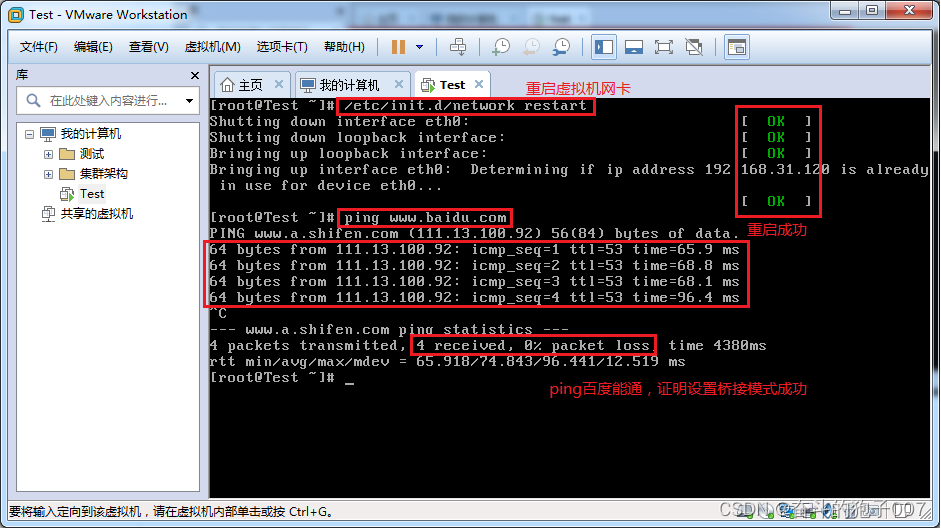
1、代码
import xlrd
import requests
read_path = 'C:\\Users\\asus\\Desktop\\大法\\公务员\\国考\\行测\\1-推理判断\\URLs.xlsx'
bk = xlrd.open_workbook(read_path)
shxrange = range(bk.nsheets)
sh = bk.sheet_by_name("Sheet2")
nrows = sh.nrows
ncols = sh.ncols
print("nrows=", nrows)
print("ncols=", ncols)
kv = {'user-agent': 'Mozilla/5.0'} # 添加请求头
for i in range(nrows):
print("下载第%d个图片", i)
url = sh.cell_value(i, 1) # 依次读取每行第2列(序号从0开始)的数据,也就是 URL
print(url)
name = str(sh.cell_value(i, 0)) # 读取图片名称
f = requests.get(url, headers=kv) # 下载图片
print("下载图片", f)
pic_name = "C:\\Users\\asus\\Desktop\\Photo\\" + name + "." + "jpg" # 构造完整文件路径+名称
print(pic_name)
with open(pic_name, "wb") as code:
code.write(f.content) # 保存文件
2、URLs.xlsx
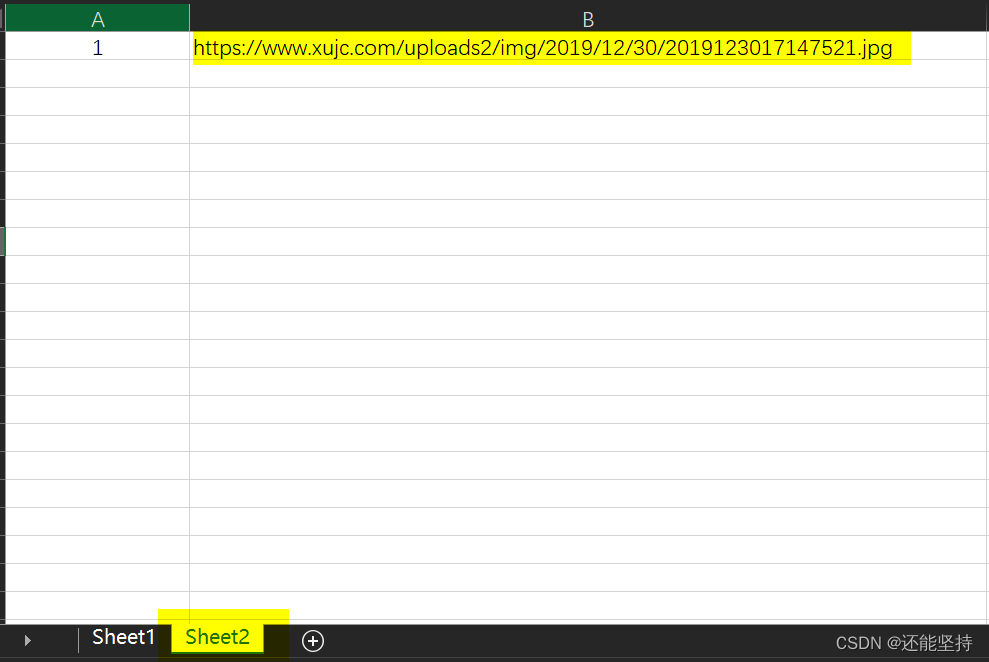
3、Python爬取网页提示状态码404,浏览器可访问网址
Python爬取网页提示状态码404,浏览器可访问网址