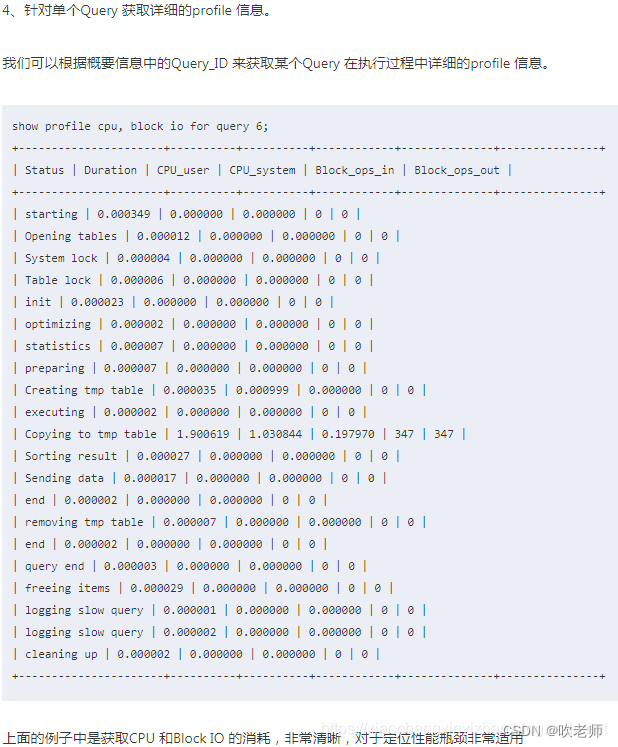
Siam R-CNN: 通过重检测进行视觉跟踪
- Siam R-CNN: Visual Tracking by Re-Detection
- Contributions
- Method
- Siam RCNN
- Video Hard Example Mining
- Tracklet Dynamic Programming Algorithm
- 实验
- 总结
更多Ai资讯:公主号AiCharm

Siam R-CNN: Visual Tracking by Re-Detection
Siam R-CNN是亚琛工业大学&牛津大学联合推出的,核心是通过重检测进行视觉跟踪,并构建了基于轨迹的动态规划算法,建模被跟踪对象和潜在干扰对象的完整历史。效率方面,该方法可以在 ResNet-101 上达到 4.7 FPS,在 ResNet-50 上达到 15 FPS 。

论文:https://arxiv.org/abs/1911.12836
代码:https://github.com/SJTU-DL-lab/SiamRCNN
Contributions
- 将重检测思想用于跟踪。通过判断建议区域(region proposal)是否与模板区域(template region)相同,重检测图像中任何位置的模板对象,并对该对象的边界框进行回归,这种方法对目标大小和长宽比变化比较鲁棒;
- 提出一种新颖的 hard example mining 方法,专门针对困难干扰物训练;
- 提出 Tracklet Dynamic Programming Algorithm (TDPA),可以同时跟踪所有潜在的目标,包括干扰物。通过重检测前一帧所有目标候选框,并将这些候选框随时间分组到tracklets(短目标轨迹)中。然后利用动态规划的思想,根据视频中所有目标和干扰物tracklets的完整历史选择当前时间步长的最佳对象。Siam R-CNN通过明确地建模所有潜在对象的运动和交互作用,并将检测到的相似信息汇集到tracklets中,能够有效地进行长时跟踪,同时抵抗跟踪器漂移,在物体消失后可以立即重检测目标。
Method
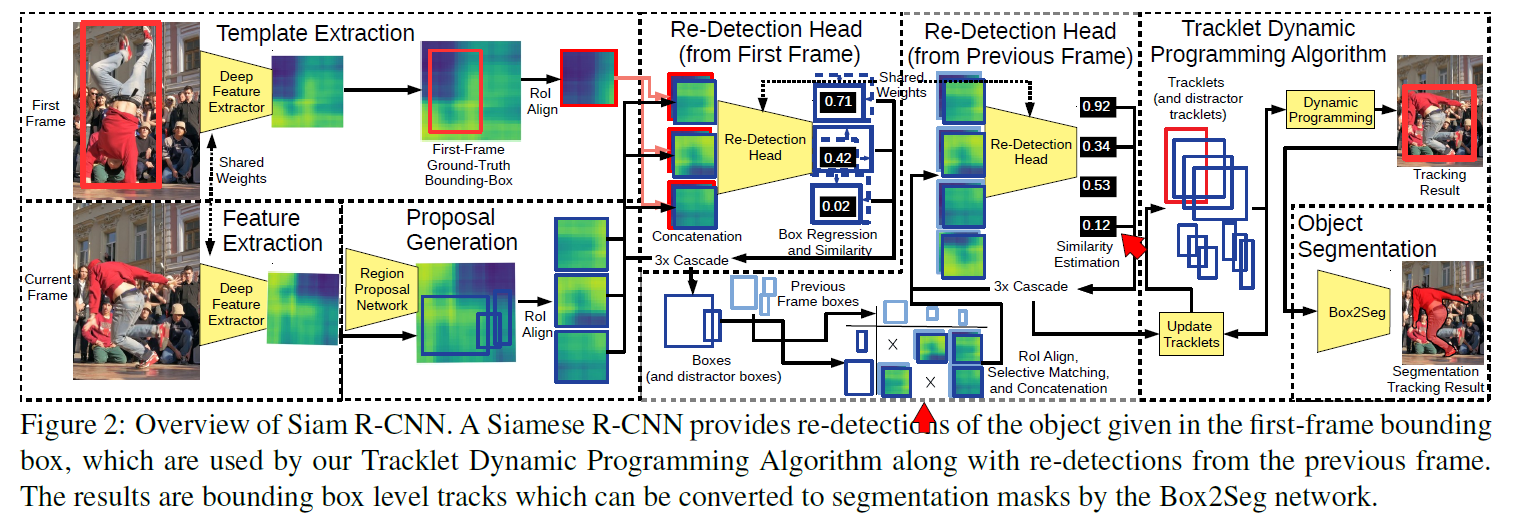
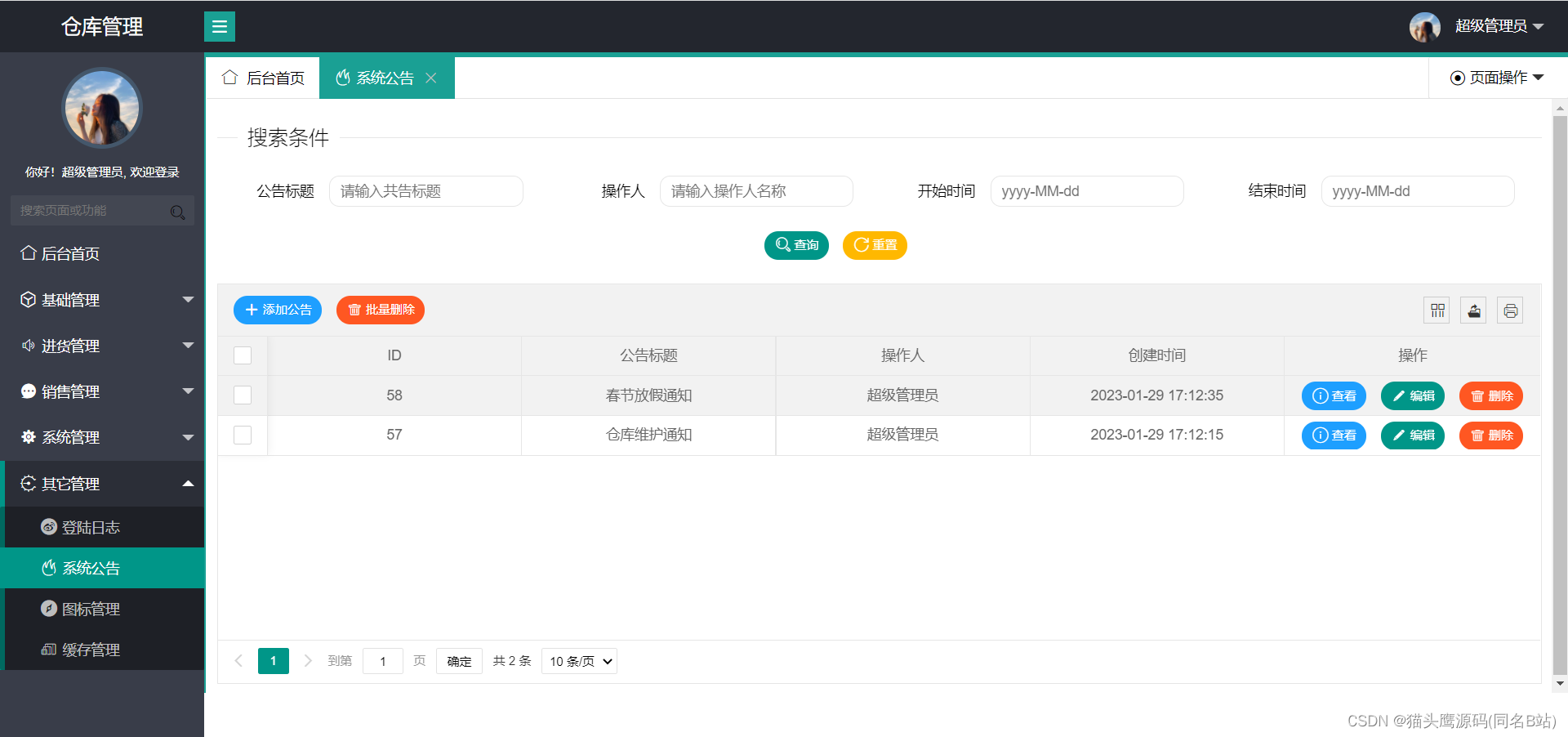
上图为Siam RCNN整体框架,作者设计了一个Siamese two-stage detection network作为跟踪器。第一阶段是RPN,第二阶段通过将感兴趣区域(RoI)的特征和参考特征拼接起来,包括以第一帧的GT作为参考和以前一帧的检测结果作为参考的两个redetction head。最后构建Tracklet Dynamic Programming Algorithm (TDPA)去跟踪所有潜在目标。
接下来按照论文结构对每一部分进行说明:
Siam RCNN
本小节主要是讲如何将 Faster RCNN 的那一套用于重检测,核心是将固定类别的detection head换成本文的re-detection head。re-detection head的输出只有两类,即候选区域是否是参考对象目标。训练时backbone和RPN的参数冻结,只有re-detection head参与训练。
Video Hard Example Mining
在传统 Faster RCNN 训练中,负样本是从RPN得到的区域中采样得到的。但是,在许多图像中,仅有少量负样本。为了最大化 re-detection head 的判别能力,作者认为需要在难负样本(hard negative samples)上训练。并且与检测中的通用难样本不同,这里的难样本是从其他视频中检索出来的与参考目标类似的样本。
-
Embedding Network 最直接的方法就是从其他视频中寻找与当前对象属于同一个类别的对象作为难负样本。然而,物体的类别标签并不总是可靠,一些同类的物体很容易区分,不同类别的物体反而可能是理想的难负样本。所以,本文受到行人重识别的启发,提出利用 embedding network 的方法,将 GT Box 中的物体映射为 embedding vector。这个网络来源于 PReMVOS,用 batch-hard triplet loss 来训练,期望达到的效果是消除单个对象实例之间的歧义,例如,两个不同的人在嵌入空间中应该离得很远,而同一个人在不同帧中的向量距离应该很近。
-
Index Structure 接下来为近邻 queries 构建一个有效的索引结构,将其用于寻找所需要跟踪的物体在 embedding space 中的最近邻。图 3 展示了一些检索得到的难负样本。

-
Training Procedure 训练时在其他视频上实时检索当前视频帧的难负样本过于耗时。本文预先对训练数据的每一个 GT Box 都提取其 RoI-aligned features。在训练的每一步,随机选择一个 video 和 object,然后随机的选择一个 reference 和 target frame。在此之后,用上一节提到的 indexing structure 来检索 10000 个最近邻的 reference box,从中选择出 100 个 negative training examples。
Tracklet Dynamic Programming Algorithm
本文所提出的 片段动态规划算法(Tracklet Dynamic Programming Algorithm)隐式地跟踪感兴趣目标和潜在干扰物,从而持续抑制干扰对象。为此,TDPA 维护一组 tracklets,即:short sequences of detections。然后利用动态规划的评分算法为模板对象在第一帧和当前帧之间选择最可能的 tracklets序列。每个detection都定义为:a bounding box, a re-dection score 和 RoI-aligned features。此外,每个 detection 都是 tracklet 的组成部分。tracklet有一个开始时间和一个结束时间,并由一组 detection 定义,从开始到结束时间的每一个时间步对应一个detection ,也就是说,在tracklet中不允许有空隙。
- Tracklet Building

Line 2 提取backbone特征
Line 3 RPN得到感兴趣区域,为了补偿潜在的假负例影响,加入上一帧的结果;
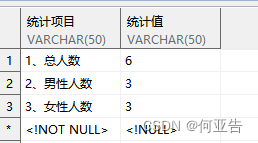
Line 4 将Roi和gt送入redetection head得到第一帧的重检测结果 $ det_{S_t} $(包括相似性得分和目标框);
Line 5-6 将当前帧结果 $ det_{S_t} $ 与上一帧结果 $ det_{S_{t-1}} $ 送入redetection head计算每一对检测结果的相似性得分(为了减少计算,仅把当前帧与上一帧框的归一化空间距离小于 r 时才送入head计算,否则相似性得分设为负无穷。如图2,上一帧有3个结果,当前帧有2个结果,理论上两两之间应该计算6个相似得分,但通过框的空间距离约束,实际参与相似得分计算的只有4组);
Line 7-20 扩展tracklets。遍历当前帧的检测结果 d _ t i n d e t _ S _ t d\_t \\in det\_{S\_t} d_tindet_S_t 加入tracklet需要满足:
- 当前结果 d _ t d\_t d_t 与上一帧结果 h a t d _ t − 1 \\hat{d} \_ {t-1} hatd_t−1 的最大相似性得分 s _ 1 s\_{1} s_1 大于阈值 a l p h a \\alpha alpha
- 当前帧没有其他检测结果与 $ \hat{d} _ {t-1} $ 具有同样高的相似性,即当前帧除 d _ t d\_t d_t 以外的结果与 $ \hat{d} _ {t-1} $ 的相似性要满足 s _ 2 l e q s _ 1 − b e t a s\_{2} \\leq s\_{1}-\\beta s_2leqs_1−beta
- 上一帧没有其他检测结果与当前的 d _ t d\_t d_t 具有同样高的相似性,即上一帧除 $ \hat{d} _ {t-1} $ 以外的结果与 d _ t d\_t d_t 的相似性要满足 s _ 3 l e q s _ 1 − b e t a s\_{3} \\leq s\_{1}-\\beta s_3leqs_1−beta
- Scoring
轨迹 A = ( a _ 1 , … , a _ N ) A=(a\_1,…,a\_N) A=(a_1,…,a_N) 是一个包含N个不重复tracklets的序列,其中 e n d ( a _ i ) < s t a r t ( a _ i + 1 ) , f o r a l l i ∈ 1 , … , N − 1 end(a\_i) < start(a\_{i+1}), \\forall i∈\\{1,…,N-1\\} end(a_i)<start(a_i+1),foralli∈1,…,N−1 ,即后一个tracklet的开始帧一定比前一个tracklet的结束帧大。一个轨迹的总分由衡量单个轨迹质量的一元分数 unuary 和惩罚轨迹之间空间距离的位置分数 loc_score 组成。

其中 ff_score 表示tracklet a _ i a\_{i} a_i 在 t 时刻以第一帧gt为参考的重检测分数;
而 ff_tracklet_score 表示 a _ i a\_{i} a_i 以gt所在tracklet的最后一个检测结果为参考的重检测分数(因为一个tracklet的所有检测结果都有很高概率与这个tracklet的第一个检测结果相同,否则这个tracklet就会终止,所以gt所在的tracklet的最后一个检测结果也有很大概率是正确的);
Location score是计算前一个tracklet最后一个检测结果和后一个tracklet的第一个检测结果的bbox之间的L1距离,是负的,作为惩罚项,越小越好。

- Online Dynamic Programming
这一节介绍如何高效找到具有最大总得分的tracklets序列。
定义 $ \theta[a]$ 表示从第一个tracklet开始到第a个tracklet的总得分。由于一旦tracklet不被扩展,就会终止。因此当新的一帧到来时,只有被扩展或者新建的tracklet需要重新计算score。
首先设置 $ \theta[a_{ff}]=0 , , ,a_{ff}$ 是first-frame tracklet(即包含gt的tracklet),当每一个tracklet a被创建或需要更新时

在更新了当前帧的 $ \theta$ 后,选择最大动态规划得分的tracklet $ \hat{a}=arg max_{a} \theta[a]$;如果被选中的tracklet在当前帧中没有检测结果,则算法会指出目标不存在。由于benchmarks要求每帧都输出结果,所以我们用选定的tracklet最近一次的检测的box,并且将其得分置0。
实验
实验做的很充分,在目前主流数据集中都有结果。在short-term的测试中,大部分达到SOTA水平或者比SOTA稍低一些,在long-term的测试效果则非常好,基本吊打第二名。其中VOT的测试因为其自带一个重启,会与算法本身的重启冲突,所以作者专门做了一个short-term版本的用于VOT测试。





消融实验比较了 使用hard example mining的效果,TPDA与直接使用每一帧最大的重检测得分(Argmax)的对比,和专门用于测试VOT2018的short-term版本;以及改变backbone和ROI的参数量来提速的验证。
总结
本文最大的贡献在于将两阶段结构和重检测用于跟踪,设计了一套适合长时跟踪的算法。两阶段结构在SPM-Tracker已经证明了其对于鲁棒性和判别性之间有较好的平衡;而重检测这类检索的方法同样对于目标变化的适应性更强。整套算法做的非常完善,美中不足在于速度太慢。
SiamRCNN很长一段时间都作为各类跟踪数据集的天花板,直到CVPR2021各类transform架构的跟踪算法出现后才被超过。
更多Ai资讯:公主号AiCharm