Title
题目
Unsupervised Medical Image Translation With Adversarial Diffusion Models
无监督医学图像翻译与对抗扩散模型
01
文献速递介绍
多模态成像对于全面评估人体解剖结构和功能至关重要[1]。通过各自模态捕获的互补组织信息,有助于提高诊断准确性并改善下游成像任务的性能。然而,由于经济和劳动成本的挑战,多模态协议的广泛应用面临困难。
医学图像翻译是一个强大的解决方案,涉及在已获得的源模态的指导下合成缺失的目标模态。考虑到跨模态之间组织信号的非线性变化,这种恢复是一个病态问题。
在这个关键时刻,基于学习的方法通过整合非线性数据驱动的先验来改善问题的条件,提供了性能的飞跃。
学习-based的图像翻译涉及训练网络模型来捕获给定源图像的目标条件分布的先验。近年来,由于它们在图像合成中的出色逼真性,生成对抗网络(GAN)模型已被广泛采用于翻译任务。
通过捕获关于目标分布的信息,鉴别器同时指导生成器从源图像到目标图像的一次性映射,基于这种对抗机制,GAN在多种翻译任务中报告了最新的结果,包括跨MR扫描仪的合成,多对比MR合成,以及跨模态合成。
虽然强大,GAN模型通过生成器和鉴别器的相互作用间接表征目标模态的分布,而不评估可能性。这种隐式表征可能容易受到学习偏差的影响,包括早期收敛和模式崩溃。此外,GAN模型通常采用快速的一次性采样过程,没有中间步骤,从根本上限制了网络执行的映射的可靠性。反过来,这些问题可能限制合成图像的质量和多样性。
作为一个有希望的替代方法,最近的计算机视觉研究采用基于明确可能性表征和逐渐采样过程的扩散模型,以改善无条件生成建模任务中的样本保真度。然而,扩散方法在医学图像翻译中的潜力仍然大部分未被探索,部分原因是图像采样的计算负担和常规扩散模型非配对训练的困难。
Abstract
摘要
Imputation of missing images via source-to**target modality translation can improve diversity in medicalimaging protocols. A pervasive approach for synthesizingtarget images involves one-shot mapping through generative adversarial networks (GAN). Yet, GAN models thatimplicitly characterize the image distribution can suffer fromlimited sample fidelity. Here, we propose a novel methodbased on adversarial diffusion modeling, SynDiff, forimproved performance in medical image translation. To capture a direct correlate of the image distribution, SynDiffleverages a conditional diffusion process that progressivelymaps noise and source images onto the target image. Forfast and accurate image sampling during inference, largediffusion steps are taken with adversarial projections in thereverse diffusion direction. To enable training on unpaireddatasets, a cycle-consistent architecture is devised withcoupled diffusive and non-diffusive modules that bilaterallytranslate between two modalities. Extensive assessmentsare reported on the utility of SynDiff against competingGAN and diffusion models in multi-contrast MRI and MRICT translation. Our demonstrations indicate that SynDiffoffers quantitatively and qualitatively superior performanceagainst competing baselines.
通过源到目标模态转换来填补缺失图像可以改善医学成像协议的多样性。合成目标图像的普遍方法涉及通过生成对抗网络(GAN)进行一次性映射。然而,隐式表征图像分布的GAN模型可能存在样本保真度有限的问题。在这里,我们提出了一种基于对抗扩散建模的新方法SynDiff,用于改善医学图像翻译的性能。为了捕捉图像分布的直接相关性,SynDiff利用逐步映射噪声和源图像到目标图像的条件扩散过程。在推断过程中,为了快速准确地进行图像采样,采用了大的扩散步骤和反向扩散方向的对抗投影。为了在非配对数据集上进行训练,设计了一个循环一致的架构,其中包括耦合的扩散和非扩散模块,双向地在两种模态之间进行翻译。在多对比MRI和MRI CT转换中,我们对SynDiff与竞争的GAN和扩散模型进行了广泛评估。我们的演示表明,SynDiff在量化和定性性能上均优于竞争基准。
Method
方法
We demonstrated SynDiff on two multi-contrast brain MRIdatasets (IXI,1 BRATS [61]), and a multi-modal pelvic MRICT dataset. In each dataset, a three-way split wasperformed to create training, validation and test sets with nosubject overlap. While all unsupervised medical image translation models were trained on unpaired images, performanceassessments necessitate the presence of paired and registeredsource-target volumes. Thus, in the validation and test sets,separate volumes of a given subject were spatially registered toenable calculation of quantitative metrics. Registrations wereimplemented in FSL via affine transformation and mutualinformation loss. In each subject, each imaging volumewas separately normalized to a mean intensity of 1. Themaximum voxel intensity across subjects was then normalizedto 1 to ensure an intensity range of Cross-sectionalimages were zero-padded as necessary to attain a consistent256 × 256 image size in all datasets prior to modeling.
我们在两个多对比脑部MRI数据集(IXI、BRATS)和一个多模态盆腔MRI CT数据集 上展示了SynDiff。在每个数据集中,进行了三路分割,以创建训练、验证和测试集,并确保主体之间没有重叠。尽管所有无监督医学图像翻译模型都是在非配对图像上训练的,性能评估需要配对并注册的源-目标体积。因此,在验证和测试集中,给定主体的不同体积被空间配准,以便计算定量指标。配准是通过FSL中的仿射变换和互信息损失实现的 。在每个主体中,每个成像体积都被单独归一化到平均强度为1。然后,跨主体的最大像素强度被归一化为1,以确保强度范围为。在建模之前,根据需要对横截面图像进行零填充,以达到所有数据集中一致的256 × 256图像大小。
Conclusion
结论
In this study, we introduced a novel adversarial diffusionmodel for medical image translation between source andtarget modalities. SynDiff leverages a fast diffusion processto efficiently synthesize target images, and a conditionaladversarial projector for accurate reserve diffusion sampling.Unsupervised learning is achieved via a cycle-consistent architecture that embodies coupled diffusion processes between thetwo modalities. SynDiff achieves superior quality comparedto state-of-the-art GAN and diffusion models, and it holdsgreat promise for high-fidelity medical image translation. Thefast conditional diffusion process in SynDiff might also offerperformance benefits over GANs in other applications such asdenoising and super-resolution.
在本研究中,我们引入了一种新颖的对抗性扩散模型,用于医学图像在源和目标模态之间的翻译。SynDiff利用快速扩散过程有效合成目标图像,并使用条件对抗投影器进行准确的逆向扩散采样。通过循环一致的架构实现了无监督学习,该架构体现了两种模态之间耦合的扩散过程。与最先进的GAN和扩散模型相比,SynDiff实现了更高质量的图像合成,对高保真度的医学图像翻译具有巨大潜力。SynDiff中的快速条件扩散过程在其他应用(如去噪和超分辨率)中也可能比GAN提供更好的性能优势。
Results
结果
We demonstrated SynDiff for unsupervised MRI contrasttranslation against state-of-the-art non-attentional GAN(cGAN, UNIT, MUNIT), attentional GAN (AttGAN,SAGAN), and regular diffusion (DDPM, UNIT-DDPM)models. First, experiments were performed on brain imagesfrom healthy subjects in IXI.
我们展示了SynDiff在无监督MRI对比度翻译上的性能,与最先进的非注意力GAN(cGAN、UNIT、MUNIT)、注意力GAN(AttGAN、SAGAN)和普通扩散(DDPM、UNIT-DDPM)模型进行了对比。首先,在IXI健康主题的脑部图像上进行了实验。
Figure
图
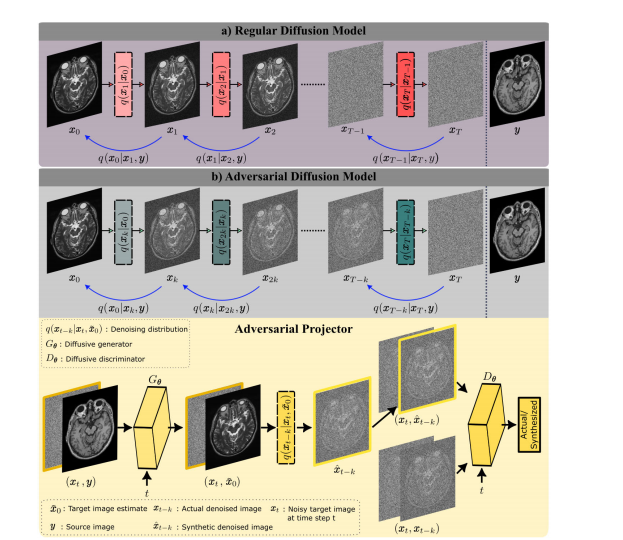
Fig. 1. a) Regular diffusion models gradually transform between actual image samples for the target modality (x0) and isotropic Gaussian noise (x**T)in T steps, with T on the order of thousands. Each forward step (right arrows) adds noise to the current sample to create a noisier sample with forwardtransition probability q
Fig. 1. a) 普通扩散模型在数千个步骤(T)中逐渐在目标模态(x₀)的实际图像样本和各向同性高斯噪声(xᵀ)之间进行转换。每个正向步骤(右箭头)向当前样本添加噪声,以创建一个更嘈杂的样本,其正向转移概率为q
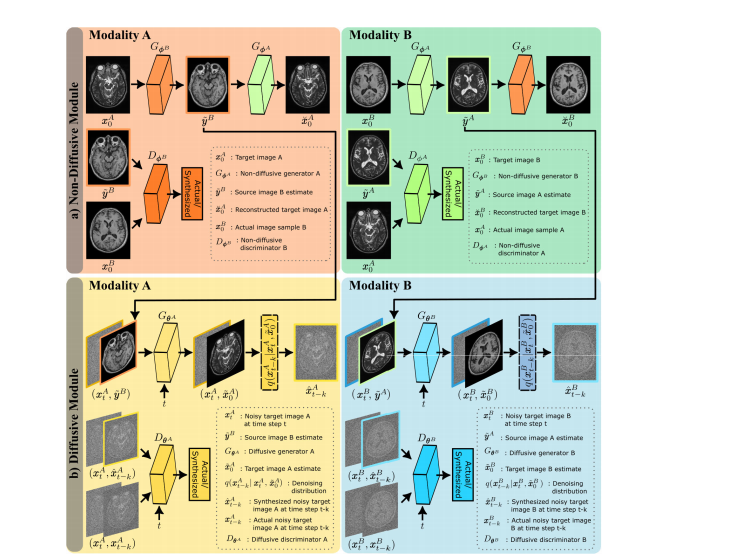
Fig. 2. For unsupervised learning, SynDiff leverages a cycle-consistent architecture that bilaterally translates between two modalities (A, B). Forsynthesizing a target image ˆx A0of modality A, the diffusive module in Fig. 1b requires guidance from a source image y B of modality B for the sameanatomy. However, a paired source image of the same anatomy might be unavailable in the training set. To enable training on unpaired images,SynDiff uses a non-diffusive module to first estimate a paired source image ˜y B from x A0. Similarly, for synthesizing a target image ˆx B0of modality B withthe diffusive module, the non-diffusive module first estimates a paired source image ˜y A from x B0. a) To do this, the non-diffusive module comprisestwo generator-discriminator pairs (Gφ A,B, Dφ A,B) that generate initial translation estimates for x A0 → ˜y B (orange) and x B0 → ˜y* A (green). b) Theseinitial translation estimates ˜y A,B are then used as guiding source-modality images in the diffusive module. For cycle-consistent learning, the diffusivemodule also comprises two generator-discriminator pairs (Gθ A,B, Dθ A,B) to generate denoised image estimates for (x At, ˜yB , t) → ˆx A−k (yellow) and(x Bt, ˜y A , t) → ˆx Bt−k (blue).
Fig. 2. 对于无监督学习,SynDiff利用了一个循环一致的架构,在两种模态(A,B)之间双向进行翻译。为了合成模态A的目标图像ˆx A0,如图1b中的扩散模块所需,需要来自模态B的同一解剖结构的源图像y B的指导。然而,在训练集中可能找不到同一解剖结构的配对源图像。为了在非配对图像上进行训练,SynDiff使用非扩散模块首先从x A0估计配对的源图像˜y B。类似地,对于合成模态B的目标图像ˆx B0,非扩散模块首先从x B0估计配对的源图像˜y A。
a) 非扩散模块包括两个生成器-鉴别器对(Gφ A,B,Dφ A,B),用于生成x* A0 → ˜y B(橙色)和x B0 → ˜y A(绿色)的初始翻译估计。
b) 这些初始翻译估计˜y A,B然后在扩散模块中作为引导源模态图像。为了循环一致学习,扩散模块还包括两个生成器-鉴别器对(Gθ A,B,Dθ A,B),用于为(x At, ˜y B, t)→ ˆx At−k(黄色)和(x Bt, ˜y A, t)→ ˆx Bt−k(蓝色)生成去噪图像估计。

Fig. 3. SynDiff was demonstrated on IXI for translation between MRI contrasts. Synthesized images from competing methods are displayed alongwith the source and the ground-truth target (reference) images for representative a) T1→T2, b) T2→PD tasks. Display windows of a) [0 0.65],b) [0 0.80] are used. Compared to baselines, SynDiff yields lower noise and artifacts, and maintains higher anatomical fidelity.
Fig. 3. 在IXI数据集上展示了SynDiff在MRI对比度之间的翻译。显示了来自竞争方法的合成图像,以及代表性任务的源图像和目标(参考)图像:a) T1→T2,b) T2→PD。显示窗口分别为a) [0 0.65],b) [0 0.80]。与基线相比,SynDiff产生的图像噪声和伪影更少,保持了更高的解剖学保真度。
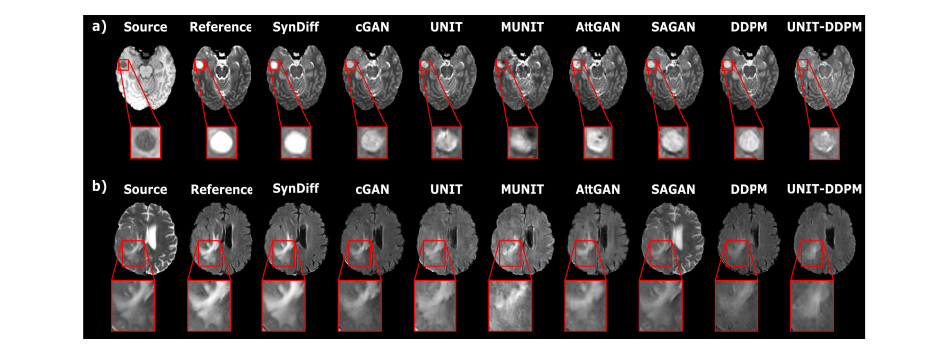
Fig. 4. SynDiff was demonstrated on BRATS for translation between MRI contrasts. Synthesized images are displayed along with the source andthe ground-truth target (reference) images for representative a) T1→T2, b) T2→FLAIR tasks. Display windows of a) [0 0.75], b) [0 0.80] are used.SynDiff lowers noise/artifact levels and more accurately depicts detailed structure compared to baselines.
Fig. 4. 在BRATS数据集上展示了SynDiff在MRI对比度之间的翻译。显示了合成图像,以及代表性任务的源图像和目标(参考)图像:a) T1→T2,b) T2→FLAIR。显示窗口分别为a) [0 0.75],b) [0 0.80]。与基线相比,SynDiff降低了噪声/伪影水平,并更准确地描绘了详细结构。
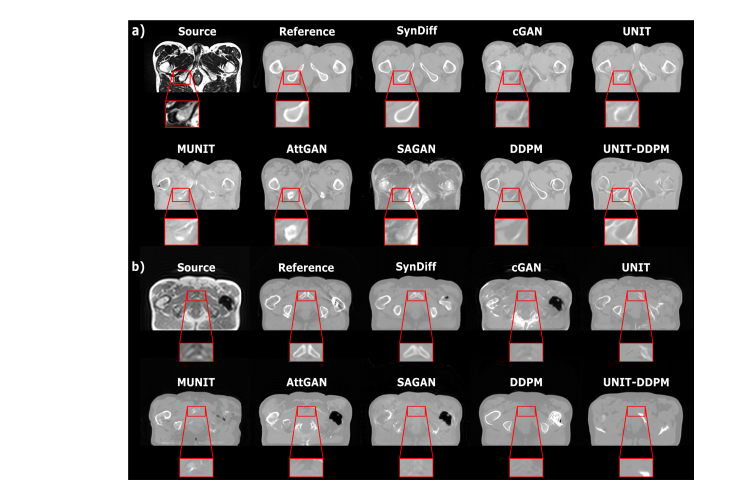
Fig. 5. SynDiff was demonstrated on the pelvic dataset for multi-modal MRI-CT translation. Synthesized images are displayed along with the sourceand the ground-truth target (reference) images for representative a) T2→CT, b) accelerated T1→CT tasks. Display windows of a) [-1000 1050] HU,and b) [-1000 1000] HU are used. Compared to diffusion and GAN baselines, SynDiff achieves lower artifact levels, and more accurately estimatesanatomical structure near diagnostically-relevant regions.
Fig. 5. 在盆腔数据集上展示了SynDiff进行多模态MRI-CT翻译。显示了合成图像,以及代表性任务的源图像和目标(参考)图像:a) T2→CT,b) 加速T1→CT。显示窗口分别为a) [-1000 1050] HU,b) [-1000 1000] HU。与扩散和GAN基线相比,SynDiff实现了更低的伪影水平,并更准确地估计了与诊断相关区域附近的解剖结构。
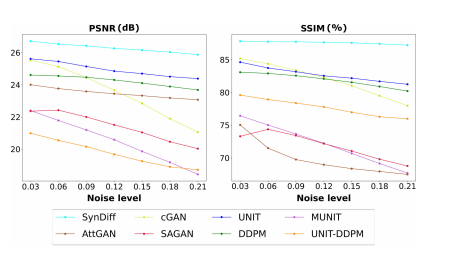
Fig. 6. Performance of competing methods as a function of added noise level on source-modality images. Results shown for the representative
T2→CT task in terms of PSNR (left), SSIM (right).
Fig. 6. 竞争方法在添加到源模态图像的噪声水平函数上的性能。以PSNR(左)和SSIM(右)显示了代表性的T2→CT任务的结果。

Fig. 7. The adversarial projector in SynDiff with T/k=4 steps wascompared against a variant model using an ℓ1-loss based projector withT/k=4 and T/k=1000. Image samples are shown for the unconditionalsynthesis tasks: a) T1 in IXI, b) T2 in BRATS and c) CT in pelvicdatasets. Display windows of a) [0 0.90], b) [0 0.80] for MRI images, andc) [-1000 1300] HU for CT images are used.
Fig. 7. 在SynDiff中,使用T/k*=4步的对抗投影器与使用基于ℓ1损失的投影器的变体模型进行了比较,其中T/k*=4和T/k=1000。显示了无条件合成任务的图像样本:a) IXI中的T1,b) BRATS中的T2,c) 盆腔数据集中的CT。MRI图像的显示窗口分别为a) [0 0.90],b) [0 0.80],CT图像为c) [-1000 1300] HU。
Table
表

TABLE I description of variables related to images, diffusion processes, networks and probability distributions. throughout the manuscript, vectorial quantities are annotated in bold font
表 I图像、扩散过程、网络和概率分布相关变量描述。
在整篇文章中,向量量用粗体字体标注。

TABLE II performance for multi-contrast mri translation tasks in ixi. psnr (db) and ssim (%) are listed as mean±std across the test set. boldface marks the top-performing model in each task
表II在IXI数据集中多对比MRI翻译任务的性能。PSNR(分贝)和SSIM(百分比)列出了在测试集上的平均±标准差。粗体字标记了每个任务中表现最佳的模型。

TABLE III performance for multi-contrast mri translation tasks in brats. psnr (db) and ssim (%) listed as mean±std across the test set
表III在BRATS数据集中多对比MRI翻译任务的性能。PSNR(分贝)和SSIM(百分比)列出了在测试集上的平均±标准差。

TABLE IVperformance for multi-modal mri-ct translation tasks in the pelvic dataset. psnr (db) and ssim (%) listed as mean±std across the test set.‘acc.’ stands for accelerated
表 IV在盆腔数据集中多模态MRI-CT翻译任务的性能。PSNR(分贝)和SSIM(百分比)列出了在测试集上的平均±标准差。“ACC.”代表加速。
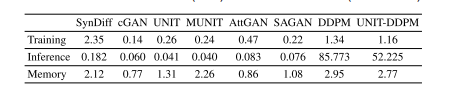
TABLE Vaverage training times per cross-section (sec), inference times per cross-section (sec) and memory load (gigabytes)
表 V每个横截面的平均训练时间(秒)、推断时间(秒)和内存负载(GB)。
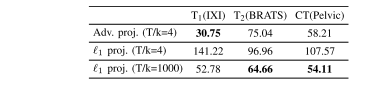
TABLE VI performance of variant models in unconditional synthesis tasks. fid is listed across the training set
表VI变体模型在无条件合成任务中的性能。FID(生成图像分布之间的Frechet距离)列出了在训练集上的值。
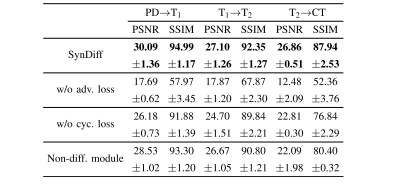
TABLE VII performance of variant models ablated of adversarial loss, cycle-consistency loss and the diffusive module. psnr and ssim listed as mean±std across the test set
表 VII变体模型在去除对抗损失、循环一致性损失和扩散模块后的性能。PSNR和SSIM列出了在测试集上的平均±标准差。
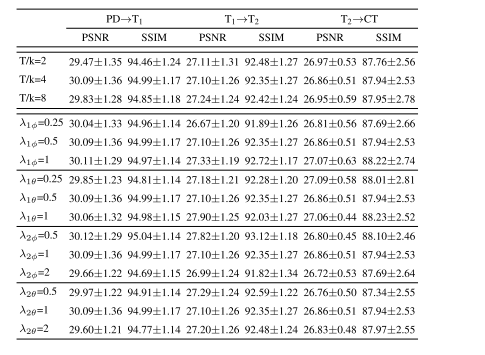
TABLE VIII performance of variant models for varying number of steps t/k and varying loss-term weights (λ₁φ, λ₁θ, λ₂φ, λ₂θ).psnr and ssim listed as mean±std across the test set
表VIII变体模型在不同步骤T/k数和不同损失项权重(λ1φ、\λ1θ、λ2φ、\λ2θ)下的性能。PSNR和SSIM列出了在测试集上的平均±标准差。
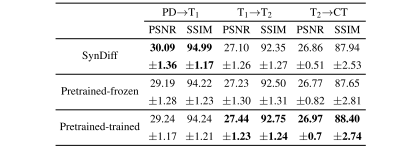
TABLE IX performance of variant models as mean±std across the test set. the non-diffusive module was pretrained in variant models. in pretrained-frozen, the non-diffusive module was not updated while training the diffusive module. in pretrained-trained, the non-diffusive module was also updated while training the diffusive module
表 IX 变体模型在测试集上的平均±标准差性能。非扩散模块在变体模型中进行了预训练。在预训练-冻结中,非扩散模块在训练扩散模块时未更新。在预训练-训练中,非扩散模块在训练扩散模块时也进行了更新。
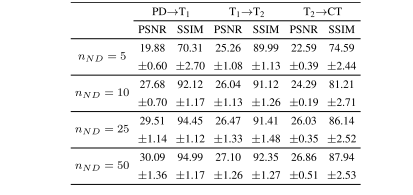
TABLE X performance of variant models as mean±std across the test set. in variant models, the non-diffusive module was only trained for nₙD epochs while the diffusive module was fully trained
表 X 变体模型在测试集上的平均±标准差性能。在变体模型中,非扩散模块仅在nₙ₋D个时期内进行训练,而扩散模块则进行了完全训练。