目录
功能以及简单使用
gin.Engine数据结构
RouterGroup
methodTrees
gin.context
功能以及简单使用
功能:
• 支持中间件操作( handlersChain 机制 )
• 更方便的使用( gin.Context )
• 更强大的路由解析能力( radix tree 路由树 )
简单使用:
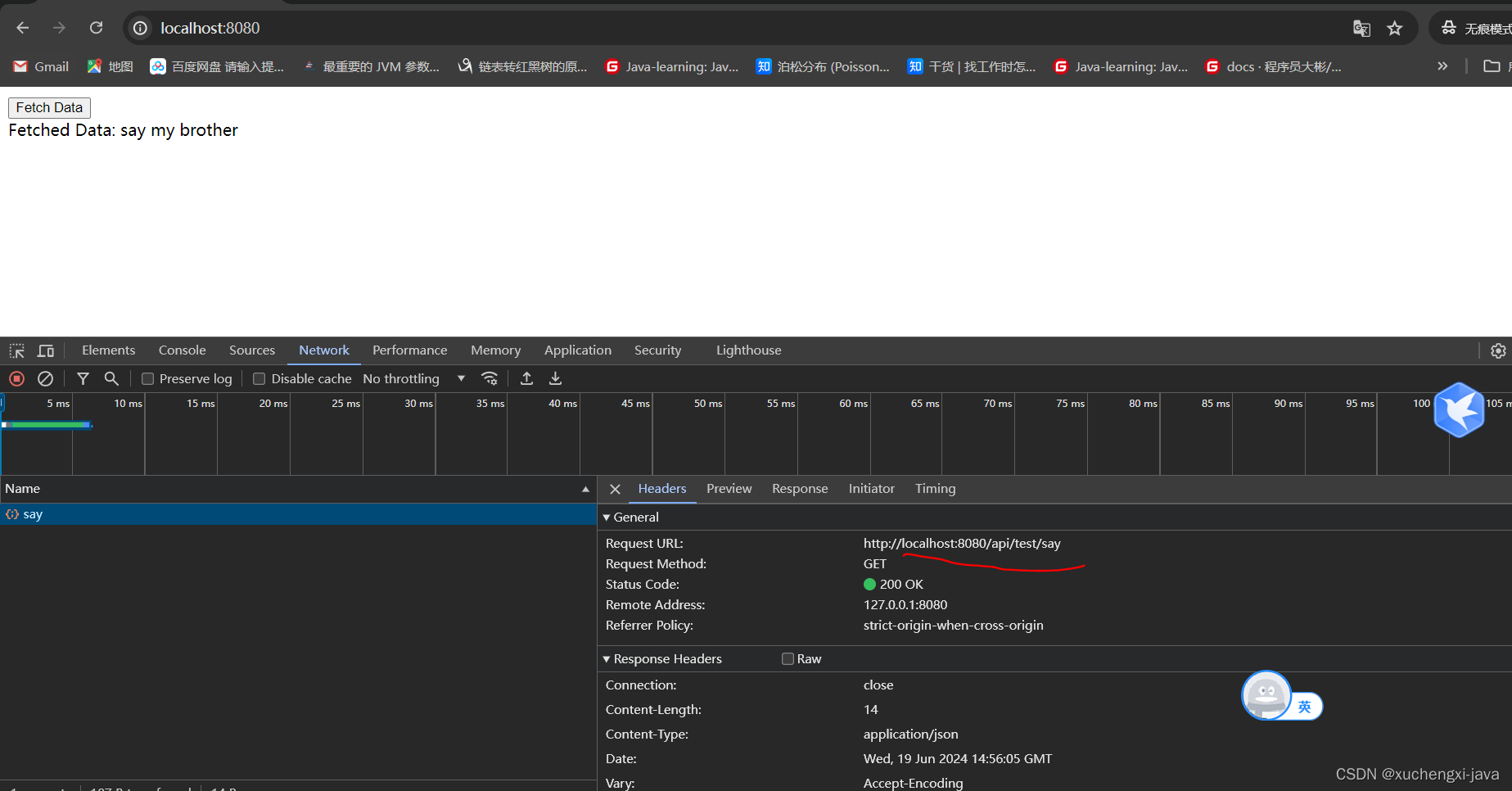
gin.Default()创建一个gin Engine(http Handler)
http字段内容有:域名,数据长度,是否长连接,数据格式,压缩格式
Engine.Use : 注册中间件 常用的中间件有 :
Recover() 捕获异常
Log() 打印日志
Cors() 跨域的资源共享
Engine.POST() : 路由组注册 POST 方法下的 handler
Engine.Run() : 启动 http server
import "github.com/gin-gonic/gin"
func main() {
// 创建一个 gin Engine,本质上是一个 http Handler
mux := gin.Default()
// 注册中间件
mux.Use(myMiddleWare)
// 注册一个 path 为 /ping 的处理函数
mux.POST("/ping", func(c *gin.Context) {
c.JSON(http.StatusOK, "pone")
})
// 运行 http 服务
if err := mux.Run(":8080"); err != nil {
panic(err)
}
}gin.Engine数据结构
最重要的三个
RouterGroup 路由组 管理更方便
context 对象池 节约资源,避免重复创建,造成资源浪费
methodTrees 路由树 强大的路由解析
type Engine struct {
// 路由组
RouterGroup
// ...
// context 对象池
pool sync.Pool
// 方法路由树
trees methodTrees
// ...
}RouterGroup
RouterGroup 是路由组的概念,其中的配置将被从属于该路由组的所有路由复用
代码:
type RouterGroup struct {
Handlers HandlersChain
basePath string
engine *Engine
root bool
}解析:
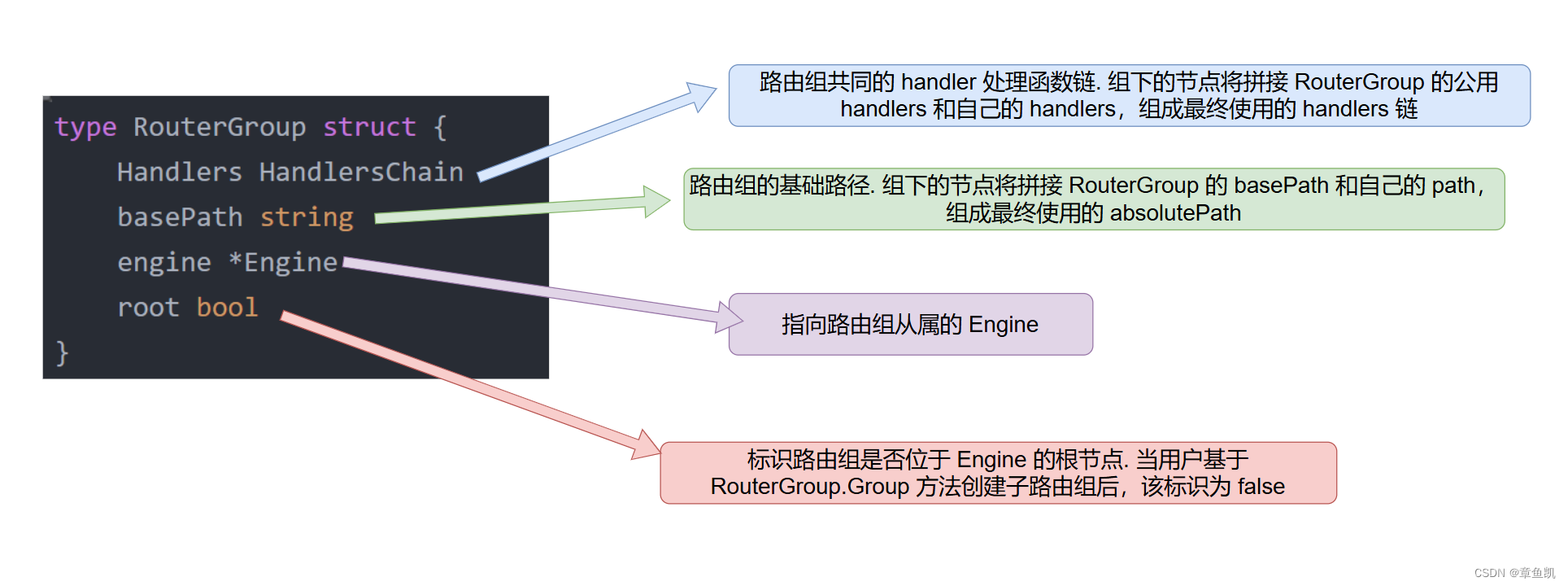
HandlersChain:由多个路由处理函数 HandlerFunc 构成的处理函数链.
在使用的时候,会按照索引的先后顺序依次调用 HandlerFunc.
methodTrees
知识补充 前缀树和压缩前缀树
前缀树:
前缀树又称 trie 树,是一种基于字符串公共前缀构建索引的树状结构,核心点包括:
-
除根节点之外,每个节点对应一个字符
-
从根节点到某一节点,路径上经过的字符串联起来,即为该节点对应的字符串
-
尽可能复用公共前缀,如无必要不分配新的节点
leetcode算法实现 208. 实现 Trie (前缀树) - 力扣(LeetCode)
示例:

压缩前缀树:
压缩前缀树又称基数树或 radix 树,是对前缀树的改良版本,优化点主要在于空间的节省,核心策略体现在:
倘若某个子节点是其父节点的唯一孩子,则与父节点进行合并
图中一下情况,就不能合并 如果合并那么 apple这个就会失效
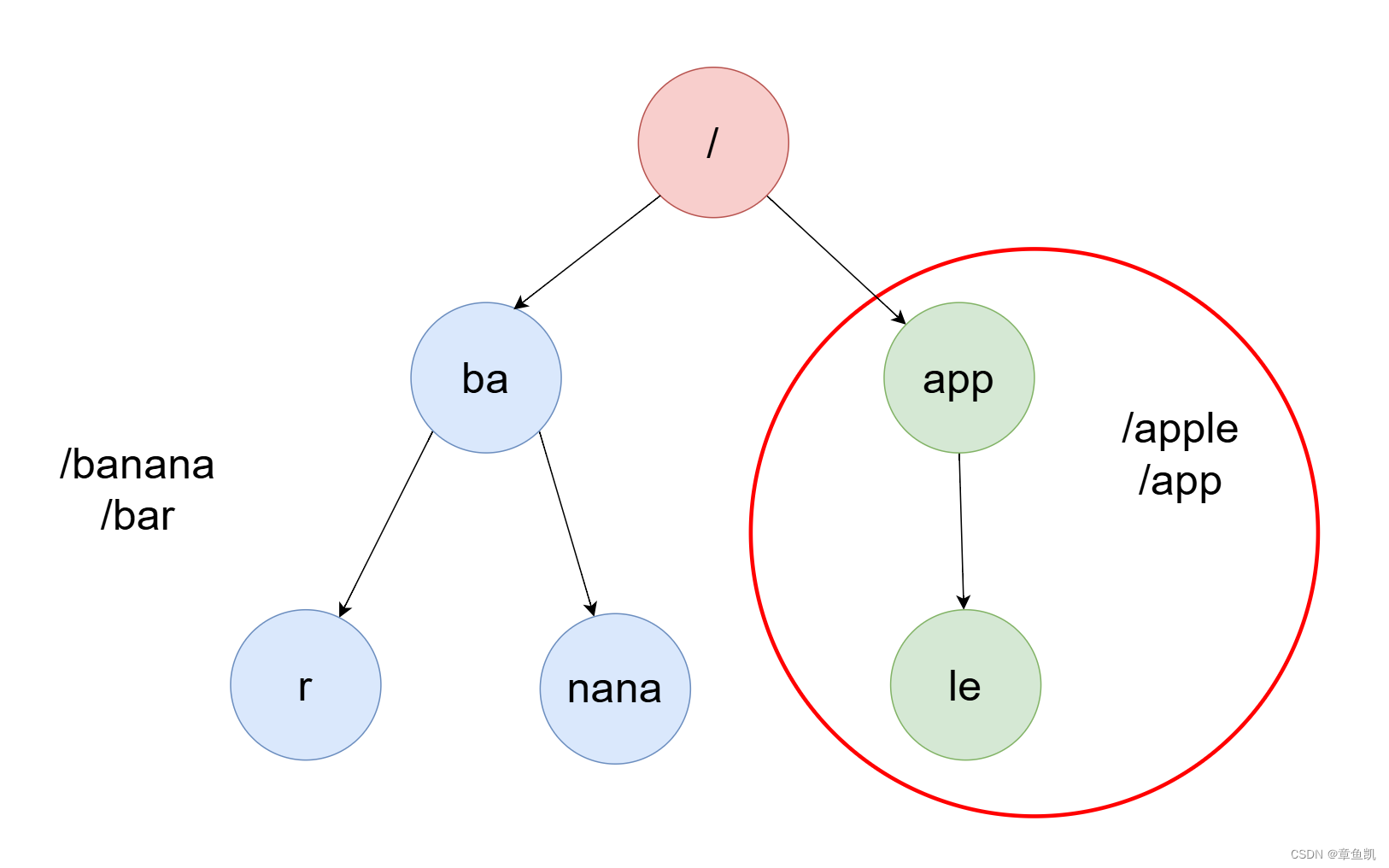
如下才能压缩

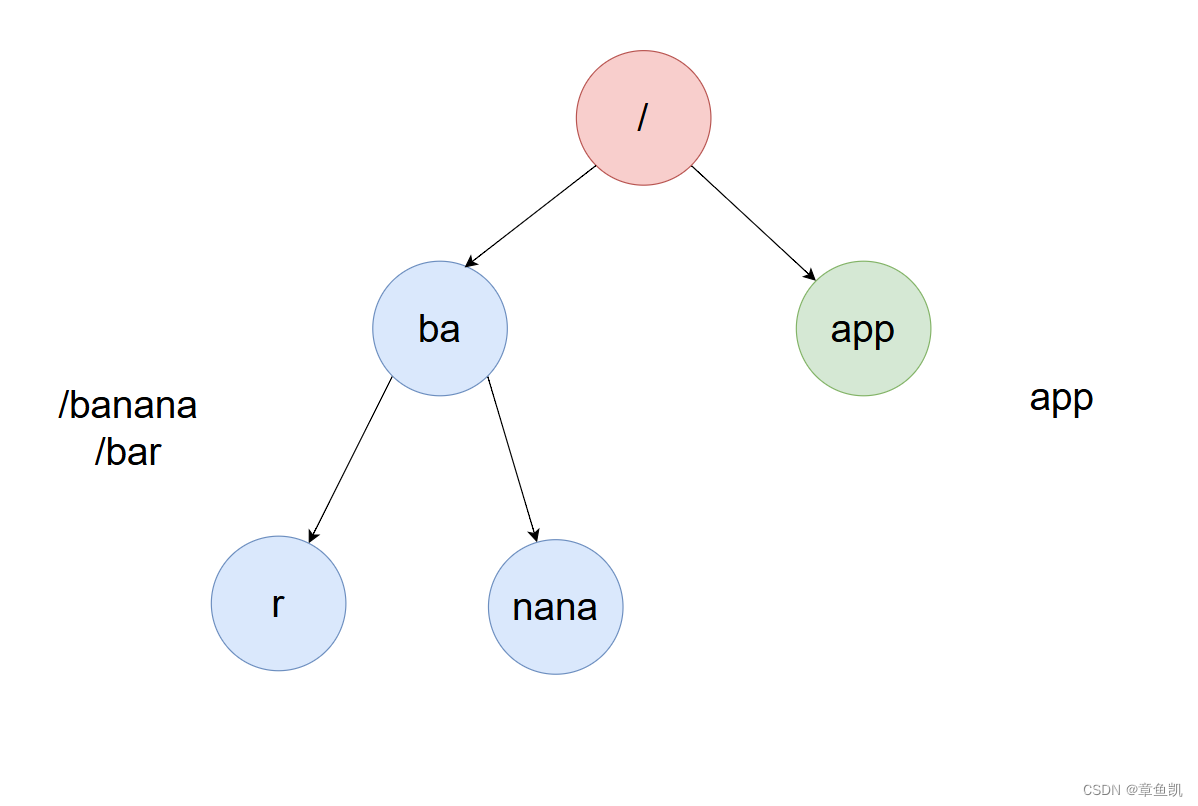
核心代码:
methodTree :
type methodTree struct {
method string
root *node
}node:
type node struct {
// 节点的相对路径
path string
// 每个 indice 字符对应一个孩子节点的 path 首字母
indices string
// ...
// 后继节点数量
priority uint32
// 孩子节点列表
children []*node
// 处理函数链
handlers HandlersChain
// path 拼接上前缀后的完整路径
fullPath string
}node 是 radix tree 中的节点,对应节点含义如下:
-
path:节点的相对路径,拼接上 RouterGroup 中的 basePath 作为前缀后才能拿到完整的路由 path
-
indices:由各个子节点 path 首字母组成的字符串,子节点顺序会按照途径的路由数量 priority进行排序
-
priority:途径本节点的路由数量,反映出本节点在父节点中被检索的优先级
-
children:子节点列表
-
handlers:当前节点对应的处理函数链
补偿策略:
将注册路由句柄数量更多的 child node 摆放在 children 数组更靠前的位置
当子节点越多时,优先级越高,因为更有可能匹配成功,也就是放在越左边,左子树先遍历
gin.context
gin.Context 作为处理 http 请求的通用数据结构,不可避免地会被频繁创建和销毁.
为了缓解 GC 压力,gin 中采用对象池 sync.Pool 进行 Context 的缓存复用
数据结构:
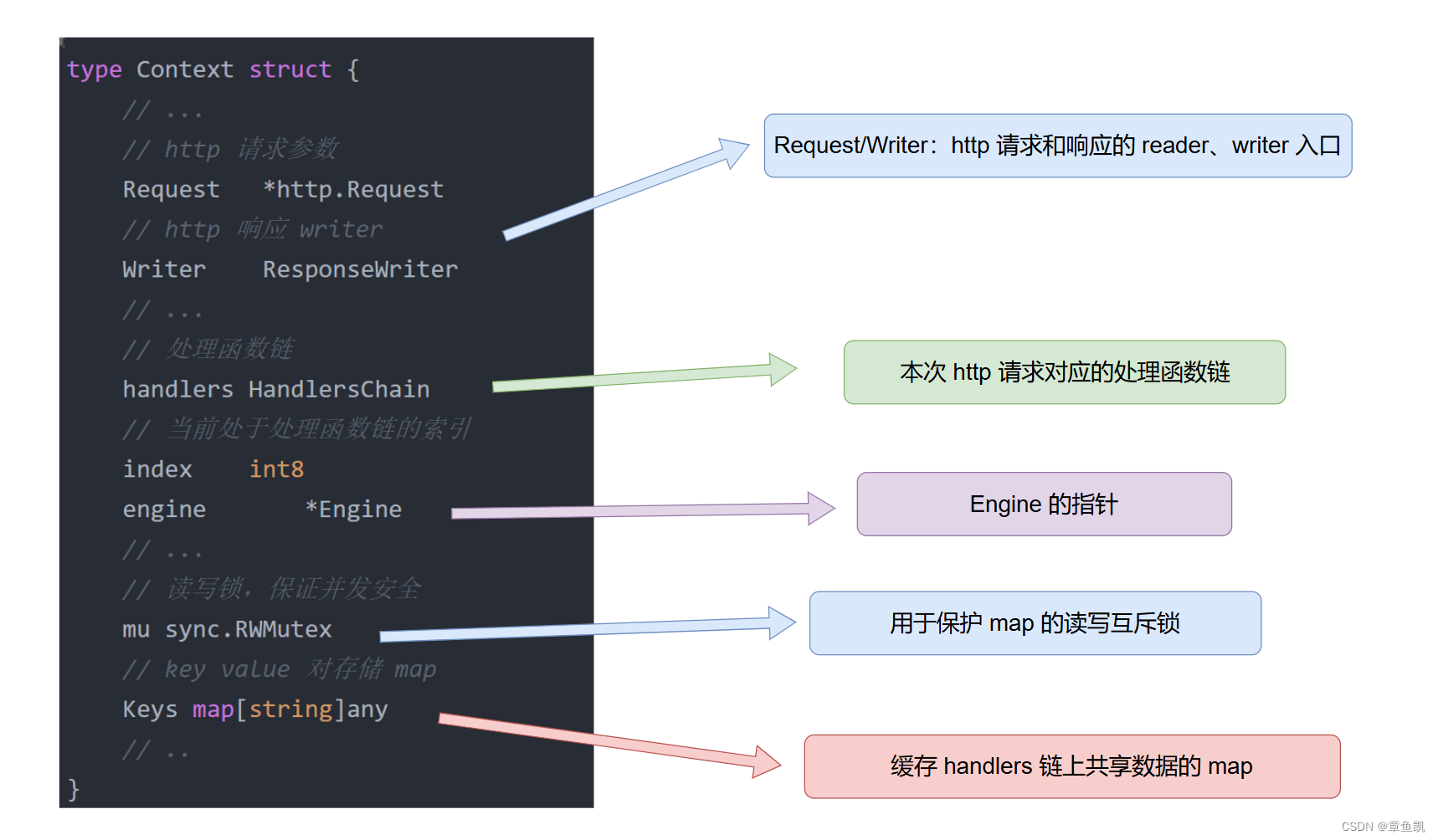
type Context struct {
// ...
// http 请求参数
Request *http.Request
// http 响应 writer
Writer ResponseWriter
// ...
// 处理函数链
handlers HandlersChain
// 当前处于处理函数链的索引
index int8
engine *Engine
// ...
// 读写锁,保证并发安全
mu sync.RWMutex
// key value 对存储 map
Keys map[string]any
// ..
}
处理流程:
http 请求到达时
从 pool 中获取 Context,倘若池子已空,通过 pool.New 方法构造新的 Context 补上空缺
http 请求处理完成后
将 Context 放回 pool 中,用以后续复用
sync.Pool
并不是真正意义上的缓存,将其称为回收站或许更加合适,放入其中的数据
在逻辑意义上都是已经被删除的,但在物理意义上数据是仍然存在的,
这些数据可以存活两轮 GC 的时间,在此期间倘若有被获取的需求,则可以被重新复用.
(两分钟一轮GC)
func New() *Engine {
// ...
engine.pool.New = func() any {
return engine.allocateContext(engine.maxParams)
}
return engine
}
type any = interface{}