(x=df_OCHL.index,
open=df_OCHL['open'],
high=df_OCHL['high'],
low=df_OCHL['low'],
close=df_OCHL['close']))
fig_2.update(layout_xaxis_rangeslider_visible=False)
fig_2.show()
def OCHL(group_values):
min_ = min(group_values)
max_ = max(group_values)
range = max_ - min_
open = min_+range*random.random()
close = min_+range*random.random()
return min_, max_, open, close
def simulate_stock(initial_price, drift, volatility, trend, days):
days=days*24
def create_pdf(sd, mean, alfa):
# 反转阿尔法的信号
x = skewnorm.rvs(alfa, size=1000000)
def calc(k, sd, mean):
return (k*sd)+mean
x = calc(x, sd, mean) # 标准的分布
return x
def create_empty_df(days):
# 创建一个带有日期的空数据帧
empty = pd.DatetimeIndex(
pd.date_range("2020-01-01", periods=days, freq="D")
)
empty = pd.DataFrame(empty)
# 时间,分钟,秒都在减少
empty.index = [str(x)[0:empty.shape[0]] for x in list(empty.pop(0))]
# 最终数据集
stock = pd.DataFrame([x for x in range(0, empty.shape[0])])
stock.index = empty.index
return stock
#ran = create_pdf(0.1, 0.2, 0) #del?
#np.random.choice(ran) #del?
#skeleton
stock = create_empty_df(days)
#初识值
stock[0][0] = initial_price
# 创建整个股票数据框
x = create_pdf(volatility, drift, trend)
for _ in range(1, stock.shape[0]):
stock.iloc[_] = stock.iloc[_-1]*(1+np.random.choice(x))
stock.index = pd.DatetimeIndex(stock.index)
return stock
def simulate_OCHL_stock(df, graph_timeseries=False, graph_OCHL=False):
df_ = list()
#df.groupby(np.arange(len(df))//24).apply(OCHL) non funziona
# 这是正确的方法,但需要从0开始创建一个新的df
for a, b in df.groupby(np.arange(len(df))//24):
group_values = np.array(b.values).flatten()
low, high, open, close = OCHL(group_values)
df_.append([low, high, open, close])
df_OCHL = pd.DataFrame(df_, index=pd.Series(pd.date_range("2020-01-01", periods=365, freq="D")), columns=['low', 'high', 'open', 'close'])
#graph
if graph_timeseries==True: graph_stock(df)
if graph_OCHL==True:
fig = go.Figure(
data=go.Ohlc(x=df_OCHL.index,
open=df_OCHL['open'],
high=df_OCHL['high'],
low=df_OCHL['low'],
close=df_OCHL['close'])
)
fig.update(layout_xaxis_rangeslider_visible=False)
fig.show()
return df_OCHL
生成股票数据
df_OCHL = simulate_OCHL_stock(simulate_stock(1000, 0, 0.01, 0, 365),
graph_timeseries=True,
graph_OCHL=True)
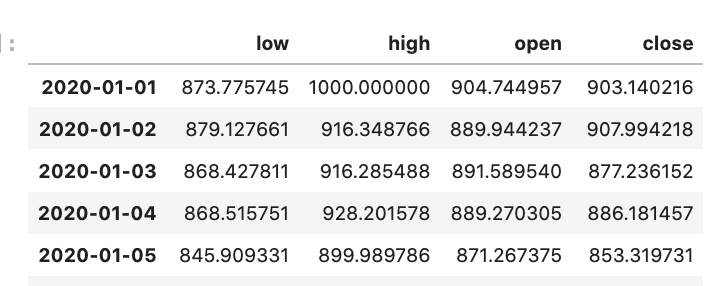
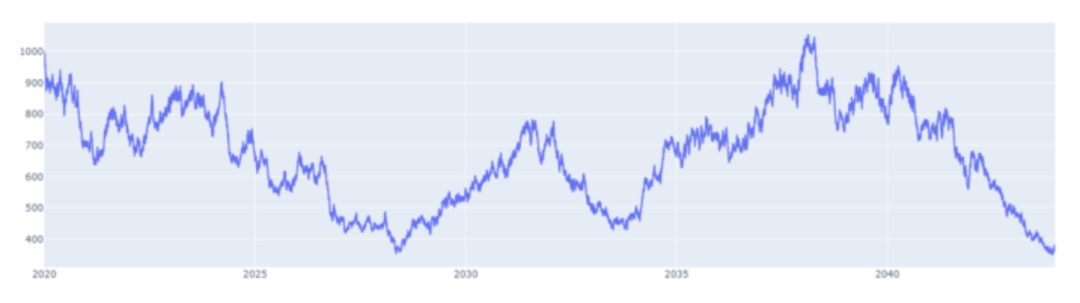
我们可以看到,每当我运行该算法时,就会产生一个新的时间序列,有4个维度,每个维度代表股票的一个OCHL数据。默认情况下,该股票只工作了365天(毕竟是出于测试目的)。让我们看一下生成的数据。
我们可以通过使用嵌入的布尔参数**graph_timeseries和graph_OCHL**轻松地绘制数据。
收盘股价产生的数据
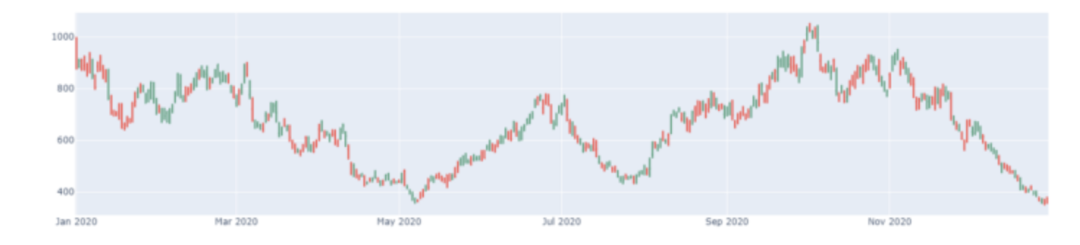
OCHL产生的数据
如果我们看一下DataFrame,生成的数据会是这样的。请注意,这种格式正是pandas_ta所要求的数据模式。
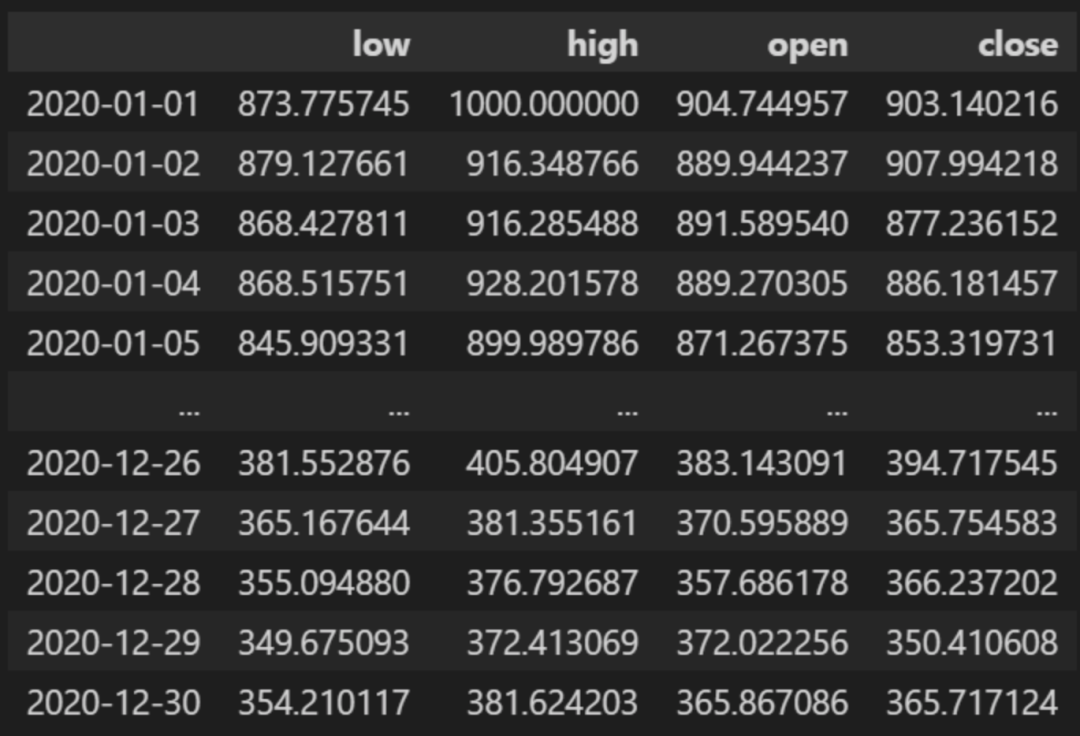
有开盘、收盘、最高、最低栏目的股票
创建备份
如果你不熟悉pandas的工作方式,我们不能简单地将一个DataFrame分配给第二个变量来复制它。我们需要使用copy函数来克隆原始DataFrame。
df_backup = df_OCHL.copy()
我之所以要复制数据,是因为 pandas_ta 会直接编辑我们应用技术分析策略的数据集。它的工作方式不像普通函数那样,我们可以输入我们的DataFrame,然后收到一个副本作为输出。
如果我们对程序模式的外观感到满意,我们可能不想在每次运行该算法时都创建一个全新的股票价格。这样一来,我们就可以安全地开始实验备份副本了。
应用pandas_ta strategy: SMA
最流行的技术分析策略被称为简单移动平均线。该技术包括创建两条不同长度的移动平均线,并使用交叉点作为买入和卖出信号。
#导入备份
df = df_backup.copy()MyStrategy = ta.Strategy(
name="DCSMA10",
ta=[
{"kind": "ohlc4"},
{"kind": "sma", "length": 10},
{"kind": "sma", "length": 20},
]
)
# 运行策略
df.ta.strategy(MyStrategy)
df = df.drop(['low', 'high', 'open'], axis=1)
graph_stock(df)
应用该策略后,我们可以看到新的列是如何被添加到我们的原始数据集中的。

两个不同长度的简单移动平均线
布林带
当然,我们也可以采用更复杂的技术,如布林带:这种策略包括当价格达到下限带以下时买入股票,当价格达到上限带以上时卖出。
我们的假设是,当趋势的导数(也就是瞬时变化率)根据我们的参数达到最大容忍度时,是股票反转趋势的适当时机。
#导入备份
df = df_backup.copy()MyStrategy = ta.Strategy(
name="strategy_3",
ta=[{
"close": 'close',
"kind": "bbands",
"length": 15,
"std": 2
}]
)
# 运行策略
df.ta.strategy(MyStrategy)
df = df.drop(['low', 'high', 'open'], axis=1)
graph_stock(df)
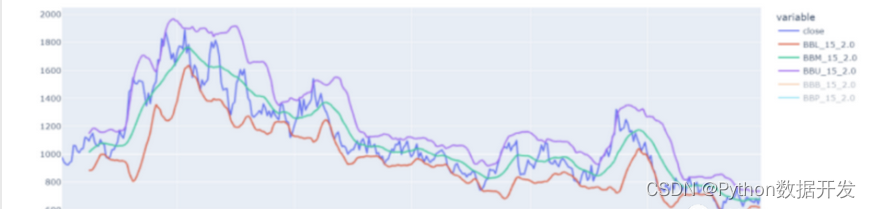
布林带的标准偏差为2
写在最后
Pandas_ta,特别是在设置之后,使用起来非常简单和直观,有80多个可用的指标,你可以简单地调用字符串。







![buuctf-web-[BJDCTF2020]Easy MD51](https://img-blog.csdnimg.cn/img_convert/e32defdf90ab4d649b5c46bd8b64b008.png)