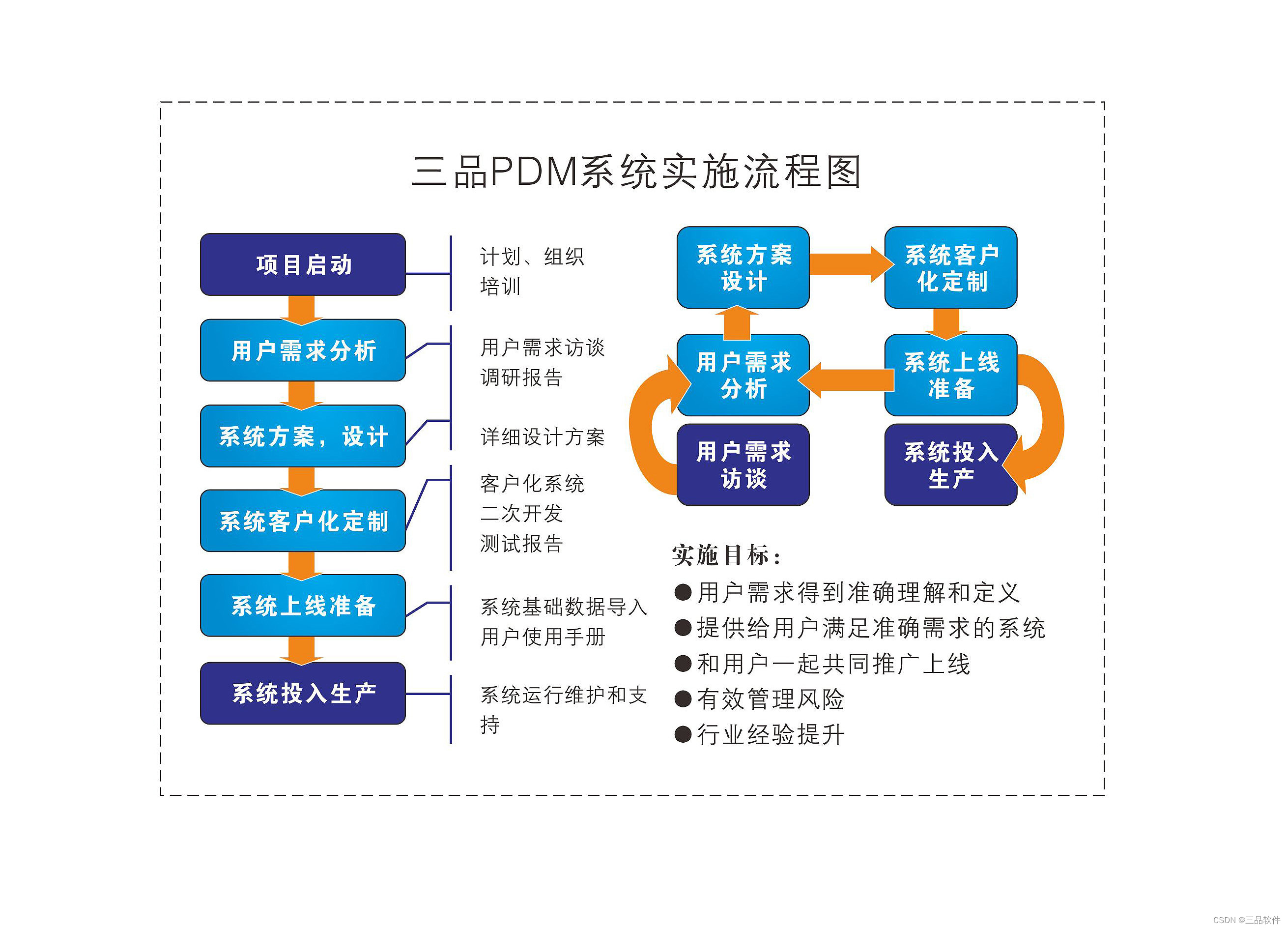
DETR表现出来的问题
- 训练周期很长,相比标准的one-stage/two-stage detection在COCO上 12 epochs就能出好的结果,DETR标配200 epochs.
- 对小目标不友好
- 作者指出,DETR中Transformer的问题是,在初始化的时候,网络几乎是把权重均等地稠密地分配给全图,但是在训练好的DETR中,网络每一个像素对图像上像素的权重分配又是及其稀疏的,这个从均等、稠密的attention到集中、稀疏的Attention情况的过渡过程中,需要大量的训练数据以及大量的训练step. 这就使得整个训练周期很长。
- 这篇Deformable DETR则在全局的关注范围以及稀疏性取得平衡


对于特征图的每一个位置会生成参考点(reference point),并且通过 Query 来生成相应的 sampling offsets,图中的是每一个点会生成三个 offsets 代 表由三个偏移点来计算出这个点的特征值,而这三个偏移点的权重也是由 Query 生成的 (Attention Weights)。从这里看到其中没有涉及矩阵乘法,因 此和 image 的尺寸是成线性关系的。
Focus:
- deformable attention:最核心的地方,在于如何进行可变形注意力的计算
- two-stage & iterative bounding box refinement: 这里讲的是从 encoder 里面出来后的输出的使用,和如何不断在 decoder 中迭代每一个 decoder layer 的输出。
- 首先前者会通过 encoder 得到每个位置的偏移预测和分数,通过分数选出 topk 的 proposal,这里有它们的偏移和 anchor 的位置,肯定也能得到其最终坐标,这个坐标就是进行 decoder 中起始的 anchor 坐标。通过对得到的坐标进行维度的转换得到进入 decoder 的 query 和位置编码。
- 后者 boxes 的迭代可以理解为每个 decoder layer 层对 boxes 进行 refine 送入下一层中作为起始的 anchor 坐标。( 很像 Cascade RCNN 的思路)






![[手机Linux PostmarketOS]一,1加6T真正的手机Linux系统](https://img-blog.csdnimg.cn/direct/d20d2382bc124ab686e4210a0fdd541a.png)