一、正排索引
Lucene的基础层次结构由索引、段、文档、域、词五个部分组成。正向索引的生成即为基于Lucene的基础层次结构一级一级处理文档并分解域存储词的过程。
索引文件层级关系如图1所示:
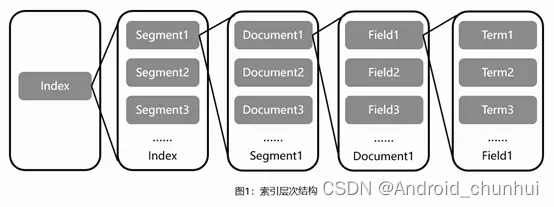
索引:Lucene索引库包含了搜索文本的所有内容,可以通过文件或文件流的方式存储在不同的数据库或文件目录下。
段:一个索引中包含多个段,段与段之间相互独立。由于Lucene进行关键词检索时需要加载索引段进行下一步搜索,如果索引段较多会增加较大的I/O开销,减慢检索速度,因此写入时会通过段合并策略对不同的段进行合并。
文档:Lucene会将文档写入段中,一个段中包含多个文档。
域:一篇文档会包含多种不同的字段,不同的字段保存在不同的域中。
词:Lucene会通过分词器将域中的字符串通过词法分析和语言处理后拆分成词,Lucene通过这些关键词进行全文检索。
二、倒排索引
词到文档ID的映射。包括term Dictionary 和Posting List两部分。
1、Term Dictionary
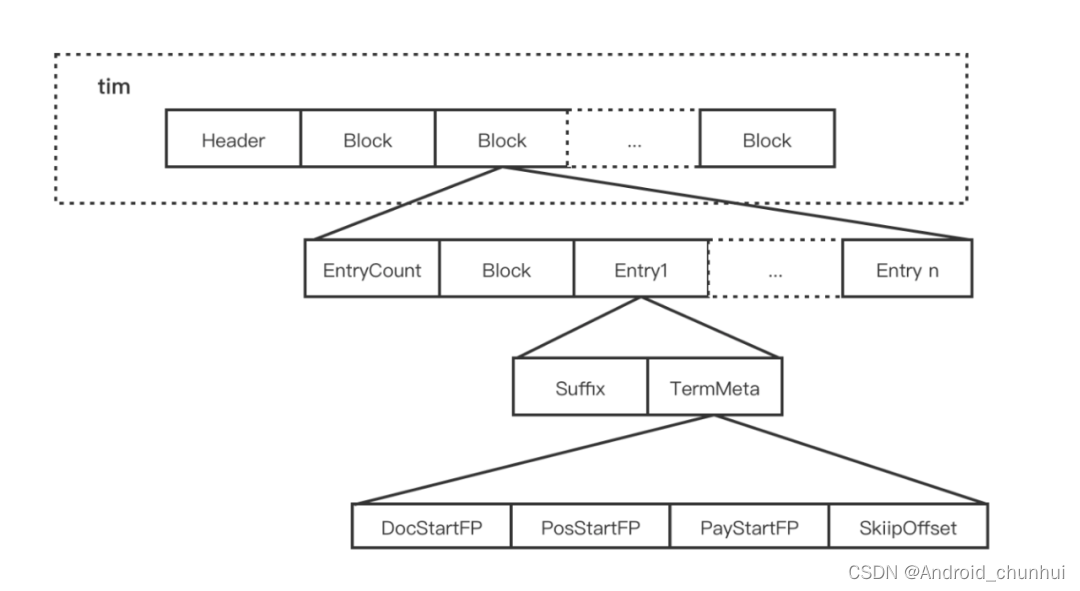
Term Dictionary 分为.tim, tip文件存储。 .tim 文件,其内部采用 NodeBlock 对 Term 进行压缩前缀存储,处理过程会将相同前缀的的 Term 压缩为一个 NodeBlock,NodeBlock 会存储公共前缀,然后将每个 Term 的后缀以及对应 Term 的 Posting 关联信息处理为一个 Entry 保存到 Block。
搜索词典巨大,用map存储无法一次性加载到内存里,因此使用FST对tim文件创建索引。
FST(Finite StateTransducers),中文名有限状态机转换器。其主要特点在于以下四点:
- 查找词的时间复杂度为O(len(str));
- 通过将前缀和后缀分开存储的方式,减少了存放词所需的空间;
- 加载时仅将前缀放入内存索引,后缀词在磁盘中进行存放,减少了内存索引使用空间的损耗;
- FST结构在对PrefixQuery、FuzzyQuery、RegexpQuery等查询条件查询时,查询效率高。
具体存储方式如图3所示:
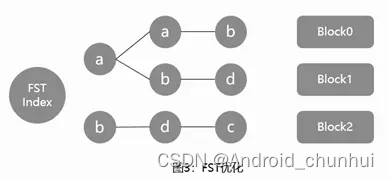
倒排索引相关文件包含.tip、.tim和.doc这三个文件,其中:
tip:用于保存倒排索引Term的前缀,来快速定位.tim文件中属于这个Field的Term的位置,即上图中的aab、abd、bdc。
tim:保存了不同前缀对应的相应的Term及相应的倒排表信息,倒排表通过跳表实现快速查找,通过跳表能够跳过一些元素的方式对多条件查询交集、并集、差集之类的集合运算也提高了性能。
doc:包含了文档号及词频信息,根据倒排表中的内容返回该文件中保存的文本信息。
2、Posting List
2.1、索引构建期间
Field被分词后变成一系列Terms的集合,而后遍历这个Terms的集合,为每个Term分配一个ID,叫TermID。Lucene用一个类HashMap的数据结构来存储Term与TermID的映射关系,同时实现去重的目的。分配完TermID之后,后续就可以使用TermID来表示Term。
在Postings构建过程中,会在PostingsArrays存储上个文档的(DocID, TermFreq),还有Term上次出现的位置(Postion,Offset, Payload)信息。PostingsArrays由几个int[]组成,其下标即为TermID(TermID是连续分配的整型数,所以PostingsArrays是紧凑的),对应的值便是记录TermID上一次出现的相关信息。

- lastPostion/lastOffset/lastDocId:term在上个文档的倒排信息。
- textStarts:用来记录Term词面在CharBlockPool中的起始位置。(早期版本term存储在ByteBlockPool后来单独放到CharBlockPool)。
- intStarts:用来记录拉链当前doc在IntBlockPool中的记录位置。
- byteStarts:用来记录拉链表头在ByteBlockPool中的起始位置。
term有两条倒排拉链,节点叫做Slice,一条存储[docId, termFreq],一条存储[pos,offset,payload],分成两条是因为Lucene这两种信息的构建是可选的,可以选择不构建[pos,offset,payload]信息。如下图,根据intStarts知道doc信息在intPool中的存储位置,进而知道在BytePool中的存储起始位置,两种Slice数据[docId, termFreq]和[pos,offset,payload]相邻存放,且大小固定的。可以看到,term的每个doc信息在ByteBlockPool中时分散存储的,但是Slice中有指向下一节点的指针,flush磁盘时byteStarts记录了拉链头结点位置,intStarts对应的IntPool数据记录了拉链尾结点位置,因此可以从ByteBlockPool中获取整条链表。
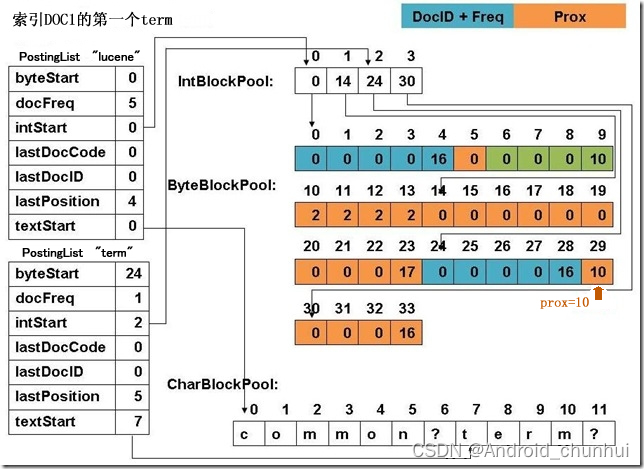
为什么在PostingArray里记录上个doc的信息呢,比如lastPostion/lastOffset/lastDocId?
因为可以做差值存储,节省存储空间。
构建过程中每个Term拉链的长度都是不确定的,因此需要用链表来存储拉链。构建中Term到来的顺序也是不固定的,不同term的倒排信息是交叉写入的。
Lucene使用了IntBlockPool和ByteBlockPool,避免Java堆中由于分配小对象而引发内存碎片化从而导致Full GC的问题,同时还解决数组长度增长所需要的数据拷贝问题,最后是不再需要申请超大且连续的内存。
2.2、索引查询期间
文档 id、词频、位置等是否构建倒排是可选的,因此 Lucene 将 Postings List 被拆成三个文件存储:
.doc后缀文件:记录 Postings 的 docId 信息和 Term 的词频
.pay后缀文件:记录 Payload 信息和偏移量信息
.pos后缀文件:记录位置信息
三个文件整体实现差不太多,这里以.doc 文件为例分析其实现。
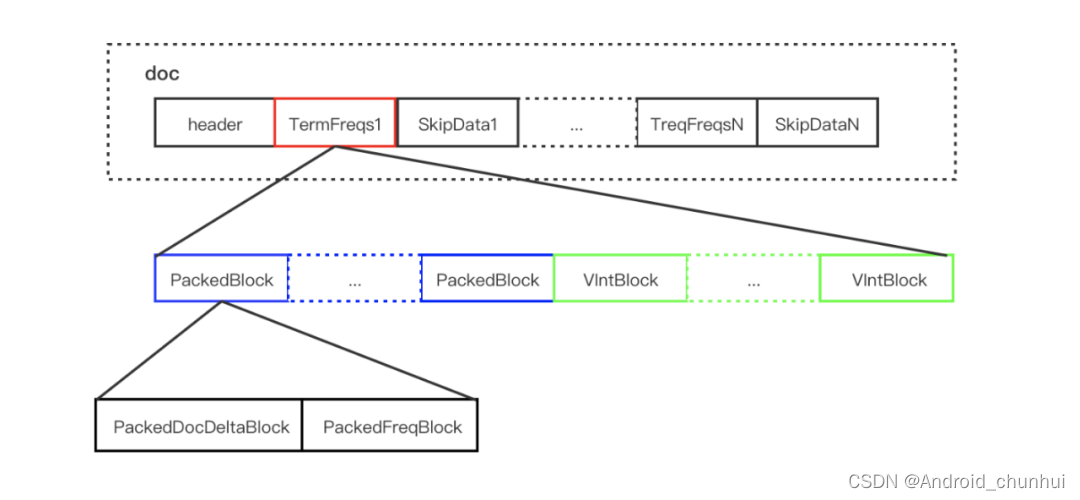
.doc 文件存储的是每个 Term 对应的文档 Id 和词频。每个 Term 都包含一对 TermFreqs 和 SkipData 结构。
其中 TermFreqs 存放 docId 和词频信息,SkipData 为跳表信息,用于实现 TermFreqs 内部的快速跳转。

2.2.1 TermFreqs
TermFreqs 存储文档号和对应的词频,它们两是一一对应的两个 int 值。Lucene 为了尽可能的压缩数据,采用的是混合存储 ,由 PackedBlock 和 VIntBlocks 两种结构组成。
PackedBlock
PackedInt的压缩方式是取数组中最大值所占用的 bit 长度作为一个预算的长度,然后将数组每个元素按这个长度进行存储,将一个 int[] 压缩打包成一个紧凑的 Buffer,改Buffer叫做PackedBlock。
VIntBlock
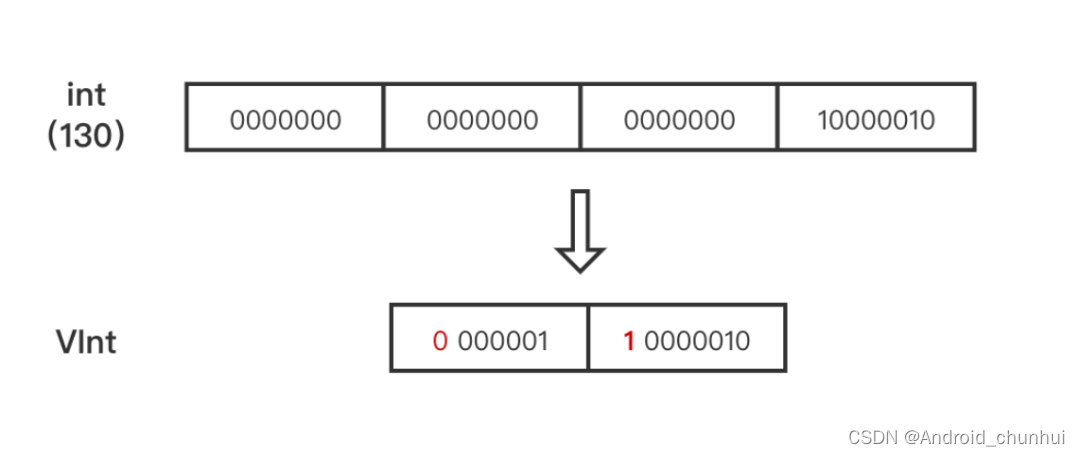
VIntBlock 是采用 VInt 来压缩 int 值,通常int 型都占4个字节,VInt 采用可变长的字节来表示一个整数。每个字节仅使用第1至第7位(共7 bits)存储数据,第8位作为标识,表示是否需要继续读取下一个字节。
根据上述两种 Block 的特点,Lucene 会每处理包含 Term 的128篇文档,将其对应的 DocId 数组和 TermFreq 数组分别处理为 PackedDocDeltaBlock 和 PackedFreqBlock 的 PackedInt 结构,两者组成一个 PackedBlock,最后不足128的文档则采用 VIntBlock 的方式来存储。这里的PackedDocDeltaBlock是指对DocId的差值存储成PackedBlock形式,因为差值数值更小,占用存储空间更小。
2.2.2 SkipData
对Term拉链求交集的操作,需要判断某个 Term 的 DocId 在另一个 Term 的 TermFreqs 中是否存在。Term拉链式DocId有序的,将其表示成调表结构,跳表节点的DocSkip 属性保存了 DocId 值,DocBlockFP、PosBlockFP、PayBlockFP 则表示 Block 数据对应在 .pay、.pos、.doc 文件的位置。
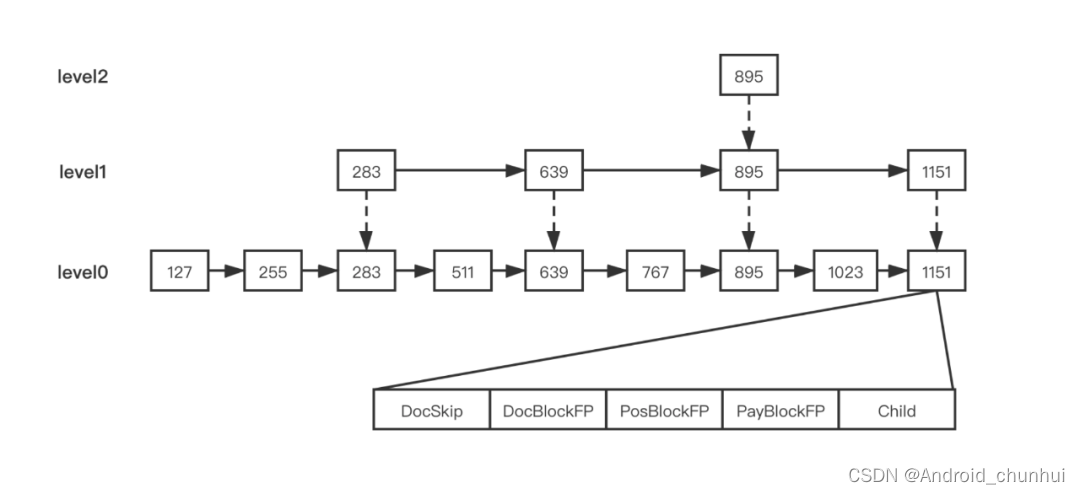
Posting List 采用多个文件进行存储,最终我们可以得到每个 Term 的如下信息:
SkipOffset:用来描述当前 term 信息在 .doc 文件中跳表信息的起始位置。
DocStartFP:是当前 term 信息在 .doc 文件中的文档 ID 与词频信息的起始位置。
PosStartFP:是当前 term 信息在 .pos 文件中的起始位置。
PayStartFP:是当前 term 信息在 .pay 文件中的起始位置。
3、倒排查询逻辑
在介绍了索引表和记录表的结构后,就可以得到 Lucene 倒排索引的查询步骤:
通过 Term Index 数据(.tip文件)中的 StartFP 获取指定字段的 FST
通过 FST 找到指定 Term 在 Term Dictionary(.tim 文件)可能存在的 Block
将对应 Block 加载内存,遍历 Block 中的 Entry,通过后缀(Suffix)判断是否存在指定 Term
存在则通过 Entry 的 TermStat 数据中各个文件的 FP 获取 Posting 数据
如果需要获取 Term 对应的所有 DocId 则直接遍历 TermFreqs,如果获取指定 DocId 数据则通过 SkipData 快速跳转
3、索引Segment的合并逻辑
因为

![【YOLOv8改进[注意力]】使用CascadedGroupAttention(2023)注意力改进c2f + 含全部代码和详细修改方式 + 手撕结构图](https://img-blog.csdnimg.cn/direct/0b1ba0c314a44dafbbe0971e7041faf0.png)