深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
此专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
从RNN到Attention到Transformer系列
专栏链接:
https://blog.csdn.net/qq_39707285/category_11814303.html
此专栏主要介绍RNN、LSTM、Attention、Transformer及其代码实现。
本章目录
- 1. Encoder
- 2. Attention
- 3. Decoder
- 4. 整体过程图解
Attention相关详细介绍及其代码实现见文章《从RNN到Attention到Transformer系列-Attention介绍及代码实现》-https://blog.csdn.net/qq_39707285/article/details/124732447
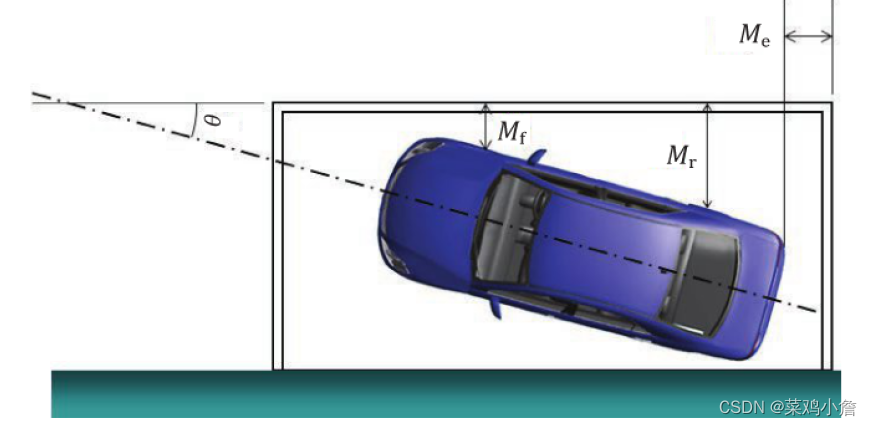
本文以实现翻译为例。假如batchsize=8,第一个batchsize内最大输入单词数为17,最大输出单词数为15(每个batchsize内的最大输入长度根据相应情况变动)。输入词典总数7853(德语),输出词典总数5893(英语)。
编码器输入size=256,隐藏层size=512,双向GPU
解码器输入size=256,隐藏层size=512,单向GPU
1. Encoder
- one-hot
输入一个batch的原句,进行one-hot转换,如下所示:

第一个batchsize内的输入单词的one-hot表示,如下所示:

shape大小为(17×8),第一行的2代表<sos>,最后一行的1代表<eos>,每一列代表一句话。
-
词向量编码-(nn.Embedding(7853,256))
把原句进行词向量编码,如下:

-
GRU
编码后的词向量输入到GRU中,输出outputs和hidden。

GRU具体运行过程如下:

第一个输入为<sos>,最后一个输入为<eos>,由于是双向GPU,所以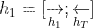
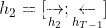
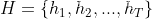 ,shape为(17×8×1024),
,shape为(17×8×1024),
h n h_n hn是最后一个输出,双向所以有两个,shape为(2×8×512) -
初始化解码器隐藏层状态 s 0 s_0 s0
由于解码器不是双向的,因此只需要一个上下文向量:

s 0 = h n s_0=h_n s0=hn,shape为(8×512)。 -
整体过程

或者

2. Attention
- 计算先前解码器隐藏状态和编码器隐藏状态之间的energy

更形象的图解如下,相当于去计算每个编码器隐藏状态与先前解码器隐藏状态 s 0 s_0 s0的“匹配”程度。

- 计算attention
每个batch中每个example的Et维度是 [dec hid dim, src len],我们希望批处理中的每个示例都是 [src len],因为注意力应该放在源句子的长度上。这是通过将乘以 v=[1, dec hid dim] 张量来实现的:

把v当为所有编码器隐藏状态的能量加权总和的权重。这些权重告诉我们应该关注源序列中的每个令牌的程度。参数v是随机初始化的,但通过反向传播与模型的其余部分一起学习。注意如何v不依赖于时间,并且相同v用于解码的每个时间步长。这里v使用没有偏差的线性层。
最后,确保注意力向量符合使所有元素在 0 和 1 之间以及向量求和为 1 的约束,使用softmax层。

- 整体过程

或者:

3. Decoder
-
加权源向量w


图中outputs是编码器的输出结果。 -
one-hot
把目标句进行词向量编码,如下:

第一个batchsize内的输入单词的one-hot表示,如下所示:

shape大小为(15×8),第一行的2代表<sos>,最后一行的1代表<eos>,每一列代表一句话。
- 词向量编码-(nn.Embedding(5893,256))
把原句进行词向量编码,如下:

- GRU
编码后的词向量一个一个输入到GRU中,输出output和hidden,首先输入第一个时, s 0 = h n s_0=h_n s0=hn,输入编码后的target和加权源向量wt,如下:

第一个target为<sos>。

- 第一个输出
使用编码后的target,wt和st通过线性层f,以预测目标句子中的下一个单词。这是通过将它们连接在一起来完成的。

- 使用 s 1 s_1 s1更新w和a
不断更新w和a,直到最后一个输入<eos>。

- 整体过程
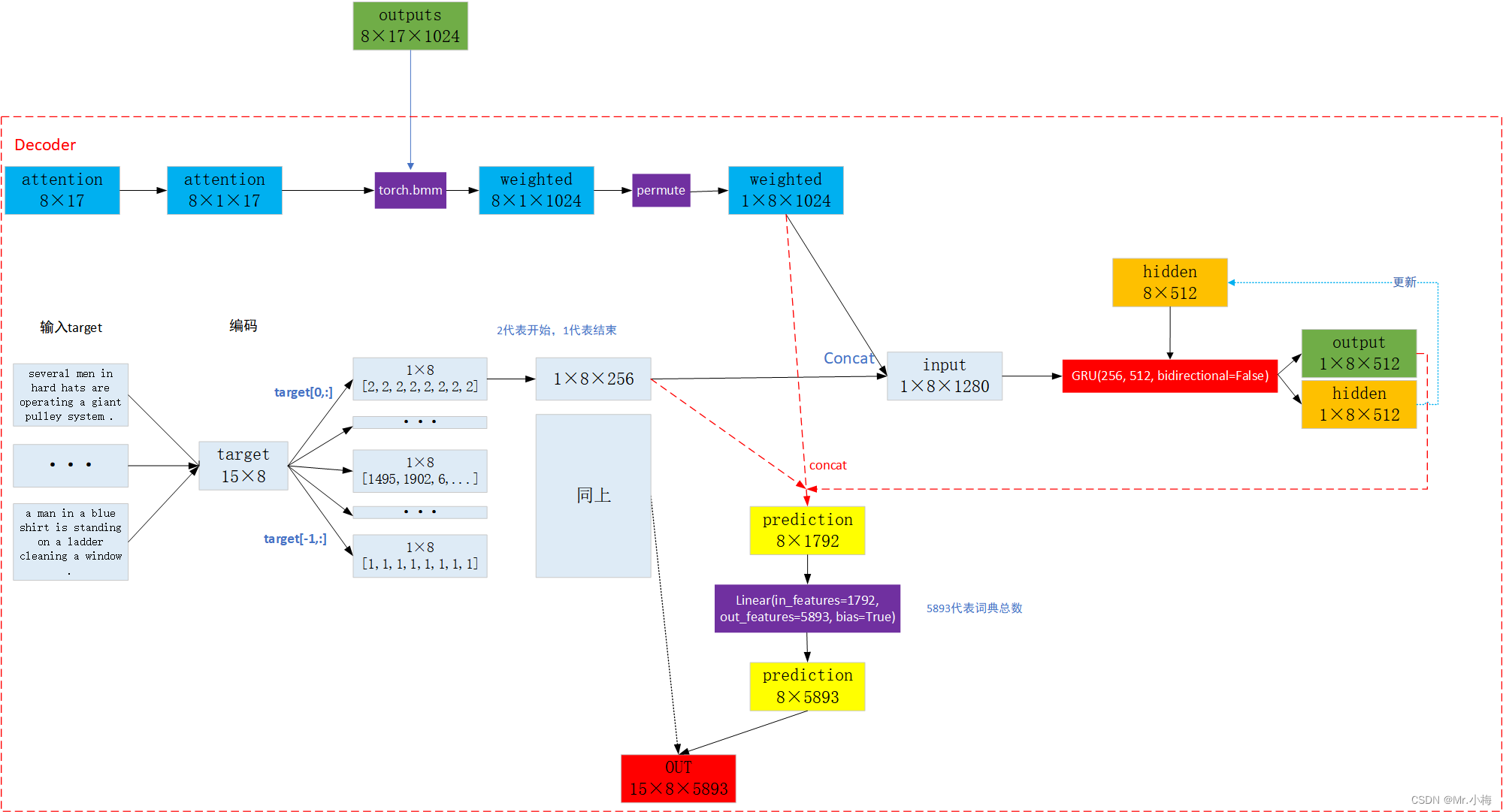
4. 整体过程图解

或者: