在过去的两周里,ChatGPT的热度居高不下,引发全网讨论。虽然AlphaGo这类AI产品也曾引起热议,但是在应用层面终究还是离用户太远了。而ChatGPT更像是「民用级」的产品,真正意义上让AI技术跨入广泛破圈应用时代。在当下,机器学习和深度学习的上云已经成为众多企业的选择,不再为算力所累,释放生产力,亚马逊云科技能够以强大的云计算底座为模型训练供能。
大模型的训练和应用门槛亟需降低
ChatGPT相比以往的对话机器人之所以“聪明”,是因为摄入了数以亿计的语料库内容,而如此规模的大模型的训练和应用成本极高,绝大部分企业都无法承担,但我们看到越来越多的大模型走向了开源,并允许用户在此基础上进行低成本的微调,以更加适配最终用户的业务场景。如何获取这些大模型,并快速进行部署和微调,是真正落地大模型应用需要考虑的问题。
Amazon SageMaker JumpStart简单明了地回答了这个问题,JumpStart提供了超过350个来自TensorFlow、PyTorch、Hugging Face以及MXNet等广受欢迎的模型中心所提供的最先进的预训练模型、内置算法以及预置解决方案模板,能为对象检测、文本分类和文本生成等流行的ML任务提供支持。
在re:Invent 2022上,亚马逊云科技宣布将来自Stability.AI的用于AI作画的Stable Diffusion模型和超大自然语言处理模型Bloom集成到SageMaker JumpStart,用户仅需点点鼠标,即可完成模型的部署和微调,极大地降低了大模型应用的门槛。
大模型训练和推理,更需高性能芯片助力
ChatGPT不仅需要巨量数据源“投喂”训练模型,而且也需要强有力的算力与芯片支持,而这些都需要巨量的成本。即便是在技术水平相当理想的情况下,成本问题也很惊人。
事实上对于很多个人学习者和初创公司来说,成本都是绕不开的问题。个人学习者其实很难不因为传统云的价格而感到吃力,但是亚马逊云科技对这类问题则有了更好的解决方案。
亚马逊云科技推出了基于Amazon Trainium自研芯片的Amazon EC2 Trn1实例的高性价比解决方案,与基于GPU的同类实例相比,Trn1可节省高达50%的训练成本,不管是从缩短时间、快速迭代模型,还是提升训练准确率维度来说,都可以助力ChatGPT这类AIGC应用降本增效,表现更出众。
值得一提的是,使用Trn1实例无需最低消费承诺或预付费用,只需为使用的计算量付费,计费方式十分合理。像是Stable Diffusion模型的母公司Stability AI就在使用Trn1进行模型训练,持续提升生产效能。
对于大模型的推理,由第二代Amazon Inferentia加速器支撑的Amazon EC2 Inf2实例。与第一代Inf1实例相比,Inf2实例的计算性能提高了3倍,加速器内存提高了4倍,吞吐量提高了4倍,延迟降低了10倍。Inf2实例经过优化,可以大规模部署日益复杂的模型,例如大型语言模型(LLM)等,其通过加速器之间的超高速连接可支持横向扩展分布式推理,即使是大如175B参数模型也可以方便部署并提升高速推理。
基于NLP大模型的服务并非仅有ChatGPT
像ChatGPT这种基于NLP大模型的服务,亚马逊云科技也拥有多种AI服务。
事实上,NLP大模型的落地是很难的,因为它们普遍需要高效的分布式大模型训练和快速的在线推理服务才能够落地,所以对于绝大多数公司来说,不管是从人力成本还是其他层面上来说,都存在一定的阻碍。亚马逊云科技凭借多年云业务经验,可以在多条业务线上齐头并进,协同合作伙伴快速展开生态化创新。
当业界谈论ChatGPT时,讨论的往往是大模型与大数据创新、强悍的机器学习能力。而亚马逊云科技与ChatGPT在迈向未来探索之路殊途同归,创新落点都是AI技术、机器学习、云技术的体系化深入探索。当技术真正作用于人、真正地赋能千行百业一线场景,产生高质量、高效能后,便能真正触及到崭新的科技边界,而这也是亚马逊云科技的愿景所在。







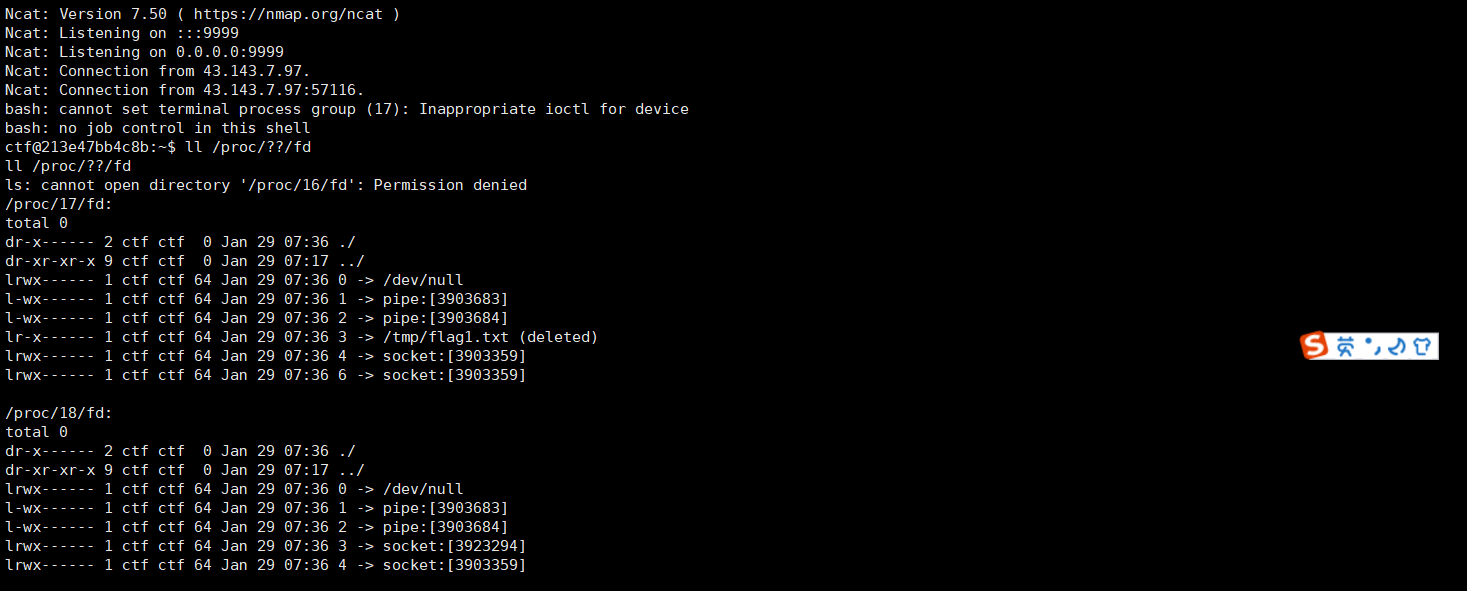
![[Vulnhub] DC-5](https://img-blog.csdnimg.cn/edaa14e2a12a40658c833ae9120fea94.png)