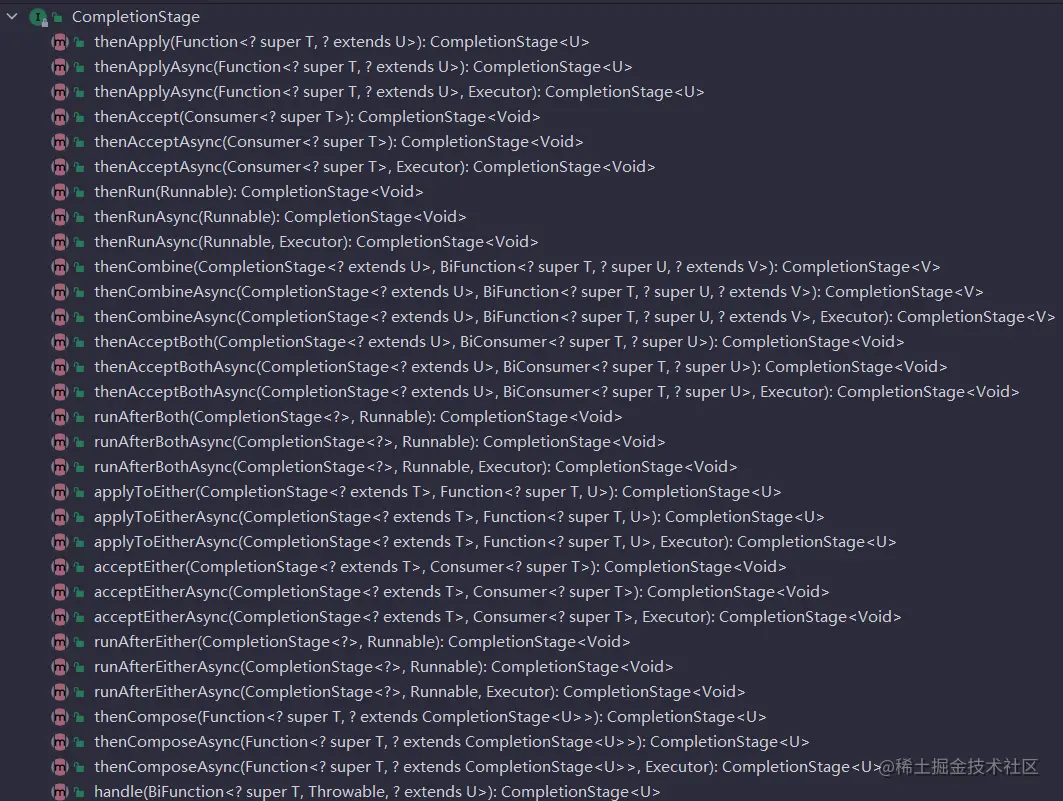
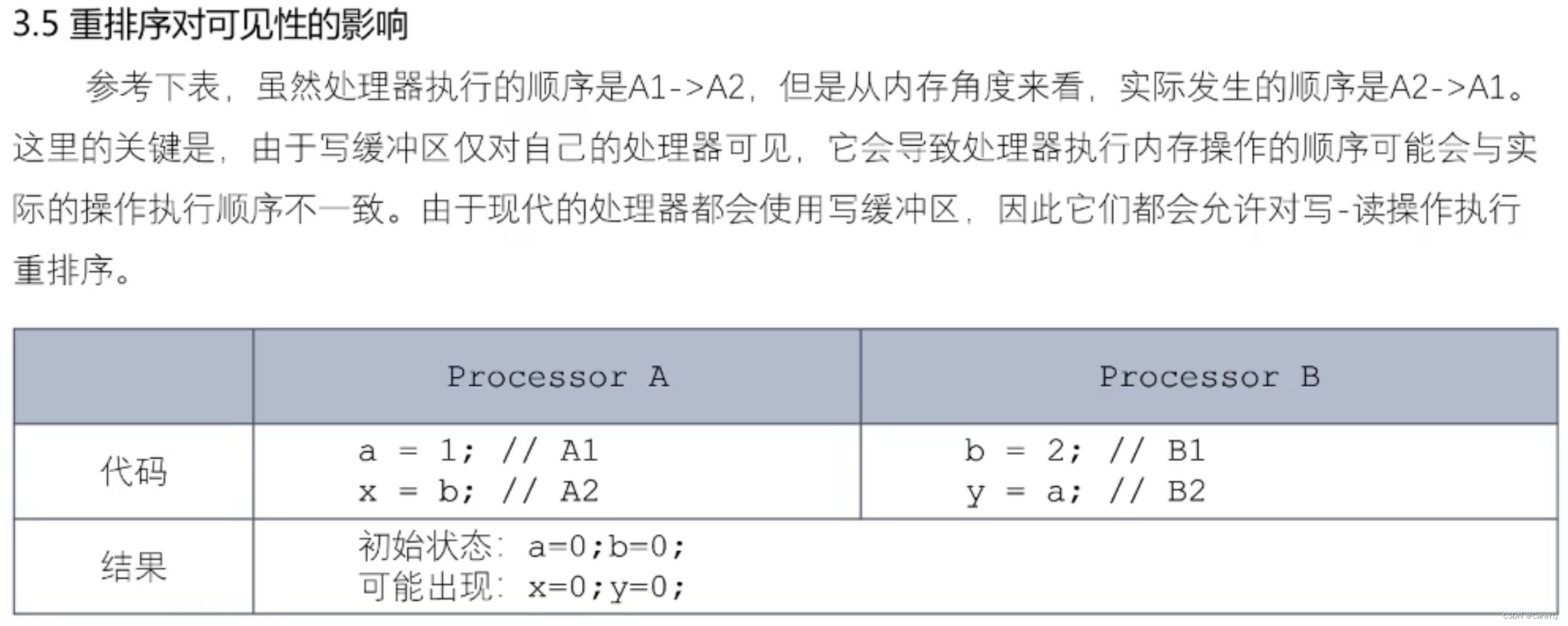
MySQL基础
1. 数据库概述
1.1 什么是数据库
数据库是持久化数据的一种介质,可以理解成用来存储和管理数据的仓库!
持久化(persistence):把数据保存到可掉电式存储设备中以供之后使用。持久化的大多数时候是将内存中的数据存储在数据库中,当然也可以存储在磁盘文件、XML数据文件中。
- 可将数据持久化到硬盘
- 可存储大量数据
- 方便检索
- 保证数据的一致性、完整性
- 安全,可共享
- 通过组合分析,可以产生新数据
表——类
列,字段——属性
行——对象
ORM对象关系映射
1.2 数据库相关概念
-
DB
数据库( database ):存储数据的“仓库”。它保存了一系列有组织的数据。
-
DBMS
数据库管理系统( Database Management System )。数据库是通过 DBMS 创建和操作的容器
-
SQL
结构化查询语言( Structure Query Language ):专门用来与数据库通信的语言。
2. MySQL数据库
2.1 简介
MySQL是一种开放源代码的关系型数据库管理系统,开发者为瑞典MySQL AB公司。在2008年1月16号被Sun公司收购。而2009年,SUN又被Oracle收购.目前 MySQL被广泛地应用在Internet上的中小型网站中。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库(Facebook, Twitter, YouTube)。阿里提出“去IOE”,更多网站也开始选择MySQL。
2.2 MySQL产品的优点
- 成本低:开放源代码,一般可以免费试用
- 性能高:执行很快
- 简单:很容易安装和使用
2.3 MySQL卸载
具体看百度,卸载后清除数据


如果前两步做了,再次安装还是失败,那么可以清理注册表
1:HKEY_LOCAL_MACHINE/SYSTEM\ControlSet001\Services\Eventlog\Application\MySQL服务 目录删除
2:HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\MySQL服务 目录删除
3:HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\Eventlog\Application\MySQL服务 目录删除
4:HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\MySQL服务 目录删除
5:HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Eventlog\Application\MySQL服务目录删除
6:HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\MySQL服务删除
注册表中的ControlSet001,ControlSet002,不一定是001和002,可能是ControlSet005、006之类
2.4 MySQL安装
win安装地址:https://www.cnblogs.com/runningStudy/p/6444047.html
win最好安装5.7.25,或者docker安装8.0以上版本,具体看docker笔记
win+R,services.msc,查看mysql服务,启动/计算机右击管理,可设置开机自启
cmd–>>net stop mysql 停止MySQL服务,管理员身份进入
cmd–>>mysql -uroot -p >> mysql -h localhost -P 3306 -u root -proot 启动服务
3. MySQL基本命令
启动和关闭mysql服务,得先进入到mysql安装目录的bin目录
- 启动:net start mysql;
- 关闭:net stop mysql;
登录:mysql -uroot -p123456 -h localhost;
-u:后面的root是用户名,这里使用的是超级管理员root;
-p:后面的root是密码,这是在安装MySQL时就已经指定的密码,这里不能去空格
-h:后面给出的localhost是服务器主机名,它是可以省略的,例如:mysql -u root -p root;
-P:指定端口,3306
退出:quit或exit;
在登录成功后,打开windows任务管理器,会有一个名为mysql.exe的进程运行,所以mysql.exe是客户端程序。
查看数据库:show databases;
进入数据库/表:use 库名/表名;
查看表:show tables;
查看某库的表:show tables from 库名;
查看当前数据库:select database(); version(); user();
创建表:create table stuinfo(
stuid int,
stuname varchar(20),
sex char,
…
);
查看表的结构:desc stuinfo; // show COLUMNS from 表
插入数据:insert into stuinfo values(1,‘吴’,‘男’,…);
修改字段为中文的字符集gbk:set names gbk;
select
update 表 set
delete from
修改表的结构:alter table stuinfo add column email varchar(20);
删除表:drop table stuinfo;
注释:-- 注释; #注释; /*多行注释*/
4. SQL语句
非数值需要单引号
通用数据库语言,语法一致。
SQL(Structured Query Language)是“结构化查询语言”,它是对关系型数据库的操作语言。它可以应用到所有关系型数据库中,例如:MySQL、Oracle、SQL Server等。
虽然SQL可以用在所有关系型数据库中,但很多数据库还都有标准之后的一些语法,我们可以称之为“方言”。例如MySQL中的LIMIT语句就是MySQL独有的方言,其它数据库都不支持!当然,Oracle或SQL Server都有自己的方言。
4.1 SQL语法要求
SQL语句可以单行或多行书写,以分号结尾;
可以用空格和缩进来来增强语句的可读性;
关键字不区别大小写,建议使用大写;
4.2 分类
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;create/drop/alter
- **DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据);**争对修改数据,insert/update/delete
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
- **DQL(Data Query Language):数据查询语言,用来查询记录(数据)。**select
4.3 DQL
DQL就是数据查询语言,数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。
语法:
SELECT
selection_list /*要查询的列名称*/
FROM
table_list /*要查询的表名称*/
WHERE
condition /*行条件*/
GROUP BY
grouping_columns /*对结果分组*/
HAVING
condition /*分组后的行条件*/
ORDER BY
sorting_columns /*对结果分组*/
LIMIT
offset_start, row_count /*结果限定*/
decimal(最大精度,但是数据范围小),float,double
基础查询
select * from 表;
select 字段名… from 表;
先执行from 表;后select *
单引号指可能字段名和表名跟关键字重复,标引号区分,指是字段名/表名。‘字段名/表名’
起别名:select 名 AS 别名
“别 名” ’别 名‘都可以,可加空格
方式一:
select 列名 as 别名 from 表名;
方式二:
select 列名 别名 from 表名;
//拼接词变成一个字段
select concat(name1,name2) AS “姓 名”
select concat(name1,’,‘,name2)
select IFNULL(name1,‘空’) //为空就是赋值’空’,否则原值
select concat(IFNULL(name1,‘空’),’,‘,name2)
//concat不能出现null,否则结果为null
distinct去重
select distinct
条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
<>不等于
- =、!=、<>、<、<=、>、>=
- AND、OR、NOT(条件)
- BETWEEN…AND、IN(set)、IS NULL、LIKE
from1
where2
select3
模糊查询
- like/not like
模糊匹配
通配符:_任意单个字符、%任意多个字符
只支持字符串
WHERE name like ‘%a%’;
查询第二个字符为_的数据,转义字符\表示字符\_
WHERE name like '_\_%';
WHERE name like '_$_%' ESCAPE '$'; 指设置$为转义字符
- in/not in
查询某字段的值是否属于指定的列表之内
a in (值1,值2,值3) 是否等于某个
- between and/not between and
判断某个字段的值是否介于xx之间
a BETWEEN 30 and 60
小的前,大的后
>=左区间 and <=右区间
- is null/is not null
查询空,非空
=null 这是错误的
=只能判断普通值
<=>安全等于,既能判断普通内容,又能判断NULL值
排序查询
order by 排序字段列表
排序字段列表可以是单个或多个字段、表达式、函数、列数、或以上组合
from1
where2
select3
order by4
order by xx ASC升序/不加 ,DESC降序
按别名年薪降序:
SELECT *,salart*12*(1+IFNULL(pct,0)) 年薪 FROM employees WHERE pct IS NOT NULL ORDER BY 年薪 DESC
按多字段排序:
ORDER BY salary ASC,id DESC;
结果是先按salary 升序,相同salary 按id 降序
按列数排序:
SELECT * FROM employees ORDER BY 2
第2列
常见函数
MySQL数据库提供了很多函数包括:
- 数学函数;
- 字符串函数;
- 日期和时间函数;
- 条件判断函数;流程控制函数;
- 系统信息函数;
- 加密函数;
- 格式化函数;
数学函数
| ABS(x) | 返回x的绝对值 |
|---|---|
| CEIL(x) | 返回大于等于x的最小整数值,向上取整 |
| FLOOR(x) | 返回小于等于x的最大整数值,向下去找 |
| MOD(x,y) | 返回x/y的模,取余 |
| RAND(x) | 返回0~1的随机值 |
| ROUND(x,y) | 返回参数x的四舍五入的有y位的小数的值 |
| TRUNCATE(x,y) | 返回数字x截断为y位小数的结果 |
| SQRT(x) | 返回x的平方根 |
| POW(x,y) | 返回x的y次方 |
字符串函数
utf-8中文一个3个字节
| CONCAT(S1,S2,…,Sn) | 连接S1,S2,…,Sn为一个字符串 |
|---|---|
| CONCAT(s, S1,S2,…,Sn) | 同CONCAT(s1,s2,…)函数,但是每个字符串之间要加上s |
| CHAR_LENGTH(s) | 返回字符串s的字符数 |
| LENGTH(s) | 返回字符串s的字节数,和字符集有关 |
| INSERT(str, index , len, instr) | 将字符串str从第index位置开始,len个字符长的子串替换为字符串instr |
| UPPER(s) 或 UCASE(s) | 将字符串s的所有字母转成大写字母 |
| LOWER(s) 或LCASE(s) | 将字符串s的所有字母转成小写字母 |
| LEFT(s,n) | 返回字符串s最左边的n个字符 |
| RIGHT(s,n) | 返回字符串s最右边的n个字符 |
| LPAD(str, len, pad) | 用字符串pad对str最左边进行填充,直到str的长度为len个字符 |
| RPAD(str ,len, pad) | 用字符串pad对str最右边进行填充,直到str的长度为len个字符 |
| LTRIM(s) | 去掉字符串s左侧的空格 |
| RTRIM(s) | 去掉字符串s右侧的空格 |
| TRIM(s) | 去掉字符串s开始与结尾的空格 |
| TRIM(【BOTH 】s1 FROM s) | 去掉字符串s开始与结尾的s1 |
| TRIM(【LEADING】s1 FROM s) | 去掉字符串s开始处的s1 |
| TRIM(【TRAILING】s1 FROM s) | 去掉字符串s结尾处的s1 |
| REPEAT(str, n) | 返回str重复n次的结果 |
| REPLACE(str, a, b) | 用字符串b替换字符串str中所有出现的字符串a |
| STRCMP(s1,s2) | 比较字符串s1,s2,-1,0,1 |
| SUBSTR(s,index,len) | 返回从字符串s的index位置其len个字符,索引1开始,len不写截取后全部 |
| INSTR | 获取字符串第一次出现的索引 |
开始日期时间函数
select date_format(now(),‘%Y年%m月%d日’)
| CURDATE() 或 CURRENT_DATE() | 返回当前日期 |
|---|---|
| CURTIME() 或 CURRENT_TIME() | 返回当前时间 |
| NOW() SYSDATE()CURRENT_TIMESTAMP()LOCALTIME()LOCALTIMESTAMP() | 返回当前系统日期时间 |
| YEAR(date)MONTH(date)DAY(date)HOUR(time)MINUTE(time)SECOND(time) | 返回具体的时间值 |
| WEEK(date)WEEKOFYEAR(date) | 返回一年中的第几周 |
| DAYOFWEEK() | 返回周几,注意:周日是1,周一是2,。。。周六是7 |
| WEEKDAY(date) | 返回周几,注意,周1是0,周2是1,。。。周日是6 |
| DAYNAME(date) | 返回星期:MONDAY,TUESDAY…SUNDAY |
| MONTHNAME(date) | 返回月份:January,。。。。。 |
| DATEDIFF(date1,date2)TIMEDIFF(time1, time2) | 返回date1 - date2的日期间隔返回time1 - time2的时间间隔 |
| DATE_ADD(datetime, INTERVALE expr type) | 返回与给定日期时间相差INTERVAL时间段的日期时间 |
| DATE_FORMAT(datetime ,fmt) | 按照字符串fmt格式化日期datetime值 |
| STR_TO_DATE(str, fmt) | 按照字符串fmt对str进行解析,解析为一个日期,(‘3/15 1998’, ‘%m/%d %Y’) |
DATE_ADD(datetime,INTERVAL expr type)
| SELECT DATE_ADD(NOW(), INTERVAL 1 YEAR);SELECT DATE_ADD(NOW(), INTERVAL -1 YEAR); #可以是负数SELECT DATE_ADD(NOW(), INTERVAL ‘1_1’ YEAR_MONTH); #需要单引号 | |
|---|---|
| 表达式类型 | YEAR_MONTH |
| YEAR | DAY_HOUR |
| MONTH | DAY_MINUTE |
| DAY | DAY_SECOND |
| HOUR | HOUR_MINUTE |
| MINUTE | HOUR_SECOND |
| SECOND | MINUTE_SECOND |
DATE_FORMAT(datetime ,fmt)和STR_TO_DATE(str, fmt)
日期格式例子:%Y-%M-%d %H:%i:%s
| 格式符 | 说明 | 格式符 | 说明 |
|---|---|---|---|
| %Y | 4位数字表示年份 | %y | 表示两位数字表示年份 |
| %M | 月名表示月份(January,…) | %m | 两位数字表示月份(01,02,03。。。) |
| %b | 缩写的月名(Jan.,Feb.,…) | %c | 数字表示月份(1,2,3,…) |
| %D | 英文后缀表示月中的天数(1st,2nd,3rd,…) | %d | 两位数字表示月中的天数(01,02…) |
| %e | 数字形式表示月中的天数(1,2,3,4,5…) | ||
| %H | 两位数字表示小数,24小时制(01,02…) | %h和%I | 两位数字表示小时,12小时制(01,02…) |
| %k | 数字形式的小时,24小时制(1,2,3) | %l | 数字形式表示小时,12小时制(1,2,3,4…) |
| %i | 两位数字表示分钟(00,01,02) | %S和%s | 两位数字表示秒(00,01,02…) |
| %W | 一周中的星期名称(Sunday…) | %a | 一周中的星期缩写(Sun.,Mon.,Tues.,…) |
| %w | 以数字表示周中的天数(0=Sunday,1=Monday…) | ||
| %j | 以3位数字表示年中的天数(001,002…) | %U | 以数字表示年中的第几周,(1,2,3。。)其中Sunday为周中第一天 |
| %u | 以数字表示年中的第几周,(1,2,3。。)其中Monday为周中第一天 | ||
| %T | 24小时制 | %r | 12小时制 |
| %p | AM或PM | %% | 表示% |
流程函数
| IF(value,t ,f) | 如果value是真,返回t,否则返回f |
|---|---|
| IFNULL(value1, value2) | 如果value1不为空,返回value1,否则返回value2 |
| CASE WHEN 条件1 THEN result1 WHEN 条件2 THEN result2…[ELSE resultn]END | 相当于Java的if…else if… |
| CASE expr WHEN 常量值1 THEN 值1WHEN 常量值1 THEN 值1…[ELSE 值n]END | 相当于Java的switch |
| SELECT ename ,CASE WHEN salary>=15000 THEN '高薪’WHEN salary>=10000 THEN '潜力股’WHEN salary>=8000 THEN '屌丝’ELSE '草根’ENDFROM t_employee; | |
SELECT oid,status, CASE statusWHEN 1 THEN '未付款’WHEN 2 THEN '已付款’WHEN 3 THEN '已发货’WHEN 4 THEN '确认收货’ELSE '无效订单’ENDFROM t_order; |
分组(聚合)函数
用于实现一列数据进行统计计算,最终得到一个值,又称聚合函数、统计函数
- sum(字段名):求和,如果指定列类型不是数值类型,那么计算结果为0;
- avg(字段名):求平均数,如果指定列类型不是数值类型,那么计算结果为0;
- max(字段名):求最大值,如果指定列是字符串类型,那么使用字符串排序运算;
- min(字段名):求最小值,如果指定列是字符串类型,那么使用字符串排序运算;
- count(字段名):计算非空字段值的个数
count(*) 查询行数,表多少条数据
count(1) 跟count(*)一样的效果,多一列查看总数
select count(distinct 去重列名) 统计去重
分组查询
当需要分组查询时需要使用GROUP BY子句,例如查询每个部门的工资和,这说明要使用部分来分组。
把部分行数据分成一组
select sum(salary)
from employees
group by department_id
select count(*) 员工个数,department_id
from employees
where xxx
group by department_id
having count(*)>5
--按多个字段分组
--多个字段组合一样的为一组
/*
工种 部门 工资
1 1 1000
1 2 2000
1 3 3000
2 1 5000
1 1 4000
1 2 6000
工种、部门组合分组则为2个字段的组合一样的为一组,以上有11、12、13、21
*/
group by 分组后再判断用having,where 只能前面
where筛选原始表,比group by先执行
having筛选分组后的结果集,比group by慢执行
条件优先放在where,这样having少执行,节省时间
from1
where2
group by3
having4
select5
order by6
连接查询
多表查询,最好结合distinct去重一起使用。
//推荐,速度最快,1次全盘扫描
select * from table1
left join table2 on 条件1
left join table3 on 条件2
left join table4 on 条件3
where 条件4
//推荐,2次全盘
select * from aaa a left join
(select * from bbb b left join
ccc c on bc条件
)x on ax条件
笛卡尔积,则是多个表行数相乘,不加有效的连接条件的话
比如结果集:表1、5数据*表2、10数据=50条组合数据
笛卡尔集会在下面条件下产生:
– 省略连接条件
– 连接条件无效
– 所有表中的所有行互相连接
为了避免笛卡尔集, 可以在 WHERE加入有效的连接条件
那么多表查询产生这样的结果并不是我们想要的,那么怎么去除重复的,不想要的记录呢,当然是通过条件过滤。通常要查询的多个表之间都存在关联关系,那么就通过关联关系去除笛卡尔积。
等值连接
表有别名就不能用表名.
--别名,指定字段必须带别名.(有别名的话必须是别名,As或空格)或者表名.
SELECT e.*/e.name...
FROM emp e,dept d
WHERE e.deptno=d.deptno;
--案例:查询哪个部门的员工个数>5,并按员工个数进行降序
SELECT department_name,COUNT(*)
FROM employees e,departments d
WHERE e.department_id = d.department_id
GROUP BY e.department_id
HAVING COUNT(*)>5
ORDER BY COUNT(*) DESC;
--结果是分组后的count,每个组的count值
非等值连接
连接条件不含=
自连接
大家也都知道,连接查询会产生无用笛卡尔积,我们通常使用主外键关系等式来去除它。而自然连接无需你去给出主外键等式,它会自动找到这一等式:
两张连接的表中名称和类型完成一致的列作为条件,例如emp和dept表都存在deptno列,并且类型一致,所以会被自然连接找到!
当然自然连接还有其他的查找条件的方式,但其他方式都可能存在问题!
SELECT * FROM emp NATURAL JOIN dept; natural
SELECT * FROM emp NATURAL LEFT JOIN dept;
SELECT * FROM emp NATURAL RIGHT JOIN dept;
内连接
sql92 与 sql99标准
表1 join 表2 on 连接条件 join 表3 on 连接条件 where 筛选条件 group by having order by
标准的内连接为:
SELECT * FROM emp e INNER JOIN dept d ON e.deptno=d.deptno;
注意:inner可以省略、on是连接条件
内连接的特点:查询结果必须满足条件。
**sql99标准将连接条件和筛选条件进行分离。**sql92标准则是employees e,departments d这种按逗号分开,条件and一起。
SELECT d.*,dep_ag.ag
FROM departments d
JOIN(
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
ORDER BY ag
LIMIT 1
)dep_ag ON d.department_id = dep_ag.department_id;
外连接
左连接:
SELECT * FROM emp e LEFT OUTER JOIN dept d ON e.deptno=d.deptno;
注意:OUTER可以省略
左连接是先查询出左表(即以左表为主),然后查询右表,右表中满足条件的显示出来,不满足条件的显示NULL。
右连接
右连接就是先把右表中所有记录都查询出来,然后左表满足条件的显示,不满足显示NULL。例如在dept表中的40部门并不存在员工,但在右连接中,如果dept表为右表,那么还是会查出40部门,但相应的员工信息为NULL。
SELECT * FROM emp e RIGHT OUTER JOIN dept d ON e.deptno=d.deptno;
FULL JOIN 全部


子查询
出现在其他语句的内部的select语句,称为子查询或内查询
里面嵌套其他select语句的查询语句,称为主查询或外查询
子查询不一定必须出现在select语句内部,只是出现在select语句内部的时候较多!
select first_name from employees where department_id >(
select department_id from departments
where location_id=1700
)
单行子查询
特点:子查询的结果集只有一行一列
多行子查询
特点:子查询的结果集有多行一列
- select后面:子查询的结果为单行单列,标量子查询
- from后面:子查询的结果为多行多列
- where或having后面:子查询的结果必须为单列,单行子查询,多行子查询
- exists后面:子查询的结果必须为单列,相关子查询
exists(子查询)存在就返回1,不存在就返回0
说明:
1、子查询语句需要放在小括号内,提高代码的阅读性
2、子查询先于主查询执行,一般来讲,主查询会用到子查询的结果
3、如果子查询放在条件中,一般来讲,子查询需要放在条件的右侧
示例:where job_id>(子查询)
不能写成:where (子查询)<job_id
4、单行子查询对应的使用单行操作符:> < >= <= = <>
多行子查询对应的使用多行操作符:in 、any/some 、all 、not in
in 判断某字段是否在指定的列表中
any/some 判断某字段的值是否满足其中任意一个
all 判断某字段的值是否满足里面所有
LIMIT用来限定查询结果的起始行,以及总行数。
多行子查询指子查询的结果集是多行的,不能用> < >= <= = <>,只能
id in/any… (
子查询
)
表1join(
子查询
) 表2 on
分页查询
语法:
select 查询列表
from 表
【where 条件】
limit 【起始条目索引,】查询的条目数;
limit 不写默认从0开始
分页模板:
select 查询列表
from 表
【where 条件】
limit (page-1)*size,size;
联合查询
union
当查询结果来自于多张表,但多张表之间没有关联,这个时候往往使用联合查询,不过表中的属性类型和名字要一致,自动去重,union all则不会自动去重。
select 查询列表 from 表1 where 筛选条件
union
select 查询列表 from 表2 where 筛选条件
语句执行顺序

4.4 DDL
4.4.1 基本操作
查看所有数据库名称:SHOW DATABASES;
切换数据库:USE mydb1,切换到mydb1数据库;
4.4.2 操作数据库
创建数据库:CREATE DATABASE [IF NOT EXISTS] mydb1;
创建数据库,例如:CREATE DATABASE mydb1,创建一个名为mydb1的数据库。如果这个数据已经存在,那么会报错。例如CREATE DATABASE IF NOT EXISTS mydb1,在名为mydb1的数据库不存在时创建该库,这样可以避免报错。
删除数据库:DROP DATABASE [IF EXISTS] mydb1;
删除数据库,例如:DROP DATABASE mydb1,删除名为mydb1的数据库。如果这个数据库不存在,那么会报错。DROP DATABASE IF EXISTS mydb1,就算mydb1不存在,也不会的报错。
4.4.3 数据类型
MySQL与Java一样,也有数据类型。MySQL中数据类型主要应用在列上。
常用类型:
tinyint、samllint、int、bigint:整型
double/float:浮点型,例如double(5,2)表示最多5位,其中必须有2位小数,即最大值为999.99;
decimal:浮点型,在表示钱方面使用该类型,因为不会出现精度缺失问题;
char:固定长度字符串类型;char(4) 范围是0-255 1个字节,n多大就多大内存
varchar:可变长度字符串类型; 内存扩展
text:字符串类型;表示存储较长文本
| 意思 | 格式 | n的解释 | 特点 | 效率 | |
|---|---|---|---|---|---|
| Char | 固定长度字符 | Char(n) | 最大的字符个数,可选默认:1 | 不管实际存储,开辟的空间都是n个字符 | 高 |
| Varchar | 可变长度字符 | Varchar(n) | 最大的字符个数,必选 | 根据实际存储决定开辟的空间 | 低 |
blob:字节类型,可存图片;//jpg mp3 avi
date:日期类型,格式为:yyyy-MM-dd;
time:时间类型,格式为:hh:mm:ss
timestamp/datetime:时间戳类型;日期+时间 yyyyMMdd hhmmss
| 保存范围 | 所占字节 | |
|---|---|---|
| Datetime | 1900-1-1~xxxx年 | 8 |
| Timestamp | 1970-1-1~2038-12-31 | 4 |
详见 《MySQL之数据类型.doc》
4.4.4 字段约束
用于限制表中字段的数据,从而进一步保证数据的一致性、准确性。
-
NOT NULL 非空
-
DEFAULT 默认值
-
PRIMARY KEY 主键,不能重复,不能为空
-
UNIQUE 值唯一,可以为空
-
CHECK 检查,用于限制该字段的值必须满足指定条件
mysql不支持,但是语法不报错
-
FOREIGN KEY 外键,主表必须是主键,主从表名字不要求
constraint 外键名 foreign key (从表属性名) peferences 主表 (主键名)
4.4.5 操作表
创建表:
CREATE TABLE [IF NOT EXISTS] 表名(
字段名 字段类型 【字段约束】,
字段名 字段类型 【字段约束】,
…
);
查看当前数据库中所有表名称:SHOW TABLES;
查看指定表的创建语句:SHOW CREATE TABLE emps;
查看表结构:DESC emps;
删除表:DROP TABLE IF EXISTS emps
复制表:CREATE TABLE 新表名 LIKE 旧表名
复制跟数据:CREATE TABLE 新表名 SELECT * FROM 旧表名
修改表结构:
a) 修改之添加列:给stus表添加classname列:
ALTER TABLE stu ADD (classname varchar(100));
b) 修改之修改列类型:修改stu表的gender列类型为CHAR(2):
ALTER TABLE stus MODIFY COLUMN gender CHAR(2);
c) 修改之修改列名:修改stu表的gender列名为sex:
修改的属性类型必须加上
ALTER TABLE stus CHANGE COLUMN gender sex CHAR(2);
d) 修改之删除列:删除stsu表的classname列:
ALTER TABLE stus DROP COLUMN classname;
e) 修改之修改表名称:修改stu表名称为student:
ALTER TABLE stus RENAME TO student;
4.5 DML
insert update delete
4.5.1 插入数据
语法:
INSERT INTO 表名(列名1,列名2, …) VALUES(值1, 值2)
插入多行:
INSERT INTO 表名(列名1,列名2, …) VALUES(值1, 值2), VALUES(值1, 值2), VALUES(值1, 值2)…
INSERT INTO stus(sid, sname,age,gender) VALUES(s_1001', 'zhangSan', 23, 'male');
INSERT INTO stus(sid, sname) VALUES('s_1001', 'zhangSan');
语法:
INSERT INTO 表名 VALUES(值1,值2,…)
因为没有指定要插入的列,表示按创建表时列的顺序插入所有列的值:
注意:所有字符串数据必须使用单引号,数值类型不用。
4.5.2 修改数据
单表修改语法:
可空字段默认为空
UPDATE 表名 SET 列名1=值1, … 列名n=值n [WHERE 条件]
UPDATE stus SET sname=’zhangSanSan’, age=’32’, gender=’female’ WHERE sid=’s_1001’;
UPDATE stus SET sname=’zhangSanSan’, age=’32’, gender=’female’ WHERE sid=’s_1001’;
UPDATE stus SET sname=’wangWu’, age=’30’ WHERE age>60 OR gender=’female’;
UPDATE stus SET gender=’female’ WHERE gender IS NULL
UPDATE stus SET age=age+1 WHERE sname=’zhaoLiu’;
多表修改语法:
UPDATE 表1 【inner】 john 表2 on 表 SET 列名1= 新值1,列名2 =新值2
【where 筛选条件】
4.5.3 删除数据
单表删除语法:
①DELETE FROM 表名 [WHERE 条件]
DELETE FROM stus WHERE sid=’s_1001’003B
DELETE FROM stus WHERE sname=’chenQi’ OR age > 30;
DELETE FROM stus;
②语法:
TRUNCATE TABLE 表名
删除表中全部数据
【面试题】二者的区别:
- DELETE可加WHERE条件,TRUNCATE不能,一次性清除所有数据。
- 虽然TRUNCATE和DELETE都可以删除表的所有记录,但有原理不同。DELETE的效率没有TRUNCATE高。
- 自增列使用TRUNCATE后从1开始,DELETE则从断点处(原先值)开始。
- DELETE删除数据会返回行数,TRUNCATE不会。
- DELETE删除数据可以支持事务回滚,TRUNCATE删除的记录是无法回滚的。
TRUNCATE其实属性DDL语句,因为它是先DROP TABLE,再CREATE TABLE。
多表删除语法:
DELETE FROM 表1 别名1 INNER JOIN 表2 别名2 on 连接条件 【AND 筛选条件】