一:docker-hub官网寻找需求镜像
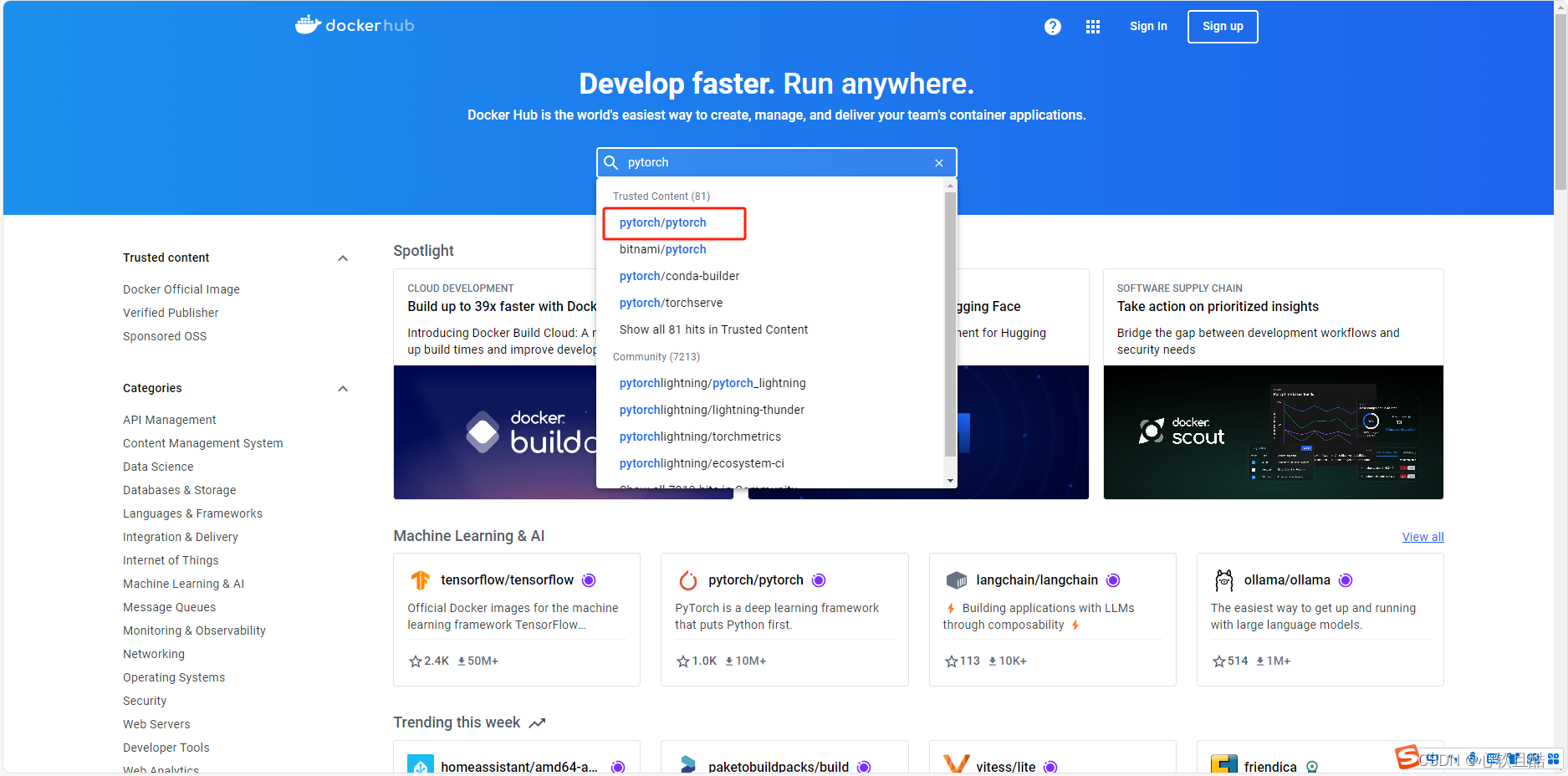
1.我们在https://hub.docker.com/官网找到要封装的pytorch基础镜像,这里我们以pytorch1.13.1版本为例
2.我们找到的这个devel版本的镜像(我们需要cuda的编译工具)
pytorch版本是1.13.1,cuda版本是11.6,cudnn gpu加速库的版本是8版本(ubuntu系统已经封装在镜像里了,一会启动时候就可以去判断系统版本是多少了)
3.runtime和devel版本的区别解释:
1.13.1-cuda11.6-cudnn8-devel: devel 是 "development" 的缩写,表示这是一个开发版本。 这个版本包含了开发深度学习应用所需的工具和库,比如编译器、头文件、静态库等。 适用于需要编译和开发深度学习应用的场景。 1.13.1-cuda11.6-cudnn8-runtime: runtime 表示这是一个运行时版本。 这个版本主要包含运行深度学习应用所需的库和二进制文件,但不包含开发工具和头文件。 适用于只需要运行预编译的深度学习模型或应用的场景。 为什么一个大一个小? 内容不同: devel 版本包含了更多的开发工具、头文件和静态库,这些文件在编译和开发过程中是必需的,但在运行时并不需要。 runtime 版本只包含运行时所需的库和二进制文件,省去了开发工具和头文件,因此体积更小。 用途不同: devel 版本适用于开发环境,你可以在这个环境中编译和调试深度学习应用。 runtime 版本适用于生产环境或部署环境,你只需要运行已经开发好的深度学习应用。 具体区别 包含的文件: devel 版本:包含 CUDA 编译器(nvcc)、开发工具(如 gdb、profiler)、头文件(如 .h 文件)、静态库(如 .a 文件)以及所有的运行时库。 runtime 版本:仅包含运行时库(如 .so 文件)和必要的二进制文件。 使用场景: devel 版本:适用于需要编译和开发的场景,如开发新模型、编写自定义 CUDA 内核等。 runtime 版本:适用于部署和运行已经编译好的模型和应用,如在生产环境中运行深度学习推理服务。 总结 选择哪个版本取决于你的需求: 如果你需要开发和编译深度学习应用,选择 devel 版本。 如果你只需要运行已经开发好的深度学习应用,选择 runtime 版本。二:拉取基础镜像
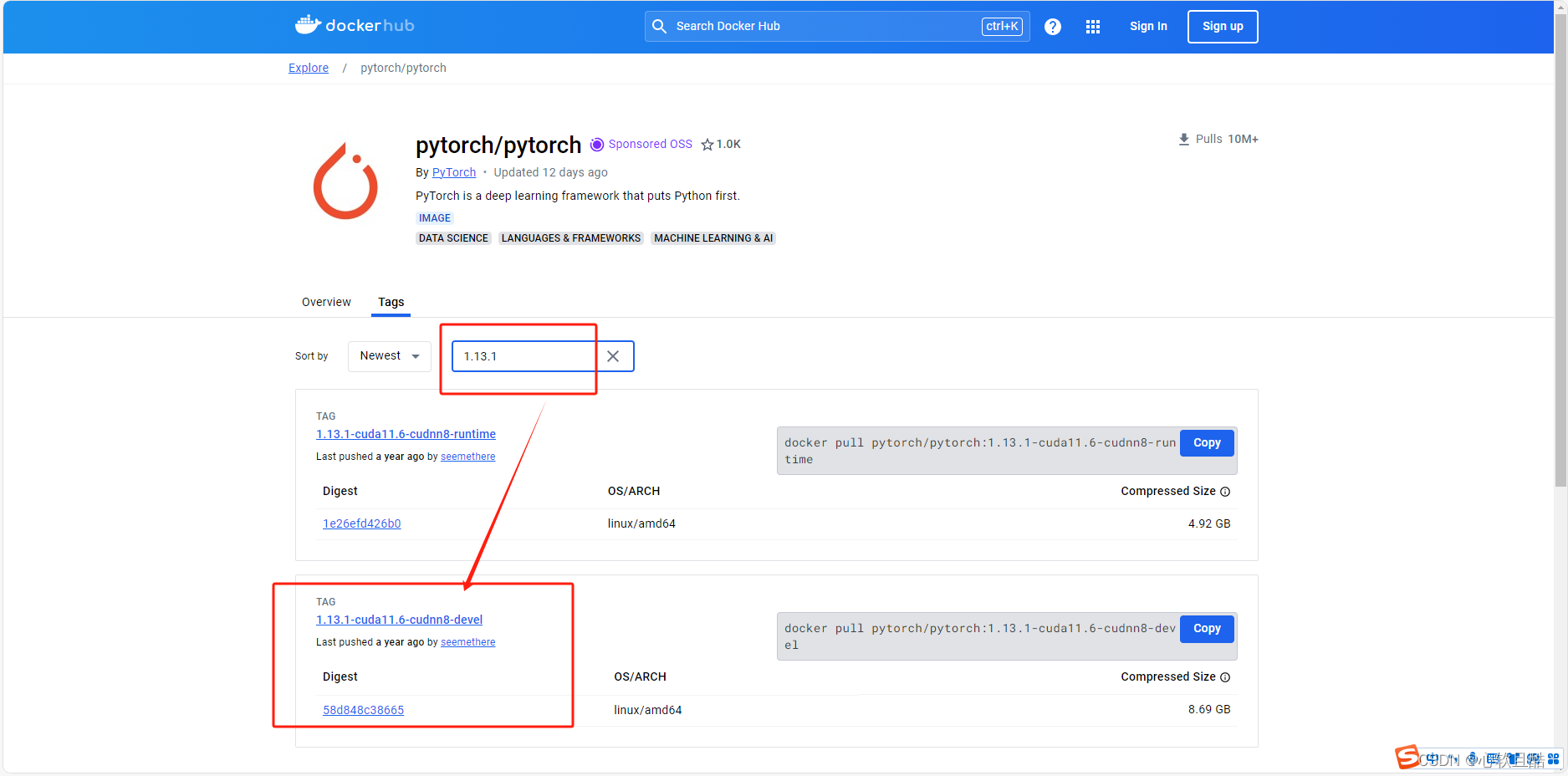
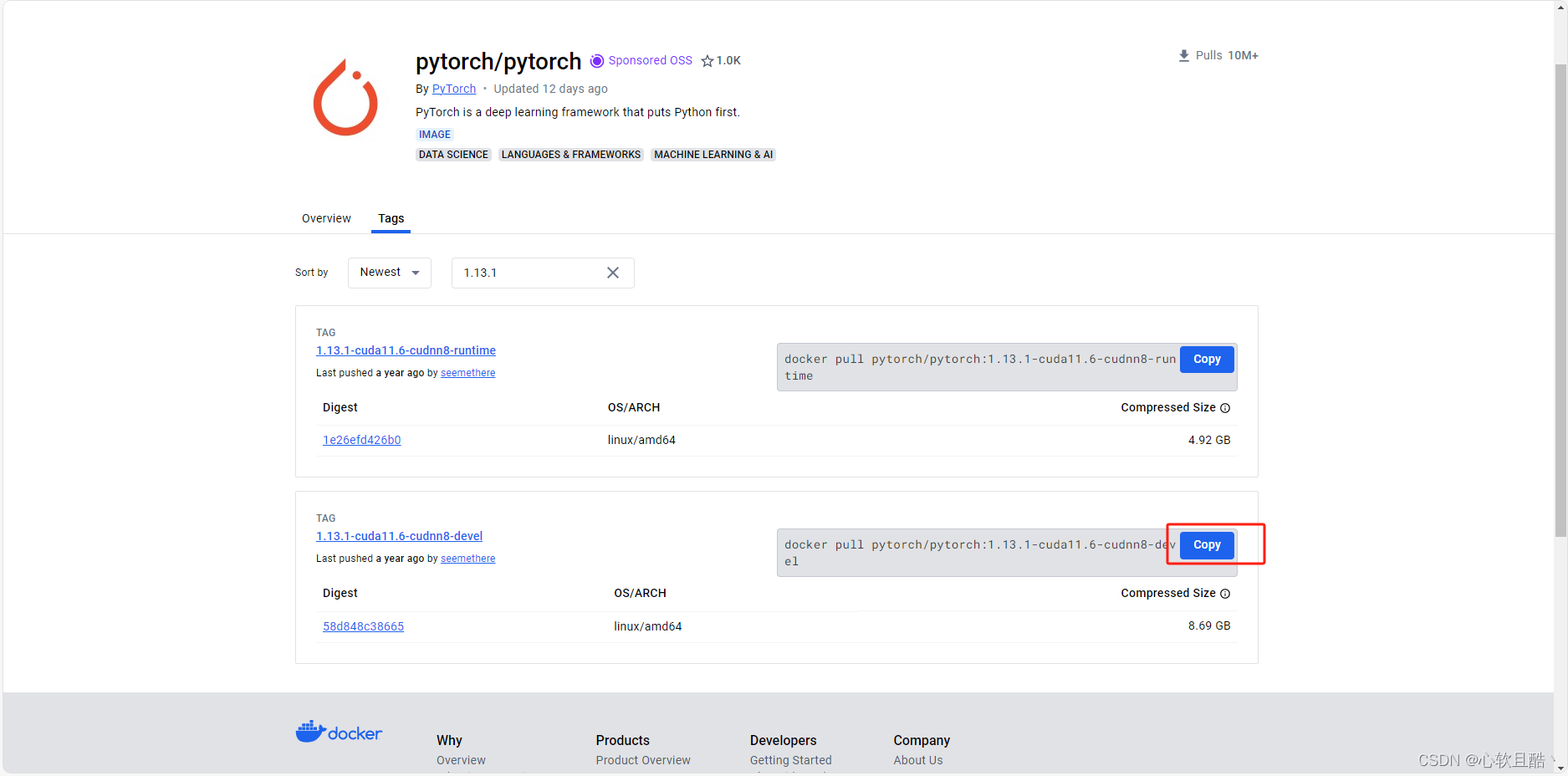
1.复制拉取命令
2.服务器上拉取基础镜像
docker pull pytorch/pytorch:1.13.1-cuda11.6-cudnn8-devel3.配置docker守护进程加速
最近dockerhub还有一些国内镜像加速源都都不好用了,这里建议走代理服务器或者给docker守护进程配置代理:
Linux服务器开启临时外网全局代理-CSDN博客
或者:
docker守护进程配置代理-CSDN博客
三:编写我们的dockerfile文件内容
需求描述:
(1)我们镜像里要求已安装好我们要用到的命令和python包等等:
## 更新包列表并安装基本工具 apt-get update && apt-get install -y \ sudo \ wget \ curl \ vim \ python3 \ python3-pip \ openssh-server \ openssh-client && \ rm -rf /var/lib/apt/lists/*(2)要求python命令指向python3:
# 设置 python 命令指向 python3 ln -s /usr/bin/python3 /usr/bin/python(3)要求修改pip源为阿里云镜像源:
mkdir -p /root/.pip \ && echo "[global]" > /root/.pip/pip.conf \ && echo "index-url = https://mirrors.aliyun.com/pypi/simple/" >> /root/.pip/pip.conf \ && echo "trusted-host = mirrors.aliyun.com" >> /root/.pip/pip.con(4)要求安装并启动ssh和jupyter-lab服务,这里我们通过外挂启动脚本实现:
# 将启动脚本配置在容器中 COPY setup.sh /setup.sh # 本地目录拷贝启动脚本到容器内/目录下 RUN chmod +x /setup.sh # 使用启动脚本作为容器初始化入口 ENTRYPOINT ["/setup.sh"](5)防止宿主机不同型号gpu导致的cuda调用异常,需要封装PyTorch NVML 基于 CUDA 检查环境变量:
ENV PYTORCH_NVML_BASED_CUDA_CHECK=1完整的dockerfile文件内容:
vim torch1.13.1_dockerfile# 定义基础镜像 FROM pytorch/pytorch:1.13.1-cuda11.6-cudnn8-devel # 设置非互动模式以避免一些安装过程中的对话框 ENV DEBIAN_FRONTEND=noninteractive # 删除无效的 Nvidia 存储库(如果它存在的话) #RUN rm /etc/apt/sources.list.d/cuda.list || true #RUN rm /etc/apt/sources.list.d/nvidia-ml.list || true # 更新包列表并安装基本工具 RUN apt-get update && apt-get install -y \ sudo \ wget \ curl \ vim \ python3 \ python3-pip \ openssh-server \ openssh-client && \ rm -rf /var/lib/apt/lists/* # 添加NVIDIA存储库和公钥 #RUN distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && \ # curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | apt-key add - && \ # curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | tee /etc/apt/sources.list.d/nvidia-docker.list && \ # apt-get update && apt-get install -y nvidia-container-toolkit && \ # rm -rf /var/lib/apt/lists/* # 设置 python 命令指向 python3 RUN ln -s /usr/bin/python3 /usr/bin/python # 修改 pip 源为阿里云镜像源 RUN mkdir -p /root/.pip \ && echo "[global]" > /root/.pip/pip.conf \ && echo "index-url = https://mirrors.aliyun.com/pypi/simple/" >> /root/.pip/pip.conf \ && echo "trusted-host = mirrors.aliyun.com" >> /root/.pip/pip.conf # 设置 CUDA 环境变量 #ENV CUDA_VERSION=11.6 #ENV CUDA_HOME=/usr/local/cuda-$CUDA_VERSION #ENV PATH=$CUDA_HOME/bin:$PATH #ENV LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH # 设置 PyTorch NVML 基于 CUDA 检查环境变量 ENV PYTORCH_NVML_BASED_CUDA_CHECK=1 # 声明暴露 SSH 和 Jupyter Lab 端口 EXPOSE 22 EXPOSE 8888 # 将启动脚本配置在容器中 COPY setup.sh /setup.sh RUN chmod +x /setup.sh # 使用启动脚本作为容器初始化入口 ENTRYPOINT ["/setup.sh"]完整的setup.sh启动脚本内容:
vim setup.sh#!/bin/bash # 设置清华源,如果尚未设置阿里源 if ! pip config get global.index-url | grep -q "https://pypi.tuna.tsinghua.edu.cn/simple"; then echo "设置 pip 使用清华源..." pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple fi # 检查 JupyterLab 是否已安装 if ! pip show jupyterlab > /dev/null 2>&1; then echo "安装 JupyterLab..." pip install jupyterlab else echo "JupyterLab 已安装,跳过安装步骤。" fi # 为 SSHD 创建必要的目录 echo "创建 SSHD 必要的目录..." mkdir -p /var/run/sshd mkdir -p /root/.ssh # 为 Jupyter Lab 创建工作目录 if [ ! -d /root/workspace ]; then echo "创建 Jupyter Lab 工作目录..." mkdir -p /root/workspace chown -R root:root /root/workspace fi # 如果 authorized_keys 文件不存在,则创建它 if [ ! -f /root/.ssh/authorized_keys ]; then echo "创建 authorized_keys 文件..." touch /root/.ssh/authorized_keys chmod 600 /root/.ssh/authorized_keys chown -R root:root /root/.ssh fi # 配置 sshd 服务,如果尚未配置 if [ ! -f /etc/ssh/sshd_config ]; then echo "配置 SSHD 服务..." cat <<EOF > /etc/ssh/sshd_config Port 22 PermitRootLogin yes PubkeyAuthentication yes AuthorizedKeysFile .ssh/authorized_keys PasswordAuthentication yes ChallengeResponseAuthentication no UsePAM yes X11Forwarding yes PrintMotd no AcceptEnv LANG LC_* Subsystem sftp /usr/lib/openssh/sftp-server EOF # 生成 sshd 主机密钥 echo "生成 SSHD 主机密钥..." ssh-keygen -A else echo "SSHD 服务已经配置,跳过配置步骤。" fi # 检查 SSHD 服务是否正在运行,如果不是则启动 if ! pgrep -x "sshd" > /dev/null; then echo "启动 SSHD 服务..." /usr/sbin/sshd else echo "SSHD 服务已经运行,跳过启动步骤。" fi # 检查 JupyterLab 服务是否已经启动 if ! pgrep -f "jupyter-lab" > /dev/null; then echo "启动 JupyterLab..." nohup jupyter lab --ip=0.0.0.0 --allow-root --no-browser --notebook-dir=/root/workspace >/dev/null 2>&1 & else echo "JupyterLab 已在运行,跳过启动步骤。" fi # 添加一个阻塞进程,保持容器运行 echo "容器已启动并运行,阻止脚本退出以保持容器运行..." tail -f /dev/null四:构建镜像
以咱们刚才编辑好的dockerfile和setup.sh构建镜像
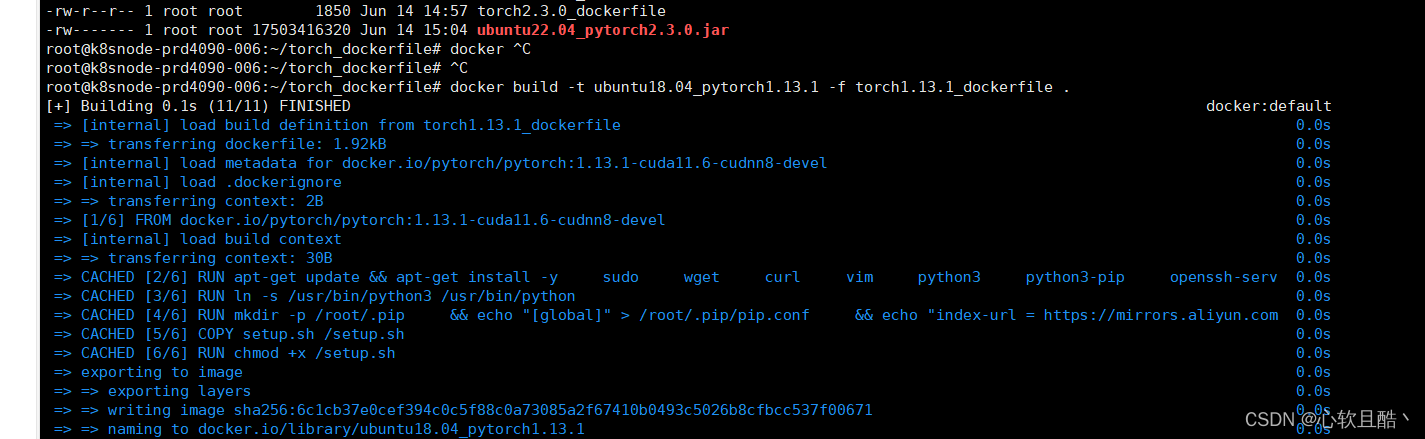
docker build -t ubuntu18.04_pytorch1.13.1 -f torch1.13.1_dockerfile .
构建成功,启动镜像测试
五:测试镜像
(1)运行镜像测试:
docker run -d -p 2255:22 5858:8888 ubuntu18.04_pytorch1.13.1
(2)查看镜像是否正常启动并找到docker id 进入容器内部测试:
docker ps | grep torch
(3)进入容器内部查看python,ubuntu,cuda和gpu的版本,显卡型号等等信息:
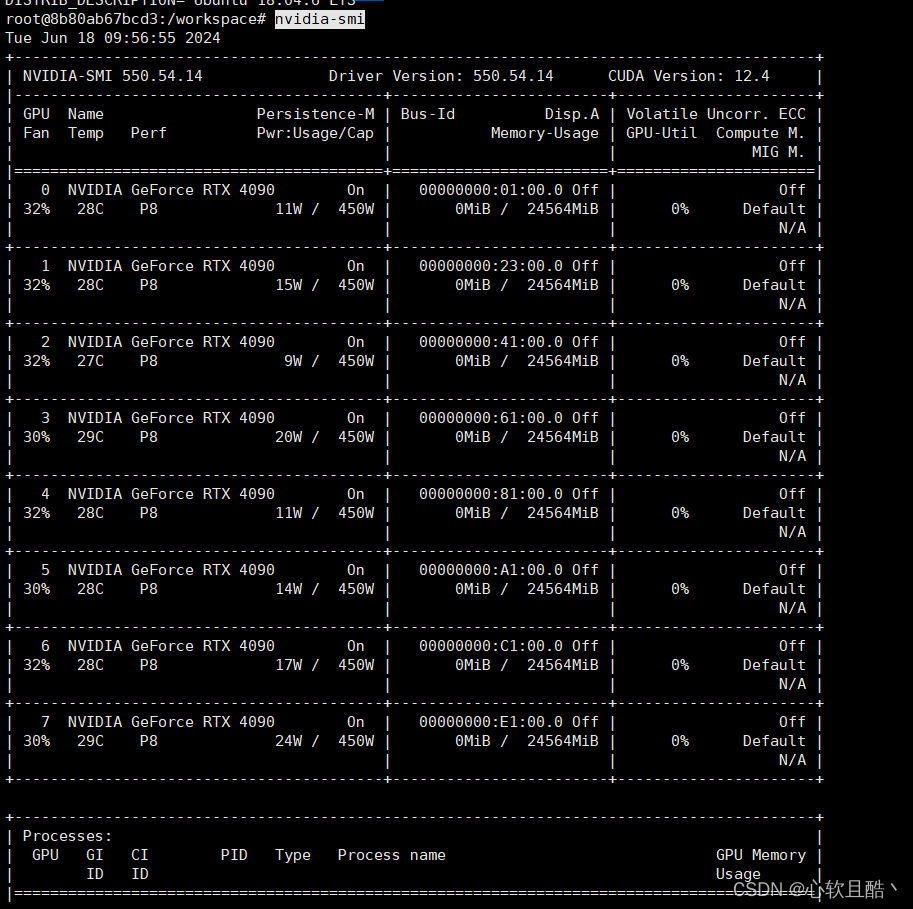
docker exec -it 8b80ab67bcd3 bashcat /etc/lsb-release
nvidia-smi ## 可以看到咱们容器内部可以读取到宿主机的显卡型号为4090,显卡驱动版本为550.54.14
python --version
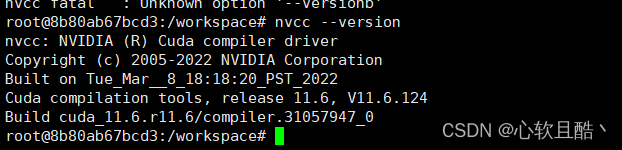
nvcc --version ## 验证cuda版本
(3)测试ssh和jupyterlab功能和服务是否正常:
浏览器访问宿主机ip+5885端口,并查看容器内部进程,jupyterlab是否正常安装启动
(4)使用python和pytorch测试pytorch是否正常,是否可以正常调用cuda和宿主机GPU:
测试脚本内容:
import torch def test_torch_cuda(): print("Checking PyTorch and CUDA installation...") # 检查 PyTorch 版本 print(f"PyTorch version: {torch.__version__}") # 检查是否可以调用 CUDA if torch.cuda.is_available(): print("CUDA is available.") else: print("CUDA is not available.") return # 检查 CUDA 版本 cuda_version = torch.version.cuda print(f"CUDA version: {cuda_version}") # 检查 GPU 的数量 gpu_count = torch.cuda.device_count() print(f"Number of GPUs: {gpu_count}") for i in range(gpu_count): print(f"GPU {i}: {torch.cuda.get_device_name(i)}") # 获取 GPU 的计算能力 capability = torch.cuda.get_device_capability(i) print(f" Compute capability: {capability[0]}.{capability[1]}") # 获取 GPU 显存信息 mem_info = torch.cuda.get_device_properties(i).total_memory / (1024 ** 3) # 单位GB print(f" Total memory: {mem_info:.2f} GB") if __name__ == "__main__": test_torch_cuda()
六:测试全部通过,镜像封装测试通过,推送私有docker-hub
(1)其他例如pytorch的其他版本,tensorflow等等,百度的paddlepaddle飞浆等大模型镜像的封装办法也一样,只需要修改基础镜像部分配置就可以:
剩下镜像里安装的工具包,环境变量按需配置。
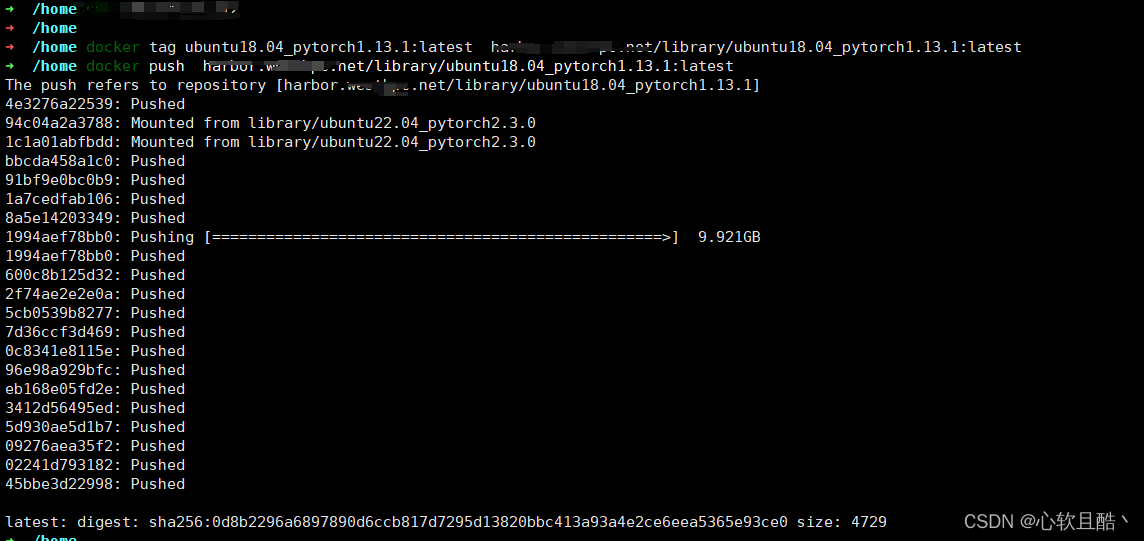
(2)推送私有镜像仓库备用
docker tag ubuntu18.04_pytorch1.13.1:latest harbor.prohub.net/library/ubuntu18.04_pytorch1.13.1:latest docker push harbor.prohub.net/library/ubuntu18.04_pytorch1.13.1:latest
Dockerfile封装制作pytorch(tensorflow)深度学习框架 + jupyterlab服务 + ssh服务镜像
news2026/3/12 15:37:41








本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1841288.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
Windows桌面运维----第四天
1、U盘故障打不开:
操作方式:WinR打开运行,输入cmd确定,在(C:\Users\Administrator>)后输入chkdsk,空格,输入U盘盘符,例如F:/F,回车,等待修复完成。
2、…
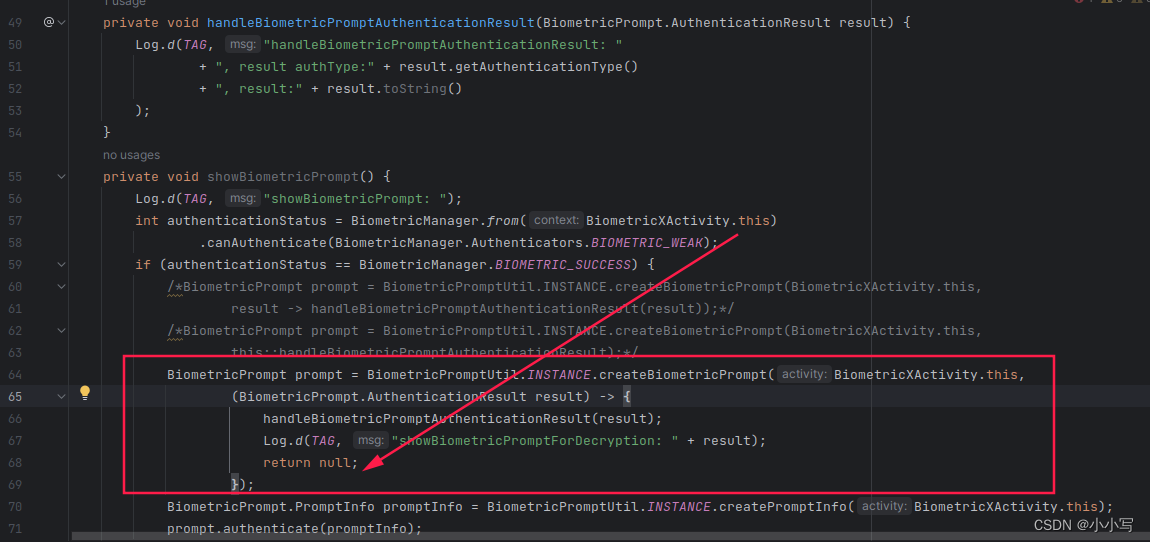
Bad return type in lambda expression: void cannot be converted to Unit
1.背景
当kotlin中声明需要传入一个返回值为空(Unit)的方法引用.
代码示例:
下方第二个参数为一个方法引用,(参数为BiometricPrompt.AuthenticationResult, 返回类型为Unit).
object BiometricPromptUtil {private const val TAG "BiometricPromptUtil"fun cre…

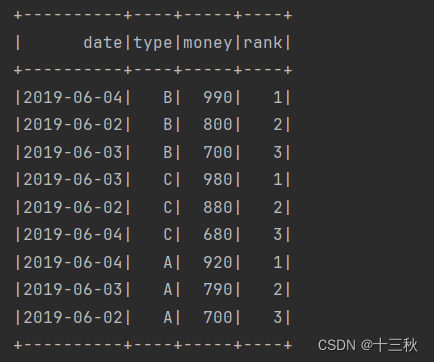
Day6—热点搜索词统计
一、要求
根据用户上网的搜索记录对每天的热点搜索词进行统计,以了解用户所关心的热点话题。 要求完成:统计每天搜索数量前3名的搜索词(同一天中同一用户多次搜索同一个搜索词视为1次)。
二、数据 三、配置scala环境
1.下载sca…

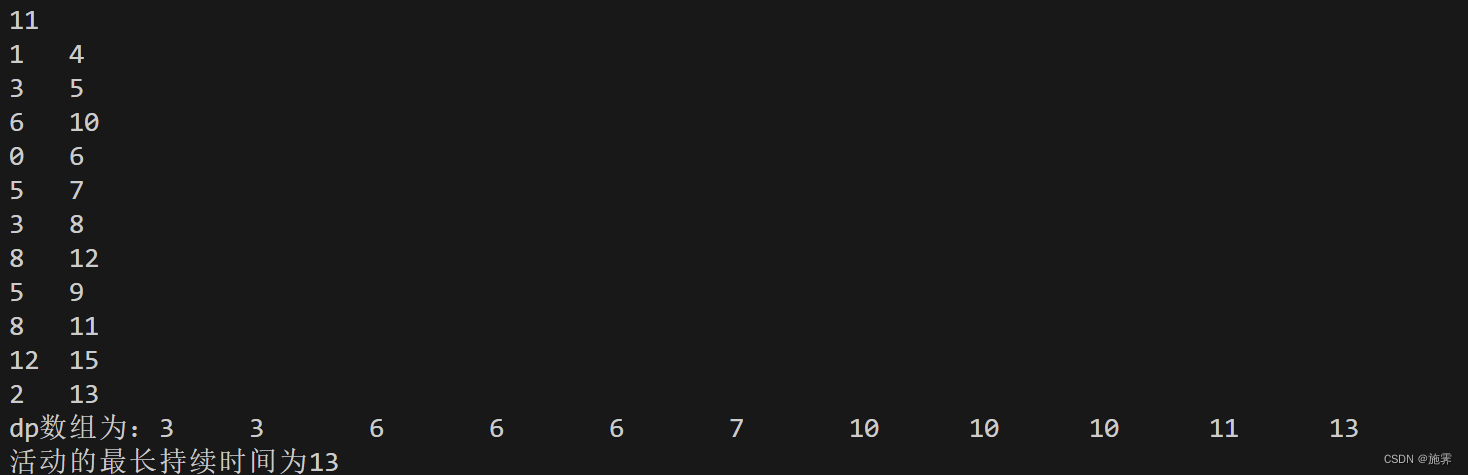
动态规划——活动安排问题II(C++)
Take it easy!
2024年6月19日 题目描述 假设有n个活动和一个资源,每个活动执行时都需要占用该资源,并且该资源在任何时间只能被一个活动所占用,一旦某个活动开始执行,中间将不能被打断,直到其执行完毕。每个活动i都有…
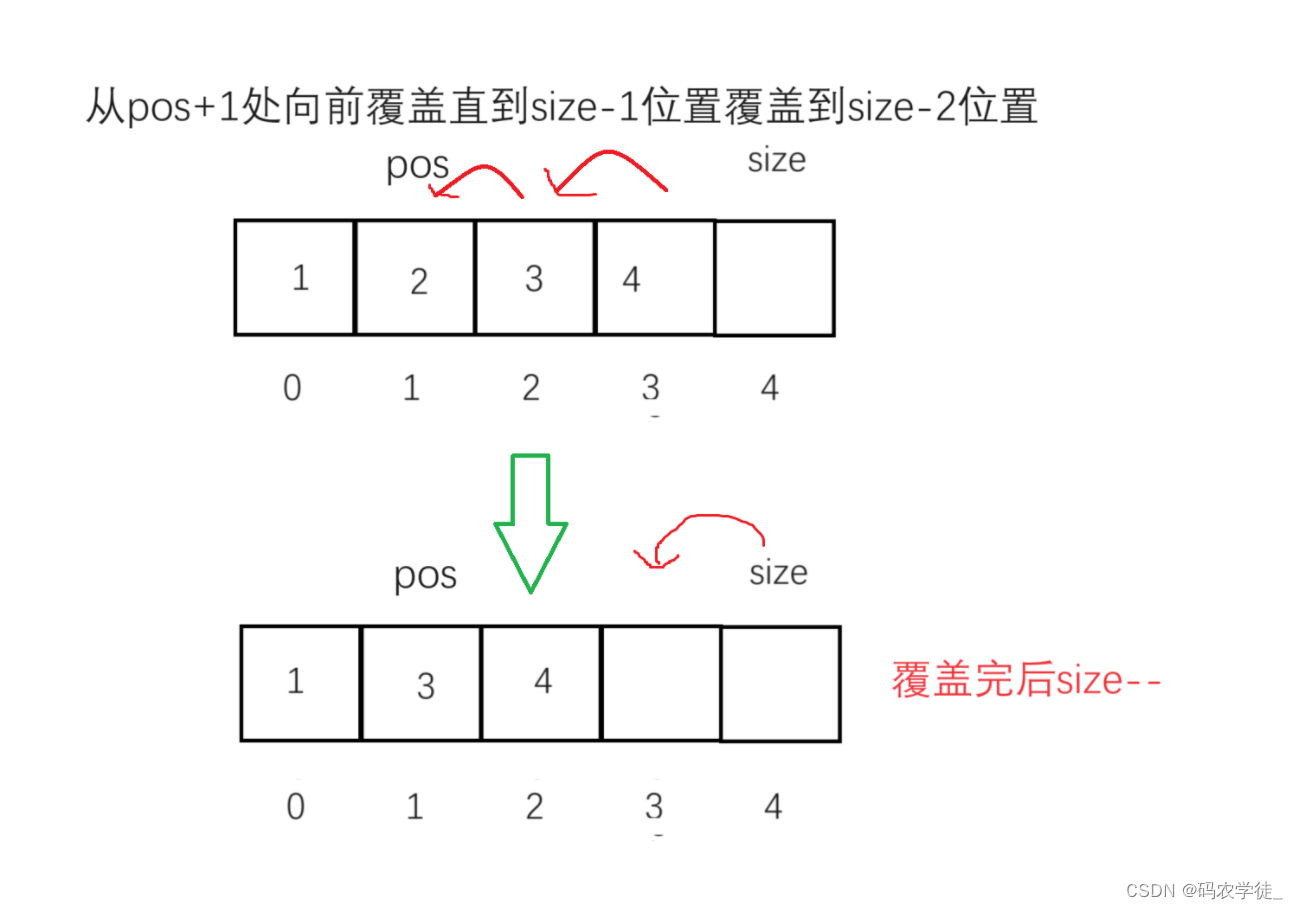
数据结构--顺序表(图文)
顺序表的概念和特点
顺序表是一种线性数据结构,它由一组数据元素构成,这些元素具有相同的特性,并按照一定的顺序排列。在顺序表中,数据元素通常存储在连续的内存空间中,这使得通过索引可以直接访问到表中的任意元素。…

考研计组chap2数据的表示和运算
3一、进位计数制 1.r进制
第i位表示r进制的权为i
2.进制转换
(1)r->10
对应位置数*权值
(2)2 -> 16 or 8
每三位2进制数可表示1位16进制
每四位2进制数可表示1位16进制
so 分开之后转为16进制即可
eg:1…

Day10—Spark SQL基础
Spark SQL介绍
Spark SQL是一个用于结构化数据处理的Spark组件。所谓结构化数据,是指具有Schema信息的数据,例如JSON、Parquet、Avro、CSV格式的数据。与基础的Spark RDD API不同,Spark SQL提供了对结构化数据的查询和计算接口。
Spark …

星戈瑞FITC-Cytochrome C:荧光标记细胞色素C的研究与应用
细胞色素C(Cytochrome C)是一种位于线粒体内膜上的蛋白质。为了深入地研究细胞色素C在细胞生物学和病理学中的功能,科学家们常常采用荧光标记技术对其进行追踪和观察。其中,异硫氰酸荧光素(FITC)作为一种常…
iOS原生APP开发的技术难点
iOS原生APP开发的技术难点主要体现在以下几个方面,总而言之,iOS原生APP开发是一项技术难度较高的工作,需要开发者具备扎实的编程基础、丰富的开发经验和良好的学习能力。北京木奇移动技术有限公司,专业的软件外包开发公司…
再谈量化策略失效的问题
数量技术宅团队在CSDN学院推出了量化投资系列课程
欢迎有兴趣系统学习量化投资的同学,点击下方链接报名:
量化投资速成营(入门课程)
Python股票量化投资
Python期货量化投资
Python数字货币量化投资
C语言CTP期货交易系统开…

数据结构之B树的理解与示例(C#)
文章目录 B树的基本概念与特点B树在C#数据结构中的应用创建一个B树节点的具体代码示例插入、删除和查找操作的示例B树在文件存储与处理中的具体应用示例总结 B树是一种自平衡的树数据结构,它维持数据的有序性,并且允许搜索、顺序访问、插入和删除的操作都…
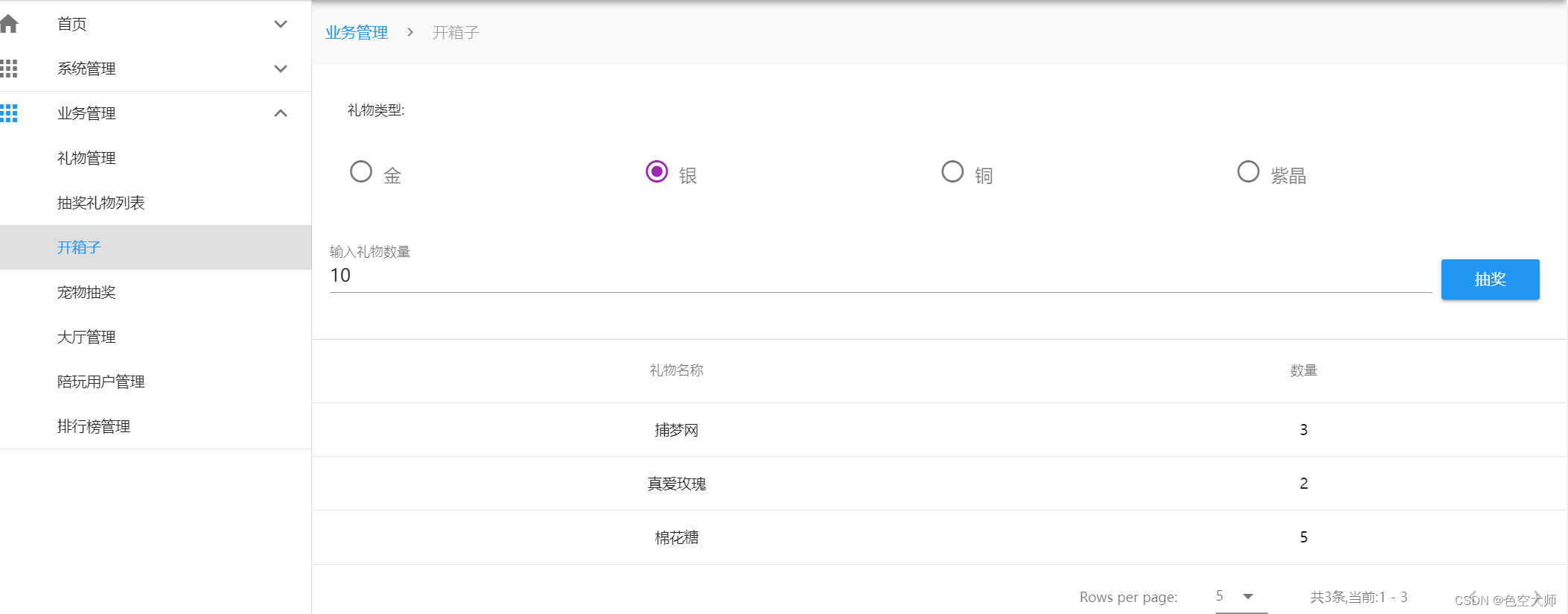
前后端完整案例-简单模仿点点开黑抽奖
数据库
后台
源码:https://gitee.com/qfp17393120407/game
前台
源码: https://gitee.com/qfp17393120407/game-weeb
vue项目打包
注意:打包时将IP改为自己公网IP
npm run build公网页面
地址:点点模拟抽奖
进入页面抽奖…
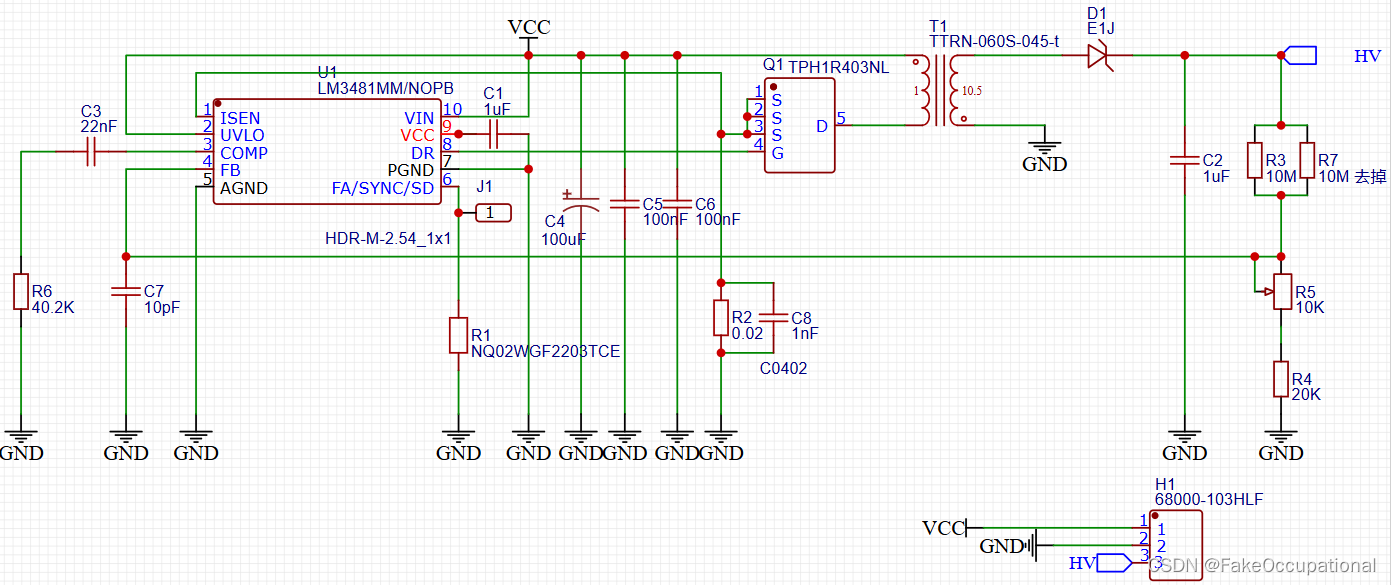
电路笔记 :LM3481MM/NOPB升压模块,升压电路原理
LM3481MM/NOPB
LM3481MM/NOPB 是德州仪器(Texas Instruments)的一款广泛应用的DC-DC控制器,常用于电源管理应用,特别是在需要升压(boost)、反激(flyback)、SEPIC或反向配置的场合。…
企业UDP文件传输工具测速的方式(下)
在前一篇文章中,我们深入讨论了UDP传输的基本概念和镭速UDP文件传输工具如何使用命令行快速进行速度测试。现在,让我们进一步探索更为高级和灵活的方法,即通过整合镭速UDP的动态或静态库来实现网络速度的测量,以及如何利用这一过程…
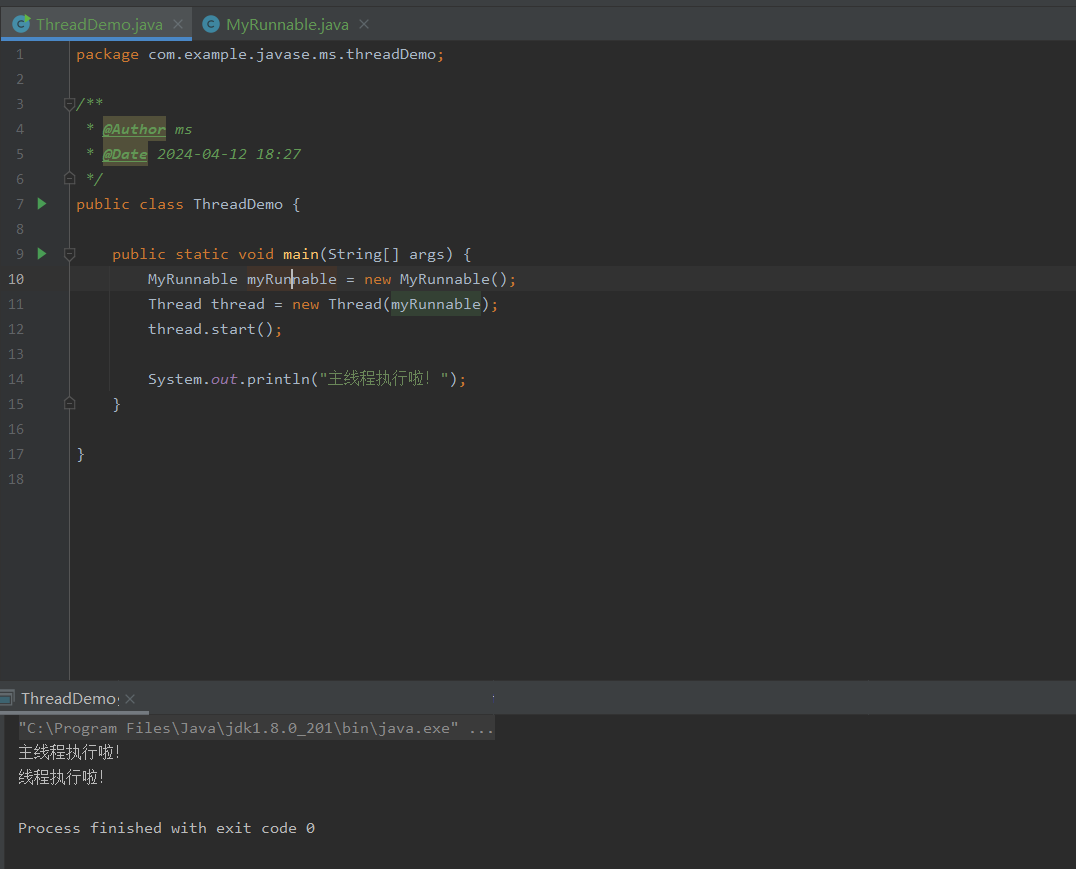
Java零基础之多线程篇:线程的多种创建方式
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云;欢迎大家常来逛逛 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一…

支持向量机 (SVM) 算法详解
支持向量机 (SVM) 算法详解
支持向量机(Support Vector Machine, SVM)是一种监督学习模型,广泛应用于分类和回归分析。SVM 特别适合高维数据,并且在处理复杂非线性数据时表现出色。本文将详细讲解 SVM 的原理、数学公式、应用场景…
![[Qt的学习日常]--窗口](https://img-blog.csdnimg.cn/direct/825be5f6888f4ef5b2bc85c8ee73a3c7.png)
[Qt的学习日常]--窗口
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、窗口的分…

最新!!单目深度估计方向文献综述--Monocular Depth Estimation: A Thorough Review
论文链接:https://ieeexplore.ieee.org/abstract/document/10313067
Abstract
一个是考虑人类深度感知的机制,另一个是包括各种深度学习方法。 这篇论文是关于单目深度估计(Monocular Depth Estimation)的全面综述,由…