对以下路径中的文件名批量修改。

一、读取指定路径中的文件名
#导入标准库
import os
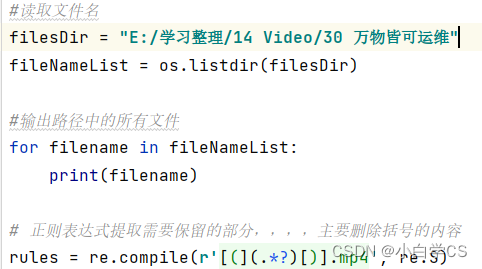
#读取文件名
filesDir = "路径……"
fileNameList = os.listdir(filesDir)
#输出路径中的所有文件
for filename in fileNameList:
print(filename)

二、正则表达式提取需要保留的部分
1、介绍re库
这里需要导入re库,re库主要是Python的标准库,主要用于字符串匹配。
Re库主要函数
| 函数名称 | 作用 | 返回类型 |
| re.findall() | 搜索并返回所有能匹配到的子串 | 列表类型 |
| re.match() | 从字符串的开头进行匹配 | match对象 |
| re.search() | 搜索匹配到的第一个位置 | match对象 |
| re.split() | 将字符串按匹配结果进行分割 | 列表类型 |
| re.finditer() | 搜索返回匹配结果的迭代类型 | match对象 |
| re.sub() | 在字符串中替换所有匹配正则表达式的子串 ,返回替换后的字符串 | 字符串 |
2、re库中函数的用法
(1)re.findall() #最常用
第一个参数为匹配的正则表达式,第二个参数为要搜索的字符串。
import re
#搜索所有的五位数字
ls = re.findall(r'[1-9]\d{5}','BIT100081 TUS444567')
print(ls)
['100081', '444567']
(2)re.sub(pattern,repl,string,count)
| 参数 | 作用 |
| pattern | 正则表达式 |
| repl | 替换匹配字符串的字符串 |
| string | 匹配字符串 |
| count | 最大替换次数 |
re库的具体用法,读者自己探索,由于字符串的复杂程度不同,正则表达式的用法不同。详情可以仔细研究官网或者菜鸟教程:Python3 正则表达式 。
3、例子说明
-
以本例子说明,这几个文件名的相同部分,都有括号,所以先写匹配括号的正则表达式。
-
re库中compile方法 可以返回一个正则表达式的截取规则。其中(.*?)表示任意字符出现任意次。
# 正则表达式提取需要保留的部分,,,,主要匹配删除括号的内容
rules = re.compile(r'[(](.*?)[)]', re.S)
- 这样就把括号以及括号中的内容删除掉了。

- 要记住compile里传进去的一定是一个字符串,前面 r 是防止转义字符。测试一下是否匹配,避免出现错误。
# 正则表达式提取需要保留的部分,,,,主要匹配删除括号的内容
rules = re.compile(r'[(](.*?)[)]', re.S)
#开始数组循环更改文件名
for filename in fileNameList:
print("旧的名字是:\t"+filename)
print("开始截取!")
newFilename = re.sub(rules,'',str(filename))
#输出保留的内容
print("新名字是:\t"+newFilename)
print("\n\n")

三、正式更改文件名
1、用 os库里的rename方法
os.rename(os.path.join(filesDir, filename), os.path.join(filesDir, newFilename))
2、测试是否正确
注: 不同的文件名,有不同的使用正则表达式的方式,还是具体问题具体分析。
#开始数组循环更改文件名
for filename in fileNameList:
print("旧的名字是:\t"+filename)
print("开始截取!")
newFilename = re.sub(rules,'',str(filename))
#输出保留的内容
print("新名字是:\t"+newFilename)
print("开始改名。。。")
os.rename(os.path.join(filesDir, filename), os.path.join(filesDir, newFilename))
print("改名完毕!")
print("======================================================================================")


3、其他的匹配情况
(1)匹配文件名序号
#删除重复的文件名序号
rules = re.compile(r'^\d', re.S)
-
如果文件名有两个序号,并且重复,即可使用此功能,像此案例就不可以使用,因为两个序号不相同。
-
如果文件不超过0-9,运行一次即可;但是超过10-99,可以在运行一次;如果序号为三位,可以运行第三次。
-
\d 等价于 [0-9]。
(2)匹配特殊字符
#删除文件名前的特殊字符,如果是"."删除".",如果是"#"删除"#"
rules = re.compile(r'^\.', re.S)
- 注: 匹配的时候要注意,这个特殊符号所在的位置;如果在开头,要按添加 ^ 符号;如果在其他位置,则要注意,如果删除的是点 . ,后缀名中的点也要注意。这时就要一开始删除后缀名,在完成更改时再添加上指定的后缀名。
(3)删除字符串中的指定的部分
# 正则表达式删除指定的的部分
rules = re.compile(r'Swagger-[0-9][0-9]:', re.S)
- 注: 正则表达式里指定的部分,建议复制粘贴,避免中间空格。
(4)最后一步添加后缀名
# 可以为文件名添加后缀,,,本质为在最后匹配的字符串最后增加一个部分,可以为数字,也可以为文件后缀
newFilename = newFilename + ".mp4"

四、完整代码
import os
import re
#读取文件名
filesDir = "E:/学习整理/14 Video/30 万物皆可运维"
fileNameList = os.listdir(filesDir)
#输出路径中的所有文件
for filename in fileNameList:
print(filename)
# 正则表达式提取需要保留的部分,,,,主要匹配删除括号的内容
rules = re.compile(r'[(](.*?)[)]', re.S)
# 正则表达式删除指定的的部分
# rules = re.compile(r'Swagger-[0-9][0-9]:', re.S)
#删除重复的文件名序号
# rules = re.compile(r'^\d', re.S)
#删除文件名前的特殊字符,如果是"."删除".",如果是"#"删除"#"
# rules = re.compile(r'^\.', re.S)
#开始数组循环更改文件名
for filename in fileNameList:
print("旧的名字是:\t"+filename)
print("开始截取!")
newFilename = re.sub(rules,'',str(filename))
#输出保留的内容
print("新名字是:\t"+newFilename)
print("开始改名。。。")
# 可以为文件名添加后缀,,,本质为在最后匹配的字符串最后增加一个部分,可以为数字,也可以为文件后缀
# newFilename = newFilename + ".mp4"
os.rename(os.path.join(filesDir, filename), os.path.join(filesDir, newFilename))
print("改名完毕!")
print("======================================================================================")
![[Vulnhub] DC-6](https://img-blog.csdnimg.cn/3f4bd925960e4cde9ab0af95b3b94f58.png)