支持向量机 (SVM) 算法详解
支持向量机(Support Vector Machine, SVM)是一种监督学习模型,广泛应用于分类和回归分析。SVM 特别适合高维数据,并且在处理复杂非线性数据时表现出色。本文将详细讲解 SVM 的原理、数学公式、应用场景及其在 Python 中的实现。
什么是支持向量机?
支持向量机的目标是找到一个最佳的决策边界(或称超平面)来最大限度地分隔不同类别的数据点。对于线性可分的数据,SVM 通过一个线性超平面进行分类;对于线性不可分的数据,SVM 可以通过核方法(Kernel Trick)将数据映射到高维空间,使其在高维空间中线性可分。
SVM 的基本原理
线性支持向量机
对于线性可分的数据,SVM 寻找一个超平面将数据集分隔成两个类别,同时最大化两个类别之间的边界(margin)。边界上的点称为支持向量(Support Vectors)。
数学公式
假设我们有一个训练数据集 ( x i , y i ) i = 1 n \ {(x_i, y_i)}_{i=1}^n (xi,yi)i=1n , 其中 x i ∈ R d \ x_i \in \mathbb{R}^d xi∈Rd 表示第 i \ i i个样本, y i ∈ { − 1 , 1 } \ y_i \in \{-1, 1\} yi∈{−1,1},表示第 (i) 个样本的类别标签。
超平面的方程可以表示为:
w
⋅
x
+
b
=
0
\ w \cdot x + b = 0 \
w⋅x+b=0
其中
w
\ w
w 是法向量,决定了超平面的方向,
b
\ b
b 是偏置项,决定了超平面的距离。
目标是找到
w
\ w
w 和
b
\ b
b,使得所有样本点满足:
y
i
(
w
⋅
x
i
+
b
)
≥
1
\ y_i (w \cdot x_i + b) \geq 1 \
yi(w⋅xi+b)≥1
同时,我们希望最大化边界,即最小化 (|w|),所以优化问题可以表示为:
min
w
,
b
1
2
∥
w
∥
2
\ \min_{w,b} \frac{1}{2} \|w\|^2 \
w,bmin21∥w∥2
约束条件为:
y
i
(
w
⋅
x
i
+
b
)
≥
1
,
∀
i
\ y_i (w \cdot x_i + b) \geq 1, \forall i
yi(w⋅xi+b)≥1,∀i
非线性支持向量机
对于线性不可分的数据,SVM 通过引入核函数(Kernel Function)将数据映射到高维空间,使其在高维空间中线性可分。常用的核函数包括:
- 多项式核(Polynomial Kernel)
- 径向基函数核(Radial Basis Function, RBF Kernel)
- 高斯核(Gaussian Kernel)
核函数的表示为 K ( x i , x j ) = ϕ ( x i ) ⋅ ϕ ( x j ) \ K(x_i, x_j) = \phi(x_i) \cdot \phi(x_j) K(xi,xj)=ϕ(xi)⋅ϕ(xj),其中 (\phi) 是将数据映射到高维空间的映射函数。
松弛变量
为了处理噪声和异常值,SVM 引入了松弛变量
ξ
i
\xi_i
ξi,使得优化问题变为:
min
w
,
b
,
ξ
1
2
∥
w
∥
2
+
C
∑
i
=
1
n
ξ
i
\ \min_{w,b,\xi} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^n \xi_i
w,b,ξmin21∥w∥2+Ci=1∑nξi
约束条件为:
y
i
(
w
⋅
x
i
+
b
)
≥
1
−
ξ
i
,
∀
i
ξ
i
≥
0
,
∀
i
\ y_i (w \cdot x_i + b) \geq 1 - \xi_i, \forall i \ \xi_i \geq 0, \forall i
yi(w⋅xi+b)≥1−ξi,∀i ξi≥0,∀i
其中 C \ C C 是惩罚参数,控制软间隔的宽度。
SVM 的优缺点
优点
- 有效处理高维数据:SVM 在高维空间中依然表现良好。
- 适合复杂非线性数据:通过核方法,SVM 能有效处理非线性数据。
- 鲁棒性强:SVM 对于部分噪声和异常值具有较强的鲁棒性。
缺点
- 计算复杂度高:尤其在大规模数据集上,训练时间较长。
- 参数选择敏感:核函数、惩罚参数 C \ C C 等需要仔细调优。
- 结果不可解释性:相比于决策树等模型,SVM 的结果较难解释。
SVM 的 Python 实现
下面通过 Python 代码实现 SVM 算法,并以一个示例数据集展示其应用。
导入库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
生成示例数据集
# 生成示例数据集
X, y = datasets.make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=42)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='bwr')
plt.title('原始数据集')
plt.show()

应用 SVM 算法
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 应用 SVM 算法
svm = SVC(kernel='linear', C=1.0)
svm.fit(X_train, y_train)
y_pred = svm.predict(X_test)
# 评估模型
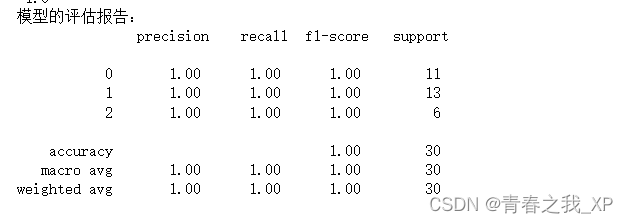
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
# 可视化决策边界
def plot_decision_boundary(X, y, model):
h = .02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap='bwr', alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='bwr')
plt.title('SVM 决策边界')
plt.show()
plot_decision_boundary(X_test, y_test, svm)

结果解释
在上面的示例中,我们生成了一个二分类的示例数据集,并使用 SVM 算法对其进行分类。最终,我们通过可视化展示了决策边界以及测试集上的分类结果。
总结
支持向量机是一种强大的监督学习算法,适用于处理复杂的高维和非线性数据。本文详细介绍了 SVM 的原理、数学公式、应用场景以及 Python 实现。虽然 SVM 在某些方面有其局限性,但通过合理选择参数和核函数,可以在许多实际应用中取得优异的效果。希望本文能帮助你更好地理解和应用支持向量机算法。
![[Qt的学习日常]--窗口](https://img-blog.csdnimg.cn/direct/825be5f6888f4ef5b2bc85c8ee73a3c7.png)