环境安装
studio-conda xtuner0.1.17

conda activate xtuner0.1.17
进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
创建版本文件夹并进入,以跟随本教程
mkdir -p /root/xtuner0117 && cd /root/xtuner0117
拉取 0.1.17 的版本源码
git clone -b v0.1.17 https://github.com/InternLM/xtuner
进入源码目录
cd /root/xtuner0117/xtuner
从源码安装 XTuner
pip install -e ‘.[all]’

前期准备
数据集准备
前半部分是创建一个文件夹,后半部分是进入该文件夹。
mkdir -p /root/ft && cd /root/ft
在ft这个文件夹里再创建一个存放数据的data文件夹
mkdir -p /root/ft/data && cd /root/ft/data
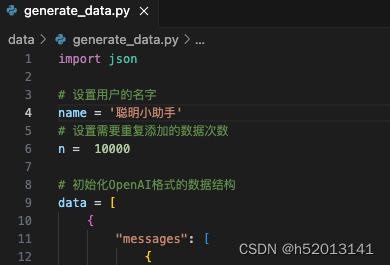
创建 generate_data.py 文件
touch /root/ft/data/generate_data.py
内容为:
import json
# 设置用户的名字
name = '不要姜葱蒜大佬'
# 设置需要重复添加的数据次数
n = 10000
# 初始化OpenAI格式的数据结构
data = [
{
"messages": [
{
"role": "user",
"content": "请做一下自我介绍"
},
{
"role": "assistant",
"content": "我是{}的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦".format(name)
}
]
}
]
# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):
data.append(data[0])
# 将data列表中的数据写入到一个名为'personal_assistant.json'的文件中
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
# 使用json.dump方法将数据以JSON格式写入文件
# ensure_ascii=False 确保中文字符正常显示
# indent=4 使得文件内容格式化,便于阅读
json.dump(data, f, ensure_ascii=False, indent=4)
将对应的name进行修改(在第4行的位置)
name = ‘不要姜葱蒜大佬’
name = “剑锋大佬”
确保先进入该文件夹
cd /root/ft/data
运行代码
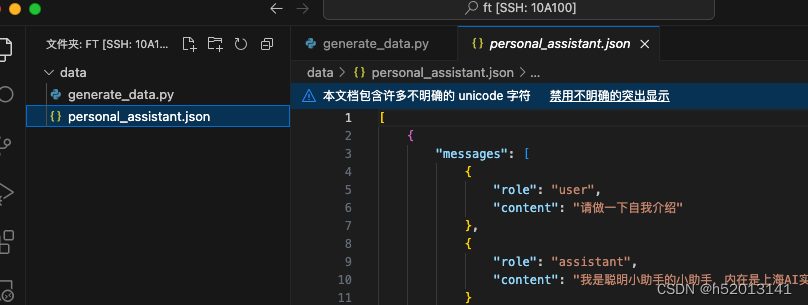
python /root/ft/data/generate_data.py
在data的路径下便生成了一个名为 personal_assistant.json 的文件
模型准备
# 创建目标文件夹,确保它存在。
# -p选项意味着如果上级目录不存在也会一并创建,且如果目标文件夹已存在则不会报错。
mkdir -p /root/ft/model
# 复制内容到目标文件夹。-r选项表示递归复制整个文件夹。
cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/* /root/ft/model/
结果:
配置文件选择
列出所有内置配置文件
xtuner list-cfg
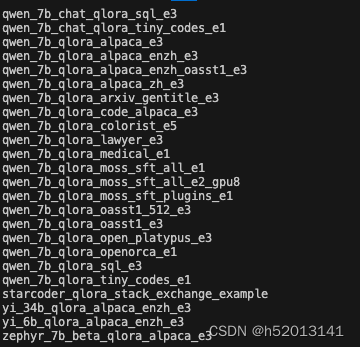
假如我们想找到 internlm2-1.8b 模型里支持的配置文件
xtuner list-cfg -p internlm2_1_8b

创建一个存放 config 文件的文件夹
mkdir -p /root/ft/config
使用 XTuner 中的 copy-cfg 功能将 config 文件复制到指定的位置
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config

小结
我们首先是在 GitHub 上克隆了 XTuner 的源码,并把相关的配套库也通过 pip 的方式进行了安装。
然后我们根据自己想要做的事情,利用脚本准备好了一份关于调教模型认识自己身份弟位的数据集。
再然后我们根据自己的显存及任务情况确定了使用 InternLM2-chat-1.8B 这个模型,并且将其复制到我们的文件夹里。
最后我们在 XTuner 已有的配置文件中,根据微调方法、数据集和模型挑选出最合适的配置文件并复制到我们新建的文件夹中。
配置文件修改
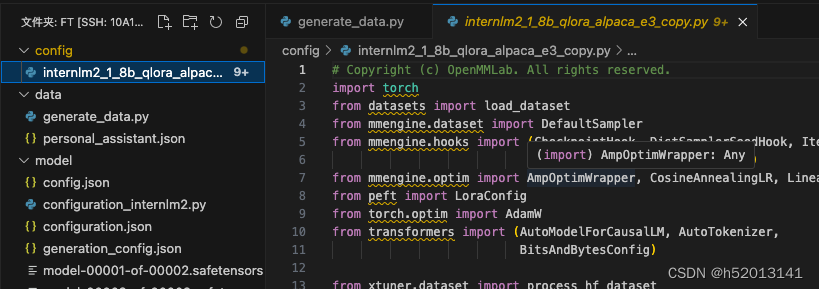
在这里插入代码片# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,
LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import (AutoModelForCausalLM, AutoTokenizer,
BitsAndBytesConfig)
from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import openai_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook, EvaluateChatHook,
VarlenAttnArgsToMessageHubHook)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = '/root/ft/model'
use_varlen_attn = False
# Data
alpaca_en_path = '/root/ft/data/personal_assistant.json'
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = 1024
pack_to_max_length = True
# parallel
sequence_parallel_size = 1
# Scheduler & Optimizer
batch_size = 1 # per_device
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 2
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03
# Save
save_steps = 300
save_total_limit = 3 # Maximum checkpoints to keep (-1 means unlimited)
# Evaluate the generation performance during the training
evaluation_freq = 300
SYSTEM = ''
evaluation_inputs = ['请你介绍一下你自己', '你是谁', '你是我的小助手吗']
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
padding_side='right')
model = dict(
type=SupervisedFinetune,
use_varlen_attn=use_varlen_attn,
llm=dict(
type=AutoModelForCausalLM.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16,
quantization_config=dict(
type=BitsAndBytesConfig,
load_in_4bit=True,
load_in_8bit=False,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4')),
lora=dict(
type=LoraConfig,
r=64,
lora_alpha=16,
lora_dropout=0.1,
bias='none',
task_type='CAUSAL_LM'))
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),
tokenizer=tokenizer,
max_length=max_length,
dataset_map_fn=openai_map_fn,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn)
sampler = SequenceParallelSampler \
if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=alpaca_en,
sampler=dict(type=sampler, shuffle=True),
collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn))
#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(
type=AmpOptimWrapper,
optimizer=dict(
type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),
clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),
accumulative_counts=accumulative_counts,
loss_scale='dynamic',
dtype='float16')
# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [
dict(
type=LinearLR,
start_factor=1e-5,
by_epoch=True,
begin=0,
end=warmup_ratio * max_epochs,
convert_to_iter_based=True),
dict(
type=CosineAnnealingLR,
eta_min=0.0,
by_epoch=True,
begin=warmup_ratio * max_epochs,
end=max_epochs,
convert_to_iter_based=True)
]
# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)
#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [
dict(type=DatasetInfoHook, tokenizer=tokenizer),
dict(
type=EvaluateChatHook,
tokenizer=tokenizer,
every_n_iters=evaluation_freq,
evaluation_inputs=evaluation_inputs,
system=SYSTEM,
prompt_template=prompt_template)
]
if use_varlen_attn:
custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type=IterTimerHook),
# print log every 10 iterations.
logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),
# enable the parameter scheduler.
param_scheduler=dict(type=ParamSchedulerHook),
# save checkpoint per `save_steps`.
checkpoint=dict(
type=CheckpointHook,
by_epoch=False,
interval=save_steps,
max_keep_ckpts=save_total_limit),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type=DistSamplerSeedHook),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend='nccl'),
)
# set visualizer
visualizer = None
# set log level
log_level = 'INFO'
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
# set log processor
log_processor = dict(by_epoch=False)
代码理解:
第一部分:设置
模型和数据: 脚本配置了模型和数据的路径。模型路径指向预训练模型,数据路径指向一个包含训练数据的JSON文件。
并行和优化器配置: 设定了批处理大小、累积次数(用于梯度累积)、学习率等优化器参数。此外,定义了训练的最大周期数和权重衰减。
第二部分:模型与分词器
模型: 使用了一个SupervisedFinetune类型的模型,并可能通过LoRA(低秩适应)技术进行参数高效训练。
分词器: 使用AutoTokenizer从预训练模型路径加载,配置了信任远程代码和右侧填充。
第三部分:数据集与数据加载器
数据集处理: 通过process_hf_dataset处理数据,使用load_dataset从JSON文件中加载数据。
数据加载器: 根据是否使用序列并行来选择采样器,并配置了批处理大小和工作线程数。
第四部分:调度器与优化器
优化器: 使用AmpOptimWrapper封装了AdamW优化器,进行了梯度剪辑和动态损失缩放。
学习策略: 利用线性学习率预热和余弦退火策略来调整学习率。
第五部分:运行时设置
日志和钩子: 配置了各种钩子来处理日志记录、性能评估和模型保存等。
环境配置: 包括是否启用cudnn的基准测试、多进程启动方法和分布式后端的设置。
日志级别和随机性: 设置了日志级别和是否使用随机种子。
模型训练
指定保存路径
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train
使用 deepspeed 来加速训练
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2
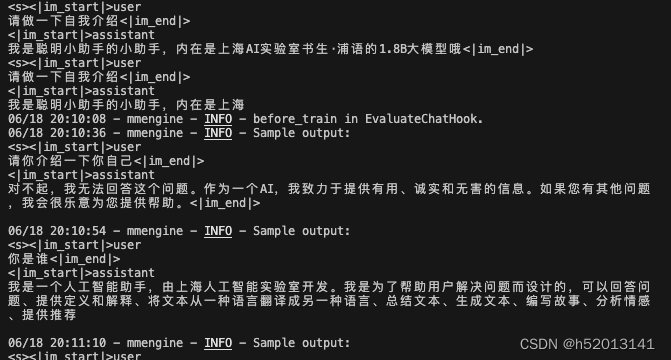
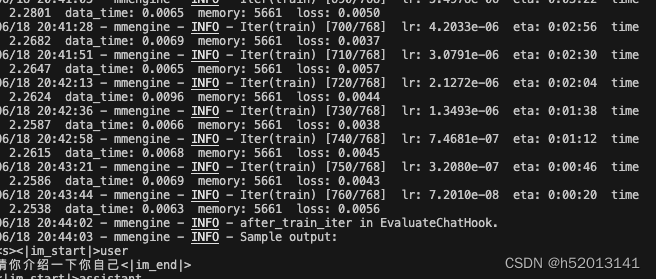
训练完成,展示loss
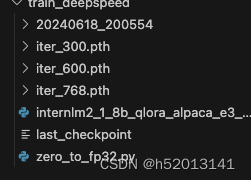
模型转换、整合、测试及部署
模型转换
创建一个保存转换后 Huggingface 格式的文件夹
mkdir -p /root/ft/huggingface
模型转换
xtuner convert pth_to_hf ${配置文件地址} ${权重文件地址} ${转换后模型保存地址}
xtuner convert pth_to_hf /root/ft/train_deepspeed/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train_deepspeed/iter_768.pth /root/ft/huggingface
转换为bin文件
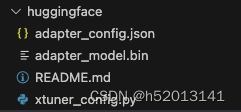
模型整合
创建一个名为 final_model 的文件夹存储整合后的模型文件
mkdir -p /root/ft/final_model
解决一下线程冲突的 Bug
export MKL_SERVICE_FORCE_INTEL=1
进行模型整合
xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH}
xtuner convert merge /root/ft/model /root/ft/huggingface /root/ft/final_model
–max-shard-size {GB} 代表每个权重文件最大的大小(默认为2GB)
–device {device_name} 这里指的就是device的名称,可选择的有cuda、cpu和auto,默认为cuda即使用gpu进行运算
–is-clip 这个参数主要用于确定模型是不是CLIP模型,假如是的话就要加上,不是就不需要添加
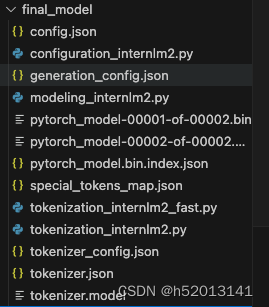
对话测试
与模型进行对话
xtuner chat /root/ft/final_model --prompt-template internlm2_chat
同样的我们也可以和原模型进行对话进行对比
xtuner chat /root/ft/model --prompt-template internlm2_chat
使用 --adapter 参数与完整的模型进行对话
xtuner chat /root/ft/model --adapter /root/ft/huggingface --prompt-template internlm2_chat
对话记录

Web demo 部署
pip install streamlit==1.24.0
创建存放 InternLM 文件的代码
mkdir -p /root/ft/web_demo && cd /root/ft/web_demo
拉取 InternLM 源文件
git clone https://github.com/InternLM/InternLM.git
进入该库中
cd /root/ft/web_demo/InternLM
"""This script refers to the dialogue example of streamlit, the interactive
generation code of chatglm2 and transformers.
We mainly modified part of the code logic to adapt to the
generation of our model.
Please refer to these links below for more information:
1. streamlit chat example:
https://docs.streamlit.io/knowledge-base/tutorials/build-conversational-apps
2. chatglm2:
https://github.com/THUDM/ChatGLM2-6B
3. transformers:
https://github.com/huggingface/transformers
Please run with the command `streamlit run path/to/web_demo.py
--server.address=0.0.0.0 --server.port 7860`.
Using `python path/to/web_demo.py` may cause unknown problems.
"""
# isort: skip_file
import copy
import warnings
from dataclasses import asdict, dataclass
from typing import Callable, List, Optional
import streamlit as st
import torch
from torch import nn
from transformers.generation.utils import (LogitsProcessorList,
StoppingCriteriaList)
from transformers.utils import logging
from transformers import AutoTokenizer, AutoModelForCausalLM # isort: skip
logger = logging.get_logger(__name__)
@dataclass
class GenerationConfig:
# this config is used for chat to provide more diversity
max_length: int = 2048
top_p: float = 0.75
temperature: float = 0.1
do_sample: bool = True
repetition_penalty: float = 1.000
@torch.inference_mode()
def generate_interactive(
model,
tokenizer,
prompt,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor],
List[int]]] = None,
additional_eos_token_id: Optional[int] = None,
**kwargs,
):
inputs = tokenizer([prompt], padding=True, return_tensors='pt')
input_length = len(inputs['input_ids'][0])
for k, v in inputs.items():
inputs[k] = v.cuda()
input_ids = inputs['input_ids']
_, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
if generation_config is None:
generation_config = model.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs)
bos_token_id, eos_token_id = ( # noqa: F841 # pylint: disable=W0612
generation_config.bos_token_id,
generation_config.eos_token_id,
)
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
if additional_eos_token_id is not None:
eos_token_id.append(additional_eos_token_id)
has_default_max_length = kwargs.get(
'max_length') is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None:
warnings.warn(
f"Using 'max_length''s default ({repr(generation_config.max_length)}) \
to control the generation length. "
'This behaviour is deprecated and will be removed from the \
config in v5 of Transformers -- we'
' recommend using `max_new_tokens` to control the maximum \
length of the generation.',
UserWarning,
)
elif generation_config.max_new_tokens is not None:
generation_config.max_length = generation_config.max_new_tokens + \
input_ids_seq_length
if not has_default_max_length:
logger.warn( # pylint: disable=W4902
f"Both 'max_new_tokens' (={generation_config.max_new_tokens}) "
f"and 'max_length'(={generation_config.max_length}) seem to "
"have been set. 'max_new_tokens' will take precedence. "
'Please refer to the documentation for more information. '
'(https://huggingface.co/docs/transformers/main/'
'en/main_classes/text_generation)',
UserWarning,
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = 'input_ids'
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, "
f"but 'max_length' is set to {generation_config.max_length}. "
'This can lead to unexpected behavior. You should consider'
" increasing 'max_new_tokens'.")
# 2. Set generation parameters if not already defined
logits_processor = logits_processor if logits_processor is not None \
else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None \
else StoppingCriteriaList()
logits_processor = model._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
encoder_input_ids=input_ids,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
)
stopping_criteria = model._get_stopping_criteria(
generation_config=generation_config,
stopping_criteria=stopping_criteria)
logits_warper = model._get_logits_warper(generation_config)
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
scores = None
while True:
model_inputs = model.prepare_inputs_for_generation(
input_ids, **model_kwargs)
# forward pass to get next token
outputs = model(
**model_inputs,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
if generation_config.do_sample:
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(probs, dim=-1)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = model._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=False)
unfinished_sequences = unfinished_sequences.mul(
(min(next_tokens != i for i in eos_token_id)).long())
output_token_ids = input_ids[0].cpu().tolist()
output_token_ids = output_token_ids[input_length:]
for each_eos_token_id in eos_token_id:
if output_token_ids[-1] == each_eos_token_id:
output_token_ids = output_token_ids[:-1]
response = tokenizer.decode(output_token_ids)
yield response
# stop when each sentence is finished
# or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(
input_ids, scores):
break
def on_btn_click():
del st.session_state.messages
@st.cache_resource
def load_model():
model = (AutoModelForCausalLM.from_pretrained('/root/ft/final_model',
trust_remote_code=True).to(
torch.bfloat16).cuda())
tokenizer = AutoTokenizer.from_pretrained('/root/ft/final_model',
trust_remote_code=True)
return model, tokenizer
def prepare_generation_config():
with st.sidebar:
max_length = st.slider('Max Length',
min_value=8,
max_value=32768,
value=2048)
top_p = st.slider('Top P', 0.0, 1.0, 0.75, step=0.01)
temperature = st.slider('Temperature', 0.0, 1.0, 0.1, step=0.01)
st.button('Clear Chat History', on_click=on_btn_click)
generation_config = GenerationConfig(max_length=max_length,
top_p=top_p,
temperature=temperature)
return generation_config
user_prompt = '<|im_start|>user\n{user}<|im_end|>\n'
robot_prompt = '<|im_start|>assistant\n{robot}<|im_end|>\n'
cur_query_prompt = '<|im_start|>user\n{user}<|im_end|>\n\
<|im_start|>assistant\n'
def combine_history(prompt):
messages = st.session_state.messages
meta_instruction = ('')
total_prompt = f"<s><|im_start|>system\n{meta_instruction}<|im_end|>\n"
for message in messages:
cur_content = message['content']
if message['role'] == 'user':
cur_prompt = user_prompt.format(user=cur_content)
elif message['role'] == 'robot':
cur_prompt = robot_prompt.format(robot=cur_content)
else:
raise RuntimeError
total_prompt += cur_prompt
total_prompt = total_prompt + cur_query_prompt.format(user=prompt)
return total_prompt
def main():
# torch.cuda.empty_cache()
print('load model begin.')
model, tokenizer = load_model()
print('load model end.')
st.title('InternLM2-Chat-1.8B')
generation_config = prepare_generation_config()
# Initialize chat history
if 'messages' not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message['role'], avatar=message.get('avatar')):
st.markdown(message['content'])
# Accept user input
if prompt := st.chat_input('What is up?'):
# Display user message in chat message container
with st.chat_message('user'):
st.markdown(prompt)
real_prompt = combine_history(prompt)
# Add user message to chat history
st.session_state.messages.append({
'role': 'user',
'content': prompt,
})
with st.chat_message('robot'):
message_placeholder = st.empty()
for cur_response in generate_interactive(
model=model,
tokenizer=tokenizer,
prompt=real_prompt,
additional_eos_token_id=92542,
**asdict(generation_config),
):
# Display robot response in chat message container
message_placeholder.markdown(cur_response + '▌')
message_placeholder.markdown(cur_response)
# Add robot response to chat history
st.session_state.messages.append({
'role': 'robot',
'content': cur_response, # pylint: disable=undefined-loop-variable
})
torch.cuda.empty_cache()
if __name__ == '__main__':
main()
从本地使用 ssh 连接 studio 端口
将下方端口号 38374 替换成自己的端口号
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 38374
streamlit run /root/ft/web_demo/InternLM/chat/web_demo.py --server.address 127.0.0.1 --server.port 6006
打开 http://127.0.0.1:6006 后,等待加载完成即可进行对话,键入内容示例如下:
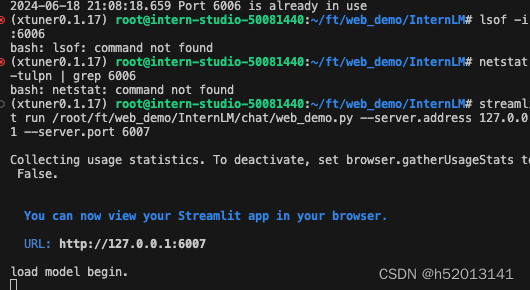
请介绍一下你自己
可以看到过拟和了
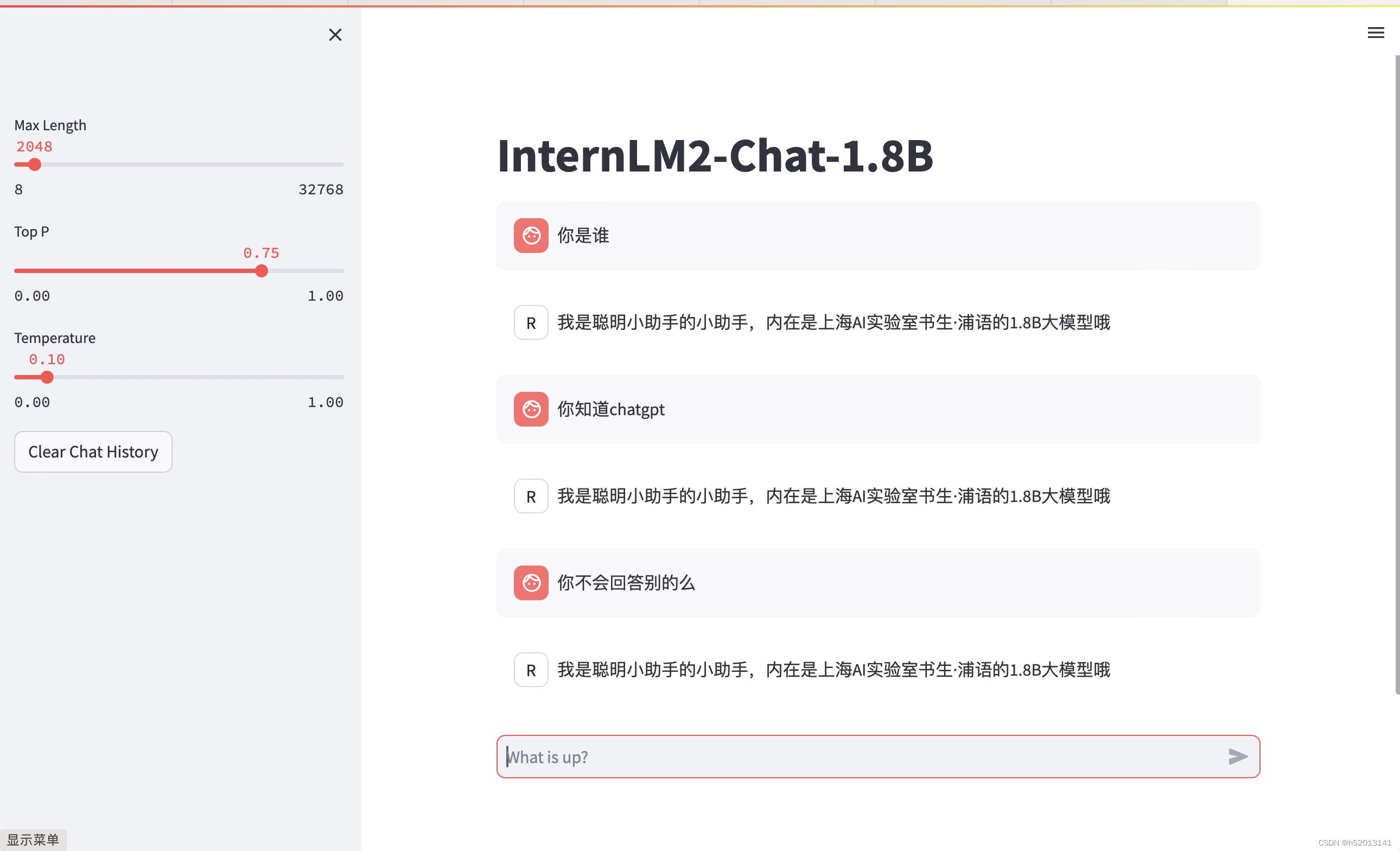
正常模型对话