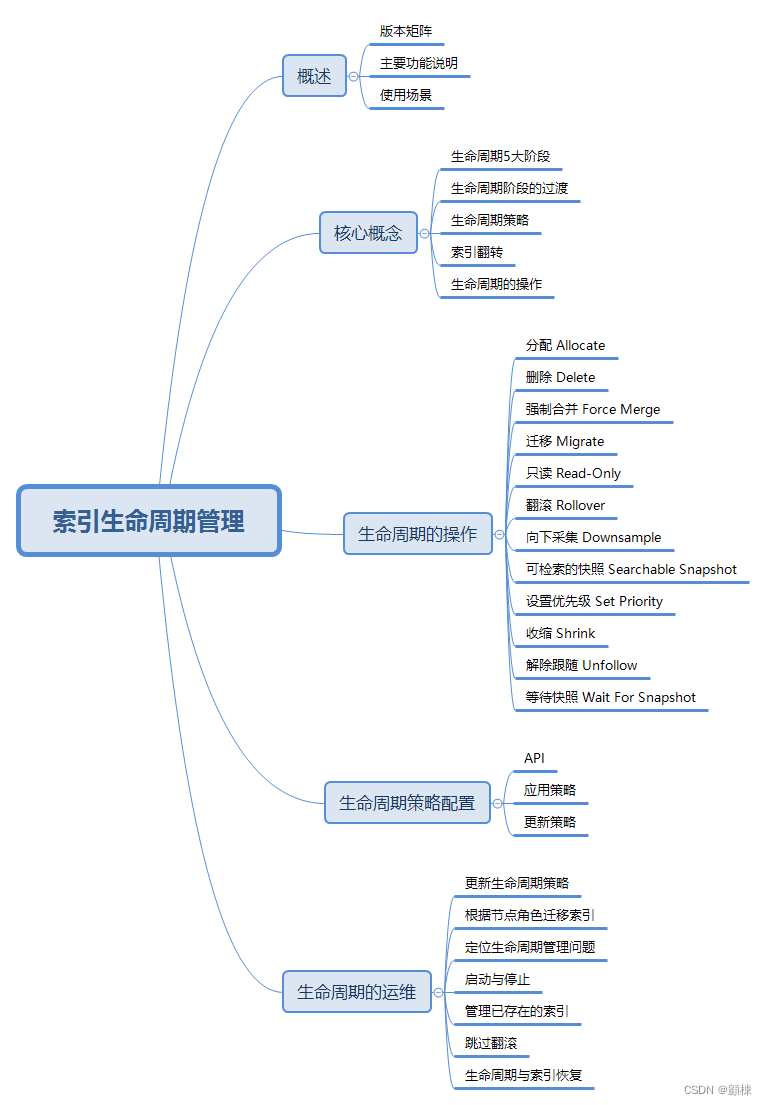
1. Transformer架构
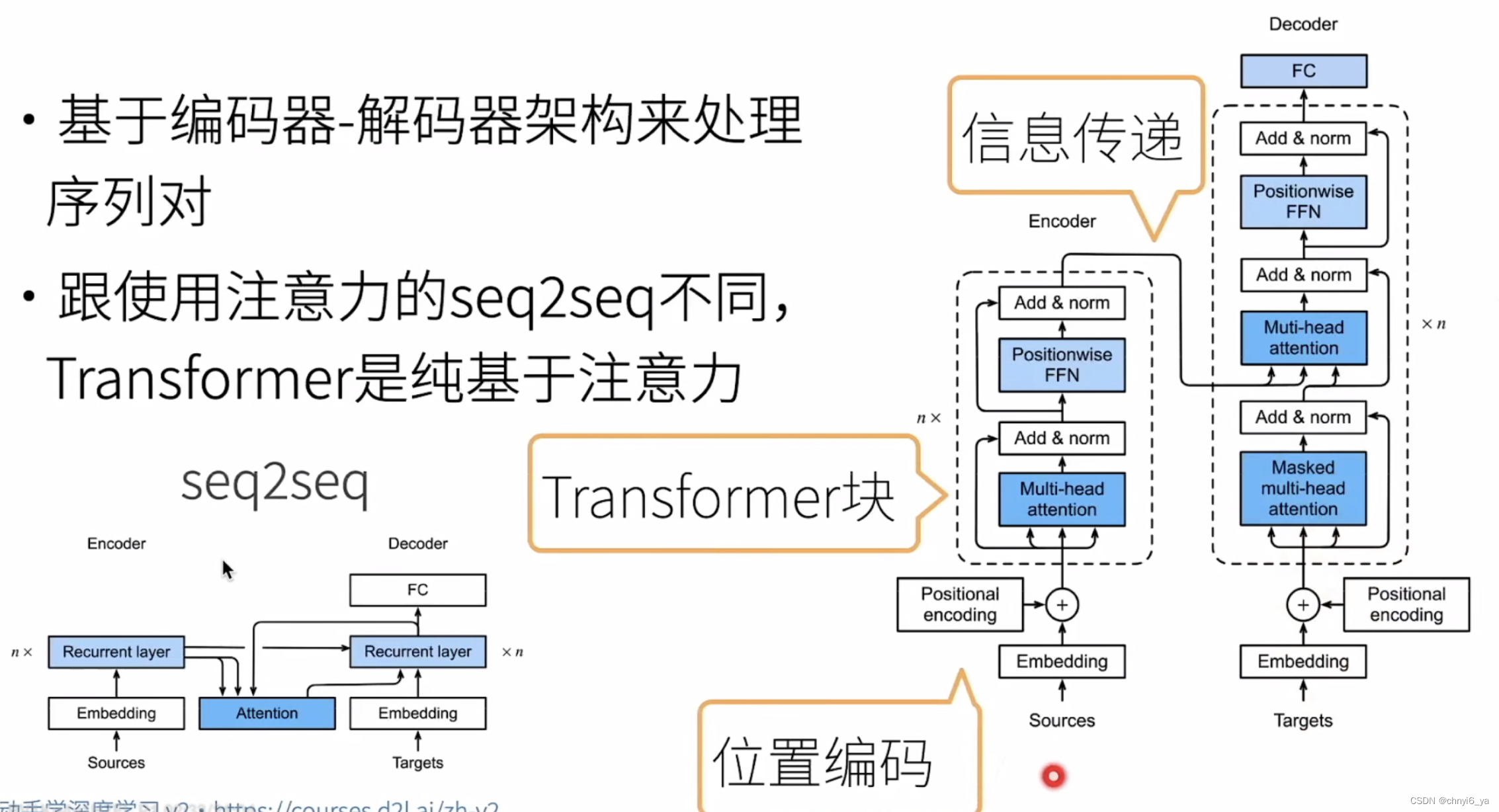
2. 多头注意力
3. 数学上来解释多头注意力

4. 有掩码的多头注意力

5. 基于位置的前馈网络

6. 层归一化
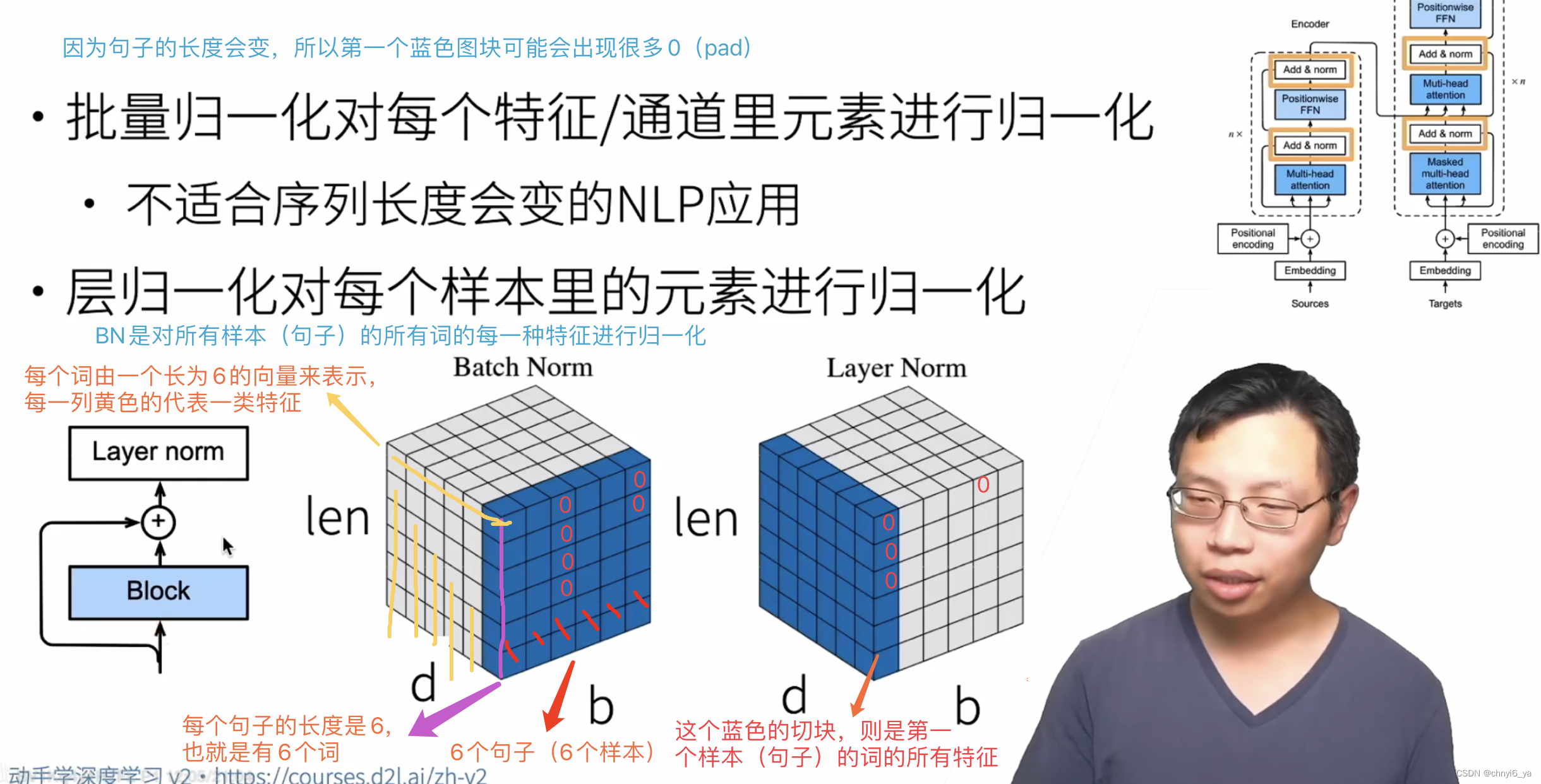
batch norm:比如说一行是一个样本,那么BN就是对一列进行归一化,就是对所有数据项的某一列特征进行归一化
layer norm:是对一个单样本内部做归一化,也就是对一个句子做norm,所以即使句子长度不一样,也对稳定性影响不大
7. 信息传递

8. 预测
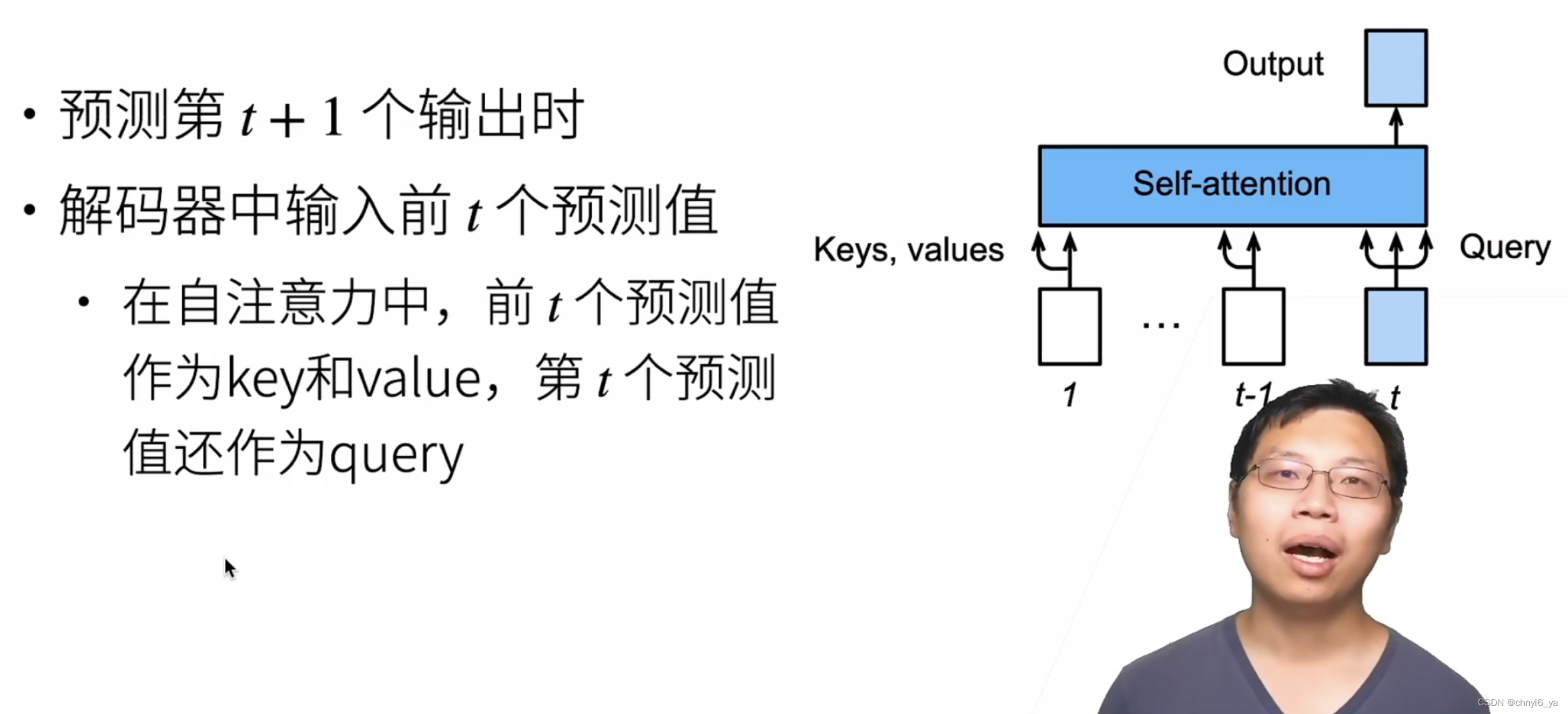
- 训练时,decoder中,第一个mask-多头k、v来自本身的Q,第二个attention的K、V来自encoder的输出;预测时,decoder中的K、V来自decoder的上一时刻的输出
9. 总结
- Transformer时一个纯使用注意力的编码-解码器
- 编码器和解码器都有n个transformer块
- 每个块里使用多头(自)注意力,基于位置的前馈网络和层归一化
10. 代码实现
import math
import torch
from torch import nn
from d2l import torch as d2l
10.1 多头注意力
在实现过程中通常选择缩放点积注意力作为每一个注意力头。 为了避免计算代价和参数代价的大幅增长, 我们设定 𝑝𝑞=𝑝𝑘=𝑝𝑣=𝑝𝑜/ℎ 。 值得注意的是,如果将查询、键和值的线性变换的输出数量设置为 𝑝𝑞ℎ=𝑝𝑘ℎ=𝑝𝑣ℎ=𝑝𝑜 , 则可以并行计算 ℎ 个头。 在下面的实现中, 𝑝𝑜 是通过参数num_hiddens指定的。
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
# attention用的是点击attention
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
为了能够使多个头并行计算, 上面的MultiHeadAttention类将使用下面定义的两个转置函数。 具体来说,transpose_output函数反转了transpose_qkv函数的操作。
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
# 返回X的形状是(batch_size,num_heads,查询的个数,num_hiddens/num_heads)
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
# permute后的形状是(batch_size,查询的个数,num_heads,num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# X.shape[0]:batch_size,X.shape[1]:查询的个数
# 返回的X的形状是(batch_size,查询的个数,num_hiddens)
return X.reshape(X.shape[0], X.shape[1], -1)
下面使用键和值相同的小例子来测试我们编写的MultiHeadAttention类。 多头注意力输出的形状是(batch_size,num_queries,num_hiddens)。
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
运行结果:

batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
运行结果,也能看出,如果是self-attention的话,输入是怎样的形状(X),输出也是一样的形状:

10.2 Transformer
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
1. 基于位置的前馈网络
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),这就是称前馈网络是基于位置的(positionwise)的原因。在下面的实现中,输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机转换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量。
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
# 其实本质上就是一个单隐藏层的MLP,只是输入不再是二维,而是个三维的tensor,
# 所以名字就叫做 "基于位置的前馈网络"
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
# pytorch中dense的默认的实现:
# 当输入X不是二维的tensor时,把前面的维度都当作样本维,最后的一个维度当作特征维度
return self.dense2(self.relu(self.dense1(X)))
下面的例子显示,改变张量的最里层维度的尺寸,会改变成基于位置的前馈网络的输出尺寸。因为用同一个多层感知机对所有位置上的输入进行变换,所以当所有这些位置的输入相同时,它们的输出也是相同的。
ffn = PositionWiseFFN(4, 4, 8)
ffn.eval()
# 输入形状时(2,3,4),经过ffn会得到形状(2,3,8)
ffn(torch.ones((2, 3, 4)))[0]
运行结果:

2. 残差连接和层规范化
现在让我们关注 transformer中的加法和规范化(add&norm)组件。正如在本节开头所述,这是由残差连接和紧随其后的层规范化组成的。两者都是构建有效的深度架构的关键。
层规范化和批量规范化的目标相同,但层规范化是基于特征维度进行规范化。尽管批量规范化在计算机视觉中被广泛应用,但在自然语言处理任务中(输入通常是变长序列)批量规范化通常不如层规范化的效果好。
以下代码对比不同维度的层规范化和批量规范化的效果。
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# 在训练模式下计算X的均值和方差
print('layer norm:', ln(X), '\nbatch norm:', bn(X))
运行结果:

现在可以使用残差连接和层规范化来实现AddNorm类。暂退法也被作为正则化方法使用。
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
# Y是X进入某一块运算后的输出
return self.ln(self.dropout(Y) + X)
残差连接要求两个输入的形状相同,以便加法操作后输出张量的形状相同。
add_norm = AddNorm([3, 4], 0.5)
add_norm.eval()
add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape
运行结果:

3. 编码器
有了组成Transformer编码器的基础组件,现在可以先实现编码器中的一个层。下面的EncoderBlock类包含两个子层:多头自注意力和基于位置的前馈网络,这两个子层都使用了残差连接和紧随的层规范化。
class EncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,
use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
正如从代码中所看到的,Transformer编码器中的任何层都不会改变其输入的形状。
X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shape
运行结果:

下面实现的Transformer编码器的代码中,堆叠了num_layers个EncoderBlock类的实例。由于这里使用的是值范围在 −1 和 1 之间的固定位置编码,因此通过学习得到的输入的嵌入表示的值需要先乘以嵌入维度的平方根进行重新缩放,然后再与位置编码相加。
class TransformerEncoder(d2l.Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
# 因为位置编码pos_encoding值在-1和1之间,而embedding(X)中的数值比较小,
# 特别是当d(num_hiddens)越大的时候,embedding(X)中每个元素值越小
# 因此嵌入值乘以嵌入维度的平方根进行缩放,使得相乘后的结果和位置编码的值的数值差不多大小
# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X
下面我们指定了超参数来创建一个两层的Transformer编码器。 Transformer编码器输出的形状是(批量大小,时间步数目,num_hiddens)。
encoder = TransformerEncoder(
200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape
运行结果:

4. 解码器
Transformer解码器也是由多个相同的层组成。在DecoderBlock类中实现的每个层包含了三个子层:解码器自注意力、“编码器-解码器”注意力和基于位置的前馈网络。这些子层也都被残差连接和紧随的层规范化围绕。
在掩蔽多头解码器自注意力层(第一个子层)中,查询、键和值都来自上一个解码器层的输出。关于序列到序列模型(sequence-to-sequence model),在训练阶段,其输出序列的所有位置(时间步)的词元都是已知的;然而,在预测阶段,其输出序列的词元是逐个生成的。
因此,在任何解码器时间步中,只有生成的词元才能用于解码器的自注意力计算中。为了在解码器中保留自回归的属性,其掩蔽自注意力设定了参数dec_valid_lens,以便任何查询都只会与解码器中所有已经生成词元的位置(即直到该查询位置为止)进行注意力计算。
class DecoderBlock(nn.Module):
"""解码器中第i个块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
# 训练阶段,输出序列的所有词元都在同一时间处理,
# 因此state[2][self.i]初始化为None。
# 预测阶段,输出序列是通过词元一个接着一个解码的,
# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
if state[2][self.i] is None: # 如果为none,就表示在train阶段
key_values = X
else: # 预测阶段
# 假设预测t时刻,要把1~t-1时刻的state都和当前时刻的query(X)concat到一起
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if self.training: # 训练阶段,有valid_lens,因为算第i个输出的时候,要把后面的mask
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),
# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(
1, num_steps + 1, device=X.device).repeat(batch_size, 1)
else: # 预测阶段,本来也看不到后面的,因为是一个一个预测的
dec_valid_lens = None
# 自注意力
# 可以看出,如果是training阶段,key_values就是X本身(自注意力)
# 但是在prediction的时候,key_values是之前的输出concat到一起
# 加上dec_valid_lens是为了在train的时候不要看后面的东西
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# 编码器-解码器注意力。
# enc_outputs的开头:(batch_size,num_steps,num_hiddens)
# key和value都是来自于编码器的输出enc_outputs
# enc_valid_lens:使用了编码器的valid_lens能把pad去掉
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
为了便于在“编码器-解码器”注意力中进行缩放点积计算和残差连接中进行加法计算,编码器和解码器的特征维度都是num_hiddens。
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
decoder_blk(X, state)[0].shape
运行结果:

现在我们构建了由num_layers个DecoderBlock实例组成的完整的Transformer解码器。
最后,通过一个全连接层计算所有vocab_size个可能的输出词元的预测值。解码器的自注意力权重和编码器解码器注意力权重都被存储下来,方便日后可视化的需要。
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
# 把每一层decoderblock放入
for i in range(num_layers):
self.blks.add_module("block"+str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
# 需要全连接层做输出
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# 第3个参数是state,先给每一层都取none
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
# 把_attention_weights存下来用来可视化
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
# 向每个block丢入X和state,再拿到更新的X和state,有n层就做n下
X, state = blk(X, state)
# 解码器自注意力权重,第0行表示第1层,第2层,...,第n层的解码器自注意力权重
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
# 第1行表示第1层,第2层,...,第n层的"编码器-解码器"自注意力权重
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
# 循环结束,也就表示X和state随着每一层的计算也进行更新
# 最后再把更新后的X放入dense层,对序列中的每一个样本做dense,
# 如果序列长度为100,那么这100个样本都会有一个vocab_size大小的向量
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
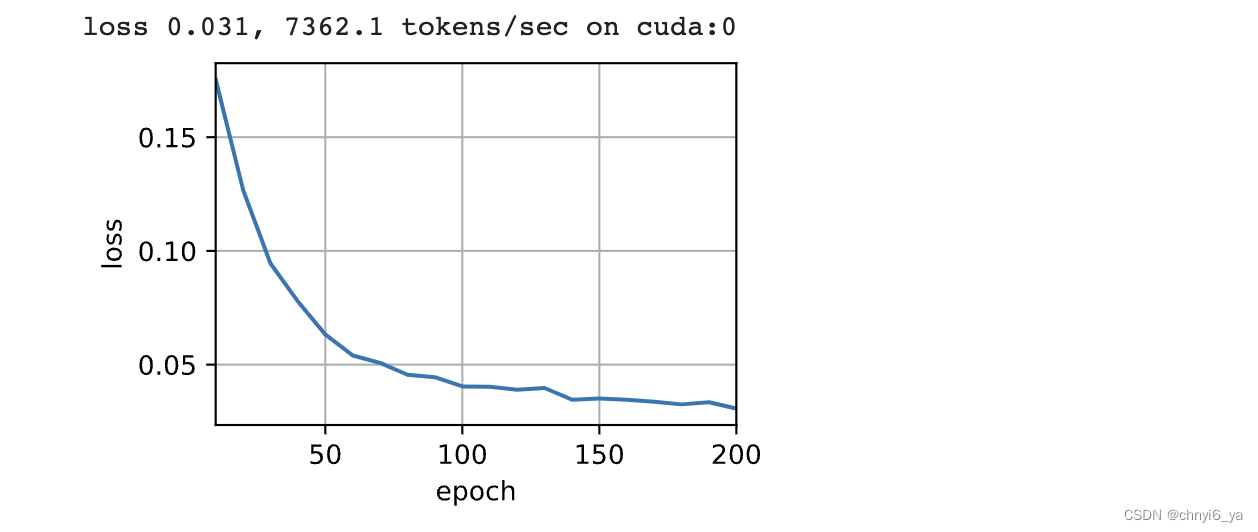
5. 训练
依照Transformer架构来实例化编码器-解码器模型。在这里,指定Transformer的编码器和解码器都是2层,都使用4头注意力。与 seq2seq_training类似,为了进行序列到序列的学习,下面在“英语-法语”机器翻译数据集上训练Transformer模型。
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
decoder = TransformerDecoder(
len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
运行结果:
训练结束后,使用Transformer模型将一些英语句子翻译成法语,并且计算它们的BLEU分数。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
运行结果:

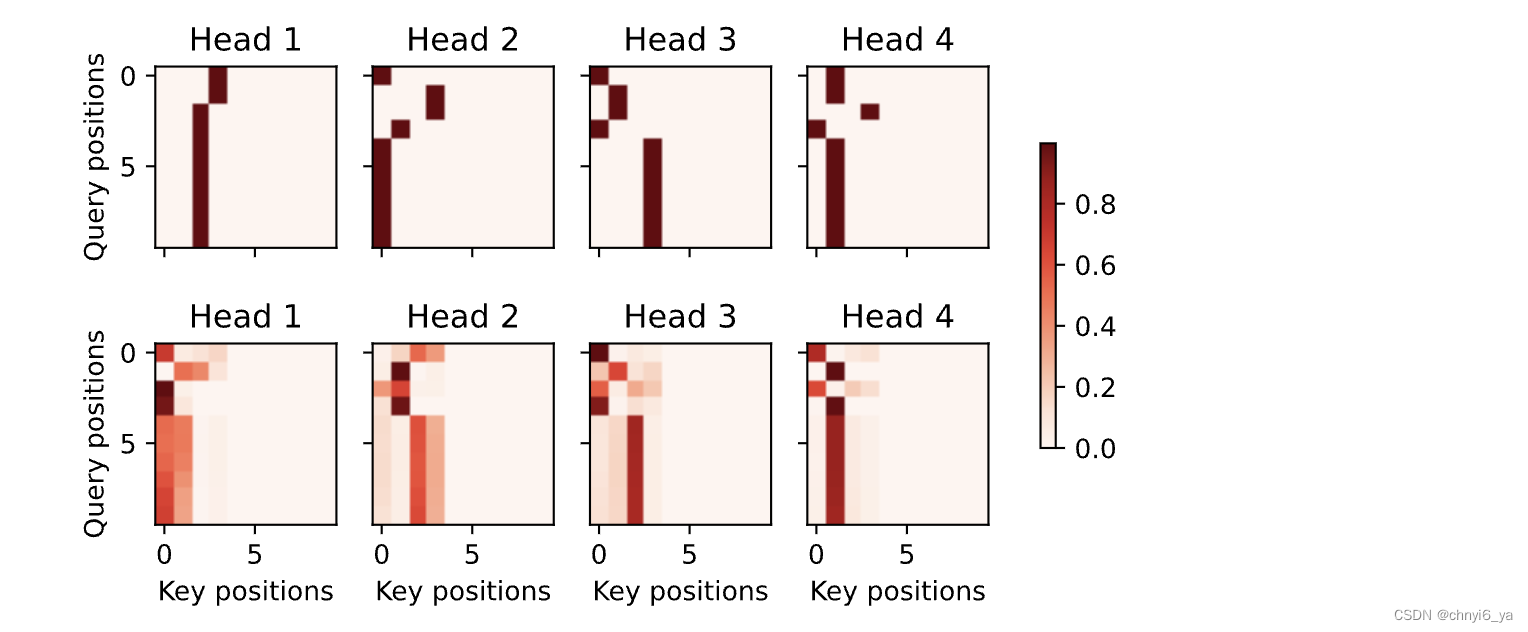
当进行最后一个英语到法语的句子翻译工作时,让我们可视化Transformer的注意力权重。编码器自注意力权重的形状为(编码器层数,注意力头数,num_steps或查询的数目,num_steps或“键-值”对的数目)。
enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers, num_heads,
-1, num_steps))
enc_attention_weights.shape
运行结果:

在编码器的自注意力中,查询和键都来自相同的输入序列。因为填充词元是不携带信息的,因此通过指定输入序列的有效长度可以避免查询与使用填充词元的位置计算注意力。接下来,将逐行呈现两层多头注意力的权重。每个注意力头都根据查询、键和值的不同的表示子空间来表示不同的注意力。
d2l.show_heatmaps(
enc_attention_weights.cpu(), xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
运行结果:
为了可视化解码器的自注意力权重和“编码器-解码器”的注意力权重,我们需要完成更多的数据操作工作。例如用零填充被掩蔽住的注意力权重。值得注意的是,解码器的自注意力权重和“编码器-解码器”的注意力权重都有相同的查询:即以序列开始词元(beginning-of-sequence,BOS)打头,再与后续输出的词元共同组成序列。
dec_attention_weights_2d = [head[0].tolist()
for step in dec_attention_weight_seq
for attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(
pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \
dec_attention_weights.permute(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape
运行结果:

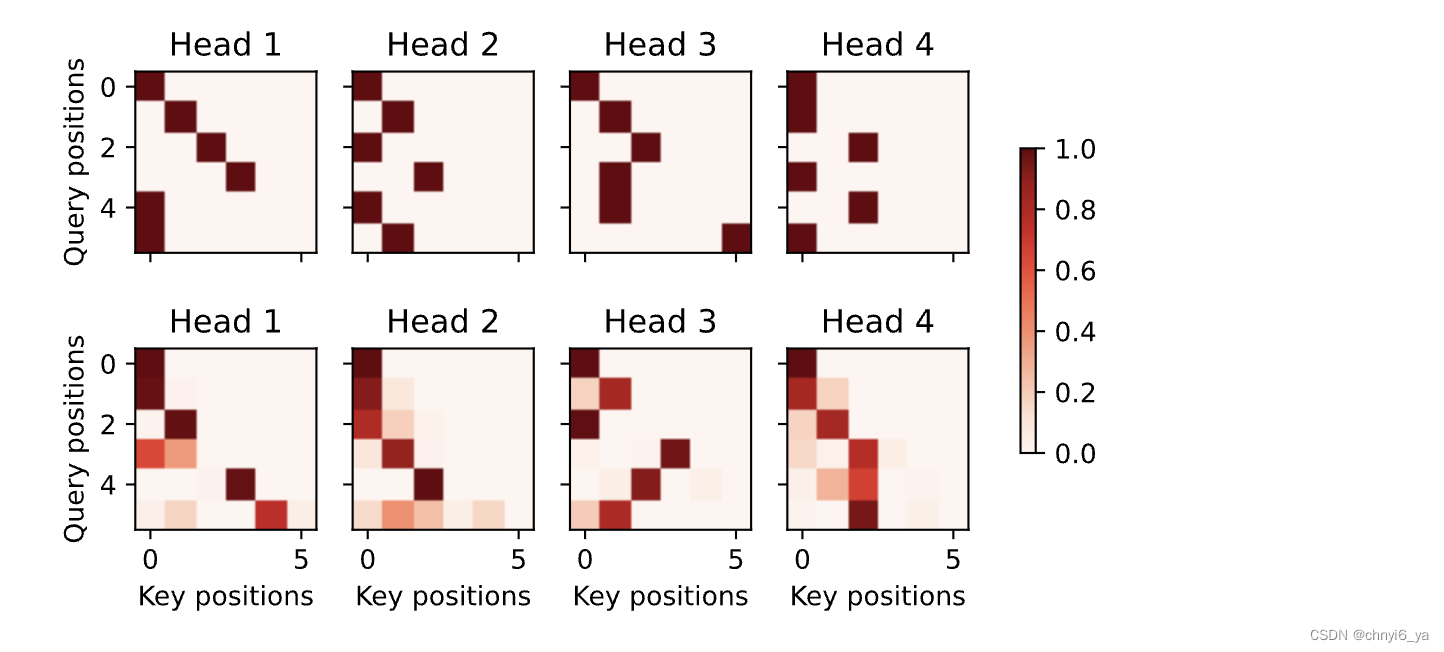
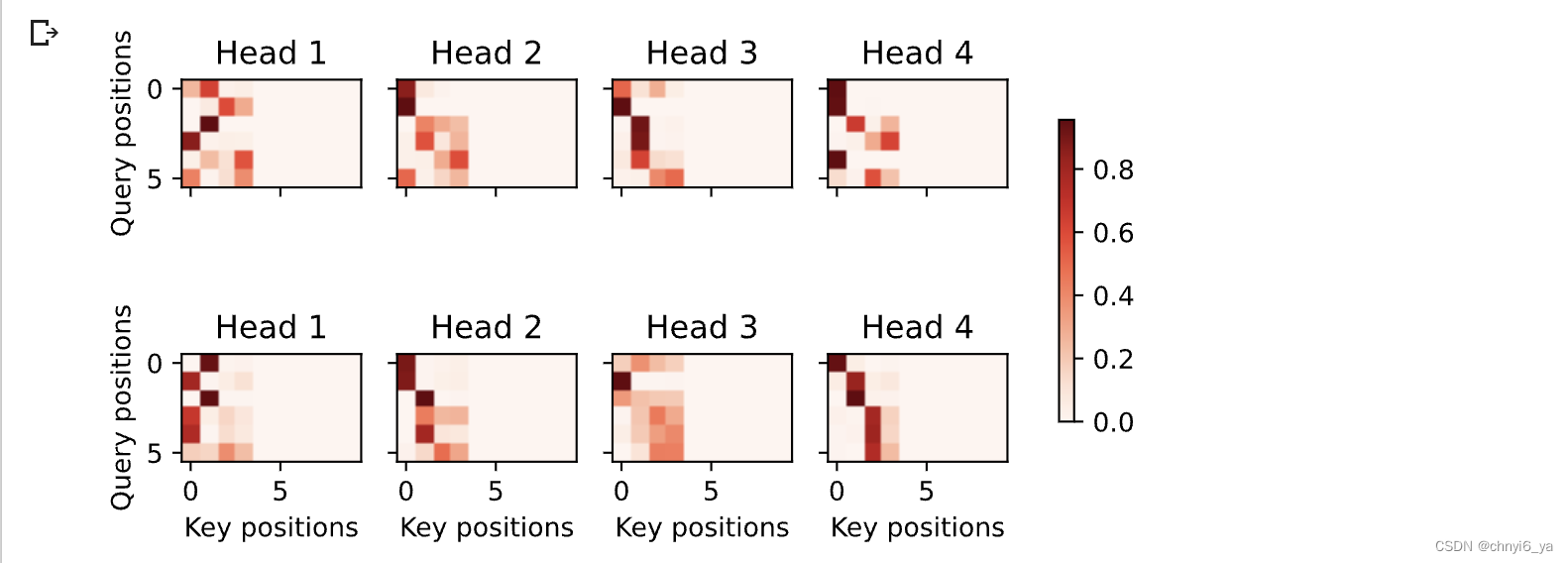
由于解码器自注意力的自回归属性,查询不会对当前位置之后的“键-值”对进行注意力计算。
# Plusonetoincludethebeginning-of-sequencetoken
d2l.show_heatmaps(
dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],
xlabel='Key positions', ylabel='Query positions',
titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))
运行结果:
与编码器的自注意力的情况类似,通过指定输入序列的有效长度,输出序列的查询不会与输入序列中填充位置的词元进行注意力计算。
d2l.show_heatmaps(
dec_inter_attention_weights, xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))
运行结果:
尽管Transformer架构是为了序列到序列的学习而提出的,但正如本书后面将提及的那样,Transformer编码器或Transformer解码器通常被单独用于不同的深度学习任务中。
Q&A
Q:kvq大小一般怎么选择呢?
A:一般取hidden_size。





![buuctf-web-[BJDCTF2020]Easy MD51](https://img-blog.csdnimg.cn/img_convert/e32defdf90ab4d649b5c46bd8b64b008.png)